Openrefine: toDate() default behaviour gives inconsistent results with month position
To Reproduce
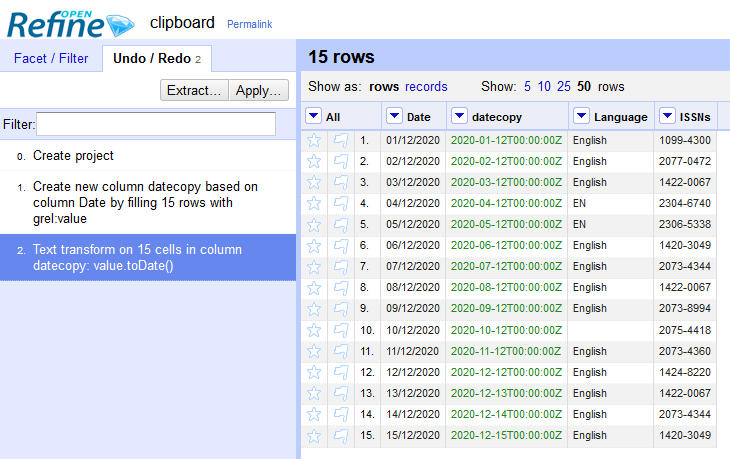
Use toDate() without options on a column that has, for example, the strings 11/12/2020 and 13/12/2020. (With the Transform dialog and the value.toDate() expression, or with Edit cells > Common transforms > To date.)
Current Results
The strings 11/12/2020 and 13/12/2020 will return the data-time values 2020-11-12T00:00:00Z and 2020-12-13T00:00:00Z respectively.
With the format xx/xx/xxxx, toDate() will use month_first = true by default, unless the number can't be the month (i.e. if it is 13, like in the example), for each cell independently.
I assume having different results depending on the value of the first number _for each cell_ is not expected by most, especially when the format is the same everywhere.
I suspect users will want the default behaviour to be consistent regarding the month_first setting. In my opinion, the international standard order of day, month, year (or the reverse year, month, day), regardless of the separator, should be preferred over the US-centric default of month, day, year.
I understand using toDate() without options can be powerful to guess parse data from a variety of different formats, but it should at least stick to one specific order of day and month to avoid this unintended behaviour.
Expected Behavior
I see it as this:
- Look at the column data. (Or pseudo-random sample of it if too large.)
- if in the 2-digit elements, one position has values > 12, determine the
month_firstsetting accordingly _and stick to it for the whole column_. - if none of the 2-digit elements have values > 12, use
month_first = falseas the international standard, _and stick to it for the whole column_.
Versions
- Operating System: Ubuntu 18.04
- Browser Version: Firefox 79.0
- JRE or JDK Version:
openjdk version "11.0.8" 2020-07-14
OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu118.04.1)
OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu118.04.1, mixed mode, sharing)
- OpenRefine: Version 3.3 [58b839b]
Datasets
Test with this CSV data:
Date,Language,ISSNs
01/12/2020,English,1099-4300
02/12/2020,English,2077-0472
03/12/2020,English,1422-0067
04/12/2020,EN,2304-6740
05/12/2020,EN,2306-5338
06/12/2020,English,1420-3049
07/12/2020,English,2073-4344
08/12/2020,English,1422-0067
09/12/2020,English,2073-8994
10/12/2020,,2075-4418
11/12/2020,English,2073-4360
12/12/2020,English,1424-8220
13/12/2020,English,1422-0067
14/12/2020,English,2073-4344
15/12/2020,English,1420-3049
See the result of toDate() on the first column: the month position switched from the 13th record.
Additional context
I understand a change in the default behaviour will mean breaking changes for scripts supposed to be reproducible, but I believe this is an important issue that needs fixing earlier rather than later.
Might be worth linking to this issue, which is probably related to the latest big changes in toDate()'s default behaviour: https://github.com/OpenRefine/OpenRefine/issues/1759
Associated to this issue, I think the section about toDate() in the transform help tab needs to be expanded to explain what it does when no options are used.
 stragu
stragu
All 7 comments
That is going to be painful to fix without introducing a nasty breaking change, but I agree with the expectations here.
 wetneb
on 3 Aug 2020
wetneb
on 3 Aug 2020
I also generally agree with applying the same format over the column.
