Openlibrary: ImportBot importing titlepage instead of cover
Description
ImportBot does not seem to be choosing covers correctly from archive.org. It seems to be using the title page even when a good cover. I wonder if this is happening in:
This is using:
which I think is wrong. We should be using e.g. https://archive.org/download/greatdebatesback0000unse/page/cover_t.jpg which gives the cover _or_ the title page (if the cover is not useful).
Evidence / Screenshot (if possible)
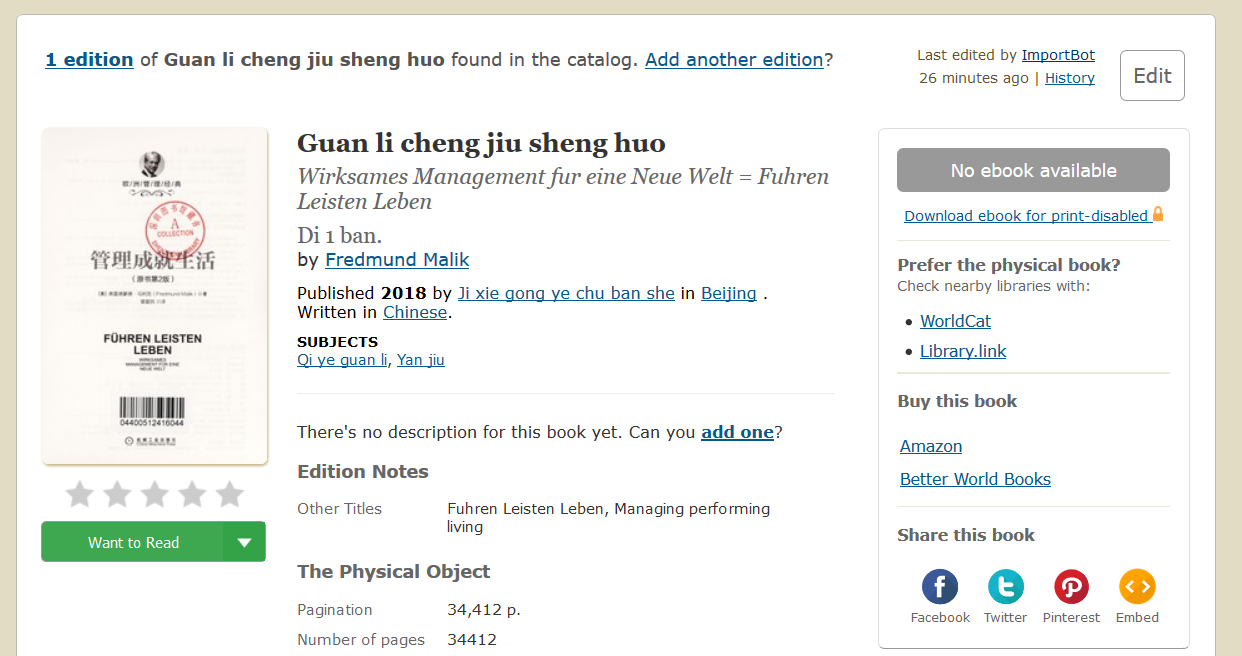
Relevant url?
e.g. https://openlibrary.org/books/OL26968796M/Guan_li_cheng_jiu_sheng_huo
Expectation
Should display e.g. https://archive.org/download/guanlichengjiush0002fred/page/cover_t.jpg
Details
- Logged in (Y/N)? Y
- Browser type/version? Firefox 67.0
- Operating system? Windows 10 Home
Stakeholders
@mekarpeles @hornc
 cdrini
cdrini
All 8 comments
@mekarpeles @hornc Is there anything special that needs to be done to deploy this, or do we just have to fix the line above?
cdrini
on 24 May 2019
Note also that for your example, https://archive.org/download/greatdebatesback0000unse/page/title.jpg (the current form) doesn't resolve at all, but in that case the title page would arguably be better than a plain blank green cover.
