Parity-ethereum: v2.6.0: 4 GB of RAM causing endless disk reads
- Parity Ethereum version: 2.6.0-beta
- Operating system: Linux
- Installation: github binary
- Fully synchronized: yes
- Network: ethereum
- Restarted: yes
Preface
We're still running v2.2.9 on our prod nodes. These prod nodes connect to the public ethereum network but the RPC ports are only accessible for us.
For us it boils down to choose between v2.2.9 (which works flawlessly) or any newer release which either produces heavy disk reads (https://github.com/paritytech/parity-ethereum/issues/10361) or has a memory leak (https://github.com/paritytech/parity-ethereum/issues/10371).
Testing v2.6.0
Last week I began testing 2.6.0 on my dedicated test node (which was running v2.2.9 until then) with this config:
[parity]
no_download = true
[snapshots]
disable_periodic = true
[ui]
disable = true
[websockets]
disable = true
[ipc]
disable = true
[rpc]
disable = false
hosts = ["http://foo:8545"]
interface = "0.0.0.0"
apis = ["rpc", "web3", "eth", "net", "personal", "parity", "parity_set", "parity_accounts"]
[network]
min_peers = 10
max_peers = 15
[mining]
tx_queue_per_sender = 1024
[footprint]
tracing = "off"
db_compaction = "ssd"
pruning = "fast"
cache_size = 2000
[misc]
log_file = "/home/foo/.local/share/io.parity.ethereum/log.txt"
logging = "own_tx,shutdown=trace,signer=trace"
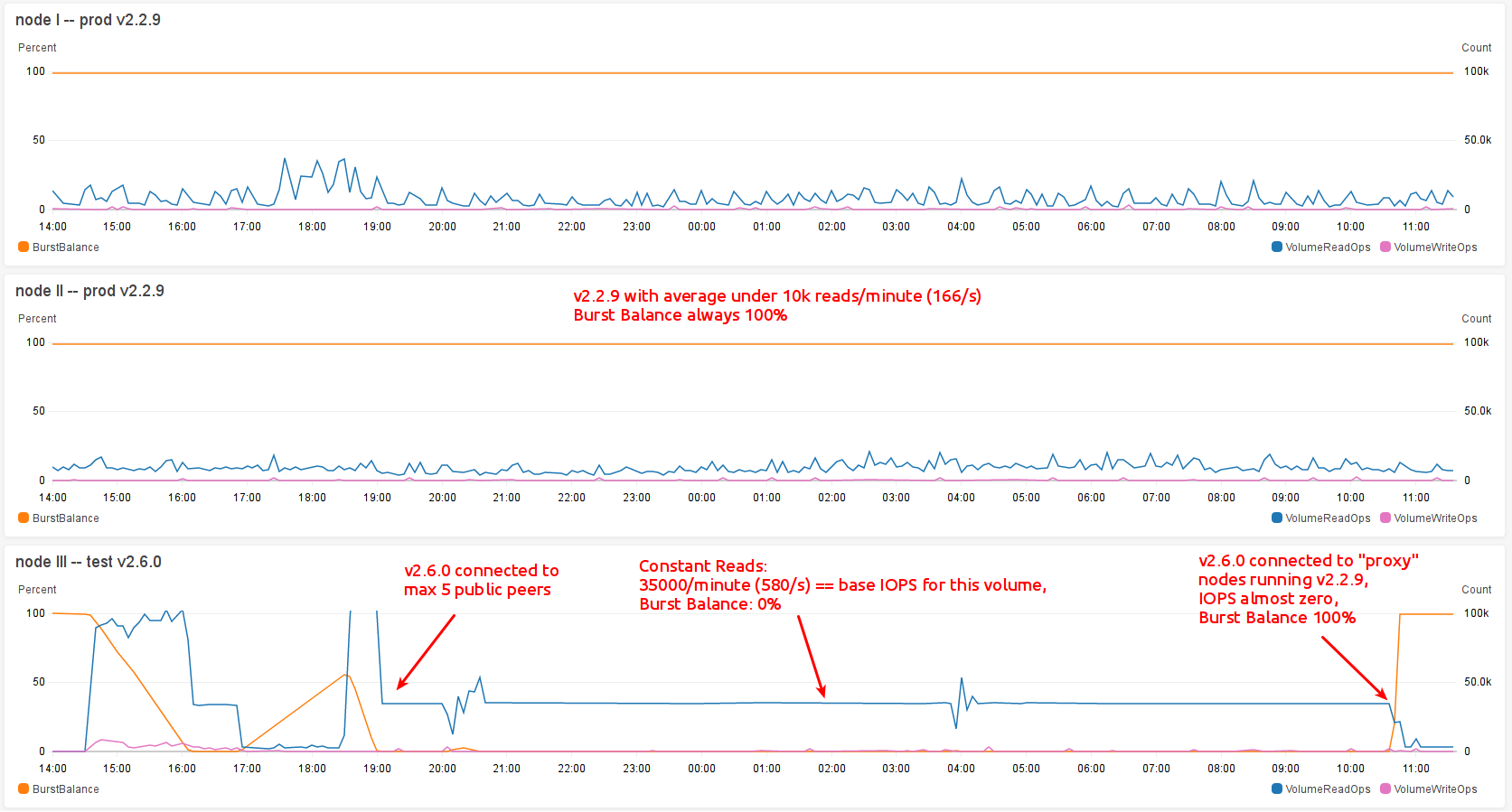
The test node is an AWS ec2 instance of type t3.medium (2 Cores, 4GB) and uses EBS backed storage of type gp2. This type of storage allows for a certain number of baseline IOPS and starts with a _Burstbalance_ of 100%. _Burstbalance_ can be considered an AWS EBS gp2 volume's remaining credit which is expressed in % from 100 to 0 and represents the possibility (BurstBalance > 0%) to burst over the provisioned IOPS or being limited to a low baseline IOPS limit (BurstBalance = 0%).
