Parity-ethereum: Thread 'IO Worker #0' panicked at 'DB flush failed.: "Corruption: block checksum mismatch"'
_Before filing a new issue, please provide the following information._
I'm running:
- Which Parity version?: Parity//v1.8.4-beta-c74c8c1-20171211/x86_64-windows-msvc/rustc1.22.1
- Which operating system?: Windows 10 64 bit
- How installed?: via installer
- Are you fully synchronized?: no
- Did you try to restart the node?:yes
_Your issue description goes here below. Try to include actual vs. expected behavior and steps to reproduce the issue._
trying to sync parity and receiving an error of the following;
2017-12-19 12:00:42 UTC Syncing #2158564 6b84…a609 306 blk/s 2302 tx/s 64 Mgas/s 0+ 7476 Qed #2166040 25/25 peers 6 MiB chain 100 MiB db 55 MiB queue 19 MiB sync RPC: 1 conn, 12 req/s, 32 µs
2017-12-19 12:00:52 UTC Syncing #2160982 c978…5f4b 243 blk/s 2445 tx/s 70 Mgas/s 0+ 5310 Qed #2166294 25/25 peers 5 MiB chain 100 MiB db 36 MiB queue 20 MiB sync RPC: 1 conn, 13 req/s, 32 µs
2017-12-19 12:01:02 UTC Syncing #2163741 342a…c1f9 273 blk/s 1836 tx/s 53 Mgas/s 0+ 2583 Qed #2166327 25/25 peers 4 MiB chain 100 MiB db 19 MiB queue 25 MiB sync RPC: 1 conn, 14 req/s, 32 µs
====================
stack backtrace:
0: 0x7ff704834812 - hid_error
1: 0x7ff704834cf3 - hid_error
2: 0x7ff70406b124 -
3: 0x7ff7049a5544 - hid_error
4: 0x7ff7049a53b9 - hid_error
5: 0x7ff7049a5292 - hid_error
6: 0x7ff7049a5200 - hid_error
7: 0x7ff7049ae86f - hid_error
8: 0x7ff7041ef8b1 -
9: 0x7ff7042c1bff -
10: 0x7ff704199f3d -
11: 0x7ff70419fdea -
12: 0x7ff7049a69d2 - hid_error
13: 0x7ff7041efa46 -
14: 0x7ff7049a33dc - hid_error
15: 0x7fff4f0a1fe4 - BaseThreadInitThunk
Thread 'IO Worker #0' panicked at 'DB flush failed.: "Corruption: block checksum mismatch"', src\libcore\result.rs:906
This is a bug. Please report it at:
https://github.com/paritytech/parity/issues/new
====================
stack backtrace:
0: 0x7ff704834812 - hid_error
1: 0x7ff704834cf3 - hid_error
2: 0x7ff70406b124 -
3: 0x7ff7049a5544 - hid_error
4: 0x7ff7049a53b9 - hid_error
5: 0x7ff7049a5292 - hid_error
6: 0x7ff7049a5200 - hid_error
7: 0x7ff7049ae86f - hid_error
8: 0x7ff7041ef8b1 -
9: 0x7ff7042c1bff -
10: 0x7ff704199f3d -
11: 0x7ff70419fdea -
12: 0x7ff7049a69d2 - hid_error
13: 0x7ff7041efa46 -
14: 0x7ff7049a33dc - hid_error
15: 0x7fff4f0a1fe4 - BaseThreadInitThunk
Thread 'IO Worker #2' panicked at 'DB flush failed.: "Corruption: block checksum mismatch"', src\libcore\result.rs:906
This is a bug. Please report it at:
https://github.com/paritytech/parity/issues/new
====================
stack backtrace:
0: 0x7ff704834812 - hid_error
1: 0x7ff704834cf3 - hid_error
2: 0x7ff70406b124 -
3: 0x7ff7049a5544 - hid_error
4: 0x7ff7049a53b9 - hid_error
5: 0x7ff7049a5292 - hid_error
6: 0x7ff7049a5200 - hid_error
7: 0x7ff7049ae86f - hid_error
8: 0x7ff7041ef8b1 -
9: 0x7ff7042c1bff -
10: 0x7ff704199f3d -
11: 0x7ff70419fdea -
12: 0x7ff7049a69d2 - hid_error
13: 0x7ff7041efa46 -
14: 0x7ff7049a33dc - hid_error
