Pipelines: [Project Health] Dependency upgrade process
KFP has many dependencies like
- library versions (e.g. tfx, mlmd)
- images (e.g. dockerhub/python, alpine, ...)
Benefits of updating these on a timely manner:
- Upstream image updates likely remove many vulnerabilities that we will need to investigate manually each time later
- We need to keep in sync with tfx/mlmd etc to know problems early.
We could stop pinning image versions to try getting above benefits, but this approach makes KFP repo non-deterministic. Tests may start to fail suddenly with no clue when some images released a new tag.
The best long term solution I can imagine is:
- build a script that programmatically update a dependency's version in KFP repo, we can use this to ease manual update efforts.
- build a bot that periodically run above script and send a PR to KFP repo, admins can approve these PRs if they pass presubmit tests.
We'll likely need to set this up for each type of dependency.
A script that programmatically update a dependency is of higher priority, because so far update efforts have been highly manual and time-costing.
In this approach,
- there's minimal ongoing efforts needed to keep images up-to-date
- tests/builds won't suddenly fail without any clue
- if there are incompatibility issues with a dependency's new version, we can discover it early
 Bobgy
Bobgy
All 61 comments
I think docker image update is a good first candidate, because it is of low possibility to break us on upgrade, also we need the timely vulnerability fixes coming from it.
Bobgy
on 28 Oct 2020
There are several main areas that might need updating:
- Python SDK deps
- Backend Go deps
- Kubernetes deps (e.g. Argo, Istio)
- Deps of micro services (Metadata Writer, Visualization Server, etc.)
- frontend deps
- MLMD client/server version
For python (SDK and Visualizations) we already have update scripts.
 capri-xiyue
on 19 Jan 2021
capri-xiyue
on 19 Jan 2021
@Bobgy Regarding the docker tags, it seems dependabot can already do this.
https://dependabot.com/blog/dependabot-now-supports-docker/
Edit:
It seems it is also already setup to do so, see https://github.com/kubeflow/pipelines/pull/4962, but Maybe some settings can be optimized as dependabot limits the amount of PRs it creates which I think should be higher than the default (5 I believe).
I just saw that the dependency was in a *.py file. In that case it is a question of setting up dependabot to scan docker files as well.
 DavidSpek
on 20 Jan 2021
DavidSpek
on 20 Jan 2021
@Bobgy I've created a script that will scan the repository for files named *ockerfile* but skipping /components/deprecated*, package*.json but skipping /*node_modules* and *requirements.txt. It then goes on to create the yaml file for dependabot so it scans the correct directories. It is setup for dockerfiles, npm, gomod and python at the moment, and I believe this should cover almost all the code in the repo. It is trivial to further customize what folders are selected if further customization is needed.
As it stands now, there are about 130 PRs that will be created with this configuration, so it might be advisable to have some form of plan to implement it in stages or be ready to quickly go through lots of the PRs. Another option is to create a target branch for all these PRs so they can be merged into that first rather than master.
https://github.com/kubeflow/pipelines/pull/5015
DavidSpek
on 20 Jan 2021
For reference, the PRs that will be created can be seen here: https://github.com/DavidSpek/pipelines/pulls
DavidSpek
on 20 Jan 2021
To add to the above PRs, by default the dependabot security alerts can only be seen by repo admins. While I understand it might not be desirable to have this information be public (although all it takes is forming the repo to find out), I do think it is important that WG members are able to see the security alerts so they can quickly see what dependabot PRs have a high priority for being merged. I'm not sure how this would work wrt https://github.com/kubeflow/internal-acls, but here are the instructions to do it through the UI:
https://docs.github.com/en/github/administering-a-repository/managing-security-and-analysis-settings-for-your-repository#granting-access-to-security-alerts
DavidSpek
on 20 Jan 2021
@Bobgy, I could be wrong but I believe my PR covers the entire scope of what was described in the original post. If you agree I will change the PR so that it links to this issue and can close it when it gets merged.
DavidSpek
on 25 Jan 2021
Based on the example https://github.com/DavidSpek/pipelines/pulls,
it looks like it will create one PR for each dependency.
I'm worried that too much PRs will get created for one major update and it causes burden for devs to review it. In addition, I'm afraid it will cause large workloads of test infra if we create one PR for one specific dependency upgrade.
