Openfoodnetwork: Throw more metal at FR Production
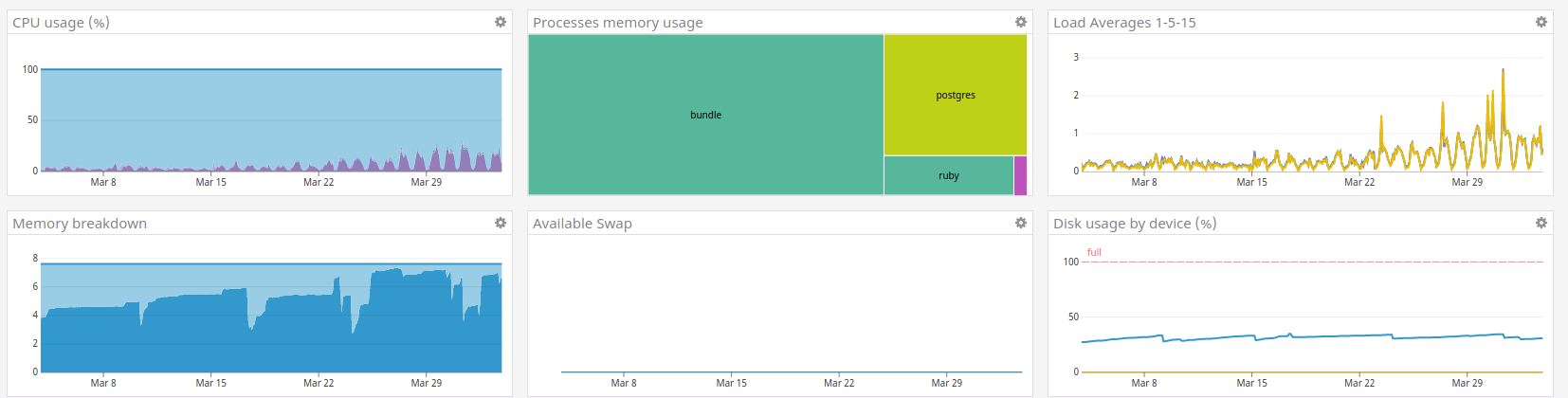
Steps done for UK:
- Shutdown server manually
- Take a snapshot (35min)
- Resize droplet (5min)
- Power droplet back on
- Ensure services are started
For FR, OVH has no offer with 16giga RAM. This leaves FR with two choices :
A. Migrate to another provider
B. Split DB & App
(C. Setup swap)
I don't know much about B, but I'm a bit afraid that this isn't the right timing to introduce a change that ig. On the other hand, each time we had to completely change a server so far it did not went _that_ well (loss of images, ...). So I'm all ears on what should be the best strategy here.
 RachL
RachL
All 18 comments
I would feel more confident moving to another provider than introducing a change like splitting the DB now. We don't even know how that shifts the performance. Yes, we spread the load, but queries need to travel between two servers which is a lot slower. That needs testing before we do that for one of the biggest instances.
 mkllnk
on 7 Apr 2020
mkllnk
on 7 Apr 2020
Since the patch yesterday I'm not sure France actually needs more RAM. And CPU doesn't seem to be an issue. We can keep an eye on it, but I don't think we'll have more downtimes due to lack of memory.
I'm not even sure UK needs 16GB RAM now... :see_no_evil:
So for French Prod I'm proposing option D: wait 48 hours and see what the metrics look like in Datadog.
 Matt-Yorkley
on 7 Apr 2020
Matt-Yorkley
on 7 Apr 2020
So for French Prod I'm proposing option D: wait 48 hours and see what the metrics look like in Datadog.
Agree, we need to see the numbers. I think we can take that time to discuss what we would do next though.
 sauloperez
on 7 Apr 2020
sauloperez
on 7 Apr 2020
The last 48 hours look great. Maybe we can wait and see how it looks over the weekend.
