Orleans: Incorrect silo shutdown behavior
We're experiencing serious problems with a rolling update after migration to 2.0. Let me explain our architecture: we have a single heterogenous Azure queue processed by multiple workers (Competing Consumers pattern). Each message in this queue may be destined to a differrent actor. The setup is quite similar to how built-in Azure Queue Streaming Provider works. See diagram below.
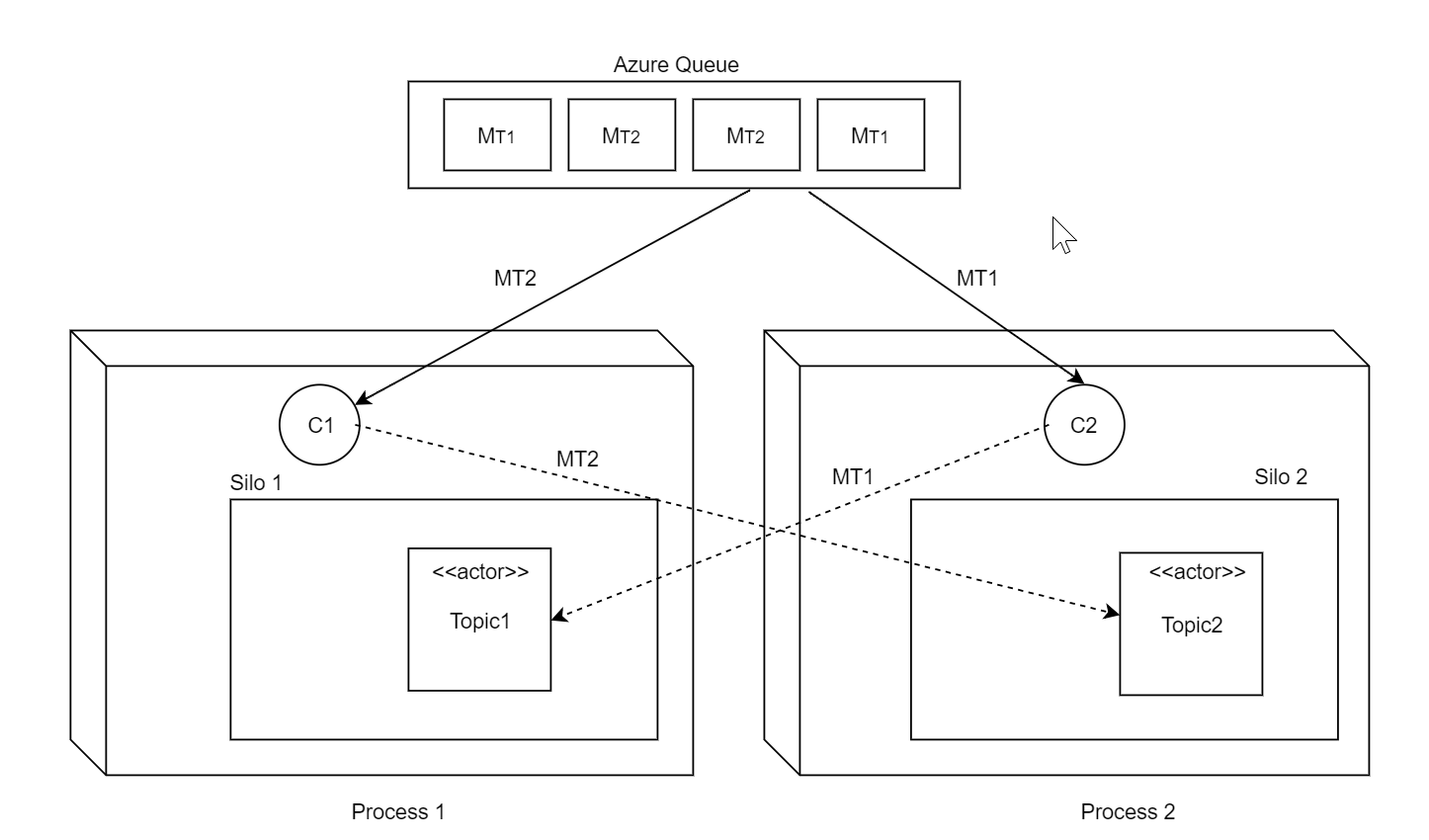
Each node runs pulling agent (queue poller) and the corresponding TPL DataFlow pipeline outside of the silo but within the same process with the silo (ie embedded). It could happen that recipent actor may reside on a different silo and so the client may forward the message to another silo, which is normal of course. Also there number of other actors that may exchange messages across silos, also normal, of course, since that's the whole point of having Orleans.
