Openj9: Investigate effect of HPRs on throughput performance and compile time
With the merge of #4378 I've set upon the quest to further understand how HPRs behave on the Z codegen and if having them is actually valuable. HPR support has historically been the source of quite a lot of defects and register allocator type issues. #4378 addressed part of them but the code is still not in the best shape. If HPRs are not providing any value we should think about their fate.
HPR support in the Z codegen can be broken up into three main pieces:
- GRA HPR support
- Local RA HPR upgrades
- Local RA HPR spilling and filling
Let's talk about each one and understand their purpose.
1. GRA HPR support
Support on GRA has been bolted on at the common level and HPRs were added in as an afterthought. As a result there are plenty of workarounds placed in the various pieces of code which make HPRs "look" like normal GRP global registers. There are tons of paths which restrict their use, based on what the IL looks like and whether it _may_ be a good idea to use HPRs.
A canonical example of when HPR registers _should_ be used as global registers is for loop iterator variables. Consider the following for loop:
for (int i = 0; i < <loop condition>; ++i) {
<loop body>
}
If i is simply used as an iterator variable then it is a prime candidate for global HPR assignment. However typical loops usually do not look like this. Typically i will be used to index into an array, or be passed as a parameter to a call, or be used as part of an arithmetic operation, etc. As such this immediately evicts HPRs in GRA from consideration because z/Architecture only has a handfull of instructions which can act on HPRs.
In fact the set is so small we can categorize the instructions as:
- compares
- additions, subtractions, and logical OR and AND
- loads and stores
That's it! There are further restrictions on the register operands of such instructions. For example for addition the target register cannot be a GPR low word register, i.e. there is no instruction to add a GPR and an HPR and store the result in a GPR. Combined with other restrictions, such as HPRs not being able to be used for addressing memory, many "compare and branch" instructions not supporting HPRs, etc. we come to quite a hefty number of restrictions.
Even in the best case, if we are able to overcome all the restrictions and the code looked as nice as it does in the above example there are other side-effects of using global HPRs. For example if i were to be allocated in an HPR and it ended up participating in an arithmetic operation with a GPR register we would have to shuffle the HPR into a GPR during local register allocation, perform the operation, then shuffle back. This incurs a ton of HPR shuffling at the local level.
2. Local RA HPR upgrades
Local RA HPR upgrades happen during local register allocation. As we're assigning registers during instruction selection forward pass we keep track of the types of instructions the register is being used in. If a register gets used within an instruction which doesn't have an equivalent HPR instruction, the register is marked with a flag indicating that this particular register should not be upgraded to an HPR during local register allocation.
After instruction selection is complete, and register which isn't marked with the flag is considered a candidate for HPR upgrades. Local RA then eagerly "upgrades" the register to an HPR when it is first assigned, and in theory the register will not get shuffled back and forth into GPRs because presumably every instruction in which the register is used can also be upgraded to an HPR instruction. As such when we allocate the locally upgraded HPR to an instruction, we also upgrade the instruction to the HPR counterpart.
This is all well and good, except for the fact that we do this eagerly. We upgrade every instruction that we can, irregardless of the register pressure. That is to say, we do not take into account whether there was free GPRs at the point we chose to upgrade a register to an HPR.
What ends up happening in this case is that we may needlessly generate a ton of HPR "upgraded" instructions when the register pressure was low and we could have instead used GPRs. GPR instructions are _always_ faster than their HPR counter parts because their encoding is shorter (fewer bytes in the icache) and some HPR instructions are cracked in millicode at the hardware level where as the GPR counterparts are implemented in hardware.
3. Local RA HPR spilling and filling
The Z local register allocator is able to spill and fill 32-bit virtual registers into the high word of other 32-bit virtual registers which live inside the low word. This effectively doubles the number of 32-bit real registers we have for assignment at the local level. This can be useful in 32-bit JVMs as it effectively doubles the number of real registers. On 64-bit this may not be the case as most virtual registers are 64-bit virtual registers (i.e. they end up being used in 64-bit instructions in their live range) and as such we cannot spill anything in the high word of 64-bit virtual registers which are assigned to full 64-bit GPRs.
In general filling and spilling just involves loads and stores of HPRs to and from the stack and is likely the most useful part of HPR story on Z.
