Openj9: Creating Kubernetes-Openshift deployment for Adopt+OpenJ9 JDKs
Hi all,
deployment technologies for applications and runtimes have progressed a lot. Kubernetes(K8s) and OpenShift(OCP) based deployments are now common. Do you think, we should add these deployment options to OpenJ9? With JIT Server technology now being available - easy deployment to K8s and OCP allow better consumability for OpenJ9 technologies in various hybrid cloud platforms.
This can include
- Helm Chart for K8s
- Operator for OpenShift4+
- And various platform support in them.
There may be support for other platforms we have to add but K8s powering most hybrid cloud platforms I think it helps to start from there and OpenShift4 is a natural option as well being an open Hybrid Cloud platform.
Please refer to the User Story and Roadmap:
V1
JITServer Deployment User Story.pdf
V2
JITServer Deployment User Storyv2.pdf
 raguks
raguks
All 30 comments
Perhaps this is a topic that could be discussed at an upcoming weekly OpenJ9 community call?
 0xdaryl
on 5 May 2020
0xdaryl
on 5 May 2020
Thanks @raguks for opening this issue. A couple of questions I'll add here and we can either address in this issue or, as Daryl suggested, discuss on the community call.
Are the helm charts / operators for JITServer deployments or intended for a general openj9 deployments?
Operators are a really cool piece of tech that helps with "day 2" concerns when running Java in K8 and there's a lot of value to having an OpenJ9-specific operator. Do you have thoughts on the capabilities of that operator?
Some ideas of potential operator capabilities:
- generate diagnostic dump files (javacore / system core / heap / trace )
- modify gc softmx in a coordinated way for JVMs on the same node
- etc
What role do you see for the Helm charts vs the Operator? My understanding is Helm is more about install while the Operator allows coordination. Do you see the need for both? Would the up-stack frameworks cover the Helm concerns?
In addition to defining the goals of the helm charts & operators, some thought on how to test these artifacts is also required. The project doesn't currently have a K8 cluster and we'd need to get access to one as well as licenses for any particular K8 distribution.
 DanHeidinga
on 6 May 2020
DanHeidinga
on 6 May 2020
Thank you @DanHeidinga
- Yes we can tailor the chart to deploy openj9 or JITServer through command line/yaml options. It makes sense to use "official" adopt+openj9 container images
- While an Operator is capable of lot more, it is also a basic deployment mechanism for OpenShift. We can start with basic deployment to OpenShift as MVP and then iterate to add features you have suggested among others such as support for JDK upgrade etc.
Helm chart while being a common deployment option for all K8 vendors is also an ingredient of the Operator. Helm chart support will give openj9 a vendor neutral way to deploy to any K8 platform.
- Charts have an inbuilt way to test deployments and we need to update CI/CD pipelines to kick off these tests. @KevinBonilla let me know your thoughts.
- Yes - we need to find infrastructure to do these tests.
Please let me know if there are questions.
raguks
on 6 May 2020
@raguk thanks for opening this issue.
Are there other examples of open source projects that provide their own helm charts & operators to facilitate k8s deployment? I wonder if there are some best practices we could learn from others on where to keep them, how to manage (test) them, etc. Is this something that primarily OpenJ9 should do, something primarily AdoptOpenJDK should do, or something we both need to work on?
Should we (also?) consider contributing something to e.g. https://github.com/helm/charts ?
 mstoodle
on 13 May 2020
mstoodle
on 13 May 2020
@mstoodle I think you beat me to it - I was preparing this note!
There are two approaches,
1) charts are put in a common public chart repos from where developers draw apps For example, bitnami helm/charts ibm/charts eclipse has one. wildfly for example is in bitnami and does not host on its own repo. open-liberty is on ibm/charts. A lot of apps seem to do that (including prometheus).
2) Some host charts in their own repo (which takes devs couple of extra steps to use the charts) eclipse-che is an example.
I was thinking hosting on openj9 and then a CI/CD process to host on multiple helm repos may be a way to go (helm bitnami) (or just stick to one).
Just to start the conversation on openj9 our charts may look like this (please comment):
/
.