15: 0x7fff4f0a1fe4 - BaseThreadInitThunk
Thread 'IO Worker #1' panicked at 'DB flush failed.: "Corruption: block checksum mismatch"', src\libcore\result.rs:906
This is a bug. Please report it at:
https://github.com/paritytech/parity/issues/new
====================
stack backtrace:
0: 0x7ff704834812 - hid_error
1: 0x7ff704834cf3 - hid_error
2: 0x7ff70406b124 -
3: 0x7ff7049a5544 - hid_error
4: 0x7ff7049a53b9 - hid_error
5: 0x7ff7049a5292 - hid_error
6: 0x7ff7049a5200 - hid_error
7: 0x7ff7049ae86f - hid_error
8: 0x7ff7041ef8b1 -
9: 0x7ff7042c1bff -
10: 0x7ff704199f3d -
11: 0x7ff70419fdea -
12: 0x7ff7049a69d2 - hid_error
13: 0x7ff7041efa46 -
14: 0x7ff7049a33dc - hid_error
15: 0x7fff4f0a1fe4 - BaseThreadInitThunk
Thread 'IO Worker #3' panicked at 'DB flush failed.: "Corruption: block checksum mismatch"', src\libcore\result.rs:906
This is a bug. Please report it at:
https://github.com/paritytech/parity/issues/new
I have been able to sync in the past week, but today it has stopped and crashes immediately once it reaches the final few blocks. I have tried manually deleting the blockchain and using "db kill" to no avail. Any help would be appreciated.
Expected behaviour is parity will sync and not force close.
This is reproducable by launching parity and letting it sync.
I have tried deleting all parity related files, registry keys and uninstalling using the uninstaller. I am attempting a fresh install on a seperate pc.
 The-Raa
The-Raa
All 30 comments
@The-Raa Could you please scan your hard drive for issues? It looks like a hardware issue to me.
 tomusdrw
on 27 Dec 2017
tomusdrw
on 27 Dec 2017
Might be related to #7424 #7279 #7088 #7087 #7029 #6974 #6960 #6905 #6798 #6790 #6670 #6506 #6501 #5837 #3634 #3432 #2830 #2640 #2603 #763
 5chdn
on 2 Jan 2018
5chdn
on 2 Jan 2018
I have run fsck.ext4 after the last failure of the bug #7424, it said everything was ok.
 aleksey-makarov
on 2 Jan 2018
aleksey-makarov
on 2 Jan 2018
I'm having the same issues. SSD seems ok.
 Canalytic
on 2 Jan 2018
Canalytic
on 2 Jan 2018
This is what I get with a custom-built parity. I hope it will help.
[amakarov@lemon parity]$ cargo run --release
Finished release [optimized] target(s) in 0.2 secs
Running `target/release/parity`
2018-01-02 22:50:00 Starting Parity/v1.9.0-unstable-6a0111361-20180102/x86_64-linux-gnu/rustc1.22.1
2018-01-02 22:50:00 Keys path /home/amakarov/.local/share/io.parity.ethereum/keys/Foundation
2018-01-02 22:50:00 DB path /home/amakarov/.local/share/io.parity.ethereum/chains/ethereum/db/906a34e69aec8c0d
2018-01-02 22:50:00 Path to dapps /home/amakarov/.local/share/io.parity.ethereum/dapps
2018-01-02 22:50:00 State DB configuration: fast
2018-01-02 22:50:00 Operating mode: active
2018-01-02 22:50:00 Configured for Foundation using Ethash engine
2018-01-02 22:50:00 Updated conversion rate to Ξ1 = US$874.55 (136124430 wei/gas)
2018-01-02 22:50:15 Removed existing file '/home/amakarov/.local/share/io.parity.ethereum/jsonrpc.ipc'.