 fjeremic
fjeremic
All 28 comments
To collect statistics I've measured three benchmarks with different characteristics to capture a wide range of data. I've placed custom code in certain places to be able to disable each piece of HPR exploitation outlined above. I've also added static debug counters all over both GRA and local RA to keep track of various quantities which are explained as follows:
- hpr
- hpr/shuffle
- Number of times we generated a local RA register shuffle of each type
- hpr/shuffle/FPR
- hpr/shuffle/GPR
- hpr/shuffle/HPR
- hpr/spill
- Number of times we had to locally spill a virtual register of each type
- hpr/spill/FPR
- hpr/spill/GPR
- hpr/spill/HPR
- hpr/spill/HPR/memory
- hpr/spill/HPR/register
- We have two types of HPR spills; one for when we spill HPRs to memory, and one for when we spill GPRs to HPRs, i.e. HPR register spills
- hpr/total-compilations
- The number of individual method compilations (including recompilations)
- hpr/upgrade
- The number of times we did a local HPR register upgrade
- hpr/upgrade-found-free-source-GPR
- hpr/upgrade-found-free-target-GPR
- The number of times there was a free GPR to assign to either the target or the source HPR that we ended up upgrading
I'm attaching the full spreadsheet here for your viewing, but I'll also summarize the results in screenshot form so that we may talk about them.
fjeremic
on 5 Feb 2019
DayTrader 7
Throughput
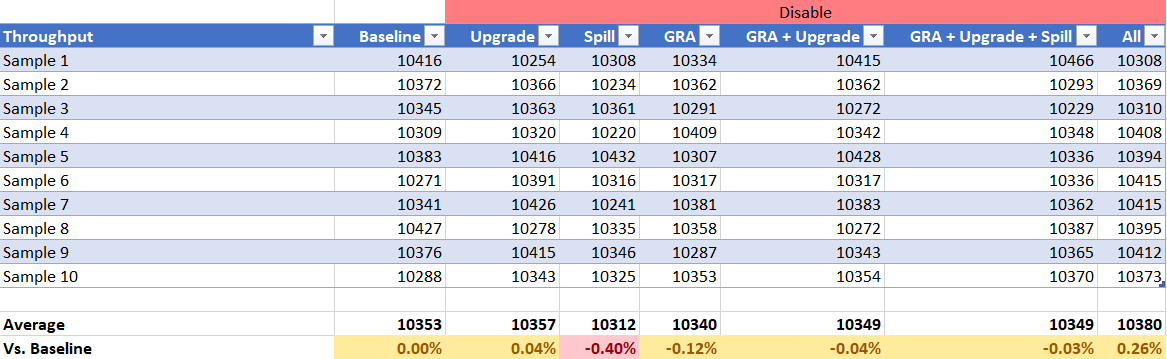
The throughput results indicate that disabling each individual piece or some of them combined, or even disabling all HPR support in the JIT does not affect throughput at all. The standard deviation on my machines is roughly 0.3%. It seems that local RA spilling is the only piece of HPR support that is worth much of anything when disabled individually. However it seems that disabling all of HPRs provides a slight improvement in throughput.
Compile Time
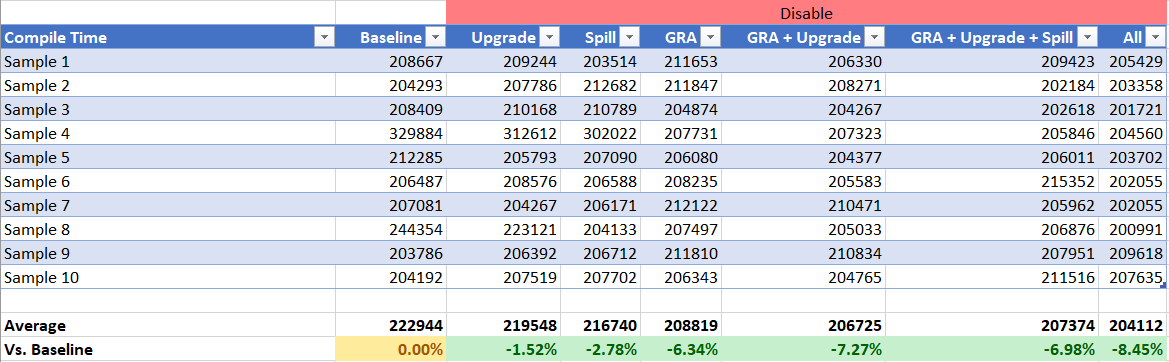
In all instances the compile time improves. In the case of GRA the compile time improves significantly and the numbers stack up as they should. It seems GRA HPR handling is worth roughly 6.5% in compile time.