The problem arises when we try to shutdown the silo during rolling update. My expectation of Orleans' silo shutdown behavior when StopAsync() is called:
- Don't accept any new requests into the silo, neither from clients nor from other silos (basically, close silo gateway)
- Wait until all outstanding requests are completed (or failed or timed out) and return results
- Deactivate all actors
- Done
Instead, what we see from logs is that upon receiving StopAsync() Orleans almost immedietely deactivates all actors and then for 1 minute it bounces requests from other clients/silos by trying to forward them to non-existent activations (and they are not reactivated on the current silo of course since it's shutting down), and after 1 minute it kills itself after silo stop timeout is expired (which is 1 minute as I can see from the code). During this time it (Orleans.Runtime.Dispatcher) spills tens of thousands of log messages like:
Trying to forward after Non-existent activation, ForwardCount = 0. Message Request S10.31.5.14:100:268955504*cli/586efeb6@0c49119e->S10.31.5.14:100:268955504*grn/2FB327A8/00000000+124531@dd334eba #17019
And
Forwarding failed: tried to forward message Request S10.31.5.14:100:268955504*cli/586efeb6@0c49119e->S10.31.5.14:100:268955504*grn/2FB327A8/00000000+136155@897e8889 #17002[ForwardCount=1]: for 1 times after Non-existent activation to invalid activation. Rejecting now.
And
Intermediate NonExistentActivation for message Request S10.31.5.14:100:268955504*cli/ee2e539e@6615b9ac->S10.31.5.14:100:268955504*grn/2FB327A8/00000000+121772@882812ba #46821: , with Exception Orleans.Runtime.Catalog+NonExistentActivationException: Non-existent activation: [ActivationAddress: S10.31.5.14:100:268955504*grn/2FB327A8/00000000+121772@882812ba, Full GrainId: [GrainId: *grn/2FB327A8/00000000000000000000000000000000060000002fb327a8+121772-0x577BB16A, IdCategory: KeyExtGrain, BaseTypeCode: 800270248 (x2FB327A8), PrimaryKey: 0 (x0), UniformHashCode: 1467724138 (0x577BB16A), KeyExtension: 121772], Full ActivationId: @42851f391a09207a71eff3b7882812ba0000000000000000], grain type: Fun.LegacyTheme.
at Orleans.Runtime.Catalog.GetOrCreateActivation(ActivationAddress address, Boolean newPlacement, String grainType, String genericArguments, Dictionary`2 requestContextData, Task& activatedPromise)
at Orleans.Runtime.Dispatcher.ReceiveMessage(Message message)
This is unacceptable behavior for us, as:
- The whole cluster restart takes more than 10 minutes (more then 2 minutes per node. we have 5 nodes at the moment). Which is super slow.
- Since during this time deactivated actors are not re-activated on other silos, queue messages are timing out and are returned to queue. For 10 minutes chaos which occur during restart messages may breach dequeue count threshold and be moved to quarantine queue. Which is super bad.
- During restart the queue length may grow up to 100x, leading to client visible processing delays and additional stress.
- Our logs cluster (ES) is not made from rubber and on each restart Orleans can easily generate 0.5M log messages. With 10 deployments per day Orleans logs take a considerable amount of space.
The question is what are we doing wrong? No matter what we do we can't gracefully shutdown the silo. Our shutdown routine:
- Stop all local pulling agents (silo local queue poller).
