Openrefine: Extending the cross() function - please give advice
Two years ago a colleague and I created a feature request (#1289) and a pull request (#1294) to extend the cross function to support multi-valued cells which was followed by a long discussion. The original cross function expects normalized data (one foreign key per cell in base column). If you have multiple key values in one cell you need to split them first in multiple rows before you apply cross (and join results afterwards). This can be quite "expensive" if you work with bigger datasets.
Finally, we all agreed upon keeping the cross function unchanged and aim for general performance improvements (https://github.com/OpenRefine/OpenRefine/projects/1#card-5380183). In the meanwhile I created a fork including the pull request to solve my use case. It is based on the OpenRefine development version of October 10, 2017 (something between OpenRefine 2.7 and 2.8):
- Code: https://github.com/opencultureconsulting/openrefine/
- Documentation: https://github.com/opencultureconsulting/openrefine/wiki
We use this fork within a data pipeline for the German Literature Archive to extract, transform, enrich and load data from an integrated library system into a search index for a new catalog, which will be published in a few months. Slides from a library conference are available here: http://doi.org/10.5281/zenodo.2678113 (cross on p. 16). The amount of data is big enough that it just don't work (within a time frame of 24 hours / daily updates of the catalog) without the extended cross (e.g. split, cross and join separately takes too much time, see some stats here https://github.com/OpenRefine/OpenRefine/issues/1289#issuecomment-340018966).
The project will end in June 2020 and I would like to find a sustainable solution by then. Currently the staff at the German Literature Archive is stuck at OpenRefine ~2.7 and merging the pull request #1294 with the current master got a bit more difficult because of other changes to Cross.java and the InterProjectModel.java.
Regarding the recent OpenRefine funding and plans to work on the core data model in 2020 what approach would you recommend?
- merge fork with current master (not very easy to maintain)
- just wait until the end of 2020 (because general performance improvements with Apache Beam will solve the issue)
- create an extension with an additional GREL function, e.g. crossSplit (not sure if this is possible because of the changes to InterProjectModel.java; will be broken in 2020 due to planned changes to the core?)
OpenRefine team, could you please give an advice here?
 felixlohmeier
felixlohmeier
All 10 comments
Thanks for opening this! I would like to understand better why @ostephens' GREL-based solution is so slow - I haven't looked in detail but I think there should be ways to make cross more efficient in that respect.
I'll report back later once I get a chance to have a proper look.
 wetneb
on 26 Nov 2019
wetneb
on 26 Nov 2019
I chatted to @felixlohmeier about this yesterday, and while I agree @wetneb it would be good to understand exactly why the performance degrades, I would like to see a solution in place for an active user of OR.
Because of this I'm in favour of a new crossSplit function to OR (core) right now (as we know this meets the immediate need), and investigate the issue at a slower pace
 ostephens
on 26 Nov 2019
ostephens
on 26 Nov 2019
Also worth noting that from the stats @felixlohmeier reports, the real problem is the length of time it takes to split and join cells - the cross takes slightly longer, but it is not really the problem here
ostephens
on 26 Nov 2019
Thanks @wetneb and @ostephens for your comments. Yes, it's actually the performance of the split and join functions. Cross is fast but expects normalized data. The GREL in https://github.com/OpenRefine/OpenRefine/issues/1289#issuecomment-339962903 does not produce the desired outcome if there are keys in the from column that are only present in multi-value form (e.g. mary, anne in one cell but no cell containing mary alone -> mary will fail to be crossed), see https://github.com/OpenRefine/OpenRefine/issues/1204#issuecomment-316012444 for some screenshots and https://github.com/opencultureconsulting/OpenRefine/wiki#usage for example data.
felixlohmeier
on 26 Nov 2019
I am totally OK with introducing NEW functions that help some use cases. That is what we have traditionally done. While we sometimes expand functions, we never try to break them for backward compatibility, and if we do, we state this upcoming change and ask users what they think on our mailing list during the bikeshedding phase.
I agree with @ostephens that we can introduce the new crossSplit() to OpenRefine now to help users of larger datasets while maintaining existing cross() as is.
This allows us to explore performance separately going into 2020 as well as tackling lookups with a more elegant UI/dialogs and set of commands, if we decide that this could fall into one of our 2020 goals in http://openrefine.org/images/czi-eoss-proposal.pdf
 thadguidry
on 26 Nov 2019
thadguidry
on 26 Nov 2019
Also, we could even give users an option on any operation to not even store a com.google.refine.history.Change (although no Undo would be available, the overhead of objects and new Strings is greatly reduced during processing) or even let users set it in preferences for however long they need, or just a Toggle checkbox along the top of the grid somewhere that says "Store Changes [x]"
thadguidry
on 26 Nov 2019
@felixlohmeier for your use case, I constantly use Pentaho for doing mass operations of lookups with further operations applied. OpenRefine as I previously discussed was never designed for batching operations, but for Humans to inspect messy data and have safety nets for undoing and exploring. When you know exactly what you need to do, you don't need to store Changes, or Logs, but just perform the work.
I think long term Beam DoFn's will help us quite a bit for users of large data jobs.
