Opentelemetry-specification: Logical reasoning behind ForceFlush API name
What are you trying to achieve?
I'd like to understand the merits of using word Force in ForceFlush API.
For C/C++/POSIX developer - it is a bit unusual to use adjectives or adverbs in API names.
Example of semantically similar APIs that guarantee flush semantics are:
- fsync - as in file descriptor
sync - fflush - as in file descriptor
flush - NetworkStream.Flush in C#
- java.io.Writer.flush
- std::flush
In (a very few unorthodox) examples where forceFlush exists on API surface, it is normally accompanied by the usual flush method.
What did you expect to see?
While we are designing the new Logging API surface, I would suggest the API be simply called Flush rather than ForceFlush. This will be consistent with other existing APIs, and more intuitive for new users to comprehend, as well as easier to find in typing hints.. plus it is less letters to type.
Additional context.
I believe we can make API simpler and more natural to users who are accustomed to similar method named Flush or flush, without Force.. if you need to use force to flush, then the flusher is broken and needs to be replaced.
 maxgolov
maxgolov
All 4 comments
Hi! The name was indeed a hot topic when the flush functionality was introduced. There is the fear that an API called "flush" will be overused (such as flushing after every ended span) when in fact it should only be required to flush in very special edge cases (e.g. AWS Lambda that may suspend your process without you knowing if you will shortly wake up again or be put to sleep forever).
The whole discussion can be read in the original issue for flush: #351 "Add flush API to processor/exporter". Fortunately this is something that was properly discussed on Github and not only decided in a SIG meeting.
 Oberon00
on 7 Nov 2020
Oberon00
on 7 Nov 2020
and more intuitive for new users to comprehend, as well as easier to find
From the above linked issue #351 you will see that it is actually intentional that ForceFlush isn't so easy to find for users -- it should be used with great care.
CC @tedsuo
Oberon00
on 7 Nov 2020
In most C++ APIs the understanding that flush is a forceful operation is intrinsic and implicit.
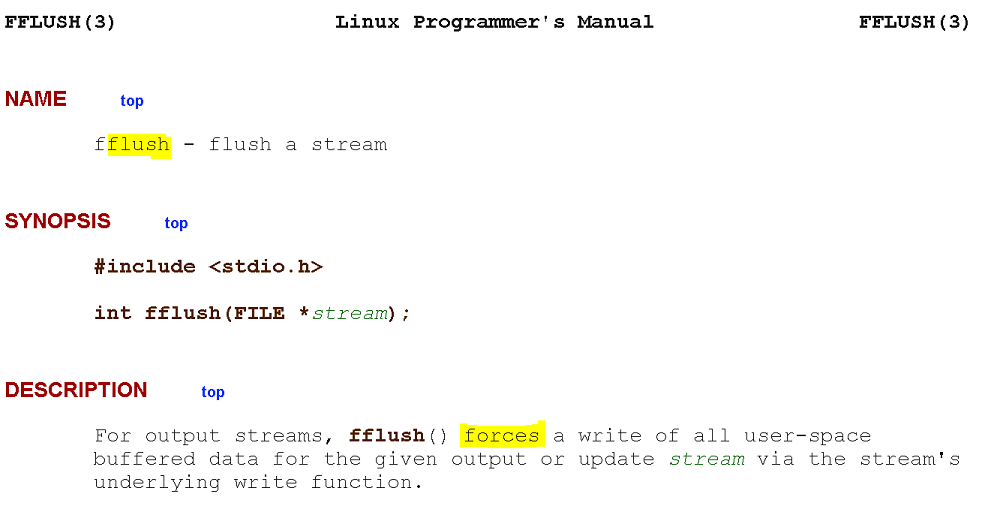
Using Linux manual and Windows manual screenshot as example.
Linux man:
Windows docs:

Thus, it is a bit unnatural to see something implicit being dumbed down and expressed in redundant wording on API surface.
My worry is for a C/C++ SDK dev implementing an exporter: this activity does require at least some level of C/C++ 101 knowledge or above. fflush and its common pitfalls is something usually explained to 1st term engineering students.
The PR from Ryan mentioned in the original spec issue - also uses the term ->flush() at SDK level rather than ->forceFlush(). My suggestion is to revisit the Logging spec API naming conventions while we are at it. Since it's obviously too late to change this for the Tracing spec.
Metapoint: devs working on C++ code implicitly understand that flush() is a forceful and undesired operation.
Secondary point:
- while
flush()is a common name for stream or pipe-based op; it's more common to see alternate naming, such asuploadfor something that requires a network I/O, e.g. Google AnalyticsuploadDataAPI.
Example:
- exporter that operates with 2-level cache: first saving logs in interim persistent disk storage, then doing network I/O on it after.. It is becoming confusing and not obvious what
flushis intended to do exactly. For client telemetry needs - these should probably be two unique distinctly named APIs:flush(persist locally) andupload(push to the cloud).
Why it is related to Logging API specifically
Default destination for logs in Docker, for example, is a file I/O first. Then some log shipper / forwarder after. Considering that it's a common knowledge in File I/O world that flush - itself is a forceful operation (doc'd in Linux and Windows man), it is redundant to have word Force in API name, as it most likely first pertains to stream I/O rather than network I/O.
What do you guys think about it?
maxgolov
on 9 Nov 2020
I believe ForceFlush is now part of the stable specification and can no longer be changed, so this discussion is no longer actionable. Closing as I believe there is nothing to do.
 tigrannajaryan
on 23 Apr 2021
tigrannajaryan
on 23 Apr 2021
Related issues
 carlosalberto
·
4Comments
carlosalberto
·
4Comments
 jmacd
·
3Comments
Oberon00
·
4Comments
jmacd
·
3Comments
Oberon00
·
4Comments
 mateuszrzeszutek
·
4Comments
mateuszrzeszutek
·
4Comments
 z1c0
·
5Comments
z1c0
·
5Comments
Most helpful comment
Hi! The name was indeed a hot topic when the flush functionality was introduced. There is the fear that an API called "flush" will be overused (such as flushing after every ended span) when in fact it should only be required to flush in very special edge cases (e.g. AWS Lambda that may suspend your process without you knowing if you will shortly wake up again or be put to sleep forever).
The whole discussion can be read in the original issue for flush: #351 "Add flush API to processor/exporter". Fortunately this is something that was properly discussed on Github and not only decided in a SIG meeting.