v2.6.0 connected to public nodes
Running v2.6.0-beta with the above mentioned config leads to massive, constant disk reads, which ultimately leads to my volumes BurstBalance hitting 0% which then even more restricts parity by slowing it down due to limited IOPS the volume allows when it hits 0%. This results in parity getting out of sync, connected peers dropping their connection to my v2.6.0 node because parity is still stuck with disk IO and presumably doesn't respond fast enough to other peers requests. Eventually parity falls back from "importing" blocks to "syncing" blocks and catches up only to begin that game again.
It's only disk READS going crazy like reported in https://github.com/paritytech/parity-ethereum/issues/10361 -- disk writes are almost zero and no issue at all.
Reducing peer count
My first step was to reduce peer count via
[network]
min_peers = 5
max_peers = 5
which didn't change a thing.
v2.6.0 connected only to my own v2.2.9 nodes
Since reducing connections to public nodes didn't change a thing I forced my test node to only connect to two of my v2.2.9 prod nodes (which itself do connect to public nodes):
[network]
#min_peers = 5
#max_peers = 5
reserved_only = true
reserved_peers = "/home/foo/.local/share/io.parity.ethereum/reserved.peers"
And what should I say: DISK READ IS DOWN TO ALMOST ZERO!
Just like mentioned by me in https://github.com/paritytech/parity-ethereum/issues/10361#issuecomment-479818959 I suspect that these massive reads are induced by a connected peer.
Maybe (please bear with me here) v2.2.9 is more resilient to such malicious (?) nodes/requests than newer versions of parity?
 c0deright
c0deright
All 9 comments
Can you confirm there aren't any similar outcomes by disabling light-serving with --no-serve-light?
 joshua-mir
on 12 Aug 2019
joshua-mir
on 12 Aug 2019
And if possible, sharing the contents of your nodes.json file when you do experience this issue would be helpful in identifying the troublesome peers and figuring out what to do about them.
joshua-mir
on 12 Aug 2019
(or the parity_netPeers rpc method)
joshua-mir
on 12 Aug 2019
Can you confirm there aren't any similar outcomes by disabling light-serving with
--no-serve-light?
Testing right now. From the _looks_ of it (running only for 7 minutes), this might be the culprit. Will report back tomorrow with more details.
c0deright
on 12 Aug 2019
What did look promising in the beginning went south after a while, so --no-serve-light didn't make a big difference. I will retest again just to be sure.
c0deright
on 13 Aug 2019
@joshua-mir
Looks like upgrading the VM from 4GB to 8GB did the trick, please see https://github.com/paritytech/parity-ethereum/issues/10960#issuecomment-521595705.
With 8GB of RAM and 10 public peers the disk reads are as low as with 4GB of RAM and only 2 of my reserved_peers connected.
You might wanna note 8 GB of RAM as a requirement for running v2.6.0 or at least mention that 4 GB might result in strange - not obviously caused by low RAM - issues.
c0deright
on 15 Aug 2019
If v2.2.9 works fine on 4GB and in v2.6.0 8GB is the minimum I think it should be a regression in performance.
 gituser
on 15 Aug 2019
gituser
on 15 Aug 2019
v2.5.5 consumes about 21GB of memory when runnning with --cache-size=8192 and this is a non-public node.
gituser
on 15 Aug 2019
I certainly agree that we need to have better guarantees about our memory usage - currently I wouldn't be able to point out parts of the codebase that use memory and cache things and that's probably part of the reason we have scenarios like this.
joshua-mir
on 15 Aug 2019
Related issues
 famfamfam
·
3Comments
famfamfam
·
3Comments
 Michael2008S
·
3Comments
Michael2008S
·
3Comments
 tzapu
·
3Comments
tzapu
·
3Comments
 uluhonolulu
·
3Comments
uluhonolulu
·
3Comments
 jacogr
·
4Comments
jacogr
·
4Comments
Most helpful comment
What did look promising in the beginning went south after a while, so
--no-serve-lightdidn't make a big difference. I will retest again just to be sure.