..
buildenv
deploy
|
stable
|
openj9-jitserver
|
charts
|
openj9-chart
operators
|
openj9-operator
on eclipse-che it looks like this:
and publishing other repos through CI/CD - like
helm/charts/stable/openj9
helm/charts/stable/openj9-operator
bitnami/charts/bitnami/openj9
bitnami/charts/bitnami/openj9-operator
By developing openj9's own charts openj9 can avoid dealing with major changes to other repos but while publishing to them as well to be widely and easily available. This includes adopt-openjdk. We can contribute a more generic version to support all adopt flavours.
raguks
on 13 May 2020
ok, it sounds like hosting them at openj9 first helps developers to quickly iterate to something that will work well for our users, but once we get things settled, we can then pursue making it easier for users to get them.
I'm still not sure I understand how we'll maintain and test this material though. Can you put a few more words to "Charts have an inbuilt way to test deployments" ?
mstoodle
on 14 May 2020
As part of the Chart validation we can have some tests defined. These test if the Chart deploys openj9 in our case. We can also add actual functional verification of jitserver in particular. To run these tests however, we need to define some Jenkins jobs and need to use openj9 test infrastructure. @chrisc66 @KevinBonilla may be able find out more if @smlambert or someone can point them to CI/CD for openj9.
@mstoodle The name for the Chart is kind of important because its used in many places. Since we need to support openj9 and jitserver what should the Chart be called? openj9-jitserver if we only consider jitserver. openj9-chart openj9-operator if we have to consider openj9 in general.
Appreciate some suggestions here.
raguks
on 19 May 2020
I want to circle back to my earlier question:
Are the helm charts / operators for JITServer deployments or intended for a general openj9 deployments?
My (admittedly limited) knowledge of Helm is that charts are for deploying applications, not runtimes. Is the proposal to add basic charts, really templates, that can easily be adapted by users to deploy their applications on OpenJ9?
It would be good to clarify how this proposal fits with the general Helm guidance.
Additionally, if this is about showing how to deploy applications with Helm charts so they employ jitserver, is it accurate to characterize this effort as providing more of an example chart that highlights the (few?) stanzas of yaml required to enable jitserver?
DanHeidinga
on 19 May 2020
For the operator, have you seen the https://github.com/application-stacks/runtime-component-operator project? It provides a set of base capabilities other operators can build on:
This Operator can also be imported into any runtime-specific Operator as library of application capabilities. This architecture ensures compatibility and consistency between all runtime Operators, allowing everyone to benefit from the functionality added in this project.
I ran across this when looking at the Open-Liberty operator which can already control JVM dump facilities.
There may be an opportunity to work with the Liberty community to share code around these capabilities.
DanHeidinga
on 19 May 2020
@DanHeidinga There are two different questions here. 1) Regarding the nature of openj9 deployment and 2) feature set and libraries.
1) The proposed chart/operator is to deploy openj9 as jitserver only primarily. Because openj9 can be deployed using the same chart as a non jitserver we can provide that option. OpenJ9 deployment works well for java applications that just need a jdk and no web-server. This is because we use adopt-openj9 docker images that are optimized for java(openj9 community is constantly working on it). The work an application developer does is to build an application image based on adopt-openj9 image and use it in the chart to deploy openj9+her app (you can think of that as template in that sense). It is also useful for development and developer advocacy. But the primary deployment is jitserver. How it actually gets used may change based on users preference. Making allowance for it gives openj9 that space. Need to grab a late breakfast! So will get back on the 2nd question a bit after. This is a very good question. Helps us get clarity on these issues.
raguks
on 20 May 2020
- While OpenLiberty operator has been around for a year, use of runtime-component-operator is new (roughly 1.5 months ago). Yes we need to explore its use. However, I think we need to do this in steps once we have a basic helm chart out.
raguks
on 21 May 2020
Thanks @raguks Based on your answers above, I'll update the title of this issue to focus on adding a JITServer Helm chart. That sounds like the primary goal being worked towards here. We can move general discussions about Operators into another issue.
I'd like to hear more about the deployment story for how this Helm chart works with deploying other applications. What's the relationship between the JITSever Helm chart and the user's application Helm chart? Does the user one need to reference the JITServer one? Does the JITServer one replace the user's existing chart? Is the new chart an example where users would only need to copy/paste a "stanza" from it to their existing charts?
If there's a simple picture that shows how the deployment works and the relationships between the JITServer Helm chart and existing charts that would help clarify the goals of this issue.
Can you also list out the steps a user would take to integrate the new Helm chart?
