Pipeline: Completed steps within a pod will re-run if restarted for some reason
Expected Behavior
Once a step in a TaskRun completes, it should not run again. If the entire pod was rescheduled before the TaskRun completed, perhaps all steps should start again, but if something triggers the re-creation of only containers within a pod, they should not run again.
Actual Behavior
The entrypoint binary will wait for it's waitfile to exist, then run, then write the file that indicates it has completed. This means that if the container is restarted after completing, its waitfile will exist, and it will run again.
Steps to Reproduce the Problem
I don't know how to reproduce it, but it happened while I was running the release pipeline for v0.13.0: https://dashboard.dogfooding.tekton.dev/#/namespaces/default/pipelineruns/pipeline-release-run-fwrpr
Check this out, it's crazy!!!
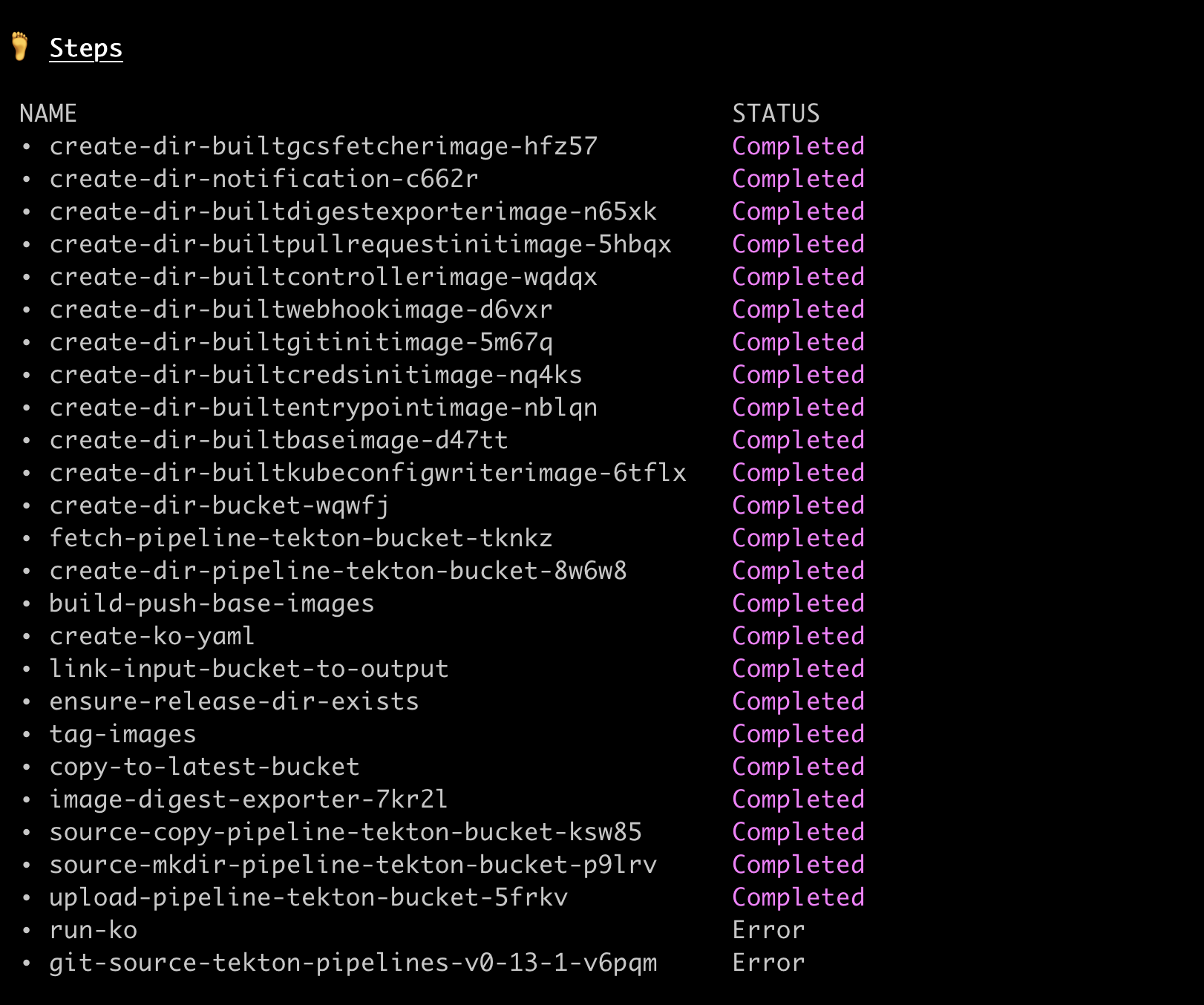
Looking at the above, somehow _all steps have succeeded_ except run-ko and git-source-tekton-pipelines-v0-13-1-v6pqm - but git-source-tekton-pipelines-v0-13-1-v6pqm is one of the first containers to run!!! It's the PipelineResource injected container that gets the git source!! It's impossible that build-push-base-images could have succeeded for example without it running. Not to mention the logs for that container are vey telling:
k --context dogfood logs pipeline-release-run-fwrpr-publish-images-wwkf7-pod-g4lc5 -c step-git-source-tekton-pipelines-v0-13-1-v6pqm
{"level":"error","ts":1591815883.1945517,"caller":"git/git.go:41","msg":"Error running git [remote add origin https://github.com/tektoncd/pipeline]: exit status 128\nfatal: remote origin already exists.\n","stacktrace":"github.com/tektoncd/pipeline/pkg/git.run\n\tgithub.com/tektoncd/pipeline/pkg/git/git.go:41\ngithub.com/tektoncd/pipeline/pkg/git.Fetch\n\tgithub.com/tektoncd/pipeline/pkg/git/git.go:81\nmain.main\n\tgithub.com/tektoncd/pipeline/cmd/git-init/main.go:53\nruntime.main\n\truntime/proc.go:203"}