Debug Counters
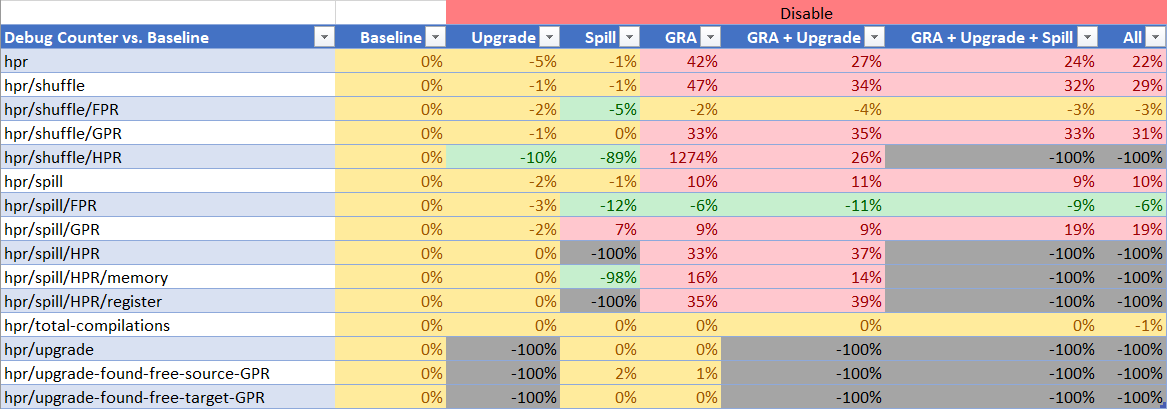
This is IMO the most interesting part. Green colors represent a decrease in the static count for each quantity while red represents an increase. Yellow represents roughly what I assume to be the noise range.
In the case of disabling local RA upgrades we have improvement across the board, with a big reduction in the number of HPR register-to-register shuffles that end up happening. From the last two counters we see that every single time (100%) when we upgraded an instruction to an HPR instruction at the local level, there were free GPRs available for assignment. That means we could have chose not to upgrade to an HPR and it always 100% would have been the right choice.
If this were not the case, then disabling upgrades would result in an increase in GPR spills, however we see exactly the opposite. We see less GPR spills happening.
In the case of local RA HPR spills we see a massive reduction in HPR spills, which indicates the code for HPR upgrades is working as intended, i.e. we are not spilling HPR upgraded registers, as intended. However what is intriguing is that the number of HPR shuffles drops by a significant amount indicating that HPR spills are the big player in the number of HPR instructions generated across the JIT. Also intriguing is that the number of FPR shuffles and spills improves for some reason. I do not understand why. I will need to investigate this.
When it comes to GRA things get very interesting. Note again that throughput is more or less constant across all of these runs, and that compile time improves in every single case. Now when GRA HPR support is disabled local RA debug counters go out of whack. We suddenly see a 10x increase in HPR shuffles that are generated which I don't quite understand yet, and a significant increase in GPR register shuffles.
The GPR portion I do understand. It appears that when HPR GRA is enabled we effectively lose the linkage registers from global register consideration by a bug in the GRA logic which attempts to avoid using HPR registers for parameter symbols. It had the right ambition in mind but the execution effectively voids the GPRs from consideration as well!
In fact this is obvious from any log file as you'd typically see paramter symbols get allocated global registers such as GPR6, GPR7, etc. when the arguments come through in GPR1, GPR2, etc. You will typically see an LG or LGR shuffle right after the prologue as a result of this.
Disabling HPR GRA fixes this problem and we're suddenly able to allocate linkage registers. This causes a ton more GPR register shuffles to happen in the cold paths of the method which are almost never executed anyway. GRA has made a tradeoff to improve the hot paths of the method at the cost of more shuffling (for linkage calls) in the cold paths.
fjeremic
on 5 Feb 2019
ILOG
Throughput
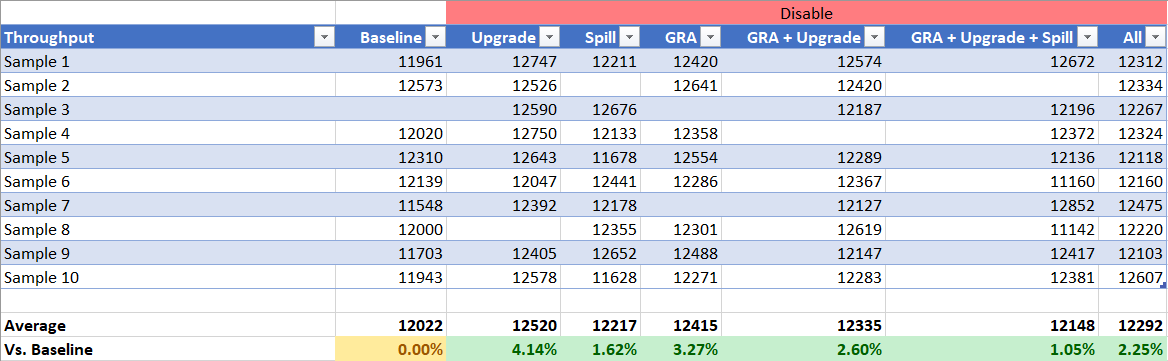
ILOG throughput is more interesting than DayTrader 7 as we actually see noticeable improvements from disabling pieces of HPR support! In fact disabling GRA HPR support nets us 3.25% in throughput on this benchmark. This is likely because of the linkage register issue noted above. Disabling HPR upgrading also shows significant improvement of 4%. And just like with DayTrader 7 disableing all of HPR gives a modest 2.25% improvement. The standard deviation on the benchmark was roughly 0.7% so these are clear improvements across the board.
