Package-maintenance: Suggestion: Provide standards around integrity between source code and published package
Right now, it seems that most maintainers may publish their packages from their local environment. There should be a way to verify what is published against the public source code or specific git sha to maintain transparency of what is being published. Not only will this mitigate out of sync issues or accidents, but will provide greater confidence that additions aren't added as they are published (potentially malicious).
Not sure if this is the best place for this, but after reading through other issues and recent resources I thought I better put this down somewhere. And it brings up the discussion of maintainers permissions to not only package registry, but SCM as well.
 shaunwarman
shaunwarman
All 85 comments
npm doesn’t require a repo, and any package with a prepublish build process (read: every Babel user) will correctly have the published package not matching any sha in their git repo.
I’m not sure how we’d be able to do any sort of verification in a consistent and automated way.
 ljharb
on 10 Dec 2018
ljharb
on 10 Dec 2018
The only way to guarantee this is to compute an hash of all the content of a module (in prepublish) and cryptographically sign it. However, there is no easy way to know:
a. what are the keys that are allowed to sign a given package
b. associate those keys with npm profiles
People have been asking for a similar feature to npm for the last 2-3 years.
 mcollina
on 11 Dec 2018
mcollina
on 11 Dec 2018
Thanks @ljharb @mcollina and sorry for the late reply.
This article by @skonves gave me a nice reminder of this topic. And it seems like there are tools in his tbv and another in npm-verified that attempt to do similar.
There would need to be a _blessed_, yet optional process to add some sort of "trusted": true || false or "verified": true || false metadata that npm or other package managers would need to set. Optional because of the common cases of transpiled code (e.g. babel, etc) and because this is an expensive task with trade offs.
shaunwarman
on 9 Jan 2019
My 1 cent out of 2 (don't have time for more): npm doesn't require a repo, but a package verification service on top of npm might require whatever is needed, and package authors that want to conform and get the "verified" badge will try and make sure their package is good. For example there are similar efforts to standardize open source repositories: https://github.com/todogroup/repolinter — there could be tools that help package authors to manage packages efficiently (I personally miss the kind of tool that would automatically set up CI and releases for me reproducibly and reliably).
 sompylasar
on 9 Jan 2019
sompylasar
on 9 Jan 2019
Indeed, that’s something npm can solve - but i don’t think it’s something node, and thus we, can.
ljharb
on 9 Jan 2019
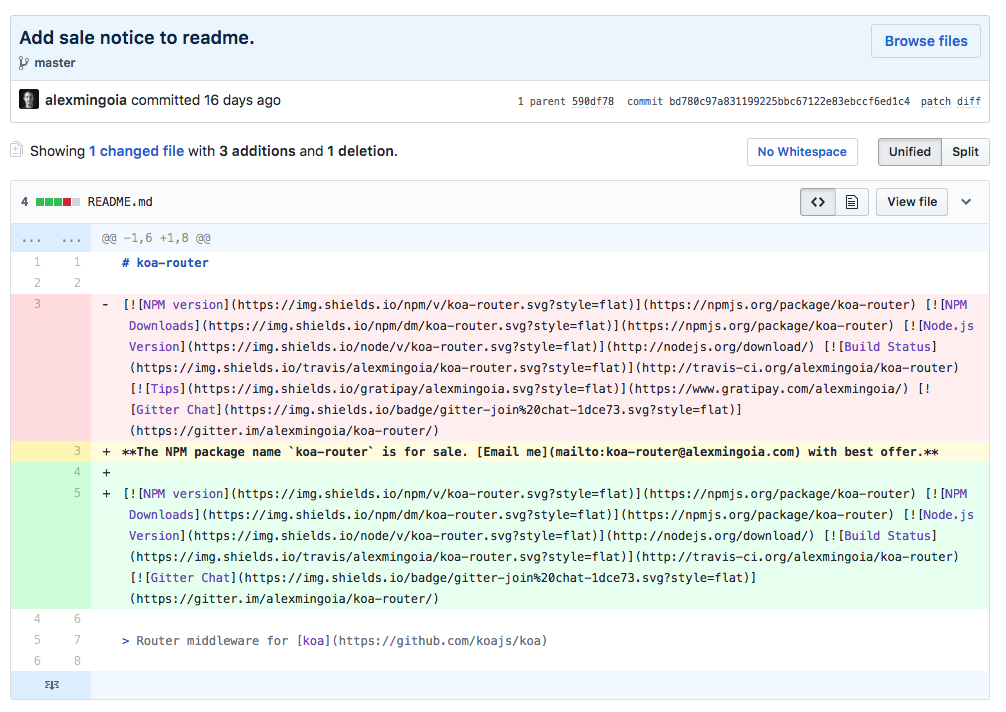
Chiming in here, we really need something like this... koa-router was just transferred to a relatively unknown user on GitHub and the package name was apparently sold
Screenshot (in case commit is force deleted):
I've version locked koa-router, which is downloaded 135K+ times per week, and subscribed on https://libraries.io/npm/koa-router to get a notification when a new version is published of this package.
 niftylettuce
on 13 Feb 2019
niftylettuce
on 13 Feb 2019
@niftylettuce i'd suggest reporting that to npm; i doubt their TOS permits the sale of a package name.
ljharb
on 13 Feb 2019
I did report that to NPM, and here was there response...