This is a lot of questions but I'm hoping they clarify the direction of this issue and show how the chart would be consumed.
DanHeidinga
on 17 Jun 2020
@DanHeidinga Our goal as part of this is to have chart/operator for both openj9 and jitserver. Yes there is material on end to end use of charts/operators. Simply put, users deploy jitserver and update their application to compile on it by using the JAVA_OPTION. There are many possibilities on how they can do it at the application including updating their charts/operators/pipeline.
I can go over the details in one of the community calls, possibly week next (coming week is bit busy for me).
raguks
on 18 Jun 2020
I've tentatively scheduled you for a lightning talk on July 8 as there won't be one on July 1 due to holiday in Canada.
As that's a couple of weeks a way, it would be good to continue the conversation here in the issue in the meantime.
Can you expand on:
Simply put, users deploy jitserver and update their application to compile on it by using the JAVA_OPTION. There are many possibilities on how they can do it at the application including updating their charts/operators/pipeline.
It's hard for me (and likely anyone else) to really understand what's being proposed here without some of those details and workflows. More context is needed to understand how this fits in the project
DanHeidinga
on 18 Jun 2020
@DanHeidinga I will post a proposal here. July 8 sounds good.
raguks
on 23 Jun 2020
Here are the slides used for helm/operator talk: Please ask questions.
OpenJ9DeploymentLightning.pdf
We are using best practices from helms own chart repo and other enterprise examples.
raguks
on 8 Jul 2020
Thanks for the lightning talk yesterday. This approach sounds like a useful starting point for users interested in trying out JITServer. It would be good to write up some blogs showing the helm chart, how to create the user roles, etc and the minimal additions/changes needed to the application to get started using JITServer.
This approach seems useful for users interested in trying out JITServer to get bootstrapped. My impression is that it's very "JITServer-centric" rather than application centric. That's partly why I suggest the blogs above - an application already deployed in K8 will have existing deployment configuration. It should be clear to these kinds of users what the minimal integration they need to deploy the JITServer as part of their application.
And that brings me back to what I've been calling "deployment physics" in conversations with yourself and others. The clearer the project can be on how to deploy a JITServer with an application the easier it will be for users to adopt it. Whether that's a JITServer per pod (probably not unless there are multiple containers - 3+? - in the pod), or a shared JITServer per some number of pods, or whatever the configuration may be.
With the information in the presentation, I'm still unclear on the answers to the above and from https://github.com/eclipse/openj9/issues/9443#issuecomment-645427397
DanHeidinga
on 9 Jul 2020
@DanHeidinga The charts will have a README. Users just have to just run some commands.