Compile Time
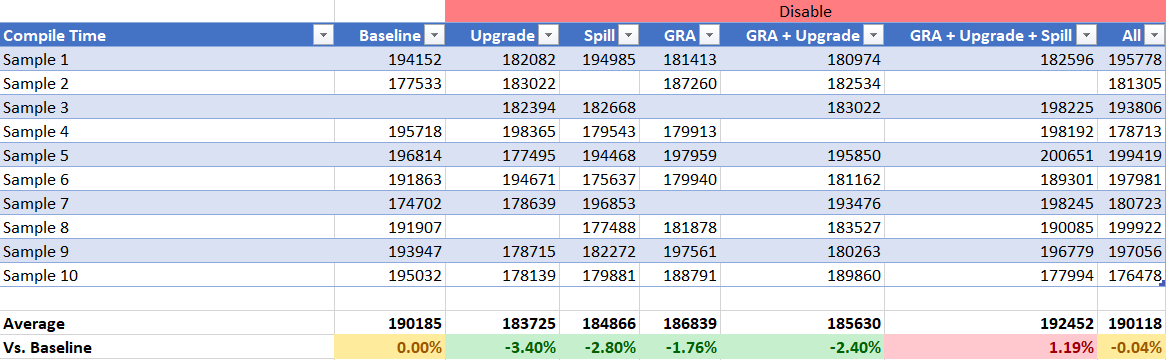
The compile time story is nearly identical to DayTrader 7. I would not consider the compile time metric important for this benchmark predominantly because it generates classes at runtime so the JIT is always compiling things in the background which is skewing the numbers to more or less all look the same. This is why there is a pretty high standard deviation in the results.
Debug Counters
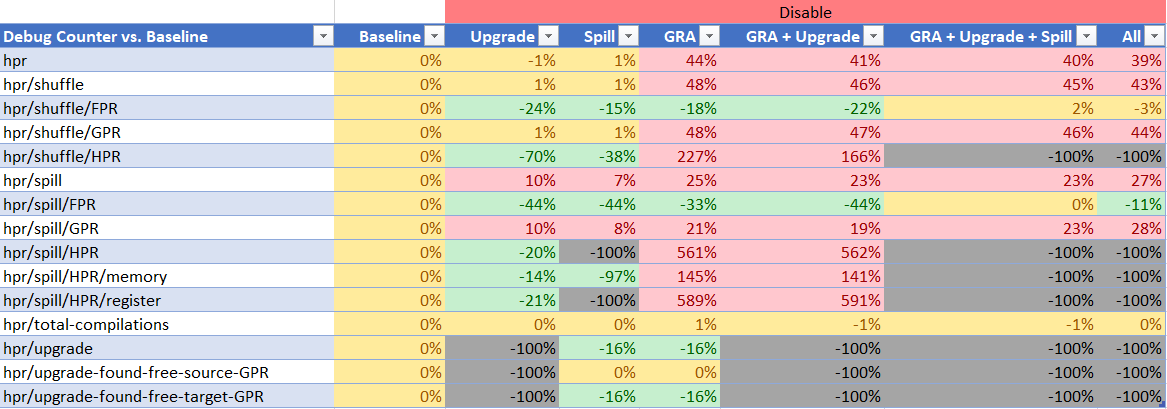
The debug counters tell the same story as in DayTrader 7.
fjeremic
on 5 Feb 2019
SPECjvm2008
Throughput

There were too many sub-benchmarks to run and it takes a long time. Since we had 7 different configurations I didn't have the compute time for 10 samples so I only did 3. Never the less the story here is similar to ILOG. Improvements across the board, and roughly the same improvement by disabling all of HPR support.
Compile Time

This is where the number of samples comes to bite us. I'm not sure I trust any of these numbers given the high ~10% standard deviation.
Debug Counters
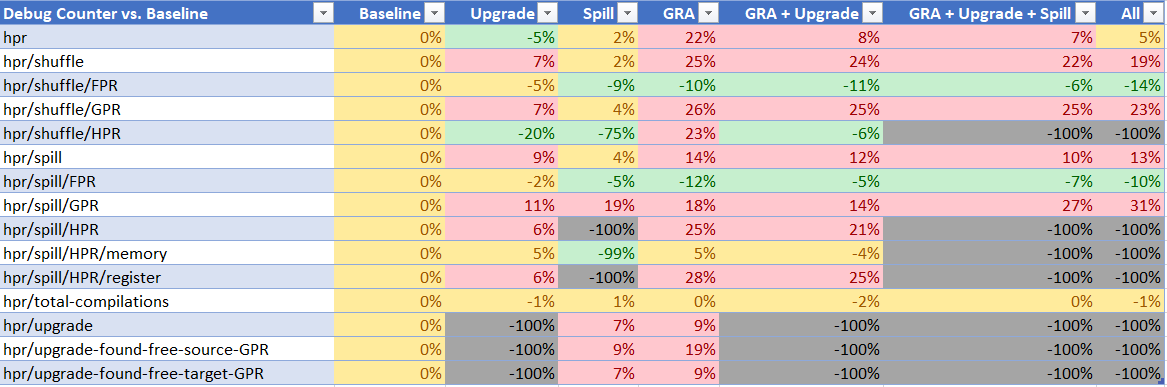
Same as all the above.