2018-01-02 22:50:19 Public node URL: enode://b554c00a3c59c6d712c06b4b0b10e937fe6a62cf8aa326ba97c05d73991a4453df9b05a04261f6f06a370d97510ea194475b09af7e2652684a2e7bbcba7d1426@192.168.0.4:30303
====================
stack backtrace:
0: 0x559d86fc496c - backtrace::backtrace::trace::h7024916dde8198e6
1: 0x559d86fc49a2 - backtrace::capture::Backtrace::new::h2e2a8c2e72401209
2: 0x559d86428468 - panic_hook::panic_hook::h0d200da102196326
3: 0x559d870234ea - std::panicking::rust_panic_with_hook::hf6217f2eaf058be5
4: 0x559d87023334 - std::panicking::begin_panic::h1d02da2b82a54ae9
5: 0x559d870232a5 - std::panicking::begin_panic_fmt::ha745e93a6afd4c9d
6: 0x559d8702323a - rust_begin_unwind
7: 0x559d87067740 - core::panicking::panic_fmt::h664ef1a8778c7464
8: 0x559d867a0255 - core::result::unwrap_failed::h558f3b79b5fae4f7
9: 0x559d86887f44 - <ethcore::client::client::Client as ethcore::client::traits::BlockChainClient>::import_block_with_receipts::h4d4e5d7e83d6114e
10: 0x559d8662d0f5 - ethsync::block_sync::BlockDownloader::collect_blocks::hf241a97aed01279c
11: 0x559d86612224 - ethsync::chain::ChainSync::collect_blocks::hd946072d3a639b9f
12: 0x559d8661ff16 - ethsync::chain::ChainSync::on_packet::h426978ea997fd758
13: 0x559d86612d8a - ethsync::chain::ChainSync::dispatch_packet::h41868434f0a6a560
14: 0x559d86636ffa - <ethsync::api::SyncProtocolHandler as ethcore_network::NetworkProtocolHandler>::read::hc90cde87e3b34095
15: 0x559d866d24fe - <ethcore_network::host::Host as ethcore_io::IoHandler<ethcore_network::host::NetworkIoMessage>>::stream_readable::hce03b188e6a73b65
16: 0x559d866ae295 - std::sys_common::backtrace::__rust_begin_short_backtrace::h7abe0f6562909006
17: 0x559d866aeb76 - std::panicking::try::do_call::haf5373e803834c21
18: 0x559d870291db - __rust_maybe_catch_panic
Thread 'IO Worker #3' panicked at 'DB flush failed.: Error(Msg("Corruption: block checksum mismatch"), State { next_error: None, backtrace: None })', src/libcore/result.rs:906
This is a bug. Please report it at:
https://github.com/paritytech/parity/issues/new
Aborted (core dumped)
Log from a dev [unoptimized + debuginfo] build:
stack backtrace:
0: 0x5622bae501a5 - backtrace::backtrace::libunwind::trace
at /home/amakarov/.cargo/registry/src/github.com-1ecc6299db9ec823/backtrace-0.3.3/src/backtrace/libunwind.rs:53
1: 0x5622bae4558b - backtrace::backtrace::trace<closure>
at /home/amakarov/.cargo/registry/src/github.com-1ecc6299db9ec823/backtrace-0.3.3/src/backtrace/mod.rs:42
2: 0x5622bae4336f - backtrace::capture::{{impl}}::new_unresolved
at /home/amakarov/.cargo/registry/src/github.com-1ecc6299db9ec823/backtrace-0.3.3/src/capture.rs:88
3: 0x5622bae432ce - backtrace::capture::{{impl}}::new
at /home/amakarov/.cargo/registry/src/github.com-1ecc6299db9ec823/backtrace-0.3.3/src/capture.rs:63
4: 0x5622b8358d17 - panic_hook::panic_hook
at panic_hook/src/lib.rs:53
5: 0x5622b835a568 - core::ops::function::Fn::call<fn(&std::panicking::PanicInfo),(&std::panicking::PanicInfo)>
at /build/rust/src/rustc-1.22.1-src/src/libcore/ops/function.rs:73
6: 0x5622baf980aa - std::panicking::rust_panic_with_hook::hf6217f2eaf058be5
7: 0x5622baf97ef4 - std::panicking::begin_panic::h1d02da2b82a54ae9
8: 0x5622baf97e65 - std::panicking::begin_panic_fmt::ha745e93a6afd4c9d
9: 0x5622baf97dfa - rust_begin_unwind
10: 0x5622bafdc3f0 - core::panicking::panic_fmt::h664ef1a8778c7464
11: 0x5622b95b373e - core::result::unwrap_failed<kvdb::Error>
at /build/rust/src/rustc-1.22.1-src/src/libcore/macros.rs:23