Here is a dipiction of how the deployment works:
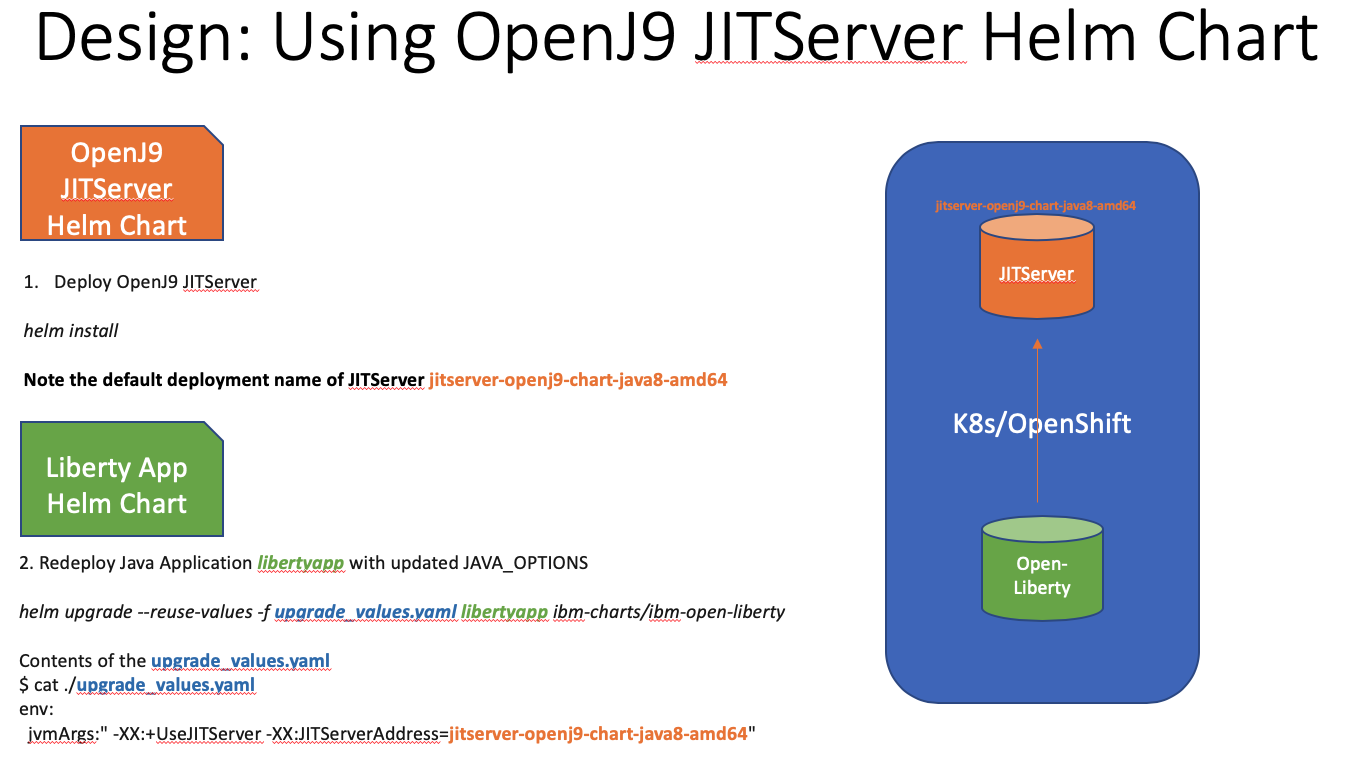
Operator works exactly like this but the commands aare based on openshift client oc. If you still have questions let me know. There are many possible combinations but we will keep it simple with an example.
raguks
on 16 Jul 2020
@DanHeidinga yes we can keep this JITServer centric but if someone wanted to try just openj9 standalone app they can. Yes we will document in operator README as well as will work on blog posts when the PR review begins. We also have to work on automated tests. tests are manual as of now. We will look at test infra on how to do that. We may have to work out a single node OCP cluster or something to get that to work @chrisc66 @KevinBonilla
raguks
on 27 Jul 2020
Had some discussion with @raguks, looks like the complexity of Runtime Component Operator is very high, 1M+ lines of code and building an extra layer is likely to takes same amount of code. We are looking to work around and start with a helm chart and helm based operator. Complexity can be added later
The helm chart is straight forward, and created by our runtimes team. The helm operator is generated on top of helm chart by a tool called operator-sdk. Its logic is a bit complexed than the helm chart, but still much simpler than RC operator. I will again create a draft PR into this repo to show the helm chart first.
 chrisc66
on 15 Sep 2020
chrisc66
on 15 Sep 2020
I'm going to link to https://github.com/eclipse/openj9/pull/10606#issuecomment-700763909 and quote it here to ensure the conversation doesn't get lost:
These are very broad goals that need to be developed and clarified further into actionable steps.
The key piece of feedback for this effort is to start by working through the deployment scenarios assuming the user already has a way to deploy their application. JITServer needs to be an add-on, and not the key focus. Users care about their applications and how they deploy them first, and tools like JITServer second.
Please, take the time to write out the following scenarios:
Existing application deployed with Helm adds a JITServer. What is needed here?
Existing application is horizontally scaled so there are two instances running now. How does it connect to the JITServer
Existing application can scale to N instances. When does this require more JITServers?
Application is upgraded and has a new base JDK. What happens to the JITServer it was previous connected to?
Same as above but now with both old and new instances still running - how is the JITServer handled?
And I'm sure there's more examples of how deployments need to work that should be figured out here.
The examples so far have assumed a 1-1 between the application and the JITServer and have put the JITServer deployment as the focus. That's too simplistic of a model for how deployments will need to really work.Before we can review the code, more of these details need to be clarified and understood.
DanHeidinga
on 29 Sep 2020
Please refer to the User Story and Roadmap:
JITServer Deployment User Story.pdf
Thanks @raguks and @mpirvu for pulling together this document to explain the user experience and roadmap.