fjeremic
on 5 Feb 2019
Subscribing @vijaysun-omr and @joransiu if you ever get a chance to read the data. With all of the above I've heavily inclined to do one of the following:
- Disable GRA HPR support
- Disable GRA HPR support and local RA HPR upgrading
- Disable all HPR support
At the end of the day the reality is that HPRs are not giving us anything in terms of throughput, and are sometimes costing us throughput. They are a significant cost of compile time, and a huge contributor to complex and non-deterministic functional bugs over the years.
I'm not inclined to keep a feature on life support if it does not provide benefit in a general case and if I cannot envision scenarios in which it can provide a benefit.
Would love to hear everyone's opinions on the matter.
fjeremic
on 5 Feb 2019
I'm interested in @joransiu thoughts here as well since I'm not that familiar with how the HPR support is implemented in the z codegen, especially wrt when HPRs are considered vs when GPRs are considered for allocation.
From a GRA perspective, apart from the one bug you mentioned, I'm not sure if we think we can improve anything to make it perform better for HPRs than before. There seems to be some issues even with GRA for HPRs disabled as your data suggests and it's possible GRA magnifies those issues when it runs.
You've run some of the loopy test cases in SPECjvm08 and those are what I'd have suggested to check if there was an improvement somewhere that we might miss in terms of performance. The performance data does make a case for taking at least one of the 3 options you mentioned, and which one we go with really comes down to how much effort we think we are willing to expend to "fix" rather than "disable" (assuming there is something that can be fixed, which I am not qualified to express an opinion on). If we think this will be a lot of effort to "fix" properly, then I'd be fine with any of the 3 options you mentioned.
 vijaysun-omr
on 8 Feb 2019
vijaysun-omr
on 8 Feb 2019
Another thought is to try and find the application that HPR support showed benefit for originally when it was done and run that to see how things look today. e.g. maybe it was envisioned in scenarios when we spill, e.g. across a native call maybe ?
vijaysun-omr
on 8 Feb 2019
Another thought is to try and find the application that HPR support showed benefit for originally when it was done and run that to see how things look today. e.g. maybe it was envisioned in scenarios when we spill, e.g. across a native call maybe ?
I think we'll need @joransiu's input on this one. HPR support predates my time.
fjeremic
on 8 Feb 2019
Kudos on a very complete and thorough analysis of these registers!
In deciding their fate, perhaps one other thing to consider is the tradeoff between the performance benefit of using these registers versus the maintenance cost of keeping them around. An analog that comes to mind from the x86 world is the reclaiming the VMThread register in certain contexts to use as a GPR in high-register pressure scenarios. There was both a global and a local RA component to this. While a good idea in theory, over the years I estimate we spent hundreds of person hours investigating problems associated with it for very little performance benefit in real code. We finally decided to remove it.
You already mentioned there has been a maintenance cost with these HPR registers. Part of the work to keep them (if you decide to) should be to improve their implementation, or other code's tolerance of them. If you don't and your expected performance benefit is still very low then that doesn't seem like a good tradeoff to me.
 0xdaryl
on 11 Feb 2019
0xdaryl
on 11 Feb 2019
You already mentioned there has been a maintenance cost with these HPR registers. Part of the work to keep them (if you decide to) should be to improve their implementation, or other code's tolerance of them. If you don't and your expected performance benefit is still very low then that doesn't seem like a good tradeoff to me.
I don't have hard data but I've fixed many bugs related to HPRs in the last 5 years. HPRs have been the source of some of the more gruesome Z codegen bugs due to their non-deteriministic nature. I agree. We should definitely take into account the maintenance cost of this rather poorly implemented feature, if one can even call it such as in most cases shown above the feature shows a net negative benefit to the environment.
fjeremic
on 11 Feb 2019
With the data you have collected on current applications of interest, the expected work needed to get it into a stable state, and the limited expected performance benefit, I'm inclined to suggest you retire this technical debt.
Although I am curious what the original use case or compilation scenario for this feature was. That was probably 15 years ago so it may no longer be relevant.
0xdaryl
on 12 Feb 2019
That was probably 15 years ago so it may no longer be relevant.