12: 0x5622b958f443 - core::result::{{impl}}::expect<(),kvdb::Error>
at /build/rust/src/rustc-1.22.1-src/src/libcore/result.rs:799
13: 0x5622b9716e38 - ethcore::client::client::{{impl}}::import_old_block
at ethcore/src/client/client.rs:647
14: 0x5622b972cfbe - ethcore::client::client::{{impl}}::import_block_with_receipts
at ethcore/src/client/client.rs:1648
15: 0x5622b8b6f97b - ethsync::block_sync::{{impl}}::collect_blocks
at sync/src/block_sync.rs:499
16: 0x5622b8b2bd70 - ethsync::chain::{{impl}}::collect_blocks::{{closure}}
at sync/src/chain.rs:1341
17: 0x5622b8b4e236 - core::option::{{impl}}::map_or<&mut ethsync::block_sync::BlockDownloader,bool,closure>
at /build/rust/src/rustc-1.22.1-src/src/libcore/option.rs:421
18: 0x5622b8b2bb6d - ethsync::chain::{{impl}}::collect_blocks
at sync/src/chain.rs:1341
19: 0x5622b8b21cec - ethsync::chain::{{impl}}::on_peer_block_receipts
at sync/src/chain.rs:876
20: 0x5622b8b38366 - ethsync::chain::{{impl}}::on_packet
at sync/src/chain.rs:1765
21: 0x5622b8b373c1 - ethsync::chain::{{impl}}::dispatch_packet
at sync/src/chain.rs:1745
22: 0x5622b8b72d5e - ethsync::api::{{impl}}::read
at sync/src/api.rs:330
23: 0x5622b8e5eb9d - ethcore_network::host::{{impl}}::session_readable
at util/network/src/host.rs:937
24: 0x5622b8e6083e - ethcore_network::host::{{impl}}::stream_readable
at util/network/src/host.rs:1044
25: 0x5622b8ec004d - ethcore_io::worker::{{impl}}::do_work<ethcore_network::host::NetworkIoMessage>
at /home/amakarov/home/parity/util/io/src/worker.rs:111
26: 0x5622b8ec0641 - ethcore_io::worker::{{impl}}::work_loop<ethcore_network::host::NetworkIoMessage>
at /home/amakarov/home/parity/util/io/src/worker.rs:101
27: 0x5622b8ebfd39 - ethcore_io::worker::{{impl}}::new::{{closure}}<ethcore_network::host::NetworkIoMessage>
at /home/amakarov/home/parity/util/io/src/worker.rs:79
28: 0x5622b8ec5f37 - std::sys_common::backtrace::__rust_begin_short_backtrace<closure,()>
at /build/rust/src/rustc-1.22.1-src/src/libstd/sys_common/backtrace.rs:134
29: 0x5622b8f418ed - std::thread::{{impl}}::spawn::{{closure}}::{{closure}}<closure,()>
at /build/rust/src/rustc-1.22.1-src/src/libstd/thread/mod.rs:400
30: 0x5622b8f192e7 - std::panic::{{impl}}::call_once<(),closure>
at /build/rust/src/rustc-1.22.1-src/src/libstd/panic.rs:296
31: 0x5622b8e683cf - std::panicking::try::do_call<std::panic::AssertUnwindSafe<closure>,()>
at /build/rust/src/rustc-1.22.1-src/src/libstd/panicking.rs:480
32: 0x5622baf9dd9b - __rust_maybe_catch_panic
Thread 'IO Worker #1' panicked at 'DB flush failed.: Error(Msg("Corruption: block checksum mismatch"), State { next_error: None, backtrace: None })', src/libcore/result.rs:906
This is a bug. Please report it at:
https://github.com/paritytech/parity/issues/new
Aborted (core dumped)
We’ve encountered the same issue on multiple machines running on ssd drives too
 mtbitcoin
on 3 Jan 2018
mtbitcoin
on 3 Jan 2018
I also experienced a db corruption issue on a running Parity node during the last days (dedicated server hardware, SSD disk):
2017-12-17 09:52:56 Imported #4747626 445d…7292 (102 txs, 6.33 Mgas, 118.20 ms, 18.83 KiB)
thread 'Verifier #0' panicked at 'DB flush failed.: "Corruption: block checksum mismatch"', /checkout/src/libcore/result.rs:906:4
 peterbitfly
on 4 Jan 2018
peterbitfly
on 4 Jan 2018
Do we have to wait for 1.9 to have this fixed? I can sync in light mode, but then I don't seem to have access to any tokens or Dapp interaction, so not really ideal for my uses.