{"level":"fatal","ts":1591815883.1947198,"caller":"git-init/main.go:54","msg":"Error fetching git repository: exit status 128","stacktrace":"main.main\n\tgithub.com/tektoncd/pipeline/cmd/git-init/main.go:54\nruntime.main\n\truntime/proc.go:203"}
The error is Error running git [remote add origin https://github.com/tektoncd/pipeline]: exit status 128\nfatal: remote origin already exists.\n which strongly indicates that this thing has run before! The error for run-ko is similar; it can't create a symlink b/c the symlink already exists.
If you look at the start and completion times of the containers in the pod you can see more evidence (from jq -r '.status.containerStatuses[] | [.name, .state.terminated.startedAt, .state.terminated.finishedAt]'):
[
"step-git-source-tekton-pipelines-v0-13-1-v6pqm",
"2020-06-10T19:04:43Z",
"2020-06-10T19:04:43Z"
]
[
"step-run-ko",
"2020-06-10T19:04:43Z",
"2020-06-10T19:04:46Z"
]
[
"step-tag-images",
"2020-06-10T18:55:03Z",
"2020-06-10T19:04:40Z"
]
[
"step-upload-pipeline-tekton-bucket-5frkv",
"2020-06-10T18:55:04Z",
"2020-06-10T19:04:53Z"
]
step-git-source-tekton-pipelines-v0-13-1-v6pqm started AFTER step-tag-images and actually somehow DURING step-upload-pipeline-tekton-bucket-5frkv.
Something truly wacky happened - i dont know WHY the containers were restarted, but I think at least we can improve the way the entrypoint binary behaves when this happens.
I didn't get to the bottom of why the kubelet decided it needed to rerun these containers (and their restart count is 0) but from looking at the logs and the statuses it seems clear that it did. (Not to mention that all elements of the release actually exist, so it did run successfully.)
Additional Info
Although I don't know what caused this to happen, I'm thinking an easy safeguard is for the entrypoint binary to check if the file it is to write upon completion already exists; if it does, that seems to indicate it has already run and does not need to run again or update its started time, etc.