Less than 15 years but getting close to that now as I wrote the original Builder code to handle saving / restoring them when calling into the interpreter or helpers. If I recall correctly, the motivation was to get some additional registers as more registers usually meant faster code :)
 DanHeidinga
on 12 Feb 2019
DanHeidinga
on 12 Feb 2019
FYI another very nasty issue which was thankfully caught by one of the new fatal asserts I've put in has been identified related to HPR spilling in #4526. We lost track of where a virtual register resided as part of local RA, and without fatal asserts this almost certainly is a runtime bug of an exotic kind.
fjeremic
on 25 Feb 2019
That's cool. Have you made a decision on what you plan to do with the HPR support?
0xdaryl
on 25 Feb 2019
That's cool. Have you made a decision on what you plan to do with the HPR support?
No not yet, still waiting on some feedback from @joransiu as he is a stakeholder in this. I'm not very keen on keeping support to be honest in light of all the data points I've raised.
fjeremic
on 26 Feb 2019
@fjeremic : I want to make sure I'm interpreting the categories correctly here:
hpr/spill
Number of times we had to locally spill a virtual register of each type
hpr/spill/FPR
hpr/spill/GPR
hpr/spill/HPR
hpr/spill/HPR/memory
hpr/spill/HPR/register
We have two types of HPR spills; one for when we spill HPRs to memory, and one for when we spill GPRs to HPRs, i.e. HPR register spills
The category (i.e. FPR/GPR/HPR) is the type of register we ended up spilling, in order to free that register up. In the case for FPR, GPR, HPR/Memory, we'd elect to spill that corresponding virtual register to memory? For HPR/register, are we spilling the HPR virtual register to GPR (or another HPR)? The comment suggests it's the other way around.
 joransiu
on 5 Mar 2019
joransiu
on 5 Mar 2019
Even in the best case, if we are able to overcome all the restrictions and the code looked as nice as it does in the above example there are other side-effects of using global HPRs. For example if i were to be allocated in an HPR and it ended up participating in an arithmetic operation with a GPR register we would have to shuffle the HPR into a GPR during local register allocation, perform the operation, then shuffle back. This incurs a ton of HPR shuffling at the local level.
Are you saying that even if it's possible to use *HHLR type arithmetic instructions here, we fail to exploit the opportunity at codegen/local RA time? If a HPR value was shuffled to GPR for some computation, wouldn't it remain that way until the basic block boundary where the GRA dependency would induce it back into an HPR, right? By "a ton" of shuffling, are you suspecting other forms of shuffling beyond the BBs where GPR is needed?
joransiu
on 5 Mar 2019
Based on the analysis above, with the concrete compilation time savings, marginal improvements (if any), and the various functional issues recently, I'd lean towards disabling all HPR. Is there a reason why we started hitting HPR related issues more often recently; the code has been developed quite a while ago...
Is it possible to also get a 31-bit set of SPECjvm2008 runs with the debug counters? I'd like to see how the the GPR spills numbers differ on 31-bit, given the different usage patterns vs 64-bit. Would help better interpret these 64-bit data-points.
joransiu
on 5 Mar 2019
The category (i.e. FPR/GPR/HPR) is the type of register we ended up spilling, in order to free that register up. In the case for FPR, GPR, HPR/Memory, we'd elect to spill that corresponding virtual register to memory?
That's correct.
For HPR/register, are we spilling the HPR virtual register to GPR (or another HPR)?
- hpr/spill/HPR
- This is not an actual debug counter, it is simply present because of the way debug counters work; i.e. it's the sum of the two values below
- hpr/spill/HPR/memory
- This is the total number of times we had to evict a value that lives in an HPR out to memory (generated something like
LFHinstruction)
- This is the total number of times we had to evict a value that lives in an HPR out to memory (generated something like
- hpr/spill/HPR/register
- This is the total number of times we had to spill a value that lives in a GPR out to some HPR, so a register-register HPR spill
fjeremic
on 5 Mar 2019
hpr/spill/HPR/register
This is the total number of times we had to spill a value that lives in a GPR out to some HPR, so a register-register HPR spill
How about the situation where we need to evict a HPR out -- potentially to another HPR or GPR?
joransiu
on 5 Mar 2019
Are you saying that even if it's possible to use *HHLR type arithmetic instructions here, we fail to exploit the opportunity at codegen/local RA time? If a HPR value was shuffled to GPR for some computation, wouldn't it remain that way until the basic block boundary where the GRA dependency would induce it back into an HPR, right? By "a ton" of shuffling, are you suspecting other forms of shuffling beyond the BBs where GPR is needed?
The issue is really the code in [1], which is correct. If you take a look at the add and sub cases we can only upgrade a value to an HPR if the first child is eligible. This makes sense because the high-word instructions we have can perform add and sub if and only if the target register is an HPR and the source register is either an HPR or GPR (AHHHR and AHHLR). There is no high-word instruction that performs addition where target is a GPR and source is an HPR.
If you look at multiply it's even more complicated due to other restrictions.