- Wait\complete\cancel local pipeline
- Stop the silo
- Diconnect local client
It seems that all those steps are useless since requests from other clientssilos are still accepted by the silo after StopAsync is issued. I can't trace whether those requests were accepted just before StopAsync() but even if they are, Orleans should not deactivate actors until all those requests are completed.
P.S. I didn't include in this conversation hundreds of thousands of SiloUnavailableException and OrleansMessageRejectionException raised by sibling nodes during each restart - I belive it's a topic of its own (perhaps retries could be advised as the solution).
 yevhen
yevhen
All 24 comments
My understanding that all new requests after silo StopAsync was called should immediately return SiloUnavailableException which senders may retry (using exponential back-off) and which will eventually succeed, once silo had completed shutdown and actors are re-activated on alive silos.
yevhen
on 11 Jul 2018
Sorry for the harsh post above, too many things fell apart today :(
To rephrase the question above: is this behavior by design or is this the flaw in our architecture? Should we just ignore this, for example suppressing the log output of Orleans.Runtime.Dispatcher? Should we redesign our polling architecture so that there no cross-silo calls (quite costly for us)? But it seems that similar architecture does not create problems for built-in polling agents (thus we never tried it).
We tried ungracefully terminating the silo which is faster to shutdown but then we got myriad of TimeoutException on other silos (sending messages to the dead silo). I've also tried to set MaxForwardCount to 0 but it scares me to change the knobs with the meaning I don't fully understand. Nevertheless, it didn't improve things much.
Is it safe to retry on SiloUnavailableException \ OrleansMessageRejectionException exceptions? We tried to retry on TimeoutException which we usually get on ungraceful shutdown but it led to even more bad things like the whole cluster falling apart and not fully recovering after restart :(
Please advice.
yevhen
on 11 Jul 2018
First a bit of history.. Earlier in the development of services that used Orleans, there was a relatively defendable view that services needed to handle ungraceful shutdown, so it was held that any logic that gracefully shutdown a service would simply act as a crutch and mask issues that would occur during ungraceful shutdown. For this reason, Orleans needed little to no graceful shutdown logic.
It was clear that this view would make in-place upgrades significantly more difficult and less reliable, so we began to improve the startup and shutdown logic. With 2.0 we introduced a silo lifecycle which allowed components to take part in an orderly startup and shutdown of the silo.
As you can see from the behaviors you've observed, our graceful shutdown logic needs more love. We deactivate the grains, as you've seen, immediately, regardless of what work is in progress or in the pipe.
Questions:
What membership service are you using?
Do you know why the silo takes 1 minute to shutdown? Where is it spending it's time? You should be able to tell at least what stage it's getting stuck in from the silo lifecycle log entries.
 jason-bragg
on 11 Jul 2018
jason-bragg
on 11 Jul 2018
I think I know where is the problem. I hope is that simple)
July 12th 2018, 00:02:04.274 | ysmscprod0201 | Orleans.Runtime.Silo | Ignoring System.TimeoutException exception thrown from an action called by Silo.Stop.
July 12th 2018, 00:01:19.247 | ysmscprod0201 | Orleans.Runtime.TypeManager | OnRefreshClusterMapTimer: refresh start
Check the timing. It looks like OnRefreshClusterMapTimer hangs when doing refresh. The pattern is consistent on every silo, the refreh event is always followed by time out. It may take 15-40 seconds between those events. No other events are written into a log in between.
Could it be that it (OnRefreshClusterMapTimer) deadlocks somehow?
UPDATE: on 1 machine it was only 1 second. It still timed out but this time smth before took all the time
yevhen
on 12 Jul 2018
Looks like the only thing heavy being done in the OnRefreshClusterMapTimer are the storage calls to get versioning strategies. These are grain calls unfortunately, so if the silo is shutting down and not handling grain calls, maybe these are experiencing trouble which takes a while to resolve. If you've no default grain storage configured the version store would be disabled, so this wouldn't likely be the issue. It should also be noted that the OnRefreshClusterMapTimer logs when a refresh starts, but not when it stops, so the delay can be anything after OnRefreshClusterMapTimer starts a refresh.
