Brief Abstract
Looking at org-roam-completion-ignore-case I was wondering if it'd be possible to allow searching for the normalized forms of Unicode strings.
Long Description
When text is saved with accents/diacritics matching text for retrieval requires entering the exact forms... which is a nightmare for Hebrew/Arabic.
Proposed Implementation (if any)
I'm not sure if it was brought up here or elsewhere, but there seem to be normalization functions available for regex searches, as mentioned here: https://nullprogram.com/blog/2014/06/13/
Please check the following:
- [ ?] No similar feature requests
 oatmealm
oatmealm
All 4 comments
I also encountered this and you actually need to configure your completion system to support char folding. In many cases it's enough to set search-default-mode to #'char-fold-to-regexp somewhere in your init.el file:
(setq search-default-mode #'char-fold-to-regexp)
(or via any other prefered way). You can verify if that's working by executing following code and typing buna as input:
(completing-read
"greeting: "
'("Bună dimineața"
"Buna dimineata"))
If you are using built-in completion, this should be enough. As well as for ivy, it respects this setting. If you are also using prescient.el, char folding is supported for literal filter. Now, for helm I don't know. 🤷
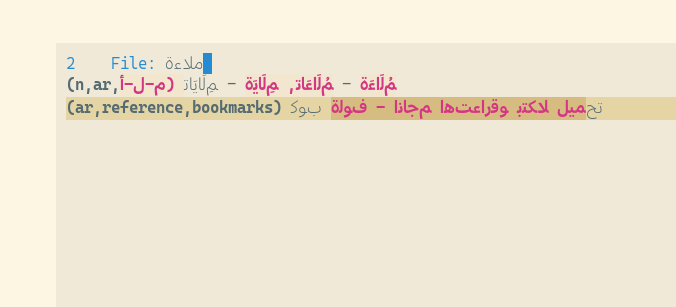
Here is a screenshot of me using org-roam-find-file (using ivy + prescient):

Hope that helps.
 d12frosted
on 13 Jan 2021
d12frosted
on 13 Jan 2021
Wow! This is so helpful and seems to work both in Hebrew and Arabic. Some false positives, but this really solving the most pressing problem!
Thanks
oatmealm
on 13 Jan 2021
Closing as mini-buffer completion is not really in the realm of Org-roam.
 jethrokuan
on 16 Jan 2021
jethrokuan
on 16 Jan 2021
@jethrokuan you forgot to close 😸
d12frosted
on 16 Jan 2021
Related issues
 grzm
·
4Comments
grzm
·
4Comments
 cantao
·
5Comments
cantao
·
5Comments
 nmartin84
·
3Comments
nmartin84
·
3Comments
 kadircancetin
·
5Comments
kadircancetin
·
5Comments
 jason-morgan
·
5Comments
jason-morgan
·
5Comments