I also reached out to the author of the package koa-router and received a very negative response which I don't wish to share publicly out of respect since I see no malicious version of the package published yet.
niftylettuce
on 13 Feb 2019
@niftylettuce You did the right thing here even if nothing negative comes of it. Its a red flag for sure and others deserve to be alerted by this information. Good job on being alert.
 justinmchase
on 13 Feb 2019
justinmchase
on 13 Feb 2019
To anyone reading this, I'm building a tool to automate this nonsense, at least until Node/NPM do something about it. Email me at [email protected] if you want to get notified once it's up. I'll notify everyone that posted in this thread and/or left reactions as well. It will be free and open-source.
niftylettuce
on 13 Feb 2019
Maybe it's time to think to an NPM alternative.
 Enrico204
on 13 Feb 2019
Enrico204
on 13 Feb 2019
What's more, even if npm validated against the git repo at publish time, the user can just force push after publication. Checking this kind of thing does nothing.
If you want to validate at install time, well, I hope you enjoy your multi-hour install times. =p (Seriously: In modern npm or yarn, install time per package is under 10ms—adding a git clone to that mix would massively increase overall run time.)
This kind of action gets you no security whatsoever. It solves no actual problem. It validates nothing.
 iarna
on 14 Feb 2019
iarna
on 14 Feb 2019
@iarna what do you think about a new command for npm, I've been thinking about a npm diff that you would be able to use while upgrading a package to see actual changes. Haven't thought about it super deep, but npm update or npm install mypkg@latest followed by a npm diff or similar.
This would effectively allow you to review the code of new/updated packages, similar to how adding node_modules to version control would allow for deeper code reviews.
 freewil
on 14 Feb 2019
freewil
on 14 Feb 2019
@niftylettuce Hey, if you're going to work on a solution, it would be way better to start a repo on github, so people can contribute ideas/feedback via issues
 jaredhirsch
on 14 Feb 2019
jaredhirsch
on 14 Feb 2019
@freewil That seems much more useful, but I am concerned how you scale that out to the thousands of deps in a typical modern deployment. 'cause yeah, the one thing you asked for may have a reasonable diff, but what about the dozen transitive deps that also updated? Still, I think this would be an excellent place to begin experimenting with, to see how it feels (--dry-run --json can get you what an action would have done, in machine readable format).
iarna
on 14 Feb 2019
@6a68 yes it will be on GitHub, I will post the link here once I have a proof of concept up
niftylettuce
on 14 Feb 2019
To anyone reading this - please do not harass, email, or contact the original maintainer of the package mentioned in the above discussion. It was never my intention for anyone to harass them. I simply wanted to raise awareness about this issue with NPM and the potential of this becoming a security issue in general. This is not the only package like this.
niftylettuce
on 14 Feb 2019
Another update on the koa-router issue for anyone subscribed to this thread. The new maintainer @ZijianHe has provided us with an update https://github.com/ZijianHe/koa-router/issues/494#issuecomment-463468328. Hopefully this eases concern and it looks like we have a new contributor in open source land.
For the CLI npm diff command, would it just accept two different versions of a package? npm diff <package> <version-a> <version-b> and diff compare tarball?
niftylettuce
on 14 Feb 2019
Maybe the best "way" to handle the change of a maintainer is that the new maintainer should open its own repository on NPM. They should not allow a "takeover" procedure: instead, the installation may fails with a message like "hi, this library is not maintained anymore by olddev, there is a new version in newdev". At least the developer knows that there is something going on..
Enrico204
on 14 Feb 2019
I think the current way npm does this is by forcing a bump in a major release. That's enough to protect users form a malicious "takeover" in the case of a non-responsive maintainer.
mcollina
on 14 Feb 2019
I think the current way npm does this is by forcing a bump in a major release. That's enough to protect users form a malicious "takeover" in the case of a non-responsive maintainer.
Is that so? Any way to confirm?
 panva
on 14 Feb 2019
panva
on 14 Feb 2019
I've done this several time, and that's how it works. I looked in https://www.npmjs.com/policies/disputes but there is no mention about that.
mcollina
on 14 Feb 2019
They certainly don’t; and can’t, because a legitimate new maintainer should be able to backport fixes as needed anyways.
Any owner can always and forever publish to any previously unused version number, and that’s how it must stay.
ljharb
on 14 Feb 2019
@iarna
What's more, even if npm validated against the git repo at publish time, the user can just force push after publication. Checking this kind of thing does nothing.
I assume you assume the evil user force pushes to remove malicious code?
If such force push leads to file changes, git commit ids will change. Npm would record the commit id it verified against, and a standalone checksum of published files. If there's no such commit in the repo, it's a red flag. If running the same checksum at the same commit id files results in a different checksum, it's a red flag.
I believe this verification has to be a background task in npm; if one of the red flags has triggered, this package downloads are paused to prevent further spread until they are resolved. There has to be cache invalidation mechanism that would notify downstream caches to not use the flagged package.
I'm in no way a security expert though, just brainstorming. What do the npm security people that npm aquihired say?
sompylasar
on 14 Feb 2019
The way I experimented in npm-verified POC is I needed a standardized package build+publish process (I used npm prepare for that). The packages that conform to the process can be marked as verified if the checks pass. The packages that do not — never. Like in Chrome, the sites that do not use HTTPS are marked as "Not Secure" by default, and even more, colored in red if they collect some user input via a form (for npm, this can be translated to using some OS APIs like process, network, and filesystem).
sompylasar
on 14 Feb 2019
@niftylettuce
For the CLI
npm diffcommand, would it just accept two different versions of a package?npm diff <package> <version-a> <version-b>anddiffcompare tarball?
