Pandoc is a memory hog.
https://groups.google.com/d/msg/pandoc-discuss/l6Xo0xk8NAQ/1KCKPyc2BgAJ
Do some profiling to figure out why and fix this.
 jgm
jgm
All 29 comments
These tests are with a 143K input file.


Note that the Markdown writer is much more memory-hungry than the HTML writer:


jgm
on 19 Oct 2016
In case you want to profile with other inputs, for panflute I searched github for large md files, and collected some of them:
These files have a diverse source of elements, and some have maybe 100,000k elements (I used them to profile panflute as it was a bit slow)
 sergiocorreia
on 19 Oct 2016
sergiocorreia
on 19 Oct 2016
This might be useful:
https://hackage.haskell.org/package/weigh
jgm
on 18 Nov 2016
Case Bytes GCs Check
Pandoc document 107,672 0 OK
markdown reader 116,843,688 227 OK
html reader 85,325,688 165 OK
docbook reader 61,925,288 119 OK
latex reader 58,609,584 114 OK
commonmark reader 3,053,696 5 OK
markdown writer 15,704,536 30 OK
html writer 6,776,128 13 OK
docbook writer 12,567,392 24 OK
latex writer 7,387,296 14 OK
commonmark writer 3,315,184 6 OK
There's a file when using pandoc -s -o -t md causes a strange behavior: Selected Hymns.docx. This file was obtained from a PDF source and used an online service to be converted to docx.
The strange behavior is this: while processing with a ton of CPU and memory usage, the resultant md file is just a newline character.
 ickc
on 20 Dec 2016
ickc
on 20 Dec 2016
The strange behavior is this: while processing with a ton of CPU and memory usage
I tried to open it with Word 2016 on Windows on a newish laptop, and gave up after a minute or so. Then I renamed it and opened the zip, and from the look of it the document seems like a mess (word/document.xml seems pretty garbled).
So this might be a problem with Word and not with Pandoc per se...
sergiocorreia
on 20 Dec 2016
I recall the Word 2016 for Mac has a similar behavior too. I now suspect the online converter actually get it wrong and returns an invalid (or a valid but really bad) docx.
The conversion is not important for me. But it is still puzzling to see it spend a ton of CPU and memory and time to render it, but results in an empty file with no debug message.
ickc
on 20 Dec 2016
As a checkpoint, here's the current result of make weigh:
Case Allocated GCs
Pandoc document 106,024 0
markdown reader 136,916,240 262
html reader 113,248,608 220
docbook reader 61,625,792 119
latex reader 92,679,280 179
commonmark reader 2,236,664 4
markdown writer 20,798,712 40
html writer 12,345,760 23
docbook writer 15,275,296 29
latex writer 19,628,304 37
commonmark writer 2,282,488 4
Mostly things have gotten worse as a result of changes since November 2016.
This needs looking into.
jgm
on 19 Jun 2017
Trying to convert this (75 MB) file makes my computer run out of memory (my computer has 16 GB): https://github.com/PerseusDL/lexica/blob/master/CTS_XML_TEI/perseus/pdllex/lat/ls/lat.ls.perseus-eng1.xml
It's not really a big deal, since pandoc probably wouldn't produce useable output for a TEI file of that sort (I was just interested in seeing what it results in), but the memory consumption seems surprising.
 ids1024
on 15 Sep 2017
ids1024
on 15 Sep 2017
Part of the problem here is that pandoc can write TEI but
not read it. So, depending on the options you used, pandoc
was trying to interpret this as some other xml format.
+++ Ian Douglas Scott [Sep 15 17 11:48 ]:
Trying to convert this (75 MB) file makes my computer run out of memory
(my computer has 16 GB):
[1]https://github.com/PerseusDL/lexica/blob/master/CTS_XML_TEI/perseus/
pdllex/lat/ls/lat.ls.perseus-eng1.xml
jgm
on 16 Sep 2017
Trying to convert this (75 MB) file makes my computer run out of memory (my computer has 16 GB): https://github.com/PerseusDL/lexica/blob/master/CTS_XML_TEI/perseus/pdllex/lat/ls/lat.ls.perseus-eng1.xml
It's not really a big deal, since pandoc probably wouldn't produce useable output for a TEI file of that sort (I was just interested in seeing what it results in), but the memory consumption seems surprising.