If you want to test this (assuming you have a default grain storage configured and don't want to remove it) you should be able to register an instance of IVersionStore in the container (as an IVersionStore) which always gives a false value for it's IsEnabled property.
services.AddSingleton
This should turn off the version store.
jason-bragg
on 12 Jul 2018
services.AddSingleton
();
that didn't help :(
yevhen
on 12 Jul 2018
After some thinking, I came to the following silo shutdown algorithm (I call it Shutdown Exorcism 😄) :
- Disable creation of new activations on stopping silo. Let's that propogate to other nodes in the cluster so this silo is filtered out in every placement director on every alive node. Perhaps, use gossip to speed up things or simply wait
TableUpdateTimeoutso that nodes will synchronize this from membership storage - Stop all pulling agents and other user-level infrastructure (storage/stream/bootstrap providers)
- Deactivate all actors. The silo should keep accepting requests until all activations are destroyed. It means that every in-flight request to a destroyed activation will lead to reactivation on alive node, thanks to forwarding
- Once there no activations, close the gateway - ie. don't accept any new requests
- Complete forwarding of in-flight requests. They will be forwared to reactivated actors on alive silos
- At this point silo will have 0 activations and 0 incompleted requests
- Tear it down
The above procedure shoud give 0 message rejection / silo unavailable exceptions and also no timeout exceptions for senders - since all requests will be properly forwarded to reactivated instances on other nodes.
What do you think? I might try to make a PR just need some pointers where to start. It seems that all of the infrastructure is already in place and we just need to fix the order. The propagation of silo status could be done by simply waiting for TableUpdateTimout so that all nodes can pick it up.
yevhen
on 14 Jul 2018
Hi, sorry for the delay I was out for few days. Trust me when I say I am trying to have a better way to shutdown cleanely silos, I am working on this for months. Some stuff was fixed thanks to the livecycle pattern, but there is still bugs, as you saw. And it is not a trivial issue to fix. See #2287 for example, I opened this in 2016!
What placement director are you using?
Some of the messages you posted are expected.
Basically the algorithm you are describing is more or less what Orleans is supposed to do. Except:
Stop all pulling agents and other user-level infrastructure (storage/stream/bootstrap providers)
Storage should NOT be stopped before the current grain activations have been deactivated, since they can have on-flight request that need them. It's probably also the case for streaming?
If I remember correctly, we choose to close the gateway as a first step (the gateway is used only for client to silo communications). No need to keep this component running IMO (but we need to change some logic in the client, that consider pending requests as failed if the gateway used for these is shutting-down)
We know we have a bug in the forwarding requests. Basically right now we don't have any way to know when all requests have been forwarded. And sometimes for some reason, the local silo that is trying to forward will try to place activation on himself.
Not sure what you are experiencing in the OnRefreshClusterMapTimer. "Deactivating" the version store is not enough since it will get the grain map from other silos (and this is a system grain call). We may have a race condition here where a silo is shutting down but the timer still try to ping it?
 benjaminpetit
on 16 Jul 2018
benjaminpetit
on 16 Jul 2018
Hi @benjaminpetit
I've already checked the shutdown code yesterday and it really seems very similar to what I've described above. The only bad thing is that you close the gateway too soon which causes the dreaded SiloUnavailableException while instead, Orleans should continue forwarding requests until there 0 activations. Seems this is a known issue as you pointed at #2287.
Storage should NOT be stopped before the current grain activations have been deactivated, since they can have on-flight request that need them. It's probably also the case for streaming?
You're absolutely right, this step should be done after all activations are destroyed (and/or all requests are forwarded)
Not sure what you are experiencing in the OnRefreshClusterMapTimer. "Deactivating" the version store is not enough since it will get the grain map from other silos (and this is a system grain call). We may have a race condition here where a silo is shutting down but the timer still try to ping it?
Forget this, it was just a correlation (from logs) not the cause.
yevhen
on 16 Jul 2018
We actually found the root cause of the shutdown timeout. The silo is hanging at DestroyAllActivation step, it is unable to destroy some of the activations until shutdown timeout.