Yeah, I think that would be one version/use-case of the command. The way I'm currently thinking, it'd be nice to also have a no argument version similar to git diff where the current unstaged/uncommitted changes are shown, but that may be more complex than necessary for an initial version as it might require git/version control integration. I'd be hesitant in entangling npm with version control-specific code, but I think there is already a precedent with some commands - one that I'm aware of is npm version, which creates git tags for you.
freewil
on 14 Feb 2019
@freewil
but that may be more complex than necessary for an initial version as it might require git/version control integration.
One alternative to prevent the need for tracking changes/state would be just to add a --diff flag to npm install that would output a diff. That should be much easier since npm install already mutates package.json (which means it needs to/could be aware of the version change while running) and prevents needing to track changes/state across two commands, as I originally proposed (npm install followed by npm diff).
freewil
on 14 Feb 2019
@niftylettuce That'd be pretty keen! (We have an RFC for doing similar things with changelogs, and this feels like a comfortably related feature.)
@sompylasar
If such force push leads to file changes, git commit ids will change. Npm would record the commit id it verified against, and a standalone checksum of published files. If there's no such commit in the repo, it's a red flag. If running the same checksum at the same commit id files results in a different checksum, it's a red flag.
Again, when are you imagining these checks are being run? At publication time there's no point, and at install time that's still high overhead.
But that doesn't even get into my real issue with these proposals. Let's imagine that it's a practical change, that it can be done in a way that verifies, at install time, that the artifact matches some ref in the git repo, and that this can be done without slowing down installers so much that users refuse to use the feature.
This would try to encourage every publish to go to a publicly hosted git repo somewhere, but what do you imagine that would accomplish? That you can be certain that malicious code is on a git repo somewhere? Who does this help and how? What attack vector is closed by this that would otherwise be open? Users can inspect it sure, but they can inspect the tarball too, trivially, and tooling could be built around either of these equally easily, so how does having the source of inspection being some git repo help?
iarna
on 14 Feb 2019
^ misattributed quote fixed
freewil
on 14 Feb 2019
@freewil 🙃 Sorry, yes, fixed!
iarna
on 14 Feb 2019
Verifying packages against the repo is an expensive and inconclusive task - I'm not sure building that natively into standard npm is even feasible, but it would be nice to have. Similar to npm-verified, there is another PoC: https://www.npmjs.com/package/tbv.
That said, I do see value in providing these checks as a signal, perhaps as a paid feature.
Alternatively, they could be provided as a SaaS to those willing to pay.
While all it proves is that the package on npm can be built from the contents on git, that is a reasonable signal that it hasn't been tampered with due to e.g. infected computer which is used to publish. It also serves as a signal of certain best practices (eg reproducible builds) kept by the maintainer, therefore increasing trust in the package.
While it only adds so much trust, it's a valuable signal, and when used with other signals (eg was this published with 2fa? Does it use any risky APIs? Does it communicate with the outside? etc static analysis) can help people draw the line or spot oddities.
Looking at this proposal and dismissing it with "well, this is expensive and you're still unsafe" is an unfair statement, because security is not a single dimension with One Fix To Rule Them All. It takes a lot of work and multiple components to build up trust in external code.
 dominykas
on 14 Feb 2019
dominykas
on 14 Feb 2019
Alternatively, they could be provided as a SaaS to those willing to pay.
I actually already have TBV running in the cloud as verifynpm.com eg. https://api.verifynpm.com/packages/tbv or https://api.verifynpm.com/packages/[email protected]
I'm footing the bill for now (AWS free tier FTW!). All of the code for that service is open source: github.com/verifynpm.
Unfortunately, as the author of TBV, I didn't know about @sompylasar's work before I started. I was mostly trying to see what steps it would take to find added or modified files in a package that aren't the product of the source code or related build script. (Moral of the story: Google first, code later 😬)
Anyway, I think there are a few conclusions to make from the actual effort that some of us have been contributing in addition to what has been verbalized in this issue so far:
- The community wants a solution
- There is indeed a process that can verify if a package is a deterministic function of source control at a specific commit
- That process is potentially expensive (time, processing, cash money, etc)
- That process can produce false negatives for legitimate packages
- That commit may be revoked from source control at any time
- Removing that commit makes a previously verifiable package unverifiable
- There are multiple attack vectors besides the SCM => NPM publishing process
- The plurality of vectors doesn't invalidate the benifit of any single solution
- This conversation needs to continue 😃
As the maintainer of the verifynpm API, I would love to get some code review on what I have built so far. I appreciate the sceptisism surrounding this topic, but the presence of multiple tools (that actually exist) indicates that it IS possible. I suggest that we steer the conversation toward poking holes in existing solutions (both Ivan Babak's and mine) so that we can start engineering solutions. Issues and PRs welcome :+1:
Cheers!
Steve
 skonves
on 15 Feb 2019
skonves
on 15 Feb 2019
RE: npm --diff, a year or so ago I put together "npmspy" to compare the code changes between package dependency trees. It was powered by loading the entirety of npm into a graph and which was fronted with an API. It's all kinda gross and broken. It was a bear to manage back when npm was only 500k packages. That's double now and I don't have the bandwidth (or funding) to work on the project anymore.