What's the command used? pandoc version and platform?
ickc
on 16 Sep 2017
I ran pandoc lexica/CTS_XML_TEI/perseus/pdllex/lat/ls/lat.ls.perseus-eng1.xml -o test.md using pandoc 1.19.2.1 on Arch Linux.
ids1024
on 16 Sep 2017
Interesting:
# pandoc v1.19.1
$ /usr/local/bin/time -v pandoc -t native lat.ls.perseus-eng1.xml -o lat.ls.perseus-eng1.native
pandoc: Stack space overflow: current size 33624 bytes.
pandoc: Use `+RTS -Ksize -RTS' to increase it.
Command exited with non-zero status 2
Command being timed: "pandoc -t native lat.ls.perseus-eng1.xml -o lat.ls.perseus-eng1.native"
User time (seconds): 253.71
System time (seconds): 6.41
Percent of CPU this job got: 99%
Elapsed (wall clock) time (h:mm:ss or m:ss): 4:20.51
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 53923790848
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 3291389
Voluntary context switches: 3
Involuntary context switches: 69123
Swaps: 0
File system inputs: 0
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 23635
Page size (bytes): 4096
Exit status: 2
# pandoc master at commit 5849b89
$ /usr/local/bin/time -v /Users/kolen/Downloads/pandoc-osx-5849b89/pandoc -t native lat.ls.perseus-eng1.xml -o lat.ls.perseus-eng1.native
pandoc: Stack space overflow: current size 33624 bytes.
pandoc: Use `+RTS -Ksize -RTS' to increase it.
Command exited with non-zero status 2
Command being timed: "/Users/kolen/Downloads/pandoc-osx-5849b89/pandoc -t native lat.ls.perseus-eng1.xml -o lat.ls.perseus-eng1.native"
User time (seconds): 4.34
System time (seconds): 0.58
Percent of CPU this job got: 99%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:04.94
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 6518554624
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 397980
Voluntary context switches: 4
Involuntary context switches: 530
Swaps: 0
File system inputs: 1
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 444
Page size (bytes): 4096
Exit status: 2
Note that the kbytes should be bytes above (a glitch of using GNU time on macOS). The interesting bit is that the current master reaches "Stack space overflow" at 4 s rather than 4 min.
ickc
on 16 Sep 2017
Pandoc assumes an xml file is docbook unless otherwise
specified. (And -f tei won't work, because TEI is not
a supported input format.)
+++ Ian Douglas Scott [Sep 16 17 03:49 ]:
I ran pandoc
lexica/CTS_XML_TEI/perseus/pdllex/lat/ls/lat.ls.perseus-eng1.xml -o
test.md using pandoc 1.19.2.1 on Arch Linux.
jgm
on 16 Sep 2017
Edit: my guess is wrong, see @jgm's reply a minute earlier than mine.
ickc
on 16 Sep 2017
See another instance of the same issue here.
Note that in this case using --trace prevented running out of memory. Perhaps forcing evaluation of the intermediate Block data structures helps?
jgm
on 3 Aug 2018
I have a background worker in my web app which uses pandoc through pandoc-ruby. Is there a way to configure pandoc to not exceed a certain amount of memory? A docx which is just 409kb is causing evictions on a pod which has 1GB of allocatable memory.
 archonic
on 28 May 2019
archonic
on 28 May 2019
Which OS, Linux?
ickc
on 28 May 2019
If Linux, try these:
https://thirld.com/blog/2012/02/09/things-to-remember-when-using-ulimit/
https://unix.stackexchange.com/questions/44985/limit-memory-usage-for-a-single-linux-process
ickc
on 28 May 2019
Currently slim but it will be alpine. Thanks @ickc!
archonic
on 28 May 2019
@archonic - If pandoc is compiled with -rtsopts (as it should be by default unless someone specifically turns this off), then you can specify the maximum heap size as follows:
pandoc +RTS -M30m -RTS -f markdown -t html MANUAL.txt
The +RTS -M30m -RTS sets max heap size to 40M. Max stack size defaults to 80% heap size.
jgm
on 28 May 2019
Awesome. If anyone else is looking for a way to limit memory usage through PandocRuby, just call this before convert:
PandocRuby.pandoc_path = "pandoc +RTS -M30m -RTS"
Is there any advice on debugging particularly heavy files? I've got a docx (which I unfortunately can't share). From what I can tell, it's a fairly "normal" file for a book — 700kb; 80,000 words; no tables; maths, images, etc.; minimal formatting; the occasional comment — but it needs something like 3GB of RAM to process.