We wrote custom activation tracker and figured out exact actors. The only pattern was that all of them are using interleaved messages (or reentrant). I then wrote a small test and reproduced the problem.
Orleans is not deactivating actors which use interleaving/reentrancy. It says in log (my test sends a custom Shutdown message which simply calls DeactivateOnIdle, while sending interleaved messages in parallel):
[Information] "Activation=XXX, DeactivateActivationOnIdle: #GrainType=ZZZ Placement=PreferLocalPlacement State=Deactivating]" "later when become idle".
And then it hangs. I have a repro which I can PR tomorrow but maybe it's also a known issue?
yevhen
on 16 Jul 2018
Very interested in this.
We've been working with Orleans for the past couple of years, and although I like the programming model a lot, it seems as it wasn't built to be upgraded.
We wanted blue green deployments, but there's no documentation on how to do that properly, and it looked like we'll have to custom fix a lot of open corners(streams, reminders)
We setteled for rolling upgrades and now we upgrade only in low traffic hours since upgrading is still noisy (all the errors mentioned above).
How to upgrade software with 0 errors and 0 downtime should be the first priority in any software application IMO.
Happy to help somehow if I can.
 talarari
on 30 Jul 2018
talarari
on 30 Jul 2018
@talarari we built custom graceful shutdown protocol and it works quite nicely. It was easy, took me just a few hours to implement (custom GrainService and placement directors), but unfortunately, that required exposing some internal Orleans stuff like Catalog so we end up doing a private build.
After the fix I did here we still have one more issue with graceful shutdown, mainly due to StatelessWorker actors being exposed directly to clients which prevent graceful deactivation due to stateless workers being always placed on local silo. It's impossible to re-reroute client requests to stateless workers on alive silos since they are not even registered in DHT.
We're moving to a different design (where stateless workers are used only via proxy grains) and should finally get a stress-free rolling upgrade :)
yevhen
on 30 Jul 2018
Do you have code to share showing your custom graceful shutdown protocol?
Feels weird that you would have to implement such internal parts of Orleans for this to work.
Any plan to incorporate this into Orleans somehow?
talarari
on 30 Jul 2018
@talarari ye, feel the same. We want to open-source it. Expect blog post in few days
yevhen
on 30 Jul 2018
We have a similar need and are unsure how to be handle the shutdown process. Our Orleans cluster uses the Event Hub stream provider to read from an Azure IoT Hub and assign events to a grain that represents a device. We need to ensure shutdown happens in the correct order so as to not lose in-flight events.
[Ideal shutdown order]
- Shutdown all pulling agents.
- Wait for all grains to finish processing.
- Call OnDeactivate on each grain
Would the LifeCycle events be valuable/necessary here? I couldn't find docs on how to hook into the shutdown LifeCycle.
Also, is there some documentation around rolling upgrades?
 andrew-laughlin
on 8 Aug 2018
andrew-laughlin
on 8 Aug 2018
I couldn't find docs on how to hook into the shutdown LifeCycle.
Whenever a component subscribes to the lifecycle it can provide an OnStart and OnStop hook. The OnStop hooks will be called during shutdown in the reverse order of the OnStart hook.
For instance, in the below logic, during startup Init is called at the InitStage, and then Start is called at the StartStage. Durring shutdown Close is called at the StartStage, then nothing is called at the InitStage.
public void Participate(ILifecycleObservable lifecycle)
{
lifecycle.Subscribe(OptionFormattingUtilities.Name<PersistentStreamProvider>(this.Name), this.lifeCycleOptions.InitStage, Init);
lifecycle.Subscribe(OptionFormattingUtilities.Name<PersistentStreamProvider>(this.Name), this.lifeCycleOptions.StartStage, Start, Close);
}
If you want to customize what stages an azure queue stream initializes and starts you can do this using ConfigureLifecycle(..) to specify the InitStage and StartStage in the StreamLifecycleOptions.
public static ISiloPersistentStreamConfigurator ConfigureLifecycle(this ISiloPersistentStreamConfigurator configurator, Action<OptionsBuilder<StreamLifecycleOptions>> configureOptions)
Edit: for clarification, I realize this doesn't even partially address your issue, just providing some info that I hope can help.
jason-bragg
on 8 Aug 2018
@yevhen any update on that blog post?
talarari
on 13 Aug 2018
@yevhen I would be interested in the code and blog post you're working on.
