Openfoodnetwork: /shops taking 30+ seconds to load (UK)
https://openfoodnetwork.org.uk/shops
consistently taking 30 secs to load
Description
This is a bug.
Expected Behavior
Page loads in "acceptable" time. I'd say we can close this if it's loads in under 10 seconds.
Edit: At #gathering19 we agreed 3-5 second load time is acceptable
Actual Behavior
Page takes 30 secs to load.
Steps to Reproduce
Go to
https://openfoodnetwork.org.uk/shops
and wait
Context
@lin-d-hop says: "Fortunately most users direct straight to their shopfront so we dont get complaints about the slow page load"
Severity
bug-s3
Your Environment
- Version used: uk live Nov 20th
- Browser name and version: chrome latest
- Operating System and version (desktop or mobile): osx mojave
Possible Fix
...
 luisramos0
luisramos0
All 45 comments
Just tested on French production, it takes 20 sec to load from homepage to "shop" page.
 myriamboure
on 21 Nov 2018
myriamboure
on 21 Nov 2018
It's weird but I haven't found any trace of ShopsController#index in Skylight for neither UK nor FR. Could be that Skylight drops these requests due to them hitting a hard limit.
By checking on my machine this is what I see, and how I knew it GET /shops maps to that controller.
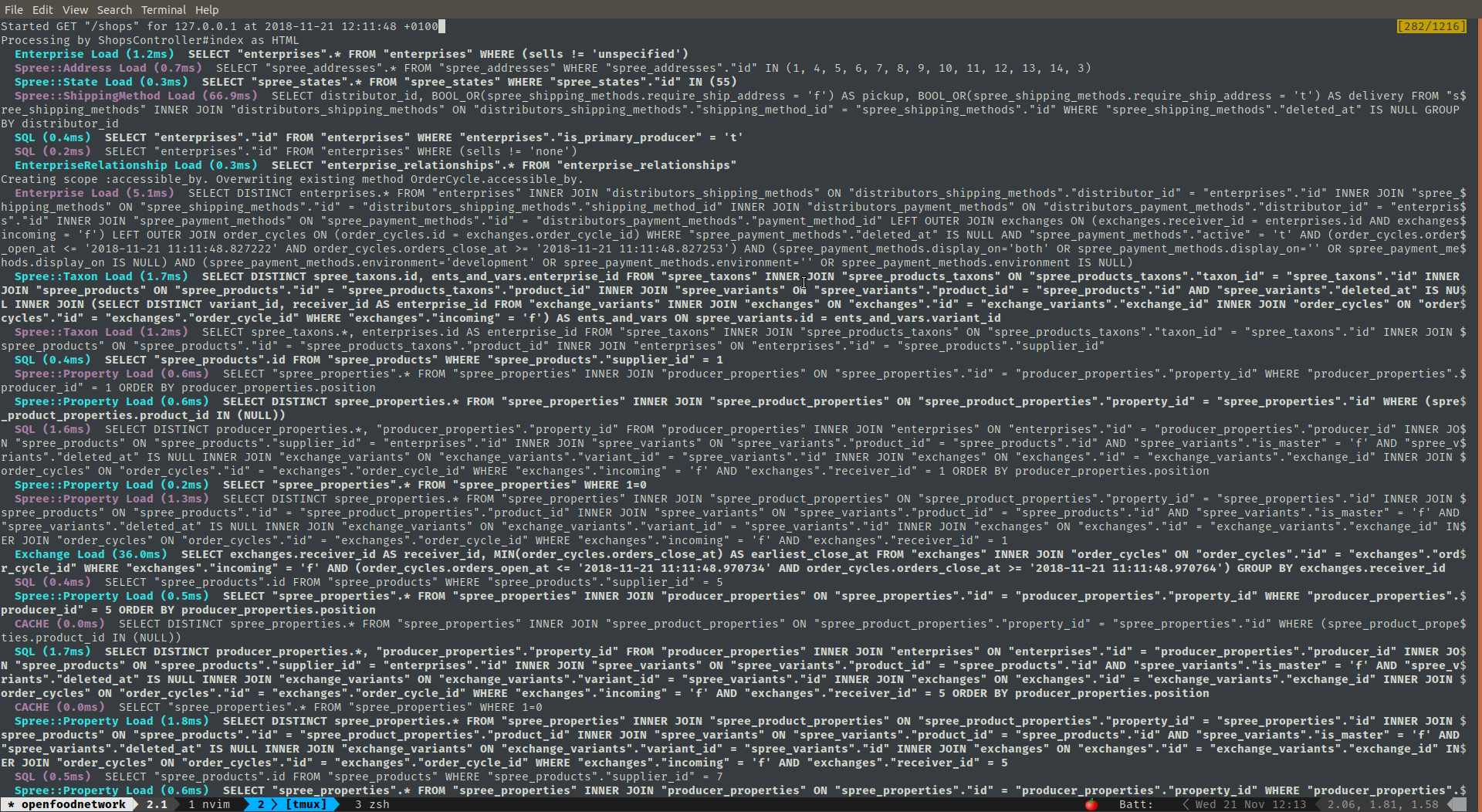
It's pretty obvious the performance hit is related to an N+1 on producer_properties and spree_properties database tables. See below
Completed 200 OK in 996.5ms (Views: 790.2ms | ActiveRecord: 204.7ms)
 sauloperez
on 21 Nov 2018
sauloperez
on 21 Nov 2018
Could be that Skylight drops these requests due to them hitting a hard limit.
This message in log/skylight.log must be it
[SKYLIGHT] [1.6.1] failed to instrument span; msg=native Trace#start_span failed; endpoint=ShopsController#index
We might need to solve https://github.com/openfoodfoundation/openfoodnetwork/issues/3101 as well first.
sauloperez
on 21 Nov 2018
Just tested on French production, it takes 20 sec to load from homepage to "shop" page.
Could we agree on using Matomo for these stats :) ? Rather than our own individual network. Matomo shows an average generation time of 13 to 15 seconds for France, up to 27s for UK. And like Lynne said, the main behaviour is not to reach this page.