After my first read through, I have some questions that hopefully we can get sorted before tomorrow's meeting.
In the "JIT Server Deployment User Story" section:
It outlines the benefits of JITServer as improving startup & rampup in constrained cloud envs and reducing peak footprint thereby increasing application density. It states that users need to:
- Deploy JIT Server in their environment easily
- Configure Java applications to enable the use of JITServer
Does 2 include modifying the "Request" and "Limit" settings for the deployment so that the applications can be packed more densely? Would "application density" be increased without something changing the requested application deployment configuration resources? I'm trying to figure out how "the increased application density" goal is addressed in this document.
"There are many possible deployment options such as JITServer and apps on the same VMs or on different VMs."
I tend to think in terms of "pods" when discussing K8 deployments. Did you mean "pod" or possibly "Node" rather than "VM" in this section. If not, can you clarify the meaning here?
In the "User Experience Roadmap for OpenJ9 JIT Server Deployment" section:
"4. Allow Serverless support on-demand java applications/functions."
Can you expand on what you mean here? What does "allow serverless support" mean for JITServer? What does this look like for a user?
"6. Very good documentation with examples, steps and clearly laid out best practices etc. This includes openj9 blogs and articles."
A very big +1 to this!
In the "An overview of JIT Server usage" section:
Key takeaway: application connects to a single, version-specific JITServer endpoint. Multiple JITServer endpoints can be deployed but the application needs to be updated (at deploy time?) to connect to a single JITServer endpoint.
In the "End to End User Scenarios" section:
First, I like the use of personas here to clarify the intended user and their priorities.
Until this point though, it seemed like the document was proposing deploying JITServer in conjunction with an application due to things like:
- "5. Define workflow for application and JITServer upgrades and possible automation (Day2 Operations)."
- " can be run on same node as the application(client) or on aremote node"
- "versions need to match between client and JITServer"
This section switches to discussing JITServer as a cluster-wide shared service managed by the K8 Admin.
Is this an unintentional shift?
In the "User Story" section:
The opening paragraph sounds like JITServer is being enabled and added to the deployment by an external group rather than the developers of the application (Not a very devops friendly approach!). But then it talks about the user needing to have an exact version match between their application the JITServer service. This seems untenable if imposed from outside the dev team without support to match the JITServer to the application JVMN. It's also untenable if deployed as a cluster wide service unless that service can dispatch to the "right" JITServer version.
"2. c. Select autoscaling to bring up another JITServer (or scale down to zero when JIT Server is not used)."
Is this relying on K8's ability to load balance across the JITServer pods and adding some logic to indicate when to scale out?
Overall comments:
There's some good information in here and it clarifies parts of the story. Unfortunately, it isn't clear on which deployment scenarios are being targeted, whether with the application or as a cluster-wide service. Either one (or both) are valid options but have different characteristics and need to be represented by different personas.
Being very clear on which personas are in play and which are the immediate target would help focus the work being done for JITServer and provide a clearer message to users who may be interested in experimenting with the tech.
Can you separate out the two personas mentioned so far (cluster admin & development team)?
There are two other JITServer personas that would be good to reference for deployments as they may have other additional deployment needs: namely a test persona and a performance engineer. Both need to be able to deploy JITServer with their applications and adding them to the picture may change the the priority of items in the final "Roadmap" section.
DanHeidinga
on 19 Oct 2020
Does 2 include modifying the "Request" and "Limit" settings for the deployment so that the applications can be packed more densely?
Yes, typically the user needs to reduce these values in order to coerce Kubernetes scheduler to pack more JVM containers (pods) on the same node.
I tend to think in terms of "pods" when discussing K8 deployments. Did you mean "pod" or possibly "Node" rather than "VM" in this section. If not, can you clarify the meaning here?
In this case VM==node. The node can be a virtual machine (more common) or a physical machine.
What does "allow serverless support" mean for JITServer?
In a serverless environment JITServer would scale back to 0 when there are no incoming requests. At the moment this is not possible; the implementations that we looked at only watch for http traffic and not TCP.
The opening paragraph sounds like JITServer is being enabled and added to the deployment by an external group rather than the developers of the application (Not a very devops friendly approach!).
The user case that is covered is an admin that deploys applications in production across a cluster. It could be one application or a bunch of them connected to one JITServer endpoint or several of them. The admin must ensure the servers match the clients version wise.