If you want to get this sort of functionality now...I'd recommend Pentaho or Apache NiFi.
thadguidry
on 26 Nov 2019
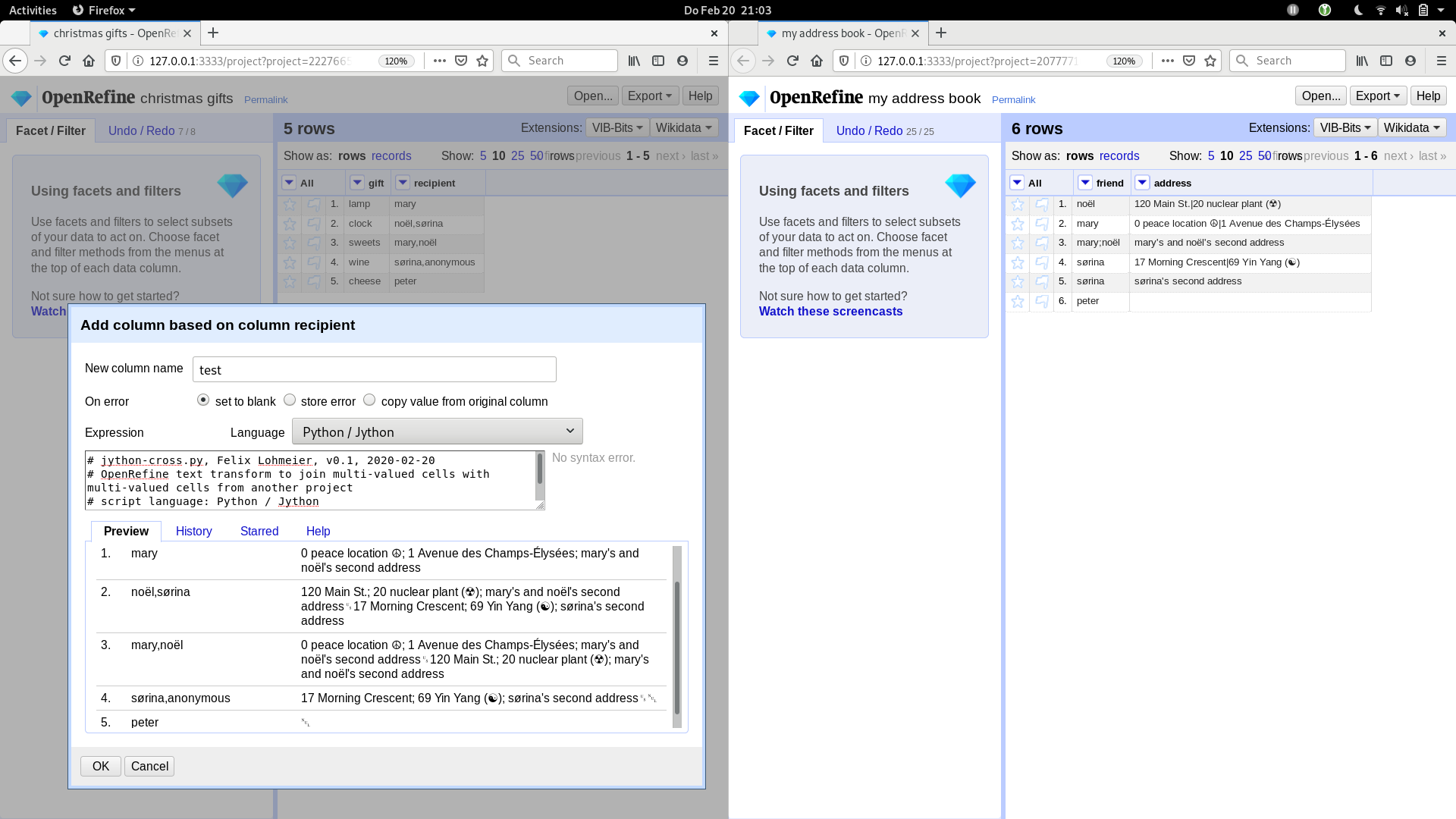
I'm sorry it's been so long. I'm on parental leave and had the opportunity to think about this issue once again and do some experiments with Jython. And actually I found a solution for my use case (fast cross with multi-valued cells in source project and foreign project) based on Jython and the openrefine-client. It is not as fast as the former fork of the cross function, but still fast enough (20 seconds for 1.6 million rows crossed against 500.000 rows with i7-7500U CPU @ 2.70GHz and 8GB java heap space).
Maybe it is helpful for others (or other contexts), so I created a Gist with code and sample data: https://gist.github.com/felixlohmeier/a5a893190e4aa8e26091664908d04e20
Owen (@ostephens), Thad (@thadguidry) and Antonin (@wetneb), thank you very much for the discussion and your support! I will close the ticket, as no other potential users left comments here.
felixlohmeier
on 20 Feb 2020
What. The. Actual. Hell. :-D This is pretty incredible.
wetneb
on 20 Feb 2020
@felixlohmeier Nice Felix! An iter-generator for the win that yields 2-tuples, yeah, that's gonna be fast.
thadguidry
on 21 Feb 2020
Related issues
 stellasia
·
4Comments
stellasia
·
4Comments
 asyrul21
·
3Comments
asyrul21
·
3Comments
 katrinleinweber
·
3Comments
katrinleinweber
·
3Comments
 dantexier
·
4Comments
dantexier
·
4Comments
 kushthedude
·
3Comments
kushthedude
·
3Comments
Most helpful comment
I'm sorry it's been so long. I'm on parental leave and had the opportunity to think about this issue once again and do some experiments with Jython. And actually I found a solution for my use case (fast cross with multi-valued cells in source project and foreign project) based on Jython and the openrefine-client. It is not as fast as the former fork of the cross function, but still fast enough (20 seconds for 1.6 million rows crossed against 500.000 rows with i7-7500U CPU @ 2.70GHz and 8GB java heap space).
Maybe it is helpful for others (or other contexts), so I created a Gist with code and sample data: https://gist.github.com/felixlohmeier/a5a893190e4aa8e26091664908d04e20
Owen (@ostephens), Thad (@thadguidry) and Antonin (@wetneb), thank you very much for the discussion and your support! I will close the ticket, as no other potential users left comments here.