Im tempted to try on a new SSD but it seems there are already users who experience this issue across multiple SSDs
`====================
stack backtrace:
0: 0x55faca61da1c -
Thread 'Verifier #0' panicked at 'Low-level database error. Some issue with your hard disk?: "Corruption: Snappy not supported or corrupted Snappy compressed block contents"', /checkout/src/libcore/result.rs:906
`
Canalytic
on 5 Jan 2018
The error Corruption: block checksum mismatch is thrown by RocksDB, it's own checksums failed for a given block (database block) so this points to some kind of hardware failure that is causing the corruption, but since there are many people with this error it may be a RocksDB bug? (https://github.com/facebook/rocksdb/blob/master/HISTORY.md)
 andresilva
on 5 Jan 2018
andresilva
on 5 Jan 2018
I always close these type of reports as "hardware failure", but the recent spike of reports indicates some other issues. Also, users were checking their devices and couldn't find any indicators for hardware issues.
5chdn
on 5 Jan 2018
The issue can be reproduced more frequently on the latest release by killing the daemon without doing a proper shutdown. Didn’t see this so often on 1.7.10
I don’t think it’s hardware related as we encountered this running on different azure instances and various different bare metal servers all running enterprise level ssd/nvme drives
mtbitcoin
on 5 Jan 2018
killing the daemon without doing a proper shutdown
@mtbitcoin did you experience it when doing proper shtudown as well? Perhaps some db tuning in recent versions increased the amount of data that needs to be synchronized to disk, that would explain why it happens more often now.
Seems more like a db-synchronization-on-shutdown issue then.
tomusdrw
on 5 Jan 2018
@tomusdrw I cannot say for sure. We run a lot of nodes that get auto-restarted. But i did notice that with 1.7.11 it happened more often and normally after a restart. Then again it could have been the monitoring service restarting the node because it had already crashed.
We've moved to "graceful" shutdowns vs a task kill and haven't seen much of this anymore.
mtbitcoin
on 5 Jan 2018
Might be related to the segfault on shutdown. Can't find the related ticket.
5chdn
on 5 Jan 2018
@mtbitcoin How do you execute a "graceful" shutdown?
Canalytic
on 6 Jan 2018
Or any one have specs I'd need to run on a cloud somewhere? Or be patient and wait for 1.9?
Canalytic
on 7 Jan 2018
@Canalytic CTRL-C
mtbitcoin
on 7 Jan 2018
Is there any update on a solution to this bug report. I have the same issue as most all in this thread.
Been watching here for a few days and decided to post my same issues are reported above. (see attached screen shot) "Corruption: block checksum mismatch"', src\libcore\result.RS:860
I'm stuck... can't get parity to run.
Thanks for any new found workarounds.
 Scyle
on 7 Jan 2018
Scyle
on 7 Jan 2018
Screen capture: documenting my issue above...