- Tekton Pipeline version:
v0.12.0
 bobcatfish
bobcatfish
All 16 comments
- here is a dump of the pod: https://gist.github.com/bobcatfish/47402f9e66ff30b3fc3a6f0026c5bdba
- here is a describe of the pod: https://gist.github.com/bobcatfish/aa4febd1da0ec521e389dc9d28d06338
- here are some maybe relevant kubelet logs: https://gist.github.com/bobcatfish/6aef43da83690937a467104e3c7584dc
bobcatfish
on 12 Jun 2020
/type bug
bobcatfish
on 12 Jun 2020
bobcatfish
on 12 Jun 2020
If the entire pod was rescheduled before the TaskRun completed
Pods should not be rescheduled or re-run at all (restartPolicy: Never). It's better to fail the TaskRun than to potentially run even parts of it twice.
Maybe the answer is to have the entrypoint binary check whether its -post_file already exists (indicating that it may have already ran under mysterious circumstances), and not run (or fail loudly?) if that's the case.
 ImJasonH
on 12 Jun 2020
ImJasonH
on 12 Jun 2020
This means that if the container is restarted after completing, its waitfile will exist, and it will run again.
by container you mean pod right ?
 vdemeester
on 15 Jun 2020
vdemeester
on 15 Jun 2020
@bobcatfish is there any k8s logs before the error on duplicated named containers ?
vdemeester
on 15 Jun 2020
by container you mean pod right ?
It sounded like the issue was that a single _container_ in the Pod was restarted, and when it restarted, re-ran the step again. It's possible this happened because the Pod restarted, but then a.) why wasn't restartPolicy:Never respected, and b.) why didn't other steps re-run?
I think we can be more defensive about re-running steps if we see a signal that we're running again. I don't know whether it would prevent this very weird bug, but it probably wouldn't hurt either.
ImJasonH
on 15 Jun 2020
by container you mean pod right ?
It sounded like the issue was that a single _container_ in the Pod was restarted, and when it restarted, re-ran the step again. It's possible this happened because the Pod restarted, but then a.) why wasn't
restartPolicy:Neverrespected, and b.) why didn't other steps re-run?
This feel so weird as I initially thought a container couldn't restart on its own from k8s, but maybe it's on the runtime that there was a weird case…
I think we can be more defensive about re-running steps if we see a signal that we're running again. I don't know whether it would prevent this very weird bug, but it probably wouldn't hurt either.
I agree it make sense to be defensive in that case.
vdemeester
on 15 Jun 2020
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
/lifecycle rotten
Send feedback to tektoncd/plumbing.
 tekton-robot
on 14 Aug 2020
tekton-robot
on 14 Aug 2020
Rotten issues close after 30d of inactivity.
Reopen the issue with /reopen.
Mark the issue as fresh with /remove-lifecycle rotten.
/close
Send feedback to tektoncd/plumbing.
tekton-robot
on 14 Aug 2020
@tekton-robot: Closing this issue.
In response to this:
Rotten issues close after 30d of inactivity.
Reopen the issue with/reopen.
Mark the issue as fresh with/remove-lifecycle rotten./close
Send feedback to tektoncd/plumbing.
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
tekton-robot
on 14 Aug 2020
This is still something we want
/reopen
bobcatfish
on 19 Aug 2020
@bobcatfish: Reopened this issue.
In response to this:
This is still something we want
/reopen
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
tekton-robot
on 19 Aug 2020
/remove-lifecycle rotten
vdemeester
on 20 Aug 2020
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
/lifecycle stale
Send feedback to tektoncd/plumbing.
tekton-robot
on 18 Nov 2020
/remove-lifecycle stale
vdemeester
on 18 Nov 2020
Related issues
 JCzz
·
3Comments
JCzz
·
3Comments
 castlemilk
·
4Comments
castlemilk
·
4Comments
 andydude
·
3Comments
ImJasonH
·
4Comments
andydude
·
3Comments
ImJasonH
·
4Comments
 chmouel
·
3Comments
chmouel
·
3Comments
Most helpful comment
Pods should not be rescheduled or re-run at all (
restartPolicy: Never). It's better to fail the TaskRun than to potentially run even parts of it twice.Maybe the answer is to have the entrypoint binary check whether its
-post_filealready exists (indicating that it may have already ran under mysterious circumstances), and not run (or fail loudly?) if that's the case.