The developer case is not described. It's debatable whether developers care that much about packing densely. I imagine each developer could launch their own instance of JITServer and that solves the versioning problem.
Is this relying on K8's ability to load balance across the JITServer pods and adding some logic to indicate when to scale out?
Yes. JITServer replication can be based on CPU and/or memory consumption. Additionally, custom metrics could be defined and exported by JITServer, but this functionality is not yet implemented.
 mpirvu
on 20 Oct 2020
mpirvu
on 20 Oct 2020
Does 2 include modifying the "Request" and "Limit" settings for the deployment so that the applications can be packed more densely?
Yes, typically the user needs to reduce these values in order to coerce Kubernetes scheduler to pack more JVM containers (pods) on the same node.
It sounds like we're on the same page that the user needs to modify their deployment to change the "Request" / "Limit" settings in addition to adding the "-XX:+UseJITServer" enablement options to get the increased packing / application density. As this is listed explicitly as a goal in the user experience document, I'd expect more information regarding the user needing to do this (automatic vs manual), how to tune those settings when JITServer is used, and when to modify them to show up in this document. Are there more sections coming to cover this?
What does "allow serverless support" mean for JITServer?
In a serverless environment JITServer would scale back to 0 when there are no incoming requests. At the moment this is not possible; the implementations that we looked at only watch for http traffic and not TCP.
It would be clearer to talk about the JITServer service scaling to zero when not needed. I initially read this as adding support for serverless application deployments (ie: user apps on Lambda or KNative).
The opening paragraph sounds like JITServer is being enabled and added to the deployment by an external group rather than the developers of the application (Not a very devops friendly approach!).
The user case that is covered is an admin that deploys applications in production across a cluster. It could be one application or a bunch of them connected to one JITServer endpoint or several of them. The admin must ensure the servers match the clients version wise.
The developer case is not described. It's debatable whether developers care that much about packing densely. I imagine each developer could launch their own instance of JITServer and that solves the versioning problem.
This may be the fundamental disconnect we've been hitting in our discussions up to this point - namely, the question of who is responsible for deploying the JITServer.
The description of "an admin that deploys applications in production across a cluster" matches the classic IT approach where developers write an application and toss it over the wall to ops folks who own the deployment. It doesn't map well to my understanding of how teams deploy on K8 as in these newer environments, the model has changed to more of a "you wrote it, you own it" model that includes owning the deployment. And deployment is done continuously[*] as changes move through the CI/CD pipeline.
When I mention the "developer" use case, I should be more explicit that I'm referring to a devops-style deployment where the team that owns the application development also owns it deployment. In this model, I'd expect the development team to also own the JITServer and handle its deployment. To be successful in this model, it's imperative that deploying the service, connecting to it, tuning the app using it, and upgrading the service along with the application are trivial to do.
There's a second model that's intermingled in the document where the JITServer service is owned by another team (call it the "OpenShift Admin/Build Captain" to match the term used in the document) which is responsible for providing JITServer as a managed service to other applications. In this model, there's a managed JITServer service applications can connect to and treat as a black box - they just need the endpoint and the backend will take care of version matching, etc. The users of this service still need the monitoring support to understand how to tune their K8 Request/Limit variables and to understand how much of their JIT compilation is successfully being offloaded, but have an easier time working with the service as they only have to connect to it, not deploy it. The Admin/Build Captain role needs to handle all the complications with having applicable backends for each supported version, scaling the backends, etc.
Both of these are valid use cases and both need some of the same features.
In order to have a productive conversation about the user experience, we need to be clear on who's experience we're talking about. The best way to do that is to split the two deployment styles into different personas and talk about what each needs from a JITServer.
[*] = for some definition of "continuous" =)
DanHeidinga
on 20 Oct 2020
Further though, focusing on the devops stye deployment would provide an easier onramp for users who want to try JITServer out. Needing to stand up the separately managed service may be overkill for most users in the "try" phase.
DanHeidinga
on 20 Oct 2020
After clarifying that the model we are pursuing is that of devops workflow and developer experience needs to be added to User Experience Roadmap, there is an agreement from all to move forward subject to the following considerations:
- Document in User Story how to deal with JITServer version compatibility when multiple applications with various java versions are running.