In addition to fixing the current code, we'll also need to figure out which editions need to have their covers fixed.
 tfmorris
on 24 May 2019
tfmorris
on 24 May 2019
It seems that there are four conflated issues here.
First, both the cover and the title page should be captured into the coverstore, not just one or the other. Capturing TP verso would also be helpful.
Second, the better of the two (by some metric) should be presented in search results and carousels. I would argue that when there is not a minimum amount of legible text on the cover (to identify the author and title), seeing the title page is often essential to confirming the edition is correctly described.
Third, absent a good identifying image for the edition, should a useful default cover for the work be presented instead?
Fourth, are all useful sources for cover images being exploited?
 LeadSongDog
on 24 May 2019
LeadSongDog
on 24 May 2019
@tfmorris could you create a new issue (probably on https://github.com/internetarchive/openlibrary-client ) for cleaning up the incorrect covers?
@LeadSongDog Trying to keep the scope of this issue small. Baby steps :)
- That would require a redesign of the way we store covers. We currently don't store any extra semantic data with the images; it's just a list of pictures labelled
covers. This would require labeling the images as "front cover", "title page", etc. Could you create a new issue to investigate redesigning our cover storage schema? - This is what this issue is trying to fix. Currently ImportBot _indiscriminately_ imports/displays the title page. The proposed solution would display the cover page if it's "better" (as deemed by the folks who scanned the book), and the title page if it's not.
- Strong disagree; displaying the work's cover is misleading. What if the edition is in a different language?
- This bot's focus is on importing from internet archive; to keep it concise/manageable, it should only be importing from there. New bots should be created to deal with other sources.
cdrini
on 24 May 2019
@cdrini
- Done.
- Understood, but how often do the scanners make that distinction?
- I take your point, but is seeing no cover at all really better than another-edition-so-annotated? Of course we should not be deceptive: other sites indicate this with "Other editions" or "Similar items"
- Good to know. Perhaps a more informative name, to more accurately match the scope? Say, "IAImportBot" perhaps? Alternatively, widen the scope to exploit a list of usable sources?
LeadSongDog
on 29 May 2019
I'm not sure whether relying on cover to be set to the title page on books where it is appropriate is fully reliable.
It seems to be the case on many items, e.g. https://archive.org/download/hesiodtheognis00daviuoft/page/cover.jpg
But it looks like title and cover are independent things, and there is no logic that redirects to the other if one is not set.
archive.org logic appears to prefer title if a book is pre-1923, but cover otherwise, but that is explicitly for choosing a preview image to display. We'll need to make a choice ourselves.
also, the correct URL is https://archive.org/download/guanlichengjiush0002fred/page/cover.jpg
cover_s4.jpg would scale the image , but the _t is not meaningful and is stripped.
Also, in the current code the archive.org id is duplicated, which does not seem necessary :man_shrugging:
I'm not sure cover.jpg is absolutely better than title.jpg, it _seems_ like it will be better in this case, and I can't find a concrete example where it is _worse_. It seems very dependent on the source data, and not on any system smarts.
We could
A. make the change and see if we notice any issues
B. Investigate further to make a stronger case
 hornc
on 13 Nov 2019
hornc
on 13 Nov 2019
Assigning @hornc per slack discussions because this issue is import related.
Also removing the Good First Issue label as this seems a little involved for a newcomer.
 xayhewalo
on 22 Nov 2019
xayhewalo
on 22 Nov 2019
I'm not sure there is a clear action to take here. Closing.
hornc
on 17 Dec 2019
Related issues
 BrittanyBunk
·
5Comments
BrittanyBunk
·
5Comments
 Pratyush1197
·
3Comments
cdrini
·
5Comments
Pratyush1197
·
3Comments
cdrini
·
5Comments
 jdlrobson
·
5Comments
jdlrobson
·
5Comments
 nonom
·
3Comments
nonom
·
3Comments