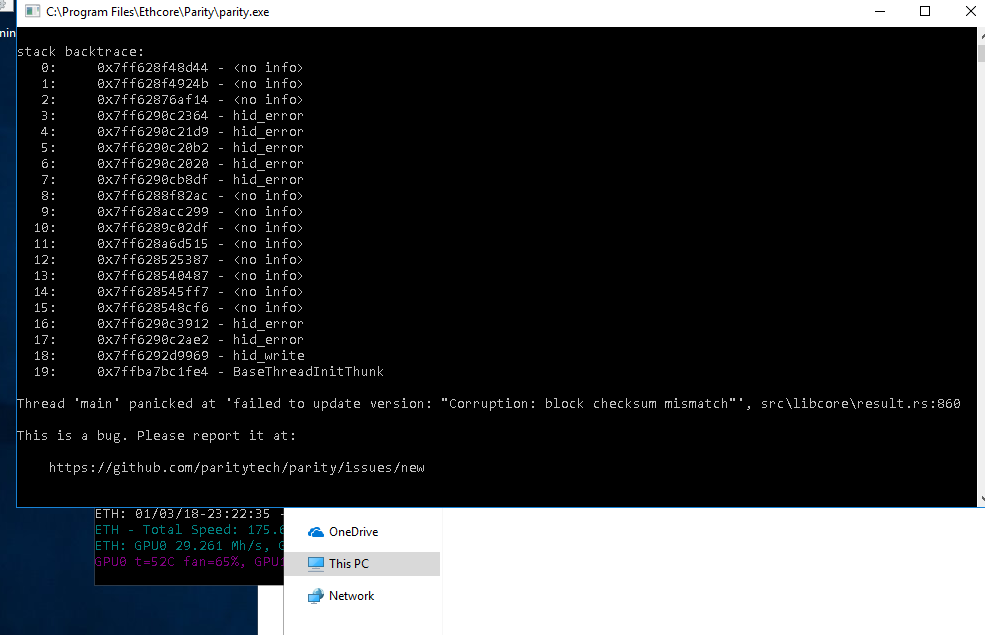
Scyle
on 7 Jan 2018
I've been struggling with this problem for a few weeks now. I'd like to share some of my experiences in the hope it helps other users, and also maybe find a fix for 1.9.
Currently, I have a synced chain. I achieved this, after getting many block checksum mismatch errors, by
- db kill
- parity --min-peers=100 --ntp-servers=pool.ntp.org:123
It took about a day to sync. I would feel satisfied, but I have already been through this about 3 or 4 times since the middle of December. @mtbitcoin mentioned doing 'graceful shutdown'. But even shutting down this way it seems that whenever Parity is stopped--for whatever reason--the DB becomes corrupted somehow and the only way to start again without the block checksum mismatch errors is from the begin of a fresh warp restore.
Canalytic
on 8 Jan 2018
I also encounter similar issue. Maybe downgrading rocksdb would help? I didn't experience this kind of error few months before.
 miningpoolhub
on 10 Jan 2018
miningpoolhub
on 10 Jan 2018
If it's any help, I encountered this error about 1h after freshly warping with 1.8.5 beta.
It seems it occurred after the peer count ran low (possibly I had some network issues).
https://gist.github.com/danuker/ec350847ca0ce7784d1183b8147ffecf
However, after restarting warp with 1.8.6 beta, it didn't happen (at least the first time).
 danuker
on 10 Jan 2018
danuker
on 10 Jan 2018
I have the same issue, I'm using 1.8.6-stable. I'm subscribing to this topic.
 vn-linescode
on 18 Jan 2018
vn-linescode
on 18 Jan 2018
We only try to repair the DB when we get a corruption error on open, maybe we should check all the calls to RocksDB for corruption and trigger a repair?
andresilva
on 18 Jan 2018
Built from the nightly tag last night (since it includes #7630), still getting these issues. Restarted after each panic, and the database is unable to repair itself.