I'd prefer we will have one single large PR for dependency update of a specific area if people need to review such dependency update PRs.
For example, one large pr for all dependency update of go code, one large pr for all dependency update of python deps and one large pr for all dependency update of front end deps. We may need to write our own scripts for dependency update of each specific area.
capri-xiyue
on 26 Jan 2021
I understand that some updates, such as updating all go kubernetes dependencies to a new version should be bundled together. However, by grouping together all updates for python dependencies and running tests on them, what happens if that test fails? You will then need to go through all the changes and this try to figure out what dependency caused the test to fail. In contrast, if 1 test is run for each dependency update (excluding those that belong together such as k8s or for example Angular), if the tests run successfully the PR can be merged without needing to think about it much. Also, that dependabot creates a set of PRs for, for example, Angular, will at least notify the devs that some time needs to be put into updating to a new Angular version.
Furthermore, there is the option to configure allow and ignore rules for what packages dependabot updates. https://docs.github.com/en/github/administering-a-repository/configuration-options-for-dependency-updates#allow. However, as this is very specific for each repository and something that the devs will encounter while they are using it, I figured this customization would be done after merging the initial PR and people go through the created PRs.
DavidSpek
on 26 Jan 2021
I agree that if we have good test coverage, maybe we can merge prs related to dependency update automatically and devs don't need to review them. However, I'm still afraid that it will cause large workloads of test infra if we create one PR for one specific dependency upgrade. I'm fine with dependabot as long as we have strong coverage of e2e tests, we have automatic process of dependency update pr merging, and the test infra can handle large number of prs at the same time.
capri-xiyue
on 26 Jan 2021
@capri-xiyue Am I correct in thinking that your concerns are mainly regarding the initial spike of PRs the dependabot will create once it is configured? Because after those initial PRs, think the test infra should be able to handle running a test for each PR.
If that is indeed the case, my idea of first merging the updates (or a lot of them) into a separate branch and then merging that into master should allow for running testing on a large number of updates in a single PR.
It is also possible to simple delete a portion of the yaml initially, or set the maximum PRs per folder*package-system to 1 to limit the initial amount of PRs.
DavidSpek
on 26 Jan 2021
@DavidSpek Not only initial spike of prs when dependabot when it is configured but also possible spike of dependency update prs in the future. When we set the maximum PRs per folder*package-system to 1, does that mean only one dependency(library) will get updated? I don't think that's what we want. Ideally, we will update all dependencies unless we have specific concerns.
capri-xiyue
on 26 Jan 2021
@capri-xiyue I fully expect that some fine tuning of the script, like adding ignore rules or limiting the amount of PRs for specific folders will be needed or even removing certain folders. However, I think most of the things that needs fine tuning will only come to light once dependabot starts creating PRs.
DavidSpek
on 26 Jan 2021
@DavidSpek I'm quite confused that why we need specific tuning regarding the amount of PRs and how it will help generate a light dependency update. I thought ideally we will update all dependencies unless we have specific concerns. For example, when we set the limit of PRs to 10, however, 15 dependency need to get updated, how will dependabot handle it and how will dependabot choose which 10 dependencies it will update. And if we still want to update another 5 dependencies left, does that mean we need to ask dependabot to run again and create another 5 prs?
capri-xiyue
on 26 Jan 2021
@capri-xiyue In the example you describe, dependabot will first create 10 PRs, how it chooses these I am not sure but I am guessing it will take security vulnerabilities into account. After you merge one of the 10 original PRs it will add another one from the 5 that are still remaining. If it does this instantly (that it keeps a backlog in memory so to say) or if it happens the next day during the new scan I am not sure. What I do know for sure is that you do not need to ask the dependabot to run again in any case.
I agree that all dependencies should be upgraded unless there are specific concerns, and that is why a human will need to check the PRs created by dependabot before allowing the tests to run or merging it. With tuning I meant, for example, removing certain dependencies that dependabot cannot update. Such as Angular version upgrades which need to be performed manually and can't just be updated by changing the dependency version in the file.
DavidSpek
on 26 Jan 2021
@DavidSpek Thanks for the explanation!
