Osquery: Windows_events (overflowed limit) and stalling writes
Bug report
We're using osquery in conjunction with Alienvault USM Anywhere. We're collecting domain controller events - primarily security event logs. The osquery is installed in 'optimized' mode (as Alienvault term it).
This has been working fine for a couple of months, but our busiest primary domain controller has started to fail to collect/forward any logs. The log file occasionally produces:
I0408 10:53:54.089895 7756 rocksdb.cpp:68] RocksDB: [WARN] [c:\users\thor\work\repos\osquery\build\chocolatey\rocksdb\rocksdb-5.7.1\db\column_family.cc:675] [queries] Stalling writes because we have 15 immutable memtables (waiting for flush), max_write_buffer_number is set to 16 rate 10737417
But continually produces:
W0408 10:53:54.824268 12828 events.cpp:311] Expiring events for subscriber: windows_events (overflowed limit 50000)
W0408 10:53:56.933640 12828 events.cpp:311] Expiring events for subscriber: windows_events (overflowed limit 50000)
The less busy domain controllers are fine, so we know this one is particularly the heaviest load - despite configuring as much as possible to load balance LDAP queries, etc.
What operating system and version are you using?
Windows Server 2012 R2 (version: 6.3.9600, build 9600)
What version of osquery are you using?
3.3.1-89-g6548de1f_19.03.2503.0301
What steps did you take to reproduce the issue?
Did a full uninstall of the original osquery install, cleaned out the original installation, clean new osquery install.
Have tried to use variations of these options in the flags file:
--events_max= (increase to 100000) - still came up with 5000 in the above warning
--max_write_buffer_number= (increase to 20)
--write_butter_size= (increase to 20 memtables)
Nothing seems to change.
What did you expect to see?
What did you see instead?
Uncertain why it did seem to work for a few months and then has stopped. Looking at Alienvault USM Anywhere, there's been no real increase in daily/monthly event log generation in that time.
I'm not seeing a huge amount of SST files - 50-60 at any one time (of size 2086KB) which doesn't seem a lot.
The osqueryd processes (2 of them) are barely breaking 1% CPU and 30MB of memory usage, so it's not like it's clearly running hot.
What's the best way to ascertain quite where the bottleneck is, any parameters that are proven with the options/flag file in this situation? Do I need to model the number of events per hour, etc. being generated by the Windows security event log?
Any pointers would be appreciated!
 sejoneshull
sejoneshull
All 13 comments
Hi @sejoneshull , As you have deduced, the rocksdb database is one of the main bottlenecks of osquery. The Alienvault osquery agent had been using the aws_kinesis logger, which inherits from buffered_logger, which unfortunately stages all results and status logs in the rocksdb database. So I rewrote the aws_kinesis logger to not use the database at all in 19.03.2503.0301, but (and totally my fault 😔 ) did not handle an error case when AWS handle expired. Please update to 19.04.0403.0301 to get the fix for this.
As far as the DB contention, this particular server probably needs a shorter windows_events interval and expiry. Please get with Alienvault support and we will see what we can do.
 packetzero
on 8 Apr 2019
packetzero
on 8 Apr 2019
Thanks @packetzero for your help. Still having same issue since upgrade to 19.04.0403.0301, did some playing with the events parameters but still no joy - seems to be the rocksdb and memtables error thats the issue. I've raised a call with Alienvault support - I'm a little reluctant to do too much playing with the configs as they're on production domain controllers ;)
sejoneshull
on 9 Apr 2019
@sejoneshull , perhaps you are facing this problem - https://github.com/facebook/osquery/issues/5420
 uptycs-nishant
on 9 Apr 2019
uptycs-nishant
on 9 Apr 2019
It looks like your server is generating about 50,000 events every 2 seconds. That's quite a bit (and make sure you do NOT have sysmon running on high-load servers like this). The osquery event architecture is still somewhat rudimentary. If you look at the diagram below, osquery is configured to accept windows events by channel. All events for subscribed channels are going to come in and get cached, whether it's of interest or not. Based on the schedule, one or more queries will run at specific intervals (typically 30-seconds to 5-minutes) to filter events and extract those that are of interest and write to logger. The logger will then save the results to disk or database before sending. The problem is that the windows_event cache table is overflowing before it can be filtered and cleared, which causes disk thrash that leads to performance issues. If the performance issues are bad enough, the filter queries such as "SELECT * FROM windows_events WHERE blah" will be seen as a performance issue by osquery watchdog, which will kill the process. When osquery child process restarts, it will see that a query caused problems, and blacklist it for 24-hours... but events still come in and get cached and overflow the table. The correct design would be to drop events if cache is full, and keep a counter so we can monitor performance. I am looking into this, as well as real-time filtering to skip cache table altogether. In the meantime, contact support or me directly and we will try to tune the settings to work for this particular situation. It's deployments like this that push the boundaries that helps us improve osquery scale and performance.