@jason-bragg thanks for the insight. I've updated my comment above to more closely reflect our current architecture. After some investigation it appears, that during shutdown of a silo (i.e. a call to ISiloHost.StopAsync() ) in a multi-silo configuration, Orleans closes the stream providers (i.e. PersistentStreamProvider.Close()), then subsequently deactivates grains. The event hub agents are rebalanced as necessary across remaining silos. This order is correct for our architecture and it doesn't appear we need to do anything special (e.g. subscribe to lifecycle events).
When shutting down a single silo, the same order of operations occurs, however the series of exceptions shown below occurs, in the order the exceptions are listed. Our scenario requires all grains finish processing before shutdown completes, otherwise we lose data.
System.InvalidOperationException: 'Grain directory is stopping'
Orleans.Runtime.Catalog.NonExistentActivationException: 'Non-existent activation: [ActivationAddress: S127.0.0.1:11111:271453246*grn/716E8E94/f6929395+SMSProvider_GatewayEventData@7c3c248e, Full GrainId: [GrainId: *grn/716E8E94/4609e6596fc820a239cd8f53f692939506000000716e8e94+SMSProvider_GatewayEventData-0x8ACBAE2B, IdCategory: KeyExtGrain, BaseTypeCode: 1903070868 (x716E8E94), PrimaryKey: ffc820a2-e659-4609-9593-92f6538fcd39 (x{0x6fc820a2,0xe659,0x4609,{0x95,0x93,0x92,0xf6,0x53,0x8f,0xcd,0x39}}), UniformHashCode: 2328604203 (0x8ACBAE2B), KeyExtension: SMSProvider_GatewayEventData], Full ActivationId: @4d8b82301204288dab4569fc7c3c248e0000000000000000], grain type: Orleans.Streams.PubSubRendezvousGrain.'
Orleans.Runtime.OrleansMessageRejectionException: 'Forwarding failed: tried to forward message Request S127.0.0.1:11111:271453246*grn/1735AD24/f6929395@de9436bf->S127.0.0.1:11111:271453246*grn/716E8E94/a39a3b84+SMSProvider_TenantEventData@ea2079b9 #1340[ForwardCount=2]: for 2 times after Non-existent activation to invalid activation. Rejecting now. '
Hi guys!
Just want to post an update about our rolling restart epic.
We finally solved everything and now have 0 exceptions instead of ~30K per each node during shutdown under high load.
What we did:
- Fixed Orleans bug where grain timers were prematurely stopped (#4774) leading to hanging requests in cases where batching was used (TaskCompletionSource). This shaved around 10% of errors. Not much but it's good to have this fixed (#4830)
- We developed custom graceful shutdown protocol and it shaved around 30% of errors but we still have a lot of them, later we discarded it in favor of other solutions (see below)
- We redesigned our system so that
StatelessWorkeractors are not directly accessible by the clients (only from proxy grains). This was a huge insight into the shutdown problem and it cut the number of errors per node to ~2K (10x decrease). The issue with stateless workers which are directly accessible by the clients is that Orleans cannot cleanly re-route requests to workers in another silo (I was not able to do it in my custom placement director), since they are addressable only locally. Moreover, Orleans will keep spawning workers during node shutdown. This could be confirmed by checking sources of StatelessWorker placement director here. Personally, I think that SWs is a leaky abstraction something that is against a paradigm of distributed Virtual Actors. - I saw that some improvements to cluster shutdown were made in 2.1.0 and I was also interested in trying silo DirectClient - I was suspecting that rest of the 2K errors (lots of
SiloUnavailableExcepetion,TimeoutExceptionand some weird Orleans errors, likeObjectDisposedException,ClientGatewayException, etc) are coming from the embedded client, we've been running it in the same process as the silo but it was connected via azure clustering and it might connect to the gateway on another silo. - We bite the bullet and built 2.1.0 from the master and then migrated to direct silo client. After some triage on staging, we tried it on the production environment. Results are fantastic (we didn't even trust the numbers at first :):
- 0 errors during restart - literally nothing. 0
SiloUnavailableExceptionorTimeoutException. 0 weird errors coming from Orleans internals - almost immediate node shutdown. It now takes less than 1 minute to fully restart 1 silo.