Feel free to read/use/steal/finish the code:
https://github.com/skonves/npmspy
https://github.com/skonves/npmspy-data
skonves
on 15 Feb 2019
@skonves I checked out https://github.com/verifynpm/tbv but before I dig into the code, it'd be great to understand what the project actually does and what problems it's meant to solve. All I get from the readme is that it does package verification, without explaining what that actually means.
freewil
on 15 Feb 2019
@iarna
This would try to encourage every publish to go to a publicly hosted git repo somewhere, but what do you imagine that would accomplish? That you can be certain that malicious code is on a git repo somewhere? Who does this help and how? What attack vector is closed by this that would otherwise be open? Users can inspect it sure, but they can inspect the tarball too, trivially, and tooling could be built around either of these equally easily, so how does having the source of inspection being some git repo help?
The first attack vector being closed is the possibility of adding malicious code to the package without pushing it to source control. The community can review the source all day long, but will never find it. This is one of the exploits in David Gilbertson's hypothetical attack.
The second attack vector being closed is the possibility of compromised npm credentials/token being enough to compromise a package. If the contents of the package must be reproducible from source control to publish, then an attacker would have to gain access to both the npm AND Github account to push malicious code. Such a process would have actually prevented the eslint-scope attack from last year. In that case, the attacker gained access to one set of tokens and then used them to publish a version of eslint-scope that stole the tokens for other packages. Github accounts were never compromised.
It is currently possible to inspect the tarball, but from my personal perspective, there are a few reasons why reviewing source control is a more optimal solution.
- Reviewing a tarball requires that you review the entire corpus of code. Reviewing source control allows the reviewer to focus on a certain range of commits/changes.
- Packages often contain transpiled and/or minified code. This code is generally more challenging to read and thus review.
- Github et al provide tooling for code review which lends more context to a change than manually diffing the contents of tarballs.
skonves
on 15 Feb 2019
@freewil
TL;DR "verification" is the process of verifying whether the contents of a package can be reliably reproduced from source control.
I have written a little bit about the problem so far:
What if we could verify npm packages?
NPM Package Verification — Ep. 2
I make some clarifications in this thread: https://twitter.com/chrisdlangton/status/1092927031392624640
I have at least one other article in the works that will (hopefully) better describe the problem that it solves and why the solution is needed.
skonves
on 15 Feb 2019
Can't you compare two tarballs, and get the same ability to look at diffs?
ljharb
on 15 Feb 2019
Thanks @skonves the work you're doing in the space is great. While iarna is right in theory, it's still extremely valuable just knowing "X was built by commit Y". This puts a malicious package maintainer in an awkward spot deciding between putting the malicious code in source-control (where it's more likely to be seen) or published the "wrong" commit (where it's trivial for someone to notice).
By no means will it fix the security nightmare that is npm, it goes a long way to hardening it.
 RHavar
on 15 Feb 2019
RHavar
on 15 Feb 2019
The first attack vector being closed is the possibility of adding malicious code to the package without pushing it to source control.
How is this an attack vector? Differences between the two are not a vulnerability. I've seen the article you linked, I just don't find it very convincing, or, frankly, interesting. It's juuust a step above saying "if you type sudo rm -rf / you'll destroy your system, so Unix is insecure".
The second attack vector being closed is the possibility of compromised npm credentials/token being enough to compromise a package.
2fa is vastly more effective mechanism for this. Making 2fa status visible of published modules (and allowing one to say "I will only accept 2fa verified publishes of package updatges") would more neatly solve this, without the entirely impractical performance hit of doing install-time git clones of every module you install. (Because if you want to verify that a particular committish exists on any public git repo, remember, means cloning the repo. No one is mandated to use github... there was that whole exodus to gitlab back when MS purchased them and believe it or not, people and projects run their own git servers as well. No solution that just leaves modules from those users in the cold is going to be acceptable. You don't actually even have to use git.)
iarna
on 15 Feb 2019
How is this an attack vector? Differences between the two are not a vulnerability.
It's not a vulnerability per se, but it's definitely an attack vector. It's yet another possible way to hide malicious code. This isn't even purely theoretical, it has been used in the past in a sophisticated attacks (see: event-stream) and it will be used in the future.
For almost all npm libraries, there is a lot more scrutiny that happens to the source repo than what is actually deployed to npm. A lot of libraries I have investigated are deploying non-reproducible minified code to npm, there's simply no way it's getting audited -- yet every commit is scrutinized closely.
If npm did the sane thing and showed how/where it was built, it would generally get noticed pretty fast if a release is derived from a weird repo state. If they don't care about getting noticed too fast, they could latch onto the other insane behavior of npm to run scripts at install time (with no warning / opt-in).
@ljharb If you're going to edit my grammar, please do so correctly. It would have made a lot more sense to replace "he" with "iarna" or "she" than "they" when I'm clearly referring to a single person. (And my apologies to iarna about using the wrong pronoun, I only saw the small profile picture and didn't realize I was speaking to a "Rebecca").
