Pandas: "cannot reindex from a duplicate axis" when groupby().apply() on MultiIndex columns
Code Sample, a copy-pastable example if possible
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.ones([6, 4], dtype=int),
columns=pd.MultiIndex.from_product([['A', 'B'], [1, 2]])
)
(
df
.groupby(level=0, axis=1)
.apply(
lambda df: pd.concat(
[df.xs(df.name, axis=1), df.sum(axis=1).to_frame('Total')],
axis=1
)
)
)
Problem description
The code above produces the error:
cannot reindex from a duplicate axis
I believe this is a bug because, as described below, essentially the same operations can be successfully run along the other axis.
Expected Output
It should, as far as I can tell, produce the following output:
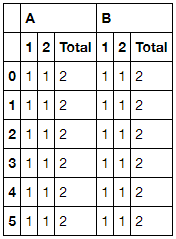
The desired output can be obtained when working on the transposed DataFrame along the index rather than the columns:
(
df
.T
.groupby(level=0)
.apply(
lambda df: pd.concat(
[df.xs(df.name), df.sum().to_frame('Total').T]
)
)
.T
)
Output of pd.show_versions()
pd.show_versions()
pd.show_versions()
INSTALLED VERSIONS
commit: None
python: 2.7.9.final.0
python-bits: 64
OS: Windows
OS-release: 8
machine: AMD64
processor: Intel64 Family 6 Model 69 Stepping 1, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
LOCALE: None.None
pandas: 0.20.2
pytest: None
pip: 9.0.1
setuptools: 34.3.3
Cython: None
numpy: 1.13.0
scipy: 0.19.0
xarray: None
IPython: 5.3.0
sphinx: None
patsy: None
dateutil: 2.6.0
pytz: 2017.2
blosc: None
bottleneck: None
tables: None
numexpr: None
feather: None
matplotlib: 2.0.0
openpyxl: None
xlrd: 1.0.0
xlwt: None
xlsxwriter: None
lxml: None
bs4: None
html5lib: 0.999
sqlalchemy: None
pymysql: None
psycopg2: 2.7.1 (dt dec pq3 ext lo64)
jinja2: 2.9.5
s3fs: None
pandas_gbq: None
pandas_datareader: None
 bdforbes
bdforbes
All 16 comments
I've just found a simpler MWE. This fails:
(
df
.groupby(level=0, axis=1)
.apply(
lambda df: 2*df.xs(df.name, axis=1)
)
)
This succeeds:
(
df.T
.groupby(level=0)
.apply(
lambda df: 2*df.xs(df.name)
)
)
this is very very odd to odd. what are you actually trying to do?
 jreback
on 9 Jun 2017
jreback
on 9 Jun 2017
for example your 'failing' ones:
Out[11]:
A [[1, 1, 2], [1, 1, 2], [1, 1, 2], [1, 1, 2], [...
B [[1, 1, 2], [1, 1, 2], [1, 1, 2], [1, 1, 2], [...
dtype: object
In [10]: (
...: df
...: .groupby(level=0, axis=1)
...: .apply(
...: lambda df: 2*df.xs(df.name, axis=1).values
...: )
...: )
Out[10]:
A [[2, 2], [2, 2], [2, 2], [2, 2], [2, 2], [2, 2]]
B [[2, 2], [2, 2], [2, 2], [2, 2], [2, 2], [2, 2]]
dtype: object
Makes no sense to do this. You can certainly iterate over the groups yourself and concat (though you will find exactly the same issue if you don't drop the indexes). By definition pandas wants to align return objects.
jreback
on 9 Jun 2017
I'm actually trying to adapt the code at https://stackoverflow.com/a/38964596/336001, which recursively adds subtotal rows into a DataFrame, to work along columns instead. Here is the original code, which adds subtotal rows:
def append_tot(df):
if hasattr(df, 'name') and df.name is not None:
xs = df.xs(df.name)
else:
xs = df
gb = xs.groupby(level=0)
n = xs.index.nlevels
name = tuple('Total' if i == 0 else '' for i in range(n))
tot = gb.sum().sum().rename(name).to_frame().T
if n > 1:
sm = gb.apply(append_tot)
else:
sm = gb.sum()
return pd.concat([sm, tot])
The adapted version to add subtotal columns looks like this:
def append_tot(df):
if hasattr(df, 'name') and df.name is not None:
xs = df.xs(df.name, axis=1)
else:
xs = df
gb = xs.groupby(level=0, axis=1)
n = xs.columns.nlevels
name = tuple('Total' if i == 0 else '' for i in range(n))
tot = gb.sum().sum(axis=1).rename(name).to_frame()
if n > 1:
sm = gb.apply(append_tot)
else:
sm = gb.sum()
return pd.concat([sm, tot], axis=1)
This code will produce the "cannot reindex from a duplicate index" error, whereas the original code provided in the Stack Overflow thread works fine.