Now yes things will only get shuffled back into HPRs at extended basic block boundaries if we've managed to globally allocate an HPR. However even for the simples of loops such as the above you would generate at least 2 HPR shuffles, and that's in a perfect world where the loop body is a single extended basic block and the stars align so that i is not used within a memory reference and not part of a multiplication where it is the source register, etc.
@vijaysun-omr and I had a debugging session to dive into GRA to force it to globally allocate an HPR in a very simple arithmetic loop with no branching in the loop body. The shuffle statement comes as a direct observation of that debugging sessions where we saw shuffles being generated due to various restrictions noted above.
fjeremic
on 5 Mar 2019
How about the situation where we need to evict a HPR out -- potentially to another HPR or GPR?
Both of these cases are covered by the hpr/shuffle/HPR debug counter. To avoid further confusion you can see exactly where I placed the debug counters in https://github.com/fjeremic/omr/commit/bf93d5309ddd3305a08a130cfba5de402fcdfea3
_Edit:_
I just now realize the "hpr" prefix in all the debug counters may be a little confusing. This prefix means absolutely nothing. It's just a prefix I picked so that I can filter to -Xjit:staticdebugcounters={hpr*}. The name chosen there can be arbitrary. In the above example the hpr/shuffle/HPR debug counter does NOT mean it's counting a shuffle from and HPR to an HPR. It just means it's counting a shuffle where an HPR was involved. The target may have been a GPR or an HPR.
fjeremic
on 5 Mar 2019
Based on the analysis above, with the concrete compilation time savings, marginal improvements (if any), and the various functional issues recently, I'd lean towards disabling all HPR. Is there a reason why we started hitting HPR related issues more often recently; the code has been developed quite a while ago...
The reason is a combination of all the following:
- Enabling use of HPRs on Linux
- Enabling the use of 64-bit registers on 31-bit by default on both z/OS and Linux
- Elimination of
TR_GPR64and introduction of dozens of fatal asserts - Removal of restriction that all registers used in an OOL path should be marked as 64-bit registers
All of these changes should have been transparent, in theory, had there not been preexisting functional issues with HPRs in the codebase since inception.
fjeremic
on 5 Mar 2019
Is it possible to also get a 31-bit set of SPECjvm2008 runs with the debug counters? I'd like to see how the the GPR spills numbers differ on 31-bit, given the different usage patterns vs 64-bit. Would help better interpret these 64-bit data-points.
Sure, I can get this data as well. Note because of 1. above we use 64-bit registers on 31-bit by default now so we should not see too much of a deviation. I'll get the numbers out this week.
fjeremic
on 5 Mar 2019
Note because of 1. above we use 64-bit registers on 31-bit by default now so we should not see too much of a deviation. I'll get the numbers out this week.
On 31-bit though, pointer sizes are only 32-bits, so I'd expect fewer evictions of HPRs. 64-bit on 31-bit is mainly around long arithmetic computations where we'd traditionally have used reg pairs, right? Those exploitation would be fairly narrow in scope.
joransiu
on 5 Mar 2019
On 31-bit though, pointer sizes are only 32-bits, so I'd expect fewer evictions of HPRs. 64-bit on 31-bit is mainly around long arithmetic computations where we'd traditionally have used reg pairs, right? Those exploitation would be fairly narrow in scope.
That's correct. There will be more opportunity for spilling values to HPRs instead of to memory. I don't see any change in global HPR candidates however. So it is the local instruction selection upgrades and local RA HPR spills that should benefit most.
Note however it's a double edged sword because on linkage points all HPRs need to be evicted because on 31-bit they are all volatile, so unlike 64-bit we cannot preserve values across calls in HPRs. This includes helper calls as well as most of them are TR_CHelper calls. Their uses are limited. See TR::RealRegister::KillVolHighRegs register dependency.
fjeremic
on 5 Mar 2019
Is it possible to also get a 31-bit set of SPECjvm2008 runs with the debug counters? I'd like to see how the the GPR spills numbers differ on 31-bit, given the different usage patterns vs 64-bit. Would help better interpret these 64-bit data-points.