I checked the usage of depantbot, https://docs.github.com/en/github/administering-a-repository/configuration-options-for-dependency-updates#open-pull-requests-limit, once we reach the open-pull-requests-limit, new requests are blocked until you merge or close some of the open requests and for the remanning dependency update, those prs will get created for next scheduled time. If we want to use usage of depantbot, I think we will need an automatic merge process of such dependency update prs(no dev review needed if the pr passes all test results) and we need to make sure we have strong coverage of tests all the time. And we need to set up the update schedule quite short like daily(as what your pr did https://github.com/kubeflow/pipelines/pull/5015/files) to avoid spike of prs.
capri-xiyue
on 26 Jan 2021
@capri-xiyue Currently I have the limit set to 10 PRs per folder*package-system and set to check daily. In regards to the testing and automatic merging that is something up to the OWNERS of each repo and/or folder. Personally I'm not against having PRs auto test and/or auto merge as I believe staying up to date and not getting stuck on old versions of software is important, but that is my opinion as an outsider in this case :).
DavidSpek
on 26 Jan 2021
@DavidSpek I agree that In regards to the testing and automatic merging that is something up to the OWNERS of each repo and/or folder. But without such automatic merging, devs of KFP may have to review at most 10 prs for each driectory(8 directories are defined with dependant config for KFP) daily which makes the review process quite unpractical. That's why I think we need to determine the PR review and merge process before we make a decision that we will use depantbot for dependency update.
capri-xiyue
on 26 Jan 2021
@capri-xiyue Out of interest, what would be the alternative system for dependency upgrading? I think custom scripts (that add dev overhead themselves) will most likely run into the same issues or be more time consuming than dependabot. I completely agree that the process for reviewing and merging should be determined before enabling dependabot. I guess what I am trying to get at is, is it still a question about using dependabot or not, or only about how to implement it?
DavidSpek
on 26 Jan 2021
@DavidSpek
I'm considering writing custom scripts like https://github.com/knative/hack/blob/8d623a0af457cbe26134e20624bc31a2809617dd/library.sh#L537 and https://github.com/google/knative-gcp/blob/master/hack/update-deps.sh, and it will create PRs like https://github.com/google/knative-gcp/pull/2091/files (one single large pr). This is a example for Go. Currently I'm not sure how much the workload is for developing other custom scripts needed in KFP.
I agree that custom scripts will take more time to develop but the workload of reviewing might be lighter.
Depedabot is easy to configure but the workload of reviewing will be a issue if we can't enable automatic review and merge process for depedabot.
Both custom scripts and dependabot have its pros and cons.
capri-xiyue
on 26 Jan 2021
@capri-xiyue Thanks for the links, I'll look into them in a moment. I think another important difference is that a custom script will need infra to run on, and the infra will also need to be managed. Also, if the infra providers changes similar to the test infra moving from GCP to AWS, the custom solution will also need to be migrated. Did you already have a plan where this custom solution would run? Also, would this solution be easy to implement for all repositories of Kubeflow, or would the script be very specific for one repository? As it is now, my python script works for all repositories and I have PRs open on all of them as well as dependency management is needed everywhere.
EDIT:
Also, the linked scripts you provided are specifically go. How difficult would it be to include python, npm and docker? Isn't the script that would then be created basically reinventing the wheel and creating a new dependabot (other than multiple updates in one PR, which I guess could be added to dependabot as well)?
DavidSpek
on 26 Jan 2021
Yep. That script I mentioned is specifically for Go and I think we already have custom scripts for python https://github.com/kubeflow/pipelines/blob/master/backend/update_requirements.sh. I'm not sure how difficult it is to include npm and docker, we need further investigation. My idea is that one custom scripts for one area(for example, one script for go, one script for python). If dependabot can support multiple updates in one PR, I think we can definitely use dependabot. If we can automatically review and merge the prs created by depedabot, I think we can also use dependabot.
By the way, for the dependency update, currently I'm not sure whether there will be any customization needed for scripts when people run on different platforms like GCP, AWS. Does dependantbot support any dependency update customization for different platforms?
capri-xiyue
on 26 Jan 2021
@capri-xiyue Do I understand correctly that the given go script or python script would need to be copied to each directory that contains the given dependency file (at least in the current form)? This would mean a lot of code duplication, especially when considering all the repo's of Kubeflow. And also figuring out which folders contain dependency listing files, which is what my script does to then generate the dependabot config yaml.