Another simple feature for npmjs.com that would help (although obviously not be a silver bullet) is adding a "source viewer" for people to browse the code. It's kind of ridiculous you have to go to a special url and unzip a tarball just to review what 'npm install pkg" is going to do
RHavar
on 15 Feb 2019
@rhavar “they” is and has always been grammatically correct to refer to a single person; you’re welcome to correct my correction.
ljharb
on 15 Feb 2019
Are you aware of https://unpkg.com where you can view any version of any npm package?
ljharb
on 15 Feb 2019
my bias is showing 😬
Please interpret "Github" to mean "your favorite online git repository." I have yet to actually try Gitlab, but it sounds nice.
skonves
on 15 Feb 2019
@ljharb Thanks for that. I wasn't aware of that site, it's very cool. Something like that just hosted by npmjs.com would help make it more accessible. I fixed your edit, but for future reference: it is generally a lot more productive to talk to the person in private (i.e. my email is in my profile) instead of showboating and adversarial edits of someone else's comment.
RHavar
on 15 Feb 2019
@rhavar there was no showboating achieved or intended, but i apologize for not contacting you first.
ljharb
on 15 Feb 2019
RE: unpkg, making a source viewer into npmjs.com itself is impractical, but adding links pointing to unpkg.com from a package page might be easy and useful for manual reviews.
Anyway, at modern node_modules scale manually reviewing every dependent package change by every consumer of a package would be highly impractical. There have to be centralized and potentially automated way to make it hard and impractical to add malicious code.
sompylasar
on 15 Feb 2019
@iarna
entirely impractical performance hit of doing install-time git clones of every module you install.
This is a strawman.
npm (or whoever implements it) does not have to do it at install time (it can do it on scheduled time and publish the result, re-verify occasionally, log the last verification time, have a manual trigger for paid users, etc)
npm client, can then use that information at install time to either warn, or, based on configuration, cancel the build, if the package can no longer be considered "verified". There are multiple layers that people use for security, and there are multiple different levels of security requirements.
There is a large spectrum between "I can use this because it has a reproducible build from 3 months ago" and "I can only use this when my compliance team allows it" and "I can use this, because I don't have compliance requirements and my threat model does not need to care".
Making 2fa status visible of published modules (and allowing one to say "I will only accept 2fa verified publishes of package updates")
YES, PLEASE 😍 Been dreaming about this for ages :)
would more neatly solve this
Somewhat, yes. For one, you can't 2fa in CI (there's going to be a solution soon, btw; in userland...) But also I'd postulate that 2fa has less usage than GitHub+Travis (ie reproducible builds) in the community. I'd love to see some data on this, though! (hint hint, can npm's chief data officer help?)
Reproducible, verifiable builds, though, serve as an independent verification factor. Anything that helps - helps.
Mind you that while reproducible builds are by far not a security silver bullet, they also are an indicator of package quality, which helps when trying to pick one.
You don't actually even have to use git.
This is a strawman.
Just because you can't verify _all_ the packages, you can still verify _some_ (most?), and that subset of _some_ may be enough for some people. If you can verify 80% of packages you use this way, then the remaining 20% need other mechanisms - which can also be built and enforced (or you can fork and do whatever else).
I really truly deeply love npm, but I find it frustrating that these ideas are getting thrown out without even bothering to attempt to _do_ anything about it, while not offering anything better.
dominykas
on 15 Feb 2019
I have several packages that are different in their tar.gz compared to what is actually released. If you need to ship a bundled version of an app, or a .min.js file, you might not want to commit those to your repository. I do not think verifying the matching between the content of an npm package and a repo improve security.
mcollina
on 15 Feb 2019
@mcollina The verification method discussed above would compare the package build+pack output from source at certain commit marked with a version tag with the published package contents at the same version. Not with the source itself.
sompylasar
on 15 Feb 2019
@mcollina The verification method discussed above would compare the package build+pack output from source at certain commit marked with a version tag with the published package contents at the same version. Not with the source itself.
That does not guarantee anything if the package is not built with a lockfile in place. The output will certainly differs.
mcollina
on 15 Feb 2019
That does not guarantee anything if the package is not built with a lockfile in place. The output will certainly differs.
Yes, that's why I'm talking about being able to mark as verified only the packages that conform to a package build process and maintenance convention (there can be more than one supported).
sompylasar
on 15 Feb 2019
I would be strongly opposed to any certification that required packages to have lockfiles.
ljharb
on 15 Feb 2019
@ljharb
I would be strongly opposed to any certification that required packages to have lockfiles.
Would you be opposed to reproducible builds from source at a commit?
I understand that package lockfiles do not lock the surrounding environment and you may produce a different build having a different version of Node.js for example, but they at least pin down the most dynamic part of it, the node_modules dependencies.
sompylasar
on 15 Feb 2019
Since it would take a lockfile to achieve that, yes.
ljharb
on 15 Feb 2019
@ljharb
Since it would take a lockfile to achieve that, yes.
This is a very strong opinion background of which isn't clear to me. Please elaborate.
What are the other ways you can think of to achieve the reproducible builds from source if not lockfiles?
Which ways of verifying package integrity and lack of injected malicious code do you think of?
sompylasar
on 15 Feb 2019
Reproducible builds are critically important for apps; I don't find any value in that for packages. The artifact (the tarball) is the reproducible part; if i want to make another build it'll be a new version, so there's no reason it needs to precisely match the previous one.
ljharb
on 15 Feb 2019
My understanding is that there are a few opposing schools of thought concerning committing lock files.
Perspective 1
The presence of a lock file in a package's repository doesn't influence the dependency tree once the package is installed.