- Developer experience — Add the Developer persona experience the User Experience Roadmap. The helm chart documentation has some of this info which needs to be incorporated in the User Experience Roadmap.
- How to derive value by making right settings? Such as decrease memory limit etc to be incorporated in the User Experience Roadmap.
- Look at Eclipse project's own helm charts and see what license they use - to ensure compatibility.
Dan and team are okay with reviewing helm chart once the doc updates and the patch to the PR linked to this issue are in place.
For later:
- Open an issue to generate operator image through AdoptOpenJDK build process and store in Adopt docker repo
- Consideration for operators
— Storing operator image can go to Adopt pipeline
— Storing operator image in RH needs to be done manually and the RH scan as well.
FYI @DanHeidinga @andrewcraik @mpirvu @mstoodle @chrisc66
raguks
on 21 Oct 2020
This is regaring ##4 above
- Eclipse has its own help repo. Good news is it looks like we can push our charts there @chrisc66 can you please check? https://www.eclipse.org/packages/repository
- The license for Eclipse Helm charts is EPL 2.0. I believe it is generated using helm tool. That helps understand what we can use.
https://github.com/eclipse/packages/blob/master/charts/hono/Chart.yaml
#
# SPDX-License-Identifier: EPL-2.0
#
@chrisc66 @mpirvu I am hoping you will take care of #5 #6 above.
For #1 #2 I have made doc updates and updated the description at the very top @chrisc66 @mpirvu we may need to update the helm chart README for #3. Can you please look at #3
@mpirvu you may please review the upcoming patch from @chrisc66 and proceed to complete the review of this PR.
When the PR is approved - we need to follow the steps to push the chart in a way it gets into Eclipse Chart Repository. Thank you.
raguks
on 2 Nov 2020
- Eclipse has its own help repo. Good news is it looks like we can push our charts there @chrisc66 can you please check? https://www.eclipse.org/packages/repository
Thanks for finding this @raguks. Have you confirmed whether this helm repo is appropriate for OpenJ9? A quick read makes it sound like it's for Eclipse IoT projects:
The Eclipse IoT packages project decided to host a Helm chart repository in order to share the effort of validating and publishing charts. Eclipse IoT projects are welcome to re-use that infrastructure to publish their charts, whether they are part of an IoT package or not
For 2, can you find one of the Contributor Questionaries (CQ) for one of those charts? It would help to clarify how they were created and speed the creating of a CQ for the openj9 chart
DanHeidinga
on 2 Nov 2020
I think you are right - looks like only IOT. @chrisc66 will check and see if there are others. If not a small repo open openj9 in a helm repository format will allow us to host in one place and push to others if required.
raguks
on 2 Nov 2020
Adding more details for #5 and #6 from previous comment. These steps can be taken care of after the helm chart discussion.
Going beyond the helm chart and extending to operator, step 5 and 6 are needed. Operator is another K8s deployment method. It deploys a container (the operator image) that monitors the application container (JITServer image) at runtime. This means we need to host the operator code, build images (from operator code), and store images. Helm chart does not include build and store images thus helm is relatively simpler.
- Open an issue to generate operator image through AdoptOpenJDK build process and store in Adopt docker repo
The extra steps needed are to build and store operator images. The ideal location of this operator image would be Adopt docker hub, as a parallel project to AdoptOpenJDK images that contains OpenJ9 images.
- Consideration for operators
— Storing operator image can go to Adopt pipeline
— Storing operator image in RH needs to be done manually and the RH scan as well.
Other operator considerations:
6.1 Adding #5 to Adopt automated pipeline, which includes
- Build operator images from source code
- Run automated tests on operator images (CICD)
- Store operator images to Adopt Docker Hub
6.2 RedHat provides its own operator certification (operator image scan), which allows users to deploy operators directly on OpenShift UI through Operator Hub. The RH certification (image scan) needs to be done manually. Once the certification is obtained, the operator image can be stored and accessed on RedHat image registry.
chrisc66
on 2 Nov 2020
Related issues
 Jeeppler
·
5Comments
Jeeppler
·
5Comments
 pshipton
·
3Comments
pshipton
·
3Comments
 xliang6
·
3Comments
xliang6
·
3Comments
 dsouzai
·
5Comments
dsouzai
·
5Comments
 JasonFengJ9
·
5Comments
JasonFengJ9
·
5Comments