Dependabot can't currently group PRs, but the core is open source it seems so it could be added. https://github.com/dependabot/dependabot-core. I also had the idea to add Kustomize support for docker images, as the docker logic is already there and it would just need to be able to identify images in the kustomize yaml files.
What I meant in regards to infra, is that any custom scripts will need to run on some form of infra. While dependabot is integrated into GitHub, if the dependabot.yml file exists in the .github folder, dependabot will start working. No further infra is needed.
DavidSpek
on 26 Jan 2021
For the code duplication, maybe we can follow what Knative does, we can put such common deps update scripts in a specific repo shared by all kubeflow repos and each kubeflow repo can make use of it as https://github.com/google/knative-gcp/blob/master/hack/update-deps.sh does.
I don't have any other concerns for dependabot as long as we can figure out how to make the review and merge process of PRs created by dependabot practical(either dependabot support PR grouping or kfp support automatic review and merge for such prs)
capri-xiyue
on 26 Jan 2021
One option would be for dependabot to have a global max PR limit, which I think wouldn't be to hard to implement and I raised here.
There seem to be more people that are facing similar problems wrt the amount of PRs that dependabot would create and wanting to group them together. Relevant issue: https://github.com/dependabot/dependabot-core/issues/2652. Tracking issue for the grouping functionality: https://github.com/dependabot/dependabot-core/issues/2672.
DavidSpek
on 27 Jan 2021
This comment links to a repository in which the ability to group dependency updates together has been added it seems. https://github.com/dependabot/dependabot-core/issues/2672#issuecomment-719130140
DavidSpek
on 27 Jan 2021
@capri-xiyue For reference, this repo has added the ability to group dependencies together in a PR, and contains the necessary docs and scripts to self-host dependabot. https://github.com/pharos/dependabot-script/tree/pharos-giltlab
If we can get this setup on the AWS infra (or another infra for that matter) I think we have the issue solved. However, I think I will try contacting one of the devs working on dependabot to see if this can get added into the github integrated version to reduce overhead of running our own dependabot.
https://github.com/pharos/dependabot-script/tree/pharos-giltlab
DavidSpek
on 27 Jan 2021
@DavidSpek Renovate is an open source tool - also available as a free app on GitHub - which supports native PR grouping, rate limiting and automerging. It also supports bazel, which it seems you use here.
As an example, I have forked this repo to view Renovate's onboarding Pull Request here: https://github.com/rarkins/pipelines/pull/1
There are 300+ Pull Requests which would be created in the current config, but:
- You can limit PR creation both per-hour as well as concurrently
- You can use the
dependencyDashboardfeature to have an issue in-repo which lets you pick PRs to crate on-demand (i.e. skip the queue/limit) - You can apply further ignore statements (e.g. samples, tests) if you prefer
- Grouping rules can be applied for related dependencies
Renovate is widely used, including by the google, googleapis and angular orgs on GitHub.
 rarkins
on 27 Jan 2021
rarkins
on 27 Jan 2021
@rarkins Thanks for bringing that up, I'm going to look into it right away. Did I see correctly that it also supports Kustomize?
DavidSpek
on 27 Jan 2021
@dav009 yes, Renovate supports Kustomize.
Renovate also has a "regex manager" capability which means you can essentially create custom package managers with config to extract dependencies from unsupported file formats too - including completely proprietary files - and have them updated too, assuming that they can be referenced against an existing datasource like github tags, Docker images, etc. We use this e.g. to keep install scripts within Dockerfiles and shell scripts updated.
rarkins
on 27 Jan 2021
Thank you @rarkins for bringing it up! Sounds like it meets almost all of our requirements.
Just for sanity checking, I was looking at permission requirements for the github app,
Read and write access to checks, code, commit statuses, issues, pull requests, and workflows
Why does it need write access to code?
Bobgy
on 27 Jan 2021
@Bobgy I think this is for the auto-merging feature. However, there is an alternative that doesn't require write access: https://github.com/apps/forking-renovate.
DavidSpek
on 27 Jan 2021
@DavidSpek neat, that looks like exactly what we need.
Bobgy
on 27 Jan 2021
Why does it need write access to code?
Apps are not "real" users in GitHub so cannot fork repos in order to submit an outsider Pull Request. Therefore the app requires write access to create its own branches even if not automerging.
