Openlibrary: Error: Changing Internet Archive ID is not allowed.
Description
I've just added an edition from Internet Archive to Open Library where no record existed. I was able to get through the initial screen and add the title, publisher, etc. However, when saving the record after adding full details I get an error "Changing Internet Archive ID is not allowed." I was not trying to change the IA ID and I don't think there is a way to do so anyway.
Evidence
Relevant url?
https://openlibrary.org/books/OL26639980M/A_Tale_of_Two_Cities
Screenshot (if possible):
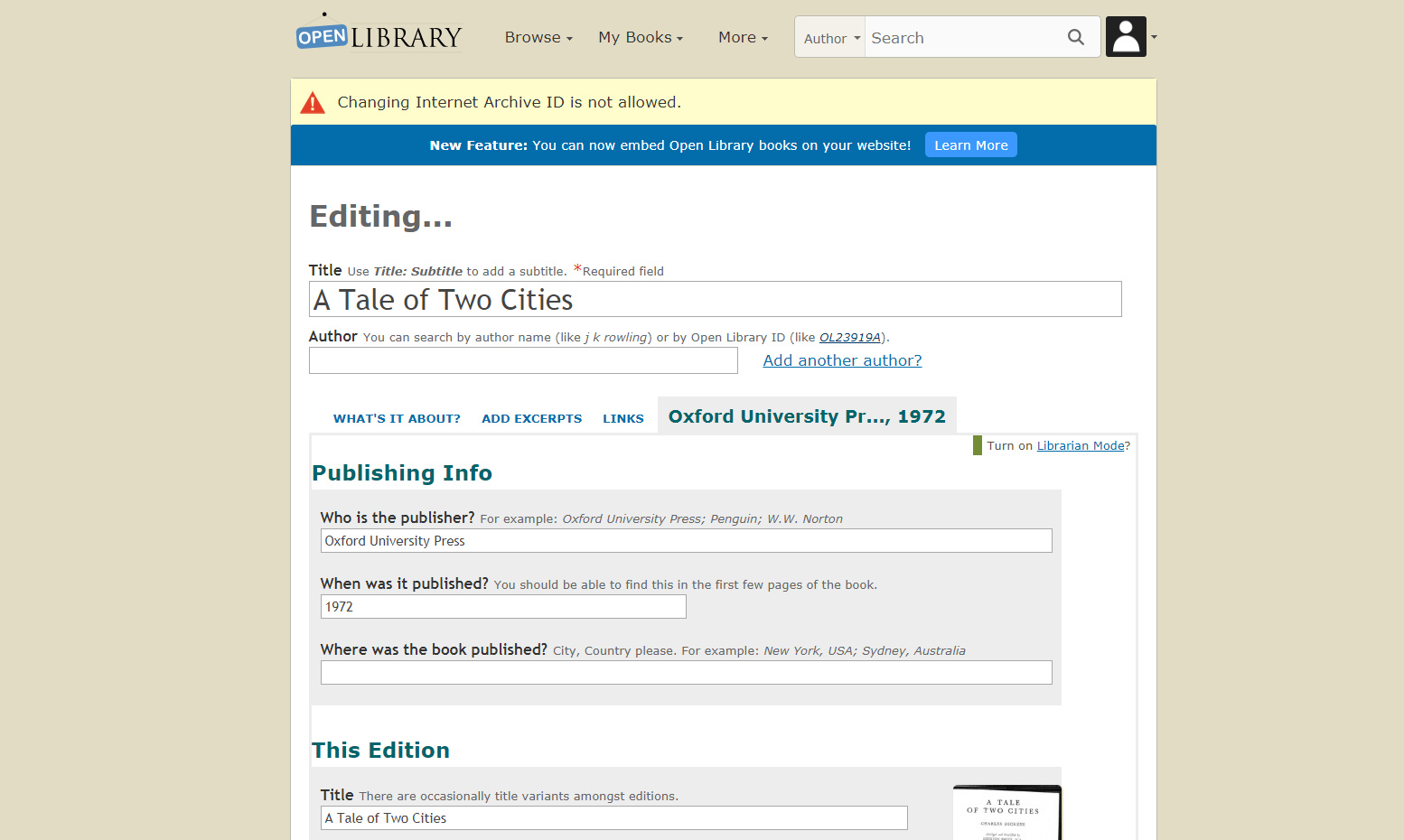
Details
Logged in (Y/N)? Y
Browser type/version? Version 71.0.3578.98 (Official Build) (64-bit)
Operating system? Windows 7 Professional
Proposal & Constraints
What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere?
Which suggestions or requirements should be considered for how feature needs to appear or be implemented?