Last night's attempt:
2018-01-20 07:05:59 Syncing #1350017 b7fa…0b43 0 blk/s 0 tx/s 0 Mgas/s 0+ 0 Qed #48896 25/25 peers 68 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 07:06:09 Syncing #1350017 b7fa…0b43 0 blk/s 0 tx/s 0 Mgas/s 0+ 0 Qed #56896 25/25 peers 68 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 07:06:19 Syncing #1350017 b7fa…0b43 0 blk/s 0 tx/s 0 Mgas/s 0+ 0 Qed #31874 24/25 peers 68 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 07:06:29 Syncing #1350017 b7fa…0b43 0 blk/s 0 tx/s 0 Mgas/s 0+ 0 Qed #41669 25/25 peers 68 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 07:06:39 Syncing #1350017 b7fa…0b43 0 blk/s 0 tx/s 0 Mgas/s 0+ 0 Qed #49019 25/25 peers 68 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 07:06:49 Syncing #1350017 b7fa…0b43 0 blk/s 0 tx/s 0 Mgas/s 0+ 0 Qed #56385 25/25 peers 68 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 07:06:59 Syncing #1350017 b7fa…0b43 0 blk/s 0 tx/s 0 Mgas/s 0+ 0 Qed #31362 23/25 peers 68 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 07:07:09 Syncing #1350017 b7fa…0b43 0 blk/s 0 tx/s 0 Mgas/s 0+ 0 Qed #36676 25/25 peers 68 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 07:07:19 Syncing #1350017 b7fa…0b43 0 blk/s 0 tx/s 0 Mgas/s 0+ 0 Qed #46070 25/25 peers 68 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 07:07:24 DB corrupted: Corruption: block checksum mismatch: expected 3341071380, got 443762524 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/004527.sst offset 31430898 size 16220. Repair will be triggered on next restart
2018-01-20 07:07:54 22/25 peers 68 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
... (repeats) ...
2018-01-20 07:22:19 24/25 peers 69 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 07:22:24 DB corrupted: Corruption: block checksum mismatch: expected 3341071380, got 443762524 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/004527.sst offset 31430898 size 16220. Repair will be triggered on next restart
2018-01-20 07:22:54 24/25 peers 69 MiB chain 45 MiB db 0 bytes queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
Followed by many more status messages and the occasional repeat of the "DB corrupted" message.
It did not crash at this point, but it stopped syncing and never resumed. I killed it manually this morning, since it had been running all night.
Upon restarting:
2018-01-20 13:26:36 DB corrupted: Invalid argument: You have to open all column families. Column families not opened: col5, col2, col4, col3, col1, col6, col0, attempting repair
Client service error: Client(Database(Error(Msg("Received null column family handle from DB."), State { next_error: None, backtrace: None })))
After running a parity db kill (and removing the cache and network folders), I tried to sync again this morning:
2018-01-20 14:37:32 Syncing #1419047 bb01…9f3d 331 blk/s 1805 tx/s 57 Mgas/s 830+ 5485 Qed #1425369 25/25 peers 57 MiB chain 48 MiB db 40 MiB queue 9 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 14:37:39 DB corrupted: Corruption: block checksum mismatch: expected 889423786, got 3252001621 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/010719.sst offset 0 size 24327. Repair will be triggered on next restart
2018-01-20 14:37:39 DB corrupted: Corruption: block checksum mismatch: expected 889423786, got 3252001621 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/010719.sst offset 0 size 24327. Repair will be triggered on next restart
2018-01-20 14:37:39 DB corrupted: Corruption: block checksum mismatch: expected 889423786, got 3252001621 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/010719.sst offset 0 size 24327. Repair will be triggered on next restart
2018-01-20 14:37:39 DB corrupted: Corruption: block checksum mismatch: expected 889423786, got 3252001621 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/010719.sst offset 0 size 24327. Repair will be triggered on next restart
====================
====================
stack backtrace:
0: 0x5571be03c86c - backtrace::backtrace::trace::h4497974251674b52
1: 0x5571be03c8a2 - backtrace::capture::Backtrace::new::hd361c6773a0e5990
2: 0x5571bd5ef139 - panic_hook::panic_hook::h6d90389c628a1a2b
Thread 'IO Worker #1' panicked at 'DB flush failed.: Error(Msg("Corruption: block checksum mismatch: expected 889423786, got 3252001621 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/010719.sst offset 0 size 24327"), State { next_error: None, backtrace: None })', /checkout/src/libcore/result.rs:906
This is a bug. Please report it at:
https://github.com/paritytech/parity/issues/new
Upon restarting:
2018-01-20 16:21:57 DB corrupted: Invalid argument: You have to open all column families. Column families not opened: col6, col5, col2, col4, col1, col3, col0, attempting repair
Client service error: Client(Database(Error(Msg("Received null column family handle from DB."), State { next_error: None, backtrace: None })))
I've been experiencing these corruption issues for a while now, through many upgrades (was on 1.8.6 until last night), with both HDD and SSD (with appropriate settings in config.toml), and even after replacing the memory in the server this is running on.