The mentioned Forking Renovate app overcomes this by forking repos using the real user @renovate-bot.
I think that concern over write access for apps is not so relevant now that GitHub supports robust branch protection for repos - which you should be using regardless of Apps.
rarkins
on 27 Jan 2021
That's a good point I overlooked, yes, we do have branch protections set up.
But anyway, I'd prefer following minimal permission principal when it's possible.
@rarkins A side question: can I confirm, do @renovate-bot already sign Google's CLA?
Bobgy
on 27 Jan 2021
@rarkins A side question: can I confirm, do @renovate-bot already sign Google's CLA?
Yes. The app is installed and active on 400+ repos within google, googleapis, GoogleCloudPlatform and ampproject, plus potentially some other Google orgs that I'm not aware of.
rarkins
on 27 Jan 2021
Awesome,
/cc @capri-xiyue @chensun @numerology @Ark-kun @zijianjoy
Hi team, this is a potentially wide impact process change, I'd like to hear your thoughts about it.
Bobgy
on 27 Jan 2021
I am currently experimenting with creating a config file for pipelines, which I hope can also serve as a nice base for other repositories as well.
DavidSpek
on 27 Jan 2021
To provide everybody with an example. With the below code snippet in the config file, it will group all patch and minor updates to all docker files together in one PR.
"packageRules": [
{
"datasources": ["docker"],
"updateTypes": ["patch", "minor"],
"groupName": "docker patch & minor updates"
}
],
The resulting PR looks as follows:
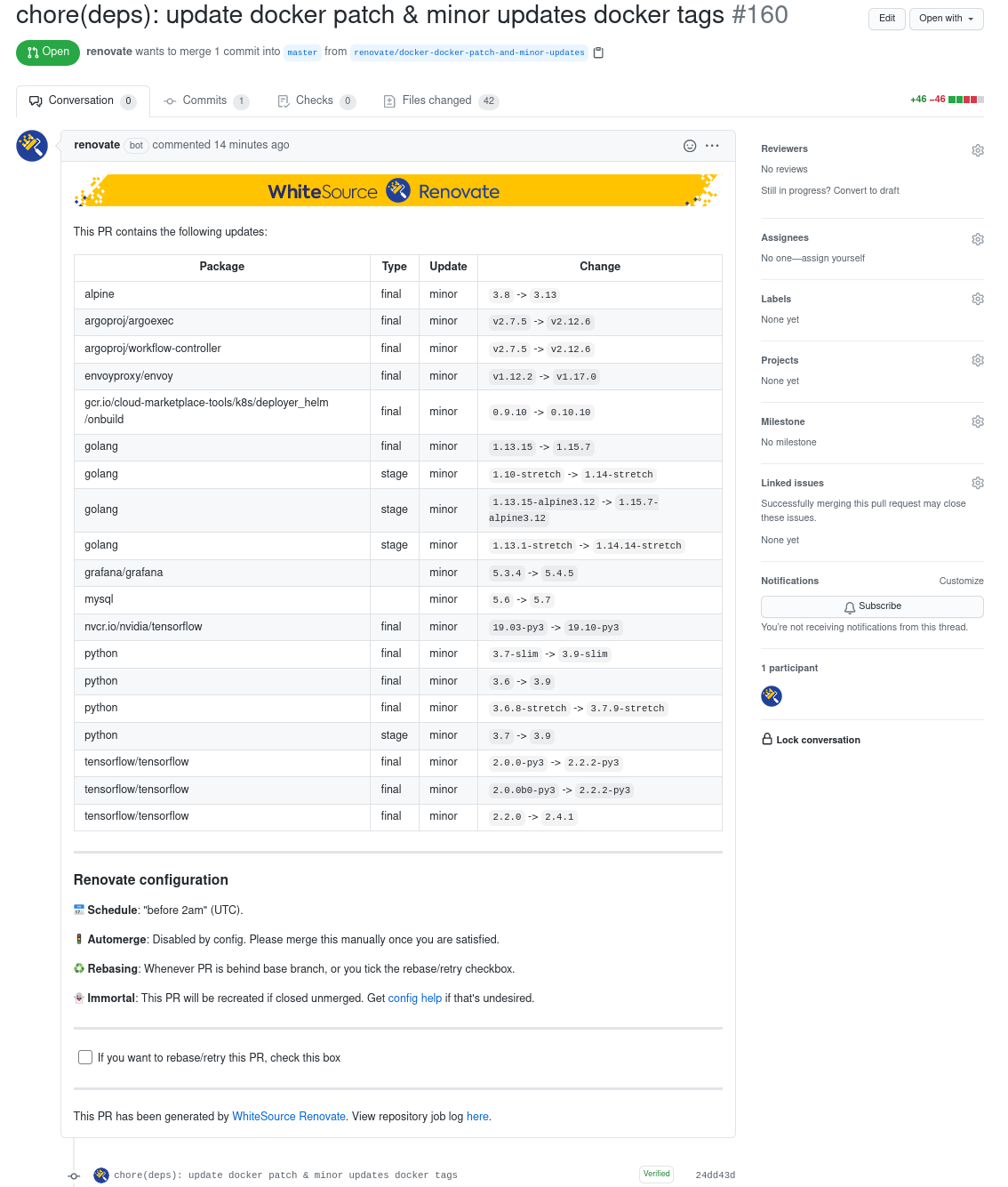
https://github.com/DavidSpek/pipelines/pull/160
DavidSpek
on 27 Jan 2021
Hi team, this is a potentially wide impact process change, I'd like to hear your thoughts about it.
Thank you everyone for contributing the ideas and discussion! It looks to me a great improvement on product health using renovate bot!
There are a couple points from my perspective:
- Since there is still a concern about test coverage which might not be able to catch issues during presubmit tests, I would suggest to upgrade dependency on one directory first with renovate bot. Once we validate the process to be trustworthy, we can apply the renovate bot to the whole repo, and finally kubeflow org.
- What schedule do we prefer on creating new PRs? Reference. I would suggest weekly PR to avoid noise or potential breakage, and determine the assignee rotation for reviewing PRs. I am open to other opinions. Thank you!
 zijianjoy
on 27 Jan 2021
zijianjoy
on 27 Jan 2021