So I tried this and it seems debug counters on 31-bit are broken, even static debug counters. They don't even work on java -version apparently:
> /jit/team/fjeremic/development/improve-ra/sdk-debug-counters-31/bin/java -Xjit:staticdebugcounters={hpr/*} -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 8.0.6.0 - pxz3180sr6-20190220_01(SR6))
IBM J9 VM (build 2.9, JRE 1.8.0 Linux s390-31-Bit 20190311_412040 (JIT enabled, AOT enabled)
OpenJ9 - 1623215
OMR - 6f68853
IBM - 62c4d31)
JCL - 20190219_01 based on Oracle jdk8u211-b76
== Static debug counters ==
This will need to be fixed, but it is a separate issue. The same command works on an equivalent 64-bit JVM. I was however able to collect throughput and compile time information though including a run with all HPR support deprecated from above two PRs. Here are the results:
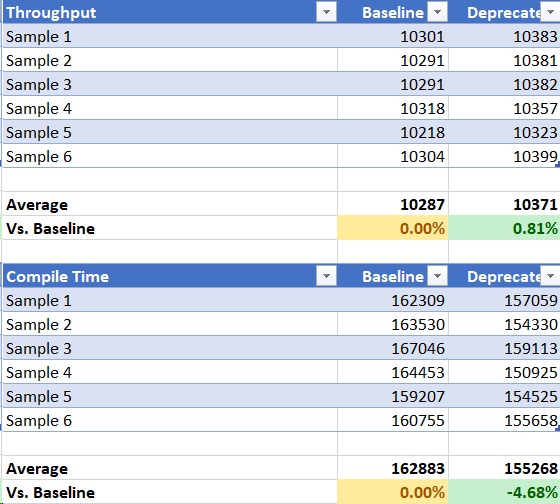
SPECjvm2008 31-bit
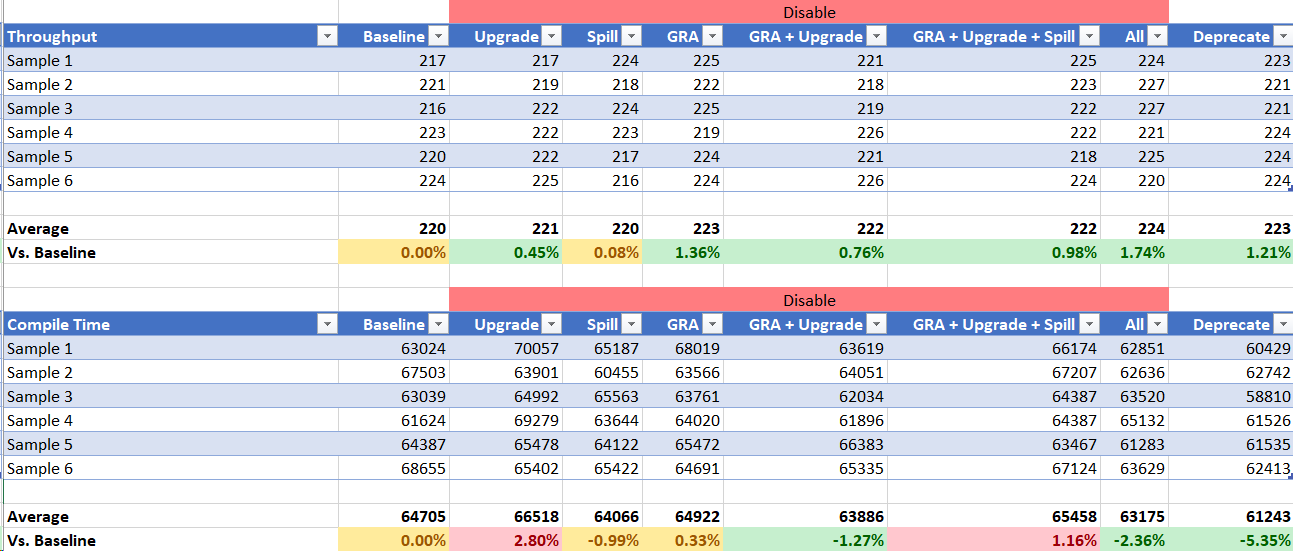
ILOG 64-bit
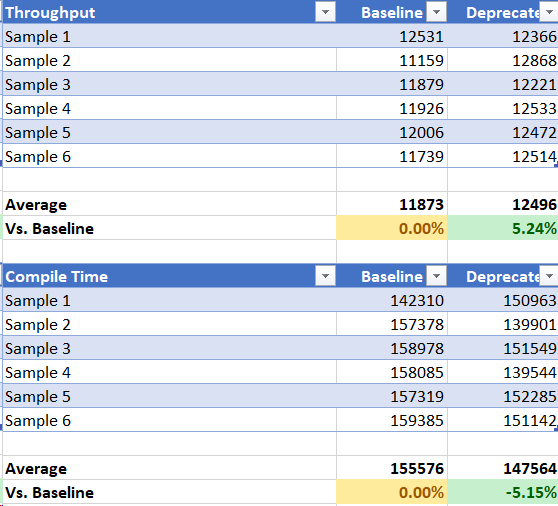
DayTrader7 64-bit
fjeremic
on 14 Mar 2019
Note we are green all across the board. I think this is enough proof we should go ahead with #5042. @0xdaryl, @joransiu, @vijaysun-omr FYI.
fjeremic
on 14 Mar 2019
Related issues
 ciplogic
·
3Comments
ciplogic
·
3Comments
 JasonFengJ9
·
5Comments
JasonFengJ9
·
5Comments
 pshipton
·
3Comments
0xdaryl
·
3Comments
pshipton
·
3Comments
0xdaryl
·
3Comments
 mikezhang1234567890
·
5Comments
mikezhang1234567890
·
5Comments