We process lots of similar files with no issues, but for some reason this one falls over. Where's the best place to start looking for oddities?
I've produced this profile dump if that helps?
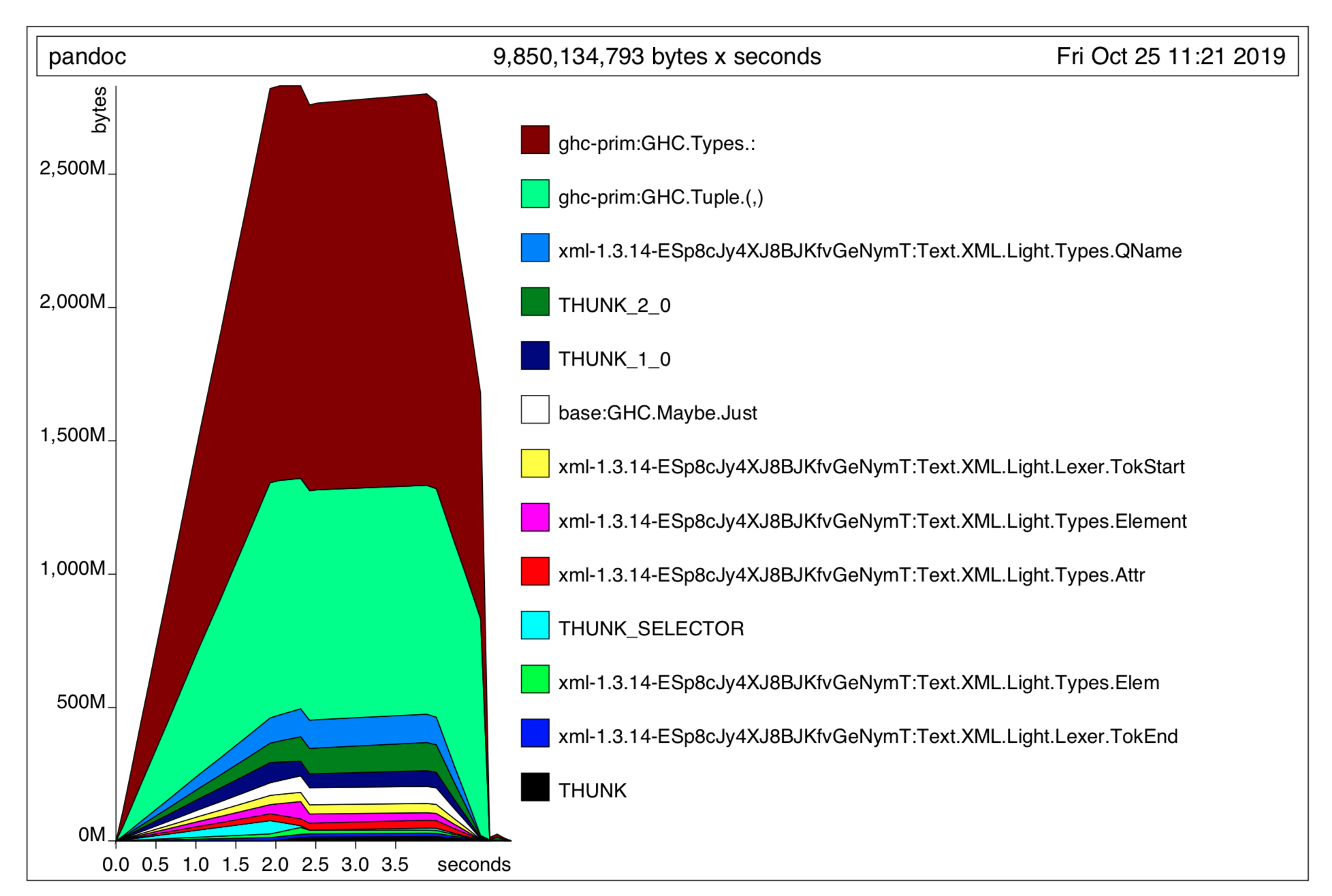
pandoc 2.7.2
Compiled with pandoc-types 1.17.5.4, texmath 0.11.2.2, skylighting 0.7.7
 alecgibson
on 25 Oct 2019
alecgibson
on 25 Oct 2019
Okay, actually I've had a rummage around in the docx, and its XML is full of repeated, redundant, nested styling. Every single word appears to be wrapped in its own styling like so:
<w:r w:rsidRPr="00074A08">
<w:rPr>
<w:rFonts w:ascii="Times New Roman" w:hAnsi="Times New Roman" w:cs="Times New Roman"/>
<w:color w:val="000000"/>
</w:rPr>
<w:t>without</w:t>
</w:r>
<w:r w:rsidR="00C734B2" w:rsidRPr="00074A08">
<w:rPr>
<w:rFonts w:ascii="Times New Roman" w:hAnsi="Times New Roman" w:cs="Times New Roman"/>
<w:color w:val="000000"/>
</w:rPr>
<w:t xml:space="preserve"></w:t>
</w:r>
<w:r w:rsidRPr="00074A08">
<w:rPr>
<w:rFonts w:ascii="Times New Roman" w:hAnsi="Times New Roman" w:cs="Times New Roman"/>
<w:color w:val="000000"/>
</w:rPr>
<w:t>backup.</w:t>
</w:r>
I'm assuming this is the issue? Is there any way to get Pandoc to be a bit smarter about this sort of thing?
alecgibson
on 25 Oct 2019
I've moved my issue into its own ticket: https://github.com/jgm/pandoc/issues/5854
alecgibson
on 25 Oct 2019
I have discovered that between 2.2.2.1 and 2.2.3.1 pandoc's performance on large documents degraded significantly, and is still degraded with 2.9.1.1.
I have a 1.9 MB, ~34,000-line .org file with many tables, verbatim blocks, and headers that go 5 levels deep (*****). Version 2.2.2.1 converts it to HTML in 5s and produces good output:
$ time ~/pandoc-2.2.2.1/bin/pandoc doc.org -f org -t html --standalone --self-contained --table-of-contents --template=./template.html > /tmp/output.html