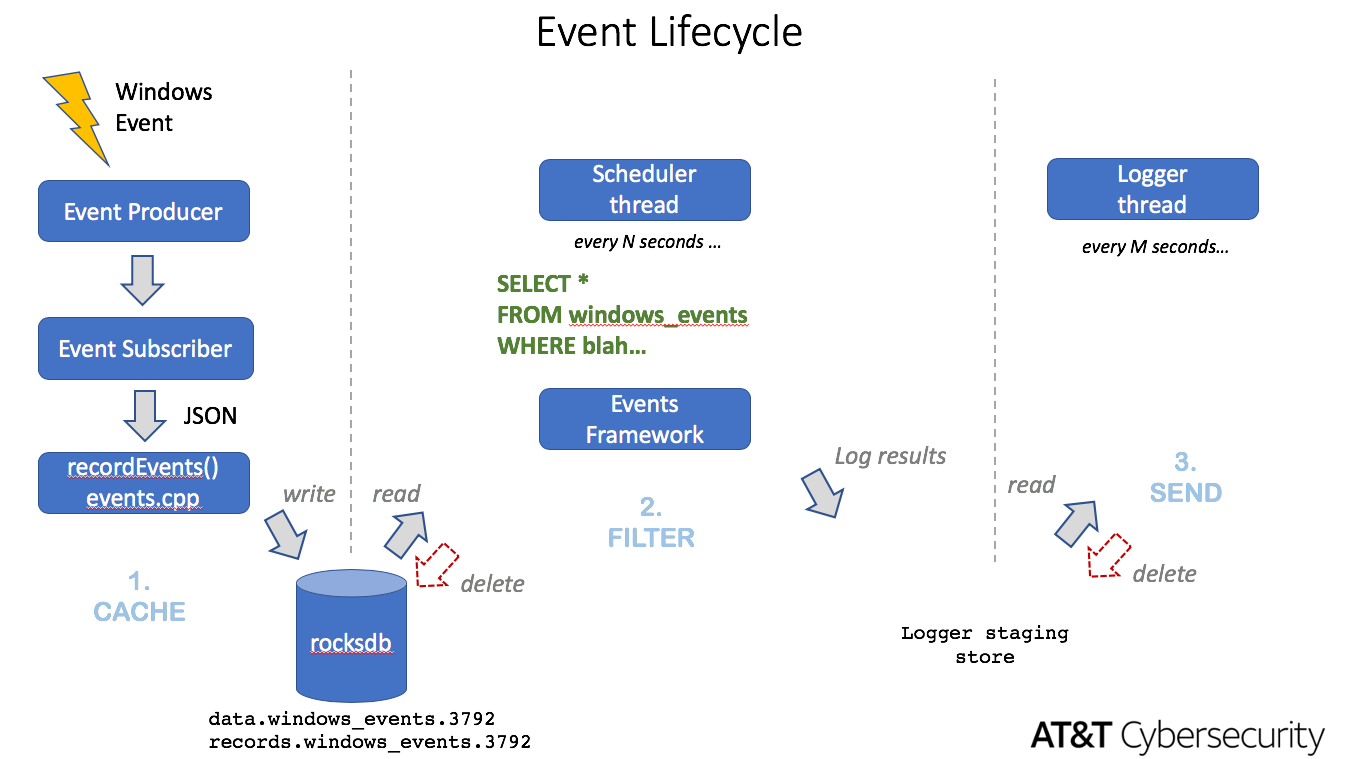
packetzero
on 9 Apr 2019
Thanks @packetzero, I appreciate your detailed reply and especially the event lifecycle - useful :) I'm still having some issues but have upped to v19.04.0403.0301 with Sysmon stopped for now to see how goes, and will pursue through Alienvault support.
sejoneshull
on 16 Apr 2019
To summarize, the issue is schedule related. Too much work for the system. The watchdog limits need to be tuned, as well as schedule to increase some query intervals. The osquery agent is executing happily along, and then gets killed by watchdog.
packetzero
on 17 Apr 2019
I'm an engineer from an MSSP using USM Anywhere and suffering this exact same issue on a client's DC. I've been troubleshooting this for hours over the past two weeks and finally gained access to the customers DC via screen sharing and found the osquery logs showing similar information. Has there been any progress or workarounds discovered since April 17th?
 SpookyUSAF
on 19 Jun 2019
SpookyUSAF
on 19 Jun 2019
@sejoneshull and @SpookyUSAF Sorry for the delay. There's a new Alienvault Agent release today that has a new event cache storage mechanism that addresses this. In initial tests on Unix, uses about 7x less I/O and 2.5 x less CPU. An incoming event will be dropped if cache is currently full, rather than constantly adding and deleting. Drop stats are logged every 5 minutes if there are any. With this change, along with the buffered-logger replacement, we should have enough scalability for most situations. Then the focus can be more on the schedule of queries, to make sure that intervals aren't too long for events tables (e.g. 30 minutes), which would delay the freeing up of new cache rows.
The library used is open-source so that others can add to mainline osquery if desired: https://github.com/AlienVault-Engineering/conveyor .
packetzero
on 12 Aug 2019
Things could be improved a little by adding batched write support to the Windows event publisher: https://github.com/osquery/osquery/blob/master/osquery/events/events.cpp#L578
The code is currently rendering and firing one event at a time, causing a massive amount of write requests to the database: https://github.com/osquery/osquery/blob/master/osquery/events/windows/windows_event_log.cpp#L96
 alessandrogario
on 14 Aug 2019
alessandrogario
on 14 Aug 2019
Event batching support for Windows has been implemented here: https://github.com/osquery/osquery/pull/6280
alessandrogario
on 9 Apr 2020
Been a while but not forgotten! Have been trying osquery (20.06.0103.0301) as of last two weeks (having switched to NXLog temporarily last 12 months to ensure our DC logs come into USM), and so far looking much better :) Have also enabled the 'create an event if agent stops sending' (USM setting) just to keep an eye on it in case they drop off. Will keep you posted!
sejoneshull
on 14 Aug 2020
Is this still current?
 directionless
on 30 Sep 2020
directionless
on 30 Sep 2020
Been a few months now, and for our DC logs, this has been really stable and solid since. Good work :)
sejoneshull
on 20 Nov 2020
Related issues
 dabeike
·
13Comments
dabeike
·
13Comments
 defensivedepth
·
11Comments
defensivedepth
·
11Comments
 sailay1996
·
15Comments
sailay1996
·
15Comments
 marpaia
·
16Comments
marpaia
·
16Comments
 danielpops
·
38Comments
danielpops
·
38Comments