I'm attempting to run a full archive sync from scratch, with transaction tracing enabled. Relevant section of config.toml that reflects the current setup:
[footprint]
tracing = "on"
pruning = "archive"
fat_db = "on"
db_compaction = "ssd"
cache_size = 1024
Prior to this I've changed the cache_size and db_compaction settings, the latter after switching to an SSD
Third attempt:
2018-01-20 17:18:30 Syncing #1373112 644f…07b6 303 blk/s 1580 tx/s 54 Mgas/s 373+ 5777 Qed #1379273 25/25 peers 51 MiB chain 46 MiB db 40 MiB queue 13 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 17:18:36 Syncing #1375202 d80e…523c 418 blk/s 1979 tx/s 84 Mgas/s 533+ 4075 Qed #1379902 25/25 peers 52 MiB chain 46 MiB db 31 MiB queue 14 MiB sync RPC: 0 conn, 0 req/s, 0 µs
2018-01-20 17:18:43 DB corrupted: Corruption: block checksum mismatch: expected 2198576243, got 1032024108 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/002678.sst offset 369423 size 7229. Repair will be triggered on next restart
2018-01-20 17:18:43 DB corrupted: Corruption: block checksum mismatch: expected 2198576243, got 1032024108 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/002678.sst offset 369423 size 7229. Repair will be triggered on next restart
2018-01-20 17:18:43 DB corrupted: Corruption: block checksum mismatch: expected 2198576243, got 1032024108 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/002678.sst offset 369423 size 7229. Repair will be triggered on next restart
2018-01-20 17:18:43 DB corrupted: Corruption: block checksum mismatch: expected 2198576243, got 1032024108 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/002678.sst offset 369423 size 7229. Repair will be triggered on next restart
====================
stack backtrace:
0: 0x55ec22c7386c - backtrace::backtrace::trace::h4497974251674b52
1: 0x55ec22c738a2 - backtrace::capture::Backtrace::new::hd361c6773a0e5990
2: 0x55ec22226139 - panic_hook::panic_hook::h6d90389c628a1a2b
Thread 'IO Worker #1' panicked at 'DB flush failed.: Error(Msg("Corruption: block checksum mismatch: expected 2198576243, got 1032024108 in parity/chains/ethereum/db/906a34e69aec8c0d/archive/db/002678.sst offset 369423 size 7229"), State { next_error: None, backtrace: None })', /checkout/src/libcore/result.rs:906
This is a bug. Please report it at:
https://github.com/paritytech/parity/issues/new
After restarting:
2018-01-20 19:27:21 DB corrupted: Invalid argument: You have to open all column families. Column families not opened: col5, col6, col1, col4, col2, col0, col3, attempting repair
Client service error: Client(Database(Error(Msg("Received null column family handle from DB."), State { next_error: None, backtrace: None })))
 DeviateFish-2
on 21 Jan 2018
DeviateFish-2
on 21 Jan 2018
@DeviateFish-2 thanks for confirming, we were already suspecting something like this. but we are not out of ideas yet :)
cc @andresilva
5chdn
on 22 Jan 2018
I have found a possible source of database corruption, we're not shutting down cleanly. I'm working on a fix.
andresilva
on 24 Jan 2018
any updates on a fix yet?
On Wed, Jan 24, 2018 at 2:03 PM, André Silva notifications@github.com
wrote:
I have found a possible source of database corruption, we're not shutting
down cleanly. I'm working on a fix.—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/paritytech/parity/issues/7334#issuecomment-360272297,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AdW5mgPW5necJa0_zGNjl8-_Vb6on0uzks5tN5qPgaJpZM4RG9dx
.
Scyle
on 3 Feb 2018
Yeah upgrade to 1.9.2
5chdn
on 5 Feb 2018
Related issues
 barakman
·
3Comments
barakman
·
3Comments
 retotrinkler
·
3Comments
retotrinkler
·
3Comments
 jacogr
·
4Comments
jacogr
·
4Comments
 m-thomson
·
3Comments
m-thomson
·
3Comments
 jordipainan
·
3Comments
jordipainan
·
3Comments
Most helpful comment
I have found a possible source of database corruption, we're not shutting down cleanly. I'm working on a fix.