This has been inconsistent since before OpenRefine 2.7 as shown here if the user does not specify a default format they want to apply for the toDate(). I also agree that we should apply a default format at the least for toDate(), if the user does not, otherwise this happens as he explained:
What that default format should be ? I would lean to using ISO 8601 international standard.
Option 1:
The algorithm could iterate over the columns values until it finds any 2 digit number > 12 and then it could reasonable guess well on which part of the date string has the day part?
What format does it consistently choose if there are no 2 digit values > 12 in the parts?
Option 2:
Or, we change toDate() and stop it even guessing?
This would force the user to choose a format always, but that breaks years of convenience for a lot of folks that have standardized ISO 8601 dates in their datasets (like most of mine).
Is there an Option 3?
 thadguidry
on 3 Aug 2020
thadguidry
on 3 Aug 2020
I understand a change in the default behaviour will mean breaking changes for scripts supposed to be reproducible, but I believe this is an important issue that needs fixing earlier rather than later.
It's already "later." This is Day 1 behavior which has been in place for over 10 years. Guessing the best format based on the contents of the entire column would be a useful enhancement, but is not context that the expression evaluator has.
Fixed format conversions are supported by specifying a format string. For the common Euro/U.S. formats, the month_first=true/false flag can be used to pin the behavior one way or another. Changing the default 10 years after the fact isn't going to happen. Compatibility needs would require introducing a toDate2 function or something similar.
 tfmorris
on 3 Aug 2020
tfmorris
on 3 Aug 2020
Thank you all for the feedback, I appreciate it!
To be clear: I see this issue as something that might _introduce_ messiness in the data – hardly something justifiable for OpenRefine! :smile:
Is version 4.0 a good opportunity for some breaking changes that introduce more consistency and less unexpected behaviour? I think people understand that reproducibility is also tied to package versioning. Is there a strong expectation of backward-compatibility in the OpenRefine project?
I guess another part of the question is: how valuable is it to have the function work without any month_first value?
I can see how useful it is to have the function guess a date format if you have a dataset that has a lot of variability, e.g. 15/10/2020, 16-10-2020 and 17/10/2020 in one single column because it was populated by a number of different people: it makes sense to have the function parse those automatically. But having the function parse the dates with a variety of month_first=true and month_first=false depending on if the first element is greater than 12? I can't see how someone would look for that behaviour, ever.
So maybe that's the best answer, "option 3": not allowing the use of toDate() without specifying a month_first value (but still having automatic guessing of the format if no formatN string is given).
stragu
on 4 Aug 2020
I think this would be worth fixing in 4.0. Adding it tentatively to the corresponding milestone, with the understanding that we still need to decide on the precise approach to take.
wetneb
on 6 Aug 2020
Thank you @wetneb.
One more thing: I said "not allowing its use without specifying a month_first values", however maybe yet another alternative option (option 4?) could be to allow not using any options, but sticking to month_first = FALSE or month_first = TRUE as a default.
Consequences of that would be previous scripts executing without a problem but potentially giving different results, so a more "silent" breaking change. Whereas forcing the user to provide a value for month_first would throw an error for all previous uses of toDate() without options, which would make it more obvious to the user that the script needs fixing.
Just food for thoughts! :)
stragu
on 6 Aug 2020
A better default might be to use the user's locale rather than doing data-dependent guessing. We should probably retire our custom date parser altogether and just use the built-in Java 8 date handling.
tfmorris
on 25 Aug 2020
Related issues
 anchardo
·
3Comments
anchardo
·
3Comments
 davidegiunchidiennea
·
3Comments
davidegiunchidiennea
·
3Comments
 ettorerizza
·
4Comments
ettorerizza
·
4Comments
 dantexier
·
4Comments
dantexier
·
4Comments
 katrinleinweber
·
3Comments
katrinleinweber
·
3Comments