If the package developer (let's call her Grace) uses a lock file, then Grace will see a certain dependency tree. When another developer (let's call him Martin) installs the package, the installation process does not respect the lock file, meaning that he will see a potentially different dependency tree. (This is known good behavior and I won't jump into the rationale here.) Stated differently, the lock file only locks dependencies on the developers (Grace's) machine, but not for consumers (Martin, et al).
From this perspective, the lock file doesn't provide value to consumers and could potentially even create confusion around what will be installed. This is a good argument for not including the lock file.
Examples: https://github.com/expressjs/express
Perspective 2
Lock files control the specific dev dependencies that are used during the build process and thus control the artifacts within the package.
For projects that require a build script, if the package developer (Grace) doesn't use a lock file, then build output may vary between installs. With a lock file, running npm ci prior to running the build script guarantees that the output of the build is deterministic for a given set of source code. When installed by a consumer (Martin), the build output is now just static files contained within the package, dev dependencies are not installed, that the latest allowed production dependencies are installed.
From this perspective, the lock file provides consistency to the build process. Grace or a CI system (let's call him Travis 😄) can run npm ci then npm run build and get deterministic results. In this case, the lock file does provide value and thus should be committed, even though it doesn't affect the dependency tree in Martin's application.
Example: https://github.com/reduxjs/redux
My current opinion
Based on these two perspectives, I don't think every repo needs a lock file because based on the nature of the repo it may or may not provide value. That being said, the "missing-ness" of a lock file shouldn't cast shade on the legitimacy of a package.
Right now, the TBV tool makes its first attempt at packing the code without installing deps. For packages like express that works great :+1:. For packages like redux, pack can't run because the prepare script needs to run babel's rollup. This is where it runs npm ci to ensure that it has the same dev dependencies as when originally published. This is also where TBV currently fails with react because that repo doesn't have a lock file.
What I hadn't previously considered was to just run npm i in the absence of a lock file (instead of ci) in an attempt to recreate the build artifacts with the latest allowed dev dependencies.
...if the package developer doesn't use a lock file, then build output may vary between installs.
I hadn't considered the case where it doesn't.
skonves
on 15 Feb 2019
@ljharb @sompylasar
Perhaps we should establish the Code Law of Identity; If you build the same code twice it should have the same end result.
You don't have to publish your lock file but you should probably have it in your repo so that from the perspective of any given packages codebase it produces identical builds from identical source.
Perhaps if npm just accepted an optional git commit hash during publication then 3rd parties (including npm possibly) could verify that the package respects the law of identity by checking out that commit and re-building the code. You could then provide a guarantee to downstream consumers that the code they are pulling is precisely what is committed in github.
From there an optional flag or command could be added to npm that would produce errors or warnings if packages are pulled that aren't flagged by npm to have been verified, or perhaps they are not pulled at all until they are flagged as being identical. Some wouldn't care about this but some might.
This would allow us to have some assurances that the code we are pulling from npm is both publicly visible and matches what was published.
There's no known way to prove code isn't malicious in an automated way (yet) but given a foundation of opennes and identity, we could then possibly establish a level of confidence based on some other facts about the committed code, such as if it was reviewed first, if it triggered CI, if there were any issues associated with it, independent audit, etc.
No matter how we handle it we'll probably have to always be diligent and rely on community but that is part of the principles of open source. What we can automate and prove, we should try to do when possible. It will help increase confidence and quality.
justinmchase
on 15 Feb 2019
@skonves Thank you for describing the two perspectives!
@justinmchase Yes, thank you, we're on the same page here.
sompylasar
on 15 Feb 2019
@ljharb
Reproducible builds are critically important for apps; I don't find any value in that for packages. The artifact (the tarball) is the reproducible part; if i want to make another build it'll be a new version, so there's no reason it needs to precisely match the previous one.
In fact another build from the same code (which without semantic-release automation contains a version, and the commit being published also most likely has a version tag) is another build of the same version, but not another version. In semver there's sometimes a separate fourth field called build number which describes that (see e.g. Chrome version).
sompylasar
on 15 Feb 2019
Inbefore, I understand that npm prohibits publishing the same version twice, if that's what you were referring as a new version @ljharb
sompylasar
on 15 Feb 2019
The lock file does not have to live in a commit, nor does it have to live inside the tar. It is trivial to automate publishing it as part of GH release artifacts. This means that you have it, in case you need it, but you don't force it onto your contributors or users (and yes, I have little love for lockfiles myself, but we do keep them around for when we need to patch production, in a similar way as I described here, ie not affecting npm installs, unless explicitly needed).
Is that something a lot of maintainers will do? Probably not. Is that something the folks in this fine maintenance WG can help with? Definitely. Are reproducible builds something that businesses would be interested in? I think so, if that can be provided without overheads. So I think it's in scope and moves towards goals of this WG?
I think there's a lot of ways to solve the original problem stated in the topic of this thread. I'm very happy to see userland attempts. Maybe we need a break here, as part of this WG, and let these attempts move forward, maybe invent some competing ideas, and bring them back to build a standard and a recommendation.