5.06user 0.50system 0:05.57elapsed 99%CPU (0avgtext+0avgdata 617120maxresident)k
0inputs+3360outputs (0major+199662minor)pagefaults 0swaps
(The template is trivial, just $body$.)
The same command using 2.2.3.1 seems to hang. I interrupted it after fifteen minutes:
$ time ~/pandoc-2.2.3.1/bin/pandoc doc.org -f org -t html --standalone --self-contained --table-of-contents --template=./template.html > /tmp/output.html
^C917.02user 7.93system 15:25.14elapsed 99%CPU (0avgtext+0avgdata 3873808maxresident)k
0inputs+0outputs (0major+969548minor)pagefaults 0swaps
Note that it consumes 6x as much memory. 2.9.1.1 performs just as poorly (as do 2.3, 2.5, 2.7.3, etc. -- I basically did a binary search).
For all of these versions, I downloaded the *-linux.tar.gz (or similar) pre-built binary.
There aren't many commits between 2.2.2.1 and 2.2.3.1. Perhaps someone more familiar with the code might be able to see why the performance degraded?
 jsomers
on 6 Feb 2020
jsomers
on 6 Feb 2020
It's probably due to the changes in the org reader; @tarleb might have a clue.
jgm
on 6 Feb 2020
The only commit in that range which touched the org reader is 4e899eb9c886df2200551f69a3f593ab5258f2e2. It looks innocent, but memory leaks can be sneaky.
@jsomers, please open a separate issue for this and provide some test data which allows us to reproduce the issue.
 tarleb
on 6 Feb 2020
tarleb
on 6 Feb 2020
@tarleb Sounds good, I just opened https://github.com/jgm/pandoc/issues/6127. In producing a minimal repro case I found that it has to do with files having many _ characters on a single line.
jsomers
on 7 Feb 2020
Related issues
 danse
·
3Comments
danse
·
3Comments
 eins78
·
5Comments
eins78
·
5Comments
 krobelus
·
4Comments
krobelus
·
4Comments
 timtroendle
·
3Comments
timtroendle
·
3Comments
 elliottslaughter
·
4Comments
elliottslaughter
·
4Comments