@zijianjoy For avoiding noise and potential breakage, I think setting stabilityDays is a very interesting option. https://docs.renovatebot.com/configuration-options/#stabilitydays.
"If you combine stabilityDays=3 and prCreation="not-pending" then Renovate will hold back from creating branches until 3 or more days have elapsed since the version was released. It's recommended that you enable dependencyDashboard=true so you don't lose visibility of these pending PRs."
In terms of testing it on one directory to validate the test coverage that sounds like a good idea.
What I would like to get some feedback on while I am creating the initial config is what dependencies should (or need to) be updated together, and if that is only for patch and/or minor releases or also major ones. This was I can create a config that will not create an overload of PRs and a large load on the testing infra.
DavidSpek
on 27 Jan 2021
I think Renovate is a great tool for the dependency upgrade process.
- Since Renovate supports grouping PRs, I don't think we need automatic merging now and devs should be able to have the bandwidth to review the dependency update PRs
I'd suggest we create all PRs of Renovate for all repos in Kubeflow Pipelines to make sure the features of Renovate will be sufficient enough for the dependency upgrade process of Go, Python, Docker, xxx . Since devs only need to review one large PR for one repo, I think the review process is practical. - For the frequency, I think weekly should be enough. I'm also fine with daily. If we update dependency daily, I think the dependency update PR should be quite light.
capri-xiyue
on 28 Jan 2021
Beware of grouping updates into a single PR too aggressively, because if one upgrade is causing then PR to fail then you get blocked updating anything. And if more than one upgrade fails then it further increases the difficulty of figuring out which upgrades are causing the failure in the first place.
If the project has quite outdated dependencies right now, it may require a different approach/process initially to bring things up to date compared to later on, where daily/weekly groupings might have a better chance of success.
If you want the lowest risk/impact initial approach, it would be to use the "Dependency Dashboard" feature of Renovate, which will result in a single issue being created in the repo which lists all pending updates (including groups, if configured) and lets you tick checkboxes to have them created on-demand. We use this in the Renovate source repo ourselves
rarkins
on 28 Jan 2021
For reference, this is the dashboard for Pipelines while I am trying to find a good starting config.