It is very clear that there is interest in this, and there is value in this in at least some contexts, so I'm honestly surprised at the opposition. What are the _downsides_ of establishing such a standard?
dominykas
on 15 Feb 2019
Myself and a lot of other maintainers with a huge numbers of packages think lockfiles are a bad idea for modules. I hope this clarifies our position: https://github.com/sindresorhus/ama/issues/479#issuecomment-310661514.
mcollina
on 15 Feb 2019
lockfiles are a very good idea for applications, which is the high majority of users. However, they are not really the target of this initiative.
mcollina
on 15 Feb 2019
@mcollina this is not about lockfiles. I don't think they make sense as part of the package or part of the repo. They do make sense as a snapshot in time to achieve reproducible builds.
Once again - they should not be published on git or npm - only kept around as a convenient metadata format.
dominykas
on 15 Feb 2019
@dominykas package-lock is already not published on npm; it'd be fine to keep a lockfile around if it didn't constrain npm install, but the only way to do that would be to rename it and commit it to git.
That might be reasonable, however - a sort of package-release.json that you'd update in-place in git, and would effectively be npm install --package-lock-only --package-lock && mv package-{lock,release}.json right before publishing a release.
ljharb
on 15 Feb 2019
@ljharb that is also an option, but it depends on the toolchain. I've literally spent this week setting up semantic-release, because we have locked masters and therefore can't have version commits. This also means that we need to push release meta data outside of git repo. We also have a pattern where we push shrinkwraps into dangling tags (i.e. a shrinkwrap-X.Y.Z for every vX.Y.Z). Basically anything but master (or npm, for various reasons) :)
I wish npm had a way to store this, and some other, release meta data, but not necessarily distribute it with the package.
dominykas
on 16 Feb 2019
A possible solution to this problem (integrity between source code and published package) is to provide a "builder" service that take the source code, builds it, then publishes the output.
ZEIT Now is probably 80% of the way there because builds are immutable, every build has a unique URL, the source code is captured during the build process, and you don't need a repo to publish. But if you do have a repo, you can connect it to the build system so that pushing to master (or any branch) automatically publishes.
There's a couple changes that would need to be implemented in npm:
The first missing piece is some way to link the published npm package back to the builder source so that npm (and users) can verify integrity (probably add a field in the generated
package.json).The second missing piece is some sort of allow-list that npm uses to trust certain builders (if anyone could host their own builder service, they could circumvent this integrity).
The third piece is an optional flag that users can use to opt-in to this type of integrity check. Something like
npm install --builder-integritythat will stop with an error if any package is missing this new builder field in thepackage.jsonor the builder field is not in the allow-list.
 styfle
on 19 Feb 2019
styfle
on 19 Feb 2019
A possible solution to this problem (integrity between source code and published package) is to provide a "builder" service that take the source code, builds it, then publishes the output.
ZEIT Now is probably 80% of the way there because builds are immutable, every build has a unique URL, the source code is captured during the build process, and you don't need a repo to publish. But if you do have a repo, you can connect it to the build system so that pushing to master (or any branch) automatically publishes.
There's a couple changes that would need to be implemented in npm:
1. The first missing piece is some way to link the [published npm package](https://react-tsx.now.sh) back to the [builder source](https://react-tsx.now.sh/_src) so that npm (and users) can verify integrity (probably add a field in the generated `package.json`). 2. The second missing piece is some sort of _allow-list_ that npm uses to trust certain builders (if anyone could host their own builder service, they could circumvent this integrity). 3. The third piece is an optional flag that users can use to opt-in to this type of integrity check. Something like `npm install --builder-integrity` that will stop with an error if any package is missing this new builder field in the `package.json` or the builder field is not in the _allow-list_.
I was initially thinking the same thing.
But what stops someone from having a build task that inject malicious code into the "built package"?
Wouldn't a per module sandbox / permission system to protect against certain actions (Network, Disk Access, etc) help?
 Bene-Graham
on 19 Feb 2019
Bene-Graham
on 19 Feb 2019
@styfle
A possible solution to this problem (integrity between source code and published package) is to provide a "builder" service that take the source code, builds it, then publishes the output.
I was also thinking this. Basically the idea is to have a trusted third-party do the packaging from source.
Docker Hub might be a good place to look for inspiration. With Docker, it can be an even bigger issue, as docker images are built into binary files and pushed up to a public repository. Although, Dockerfiles/images are generally much more simple.
freewil
on 20 Feb 2019
But what stops someone from having a build task that inject malicious code into the "built package"?
There shouldn't be any user-provided build task code while using one of the trusted builders, only a build pipeline configuration, for example, like https://github.com/pikapkg/pack does.
Wouldn't a per module sandbox / permission system to protect against certain actions (Network, Disk Access, etc) help?
Yes, that, too, may increase confidence, and complexity. That is needed, too, but is orthogonal to this particular discussion about package build-from-source integrity.
sompylasar
on 20 Feb 2019
The build process itself needs to be able to contain user-written transforms, if it's babel, or a bundler, to support common and valid use cases.
ljharb
on 20 Feb 2019
The build process itself needs to be able to contain user-written transforms, if it's babel, or a bundler, to support common and valid use cases.
It doesn't if all the common and valid use cases like babel and bundler are standardized into trusted builders. I guess there should be either no way, or a hard and impractical way, to tamper with the executable content (e.g. JavaScript code) of a trusted build by providing a malicious build step.