Matt-Yorkley
on 8 Apr 2020
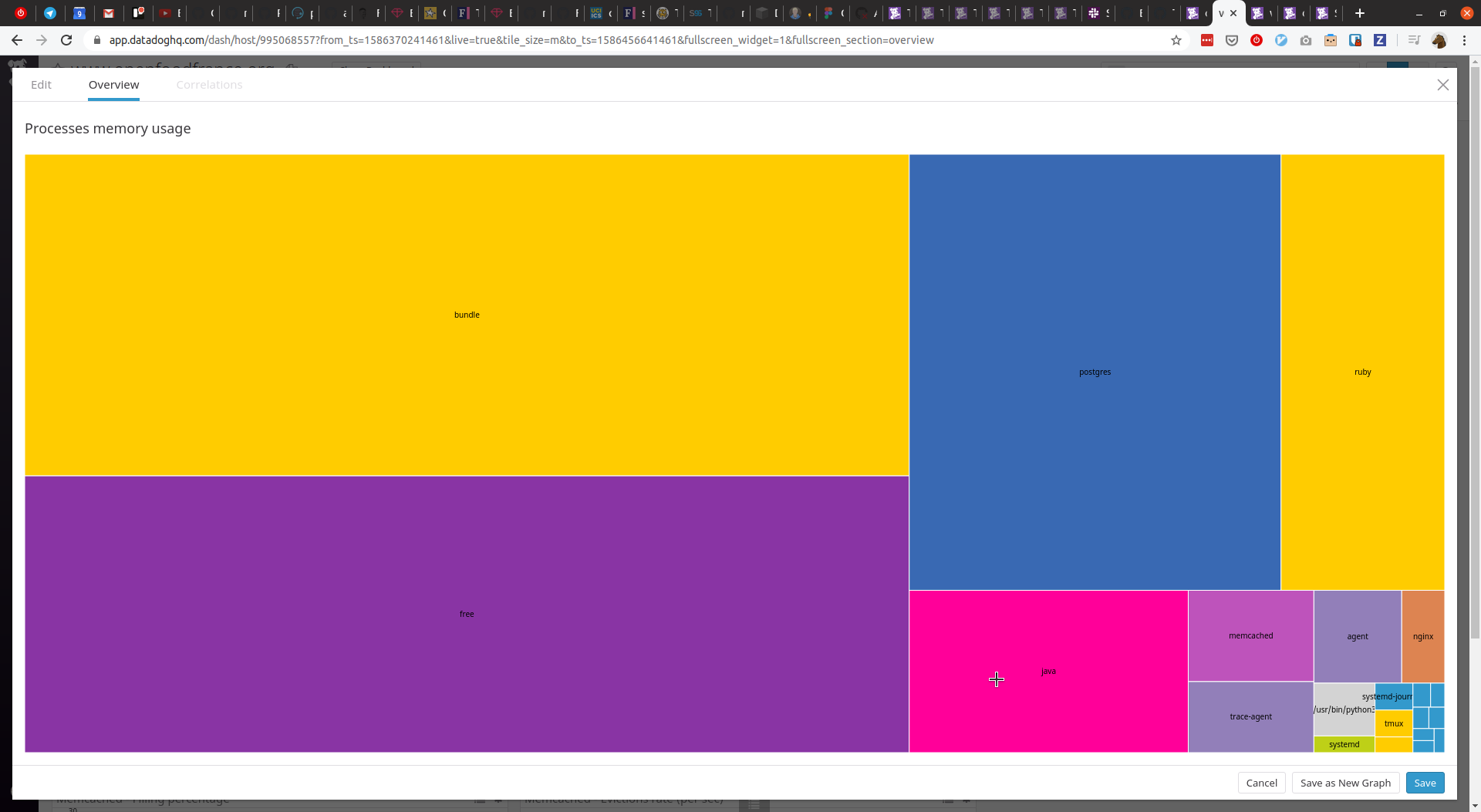
While checking numbers I found a java process in FR's server. That's very odd. Only FR has it. Does it ring a bell @pacodelaluna ? It's using a considerable amount of memory. This :point_down: is yesterday's data but it's always been there.
sauloperez
on 9 Apr 2020
What concerns me now is the spikes on CPU IO wait. Not specifically for FR but for the entire triumvirate (FR, UK, and AU). I'm not an expert myself but I think it's a direct consequence of the disk being busy and being a bottleneck. The correlation is pretty obvious in those crazy long COMMIT latencies: https://app.datadoghq.com/apm/trace/5046029988331528413?colorBy=service&env=production&graphType=flamegraph&shouldShowLegend=true&sort=time&spanID=1909655014533329108 and https://app.datadoghq.com/apm/trace/5046029988331528413?colorBy=service&env=production&graphType=flamegraph&shouldShowLegend=true&sort=time&spanID=1909655014533329108.
I thought this was related to high swap usage but FR is a counterexample. It has no swap but it has quite high IOwait https://app.datadoghq.com/dash/integration/2/system---disk-io?from_ts=1586285837966&live=true&tile_size=m&to_ts=1586458637966&tpl_var_scope=host-id%3Afr-prod. This can't be good. On the other hand, UK has some but never reaches 1.5% and has no swap either.
sauloperez
on 9 Apr 2020
Something else I have spotted and I can't find an explanation for is seeing INSERT INTO sessions statements in totally unexpected endpoints. All the traces I've seen have absolutely crazy latencies for that SQL statement.