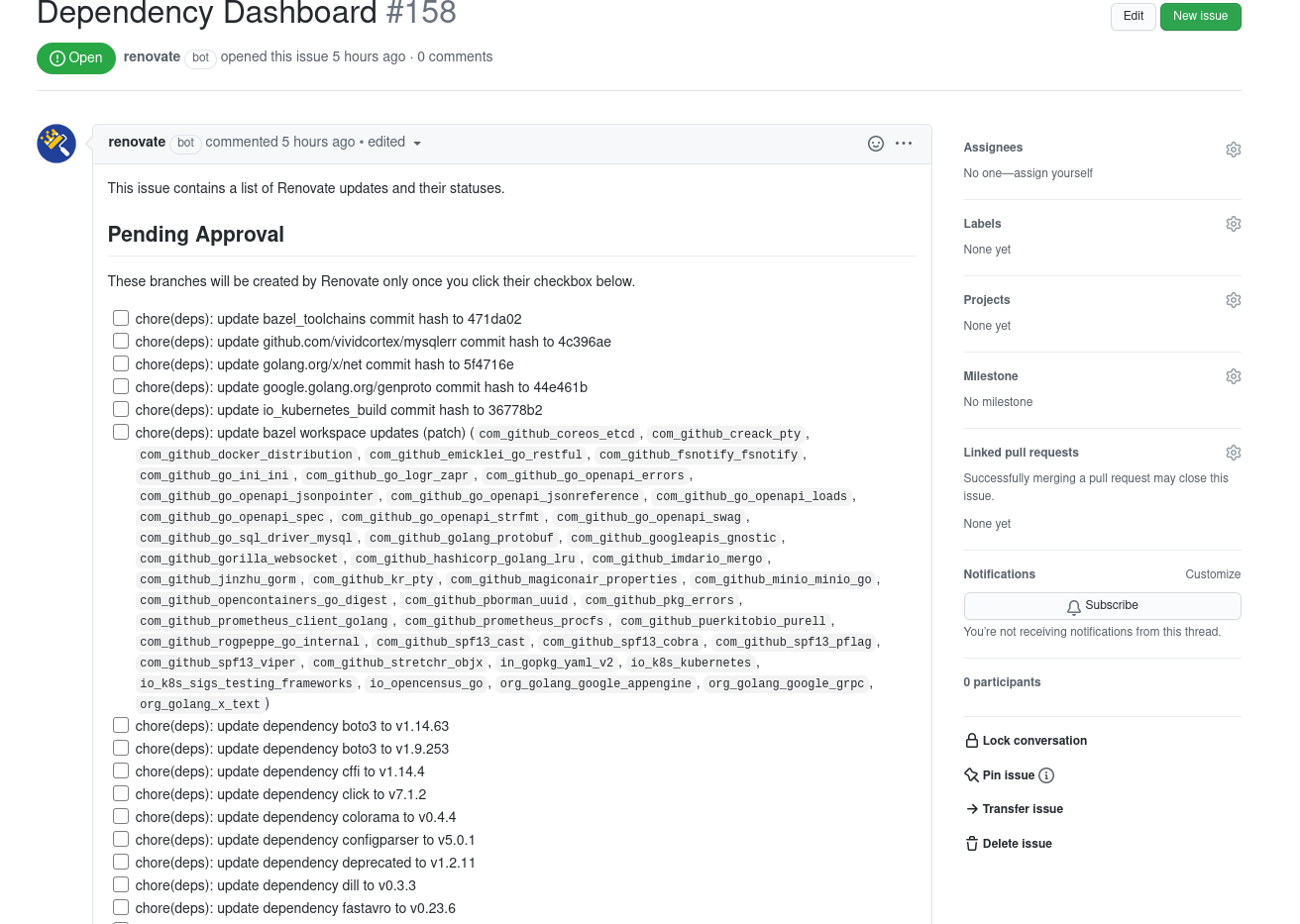
https://github.com/DavidSpek/pipelines/issues/158
DavidSpek
on 28 Jan 2021
Neat, I think we can get started with that dashboard first as @rarkins suggested.