The minimal working example I've found was just the simplest way to reproduce the error.
bdforbes
on 9 Jun 2017
I'm facing the same issue when trying to interpolate each series within a group:
>>> df = pd.DataFrame({
... 'node': [59, 59, 59, 314, 314, 314, 59],
... 'ping': [116, np.nan, 106, 87, 80, np.nan, 118],
... 'mode': ['2G', np.nan, '4G', '3G', np.nan, '3G', '2G']},
... columns=['node', 'ping', 'mode'],
... index=pd.to_datetime(['2017-07-13 00:30:00',
... '2017-07-13 00:30:00',
... '2017-07-13 00:30:00',
... '2017-07-13 00:30:00',
... '2017-07-13 01:00:00',
... '2017-07-13 01:00:00',
... '2017-07-13 01:00:00']))
>>> df
node ping mode
2017-07-13 00:30:00 59 116.0 2G
2017-07-13 00:30:00 59 NaN NaN
2017-07-13 00:30:00 59 106.0 4G
2017-07-13 00:30:00 314 87.0 3G
2017-07-13 01:00:00 314 80.0 NaN
2017-07-13 01:00:00 314 NaN 3G
2017-07-13 01:00:00 59 118.0 2G
>>> def interpolator(series): # ffill for categoricals, linear otherwise
... if series.dtype == object:
... return series.ffill()
... return series.interpolate()
>>> df.groupby('node').apply(lambda subdf: subdf.apply(interpolator))
---------------------------------------------------------------------------
ValueError: cannot reindex from a duplicate axis
Anything obvious?
Edit: It works, however, if I df.reset_index(inplace=True) before grouping.
 kernc
on 1 Sep 2017
kernc
on 1 Sep 2017
I never resolved my earlier problem, I managed to get around it by performing my operations along the other axis and transposing. It doesn't appear that your issue fits that pattern however.
bdforbes
on 2 Sep 2017
I have the same issue here. This seems to have something to do with index of the data frame. Please see the following example to reproduce the error:
data = pd.DataFrame({'x':[1,2,3],'y':[0,1,0]}, index=[0,0,1])
data.groupby(by='y').apply(lambda u: u)
Error: ValueError: cannot reindex from a duplicate axis
However, the following code which only differs by one element in the index will execute without producing the error:
data = pd.DataFrame({'x':[1,2,3],'y':[0,1,0]}, index=[0,1,1])
data.groupby(by='y').apply(lambda u: u)
Note that the only change is the index of the second row.
python 3.5
pandas 0.20.3
 dayuhuang
on 5 Oct 2017
dayuhuang
on 5 Oct 2017
I think you can just set the index in this case (this is internally where the error happens), rather than re-index, as its a transformation. PR's welcome.
jreback
on 6 Oct 2017
Duplicate of https://github.com/pandas-dev/pandas/issues/19437 (that's for duplicate index, this is for duplicate columns with axis=1). Should be the same fix.
 TomAugspurger
on 31 Jan 2018
TomAugspurger
on 31 Jan 2018
@kernc Thank you thank you for the amazing workaround!
i.e.
It works, however, if I df.reset_index(inplace=True) before grouping.
 jtlz2
on 16 May 2018
jtlz2
on 16 May 2018
@TomAugspurger I'm not sure this was actually fixed along with #19437, I'm seeing the same issue on 1.0.1:
[nav] In [62]: data = pd.DataFrame({'x':[1,2,3],'y':[0,1,0]}, index=[0,0,1])
...: data.groupby(by='y').apply(lambda u: u)
---------------------------------------------------------------------------
...
~/model/.venv/lib/python3.7/site-packages/pandas/core/indexes/base.py in _can_reindex(self, indexer)
3097 # trying to reindex on an axis with duplicates
3098 if not self.is_unique and len(indexer):
-> 3099 raise ValueError("cannot reindex from a duplicate axis")
3100
3101 def reindex(self, target, method=None, level=None, limit=None, tolerance=None):
ValueError: cannot reindex from a duplicate axis
If I understand the above comments correctly it seems that this should still be considered a bug (as opposed to unsupported behavior), right?
 bnaul
on 13 Mar 2020
bnaul
on 13 Mar 2020
Yeah, seems to not be a duplicate.
TomAugspurger
on 20 Mar 2020
take
 smithto1
on 28 Jul 2020
smithto1
on 28 Jul 2020
Thanks, the fix in #35441 appears to work.
To test it, I installed pandas 1.1.0 in a virtual environment and manually patched the lines in core/groupby/ops.py following #35441. Is there an easier way to test a PR that has just gone into master? Do I have to clone the repo and build it from scratch? I'm on Windows and I haven't tried this before.
bdforbes
on 8 Aug 2020
@bdforbes If you follow the instructions on website, it's not too hard.
https://pandas.pydata.org/docs/development/contributing.html#creating-a-python-environment
There is an hour or two to set up a C-compiler, git etc, but after that you can clone the repo and work current master/PR branches.
smithto1
on 8 Aug 2020
Thanks @smithto1, the instructions look pretty clear.
bdforbes
on 9 Aug 2020
Related issues
 jaradc
·
3Comments
jaradc
·
3Comments
 mfmain
·
3Comments
mfmain
·
3Comments
 Ashutosh-Srivastav
·
3Comments
Ashutosh-Srivastav
·
3Comments
 ebran
·
3Comments
ebran
·
3Comments
 Abrosimov-a-a
·
3Comments
Abrosimov-a-a
·
3Comments
Most helpful comment
I'm facing the same issue when trying to interpolate each series within a group:
Anything obvious?
Edit: It works, however, if I
df.reset_index(inplace=True)before grouping.