But again, I'm not a security expert. I pinged the Node.js SecurityWG to take a look at this discussion as I think it is rather opitionated, not engineered as a document with clear sets of requirements, tradeoffs and solutions.
sompylasar
on 20 Feb 2019
It doesn't if all the common and valid use cases like babel and bundler are standardized into trusted builders
i think you missed a very important detail in the point you quoted:
contain user-written transforms
part of the valid use of babel is to apply custom transformations beyond those provided by babel itself or even official plugins. these are often included as devDependencies. locking down approved builders that didnt allow the inclusion of those custom transformations would eliminate a significant portion of the value of tools like this, but allowing them does allow for changes that would be difficult to ensure are not malicious.
 travi
on 20 Feb 2019
travi
on 20 Feb 2019
part of the valid use of babel is to apply custom transformations beyond those provided by babel itself or even official plugins. these are often included as
devDependencies. locking down approved builders that didnt allow the inclusion of those custom transformations would eliminate a significant portion of the value of tools like this, but allowing them does allow for changes that would be difficult to ensure are not malicious.
I'd like to see some data about how popular these are, and whether they can be standardized. They can be published as a trusted package that itself does not use them, thus building a chain of trust. I hear you, but there's always a tradeoff between security and convenience.
sompylasar
on 20 Feb 2019
@sompylasar packages are all already implicitly trusted; the attack vector i thought you're trying to address here is when a trusted package is hijacked, for which the same risks exist for any package, including ones in the build system.
ljharb
on 20 Feb 2019
@sompylasar packages are all already implicitly trusted; the attack vector i thought you're trying to address here is when a trusted package is hijacked, for which the same risks exist for any package, including ones in the build system.
Yeah I guess you're right. Well that's what I mentioned above. We all would benefit from a document (like an RFC) with the list of potential attack vectors, and how they are addressed or can be.
sompylasar
on 20 Feb 2019
I have actually already put together a draft of a graph of the NPM ecosystem for just that purpose. Each edge and vertex definitely has its own unique set of challenges. For the past few evenings, I have been working on a writeup, but I wouldn't mind opening it up for community feedback/contribution.
Here is the draft of the graph I have so far:

I have a draft on Medium right now, but I will move that to a more public place in a heartbeat if it means more eyes on it. Thoughts?
FWIW, my work with TBV/verifynpm and @sompylasar's similar work with npmverified seems reasonably confined to the "publishes to" edge near the top; however, I strongly agree with Ivan that understanding the full picture helps inform any proposed solution (particularly what is in and out of scope).
skonves
on 21 Feb 2019
Wouldn't a per module sandbox / permission system to protect against certain actions (Network, Disk Access, etc) help?
I saw an interesting post about this idea from the NPM perspective not too long ago: https://hackernoon.com/npm-package-permissions-an-idea-441a02902d9b
CC @davidgilbertson
 JamesMGreene
on 21 Feb 2019
JamesMGreene
on 21 Feb 2019
FWIW, we built Package Diff to gain visibility into npm package updates by directly examining the package instead of looking at the potentially-misleading source code repository:
https://diff.intrinsic.com
 tlhunter
on 26 Feb 2019
tlhunter
on 26 Feb 2019
FWIW, I built package diff for the purpose of comparing next prepared version with the latest published one for the review and version bump purposes https://github.com/sompylasar/zmey-gorynych/blob/9029972/bin/cli.js#L512
sompylasar
on 26 Feb 2019
@tlhunter very nice.
I had one thought, one way to get around it. What if you were using node-pre-gyp which fetches pre-compiled binaries rather than builds them from the source in the package and someone malicious had uploaded a pre-compiled binary from something other than the source that is published, how could we verify that they match?
justinmchase
on 27 Feb 2019
@tlhunter very nice.
I had one thought, one way to get around it. What if you were using
node-pre-gypwhich fetches pre-compiled binaries rather than builds them from the source in the package and someone malicious had uploaded a pre-compiled binary from something other than the source that is published, how could we verify that they match?
For the system to be perfect we'd need to throw away the concept of npm install scripts. One _could_ perform an npm install of every package ever made, on a set schedule, and constantly diff the artifacts left behind, but even that wouldn't be perfect. Like, the fetching of pre-compiled binaries might include information about the host machine. The event-stream incident, for example, would only inject malicious code if certain criteria were met.
I'd like to see some sort of package manager service which does the following:
- Distributes both a tarball AND is the git repo
- The user wouldn't be able to generate tarballs
- The server would guarantee correlation between git tags and tarballs
- Disable all installation scripts
tlhunter
on 28 Feb 2019
Yeah, I agree that sounds like the only way. I could imagine npm flagging releases that were published that way and you could then opt to only accept verified dependencies if you wanted.
It would be tricky for pre-compiled binary modules as they could have a large build matrix for platforms and versions but it would be enormously helpful for confidence and security.
justinmchase
on 28 Feb 2019
Interesting and related proposal in the golang ecosystem:
https://go.googlesource.com/proposal/+/master/design/25530-notary.md
shaunwarman
on 8 Mar 2019
Related issues
dominykas
·
6Comments
 ruyadorno
·
6Comments
ruyadorno
·
6Comments
 wesleytodd
·
4Comments
wesleytodd
·
4Comments
 Eomm
·
5Comments
Eomm
·
5Comments
 mhdawson
·
5Comments
mhdawson
·
5Comments
Most helpful comment
To anyone reading this, I'm building a tool to automate this nonsense, at least until Node/NPM do something about it. Email me at [email protected] if you want to get notified once it's up. I'll notify everyone that posted in this thread and/or left reactions as well. It will be free and open-source.