Stakeholders
@ tag stakeholders of this bug / feature
 seabelis
seabelis
All 12 comments
Reproduced with Chrome on iOS. The target file is present on IA at ark:/13960/t8z94mv6v but for some reason it doesn't show an OLID as most IA metadata records do. There may be a systemic issue with the metadata on files sourced from the Digital Library of India (a.k.a. National Digital Library) http://meity.gov.in/content/national-digital-library
 LeadSongDog
on 9 Jan 2019
LeadSongDog
on 9 Jan 2019
Or e.g. admin access may be required for updating archive.org ids? Is that possible?
 mekarpeles
on 10 Jan 2019
mekarpeles
on 10 Jan 2019
I don't recall seeing any Digital Library of India items that DO have an OLID but this is the first time I've encountered this error.
seabelis
on 10 Jan 2019
@mekarpeles
There is no intent to update the archive.org id here, the problem is that OL26639980M cannot be revised at all. The error message likely comes up because the OCAID has an unwanted leading space: see https://openlibrary.org/books/OL26639980M.json
@hornc @mekarpeles
This touches on #731 #732 #950 #854 #856 #1436
For all extant OCAIDs where the OLID has never been written back to IA, there ought to be automated cleanup running. This might be as simple as rerunning the record through import_bot if that now works correctly. I suspect there has been a premature declaration of victory somewhere.
LeadSongDog
on 10 Jan 2019
Thank you for explaining @LeadSongDog!
IA/OL sync is, and will be an ongoing perpetual energy machine :sweat_smile:
Is this fixed? I used the edit UI to remove the internet archive ID, to add a new (the same) archive id (which worked with no problem), and then ran an IA/OL sync (admin button)
mekarpeles
on 10 Jan 2019
@mekarpeles
The specific record is fixed, thank you:
https://openlibrary.org/books/OL26639980M/A_Tale_of_Two_Cities?b=4&a=3&_compare=Compare&m=diff
Re sync, only 66 of the many OCAIDs containing "in.ernet.dli." have been imported, for whatever reason. Obviously none of the remainder have had an OLID written back. On a broader approach, we really should have a handy progress metric that tells us what proportion of all text OCAIDs (from all sources) have been imported to OL, and another to say what proportion have been written back.
Googling "in.ernet.dli.2015." details site:archive.org finds 259,000 hits, so we have some room for improvement.
LeadSongDog
on 10 Jan 2019
i agree with these sentiments, and would love to move towards a dashboard where we can have a better realtime idea of our progress. thanks for proposing @LeadSongDog
mekarpeles
on 10 Jan 2019
I think I probably "imported" those 66.
seabelis
on 10 Jan 2019
That makes more sense, typically our importer only imports things from archive.org which are verifiably "books" (which may mean, e.g. they have a scanning center and a MARC record)
mekarpeles
on 11 Jan 2019
A quick sampling suggests that most of the remainder are books. Narrowing the hits down to just these:
https://www.google.com/search?q=%22details/in.ernet.dli.%22+djvu+site%3Aarchive.org
we still get 174,000 djvu files with "details/in.ernet.dli." in their paths.
Further refinement to:
https://www.google.com/search?q="details/in.ernet.dli."+djvu+scanner+site:archive.org
finds only 15,500 so it seems like the dc metadata is not consistently completed. Still, it's a lot more than 66.
LeadSongDog
on 11 Jan 2019
Should this be closed or expanded to fix all the thousands of Digital Library of India books?
Picking one of the top search hits from the queries above: https://archive.org/details/in.ernet.dli.2015.221533
It's got some embeded Dublic Core metadata which could be used, but not a ton:
dc.contributor.author: Bertrand Russell
dc.identifier.uri: http://www.new.dli.ernet.in/handle/2015/221533
dc.description.totalpages: 440
dc.language.iso: English
dc.publisher: Kegan Paul Trench Trubner Co Ltd
dc.subject.classification: Philosophy. Psychology
dc.subject.keywords: Matter
dc.title: The Analysis Of Matter
Internet Archive seems confident enough of the author's identity to include a Wikipedia link, but no idea how it determined that.
It would be nice to include these, but it also seems like it could be a large task to do the cleanup and import.
 tfmorris
on 21 Jan 2019
tfmorris
on 21 Jan 2019
I will close this as the specific work in question is resolved. Re-open if necessary.
seabelis
on 3 Apr 2019
Related issues
 cdrini
·
5Comments
LeadSongDog
·
5Comments
cdrini
·
5Comments
cdrini
·
5Comments
LeadSongDog
·
5Comments
cdrini
·
5Comments
 cclauss
·
3Comments
cclauss
·
3Comments
 nonom
·
3Comments
nonom
·
3Comments