Take https://app.datadoghq.com/apm/trace/4587572253662320910?spanID=797142534883353436&env=production&sort=time&colorBy=service&graphType=flamegraph&shouldShowLegend=true as example. There's an 8% IOwait and 225ms of disk latency. And it was just a heartbeat request at 3:58 AM from Wormly :see_no_evil: . We do have a problem with the disk.
sauloperez
on 9 Apr 2020
@sauloperez No idea about this Java proc... 14317 cp-kafk+ 20 0 3967844 424976 0 S 0.3 5.3 1514:25 java, is Kafka running on the FR prod instance? Could be related actually.
 pacodelaluna
on 9 Apr 2020
pacodelaluna
on 9 Apr 2020
I found a java process in FR's server
That's a Kafka-Connect worker for the replication trial. It's got built-in memory limits and doesn't use much CPU.
seeing
INSERT INTO sessionsstatements in totally unexpected endpoints
This is just creating a new user session, right? It looks like a lot of the time it's taking a few milliseconds. In some cases it takes a lot longer, but I think it might just be where it's running at the same time as loading a badly-performing page..?
I did notice that user sessions were being _fetched_ in some places where it seems like they weren't needed at all, like on some asset requests... maybe we could look at skipping loading the session in those cases where it's not needed?
Matt-Yorkley
on 10 Apr 2020
Three weeks before the patch, and the week since the patch:
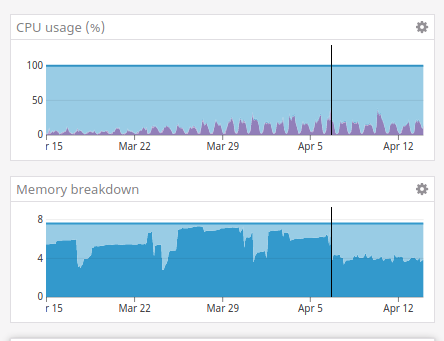
I think we can close this issue for now?
Matt-Yorkley
on 14 Apr 2020
@mkllnk I think it's time to apply this change to AU as well. It's straightforward and we can do it while you guys sleep.
sauloperez
on 14 Apr 2020
Great job guys!
pacodelaluna
on 14 Apr 2020
@sauloperez Which change do you mean?
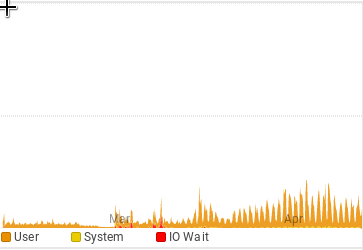
The Australian server has been quite healthy in the last weeks. There's plenty of free memory, no swap usage in normal operation and response times have dropped. The only thing that worries me is the increase in CPU. But as long as we have enough workers and quick responses, that shouldn't be a problem.
mkllnk
on 15 Apr 2020
I meant the unicorn-worker-killer so then we can remove the swap. It's RAM what concerns me.
sauloperez
on 15 Apr 2020
I think it's already on Aus production, just with more conservative settings.
Matt-Yorkley
on 15 Apr 2020
P.S. Aus production was dipping into swap last week even with 12G of RAM and only 3 workers...
Matt-Yorkley
on 15 Apr 2020
then I would go with the general settings that we know are good. UK is proof of that.
sauloperez
on 15 Apr 2020
Aus production was dipping into swap last week even with 12G of RAM and only 3 workers...
I can only see very few swap reads while there is plenty of free memory since last Wednesday, after the deploy. During the deploy was the last swap write. So I guess that it's leftovers from before. Swap usage should disappear over time.
then I would go with the general settings that we know are good. UK is proof of that.
Where is the proof that UK is doing better than AU? Both are doing much better than before but they are difficult to compare because the usage patterns are different. UK is struggling more after all. I think that we are missing data to make that call.
mkllnk
on 16 Apr 2020
Related issues
 filipefurtad0
·
3Comments
filipefurtad0
·
3Comments
filipefurtad0
·
3Comments
RachL
·
3Comments
Matt-Yorkley
·
3Comments
filipefurtad0
·
3Comments
filipefurtad0
·
3Comments
filipefurtad0
·
3Comments
RachL
·
3Comments
Matt-Yorkley
·
3Comments
Most helpful comment
Three weeks before the patch, and the week since the patch:
I think we can close this issue for now?