Bobgy
on 29 Jan 2021
Installed the forking renovate github app
Bobgy
on 29 Jan 2021
The configuration PR was created: https://github.com/kubeflow/pipelines/pull/5056
Bobgy
on 29 Jan 2021
The dashboard is live!
https://github.com/kubeflow/pipelines/issues/5068
Bobgy
on 2 Feb 2021
A remaining configuration thing to discuss is, do we want to pin our dependencies?
https://docs.renovatebot.com/dependency-pinning/
There are two approaches:
package.jsonkeeps using semver versions, renovate only updatespackage-lock.json- We pin all direct dependencies in
package.jsonto the exact versions like in https://github.com/kubeflow/pipelines/pull/5069, renovate will update bothpackage.jsonandpackage-lock.json.
EDIT: if we want to choose 1, we should enable :preserveSemverRanges config: https://docs.renovatebot.com/presets-default/#preservesemverranges.
If we want to choose 2, that's the default behavior.
I tend to stay with 1 first, because that's our existing approach.
Bobgy
on 2 Feb 2021
Hmm, something doesn't look right. After making this configuration only webdriverio/wdio-selenium-standalone-service, webpack/webpack were updated in npm patch PR.
Revising again based on https://docs.renovatebot.com/configuration-options/#rangestrategy
Bobgy
on 2 Feb 2021
@Bodgy please see #5075
rarkins
on 2 Feb 2021
FWIW I recommend against retaining ranges in package.json unless you are publishing a library. By retaining ranges you don't save any noise to the repo (need just as many updates) but it's harder to tell what version you are currently on or what is being upgraded, because you have to dig through hundreds or thousands of lines of a lock file instead of dozens in a package.json.
rarkins
on 2 Feb 2021
@rarkins I can see your point, for clarification, we will unnecessarily have specific reasons to stick to certain version of a library for some time.
I'd hope such a decision can be represented in a form not coupled to renovate, so that e.g.
- we can still upgrade dependencies in the usual way -- using npm update
- keep source of truth in
package.json
If we pin all versions in pakcage.json and configure package specific no update rules in renovate.json, that sounds like too aggressive for adopting a new tool.
Bobgy
on 2 Feb 2021
In fact, even with rangeStrategy=update-lock, version update is still very visible thanks to Renovate: https://github.com/kubeflow/pipelines/pull/5071.

Bobgy
on 2 Feb 2021
TODO: set up a process so people periodically come and fix upgrade problems.
Right now, the npm patch update PR #5071 fails because of some typescript errors after upgrade. Without a process, upgrade PRs will never be prioritized and merged.
Bobgy
on 19 Feb 2021
@Bobgy Might I suggest pinning the dependency dashboard issue so that it doesn't get lost between the countless new issues that are created? Related to that, there is another issue that is now pinned that has been closed so it can probably be unpinned. https://github.com/kubeflow/pipelines/issues/5020
DavidSpek
on 19 Feb 2021
@Bobgy Any update how Renovate has been working out? Or has everybody been to busy with the upcoming release to go through the dependency updates?
DavidSpek
on 18 Mar 2021
Yes, everyone has been busy.
I tried the batch patch upgrade, but some typescript changes need manual fix. So I was stuck there.
Will try to resume after release.
Anyway, I feel that the dashboard is very helpful. It allowed us to integrate at our own pace.
Bobgy
on 18 Mar 2021
Is there a way to allow repository owners (or rather people listed in the OWNERS file) to edit issues? For kubeflow/kubeflow the Dependency Dashboard would only serve as an overview, but the ability to need to approve a PR in the dashboard before it is created is lost otherwise.
DavidSpek
on 18 Mar 2021
I think the plan is to move notebooks code to kubeflow/notebooks repo, where they can get write permission
Bobgy
on 18 Mar 2021
Great! The way I had envisioned the management of the notebook images relies heavily on Renovate and setting that up without the Dependency Dashboard approval feature complicates things a lot as you can image.
DavidSpek
on 18 Mar 2021
Related issues
Bobgy
·
4Comments
 xinbinhuang
·
3Comments
xinbinhuang
·
3Comments
 goswamig
·
5Comments
goswamig
·
5Comments
 maggiemhanna
·
5Comments
maggiemhanna
·
5Comments
 discordianfish
·
4Comments
discordianfish
·
4Comments
Most helpful comment
Yes. The app is installed and active on 400+ repos within
google,googleapis,GoogleCloudPlatformandampproject, plus potentially some other Google orgs that I'm not aware of.