- average CPU decrease around 20-30%. Kudos to @dVakulen for all the scheduler optimization work (we even turned off 1 VM, which is $3K savings per year)
- 0 errors during restart - literally nothing. 0
So I want to say big thanks for everyone for the fantastic work done in 2.1.0. The introduction of silo direct client is a life-saver for embedded scenarios I've described in #4757. The fact that it dies automatically with the silo fixes all of the race conditions particular to this use-case. Kudos for all the optimization work done for the scheduler.
P.S. @talarari @andrew-laughlin It didn't really help so we discarded it. Instead, we figured out the root cause and fixed it by migrating to 2.1.0 and direct silo client.
yevhen
on 16 Aug 2018
@yevhen Thank you for the detailed report!
Sounds like we need to take a close look at StatelessWorkers's behavior during shutdown.
 sergeybykov
on 16 Aug 2018
sergeybykov
on 16 Aug 2018
Sounds like 2.1 is something to look forward to.
Can I ask what a silo direct client is?
talarari
on 16 Aug 2018
@talarari check https://github.com/dotnet/orleans/pull/3362
yevhen
on 16 Aug 2018
Sounds like 2.1 is something to look forward to.
If you don't want ro recompile master, you can use our nightly builds: https://dotnet.myget.org/gallery/orleans-ci
They are signed, just like the one on nuget.org. They are published only if they pass our full nightly build tests.
benjaminpetit
on 16 Aug 2018
Fixed with #4883
benjaminpetit
on 30 Aug 2018
Related issues
 DixonDs
·
4Comments
DixonDs
·
4Comments
 SebastianStehle
·
4Comments
SebastianStehle
·
4Comments
 pherbel
·
4Comments
pherbel
·
4Comments
 jdom
·
3Comments
jdom
·
3Comments
 guopenglun
·
3Comments
guopenglun
·
3Comments
Most helpful comment
Hi guys!
Just want to post an update about our rolling restart epic.
We finally solved everything and now have 0 exceptions instead of ~30K per each node during shutdown under high load.
What we did:
StatelessWorkeractors are not directly accessible by the clients (only from proxy grains). This was a huge insight into the shutdown problem and it cut the number of errors per node to ~2K (10x decrease). The issue with stateless workers which are directly accessible by the clients is that Orleans cannot cleanly re-route requests to workers in another silo (I was not able to do it in my custom placement director), since they are addressable only locally. Moreover, Orleans will keep spawning workers during node shutdown. This could be confirmed by checking sources of StatelessWorker placement director here. Personally, I think that SWs is a leaky abstraction something that is against a paradigm of distributed Virtual Actors.SiloUnavailableExcepetion,TimeoutExceptionand some weird Orleans errors, likeObjectDisposedException,ClientGatewayException, etc) are coming from the embedded client, we've been running it in the same process as the silo but it was connected via azure clustering and it might connect to the gateway on another silo.SiloUnavailableExceptionorTimeoutException. 0 weird errors coming from Orleans internalsSo I want to say big thanks for everyone for the fantastic work done in 2.1.0. The introduction of silo direct client is a life-saver for embedded scenarios I've described in #4757. The fact that it dies automatically with the silo fixes all of the race conditions particular to this use-case. Kudos for all the optimization work done for the scheduler.
P.S. @talarari @andrew-laughlin It didn't really help so we discarded it. Instead, we figured out the root cause and fixed it by migrating to 2.1.0 and direct silo client.