 RachL
on 21 Nov 2018
RachL
on 21 Nov 2018
yes @RachL matomo is more precise but not too far from our own experience. uk is showing 26.79s.
my opinion: this is totally unacceptable and we should fix this asap in all instances.
there are many dimensions to this, UX for new users being the top one I believe, another one is SEO. search engines will seriously reduce our ranking because of this.
luisramos0
on 21 Nov 2018
@luisramos0 I was about to say that I wasn't sure about the "asap" part as stats shows that the page is not used that often.... until I've reach Australian stats where the page is more used and needs 32 to 37s to load. 😱
RachL
on 21 Nov 2018
yes. incredible, a few facts:
- a pretty consistent number is that in all instances in all months with numbers this page represents 5% of the total page views (UK with less views because less page views in matomo, but still ~5%)
- in October /shops was taking FR ~12s, UK ~28s and AUS ~26s
- in November /shops was taking FR ~14s, UK ~26s and AUS ~36s
- but in AUS in September (only instance with data), for the 694 pageviews the load time is 5.5s!
Also, these numbers are always very similar for /producers and /maps
Also, one typical fix for this problem is "metal": https://www.digitalocean.com/pricing/
The difference in numbers between FR and UK/AUS must be explained by amount of data in the DB but also server specs.
luisramos0
on 21 Nov 2018
I totally understand your point but I'm not sure metal will change things too much. Saving useless work might have a bigger impact in this case. Also, if we take the put-more-money-approach I foresee pan para hoy, hambre para mañana. I'm afraid that not changing our dev practices we might hit this problem again soon.
We need to also consider that the app and db server's share the machine, so we can't tune system resources tailored to their needs. We will need to have a machine with the resources of both. I bet, better memory and disk.
The difference in numbers between FR and UK/AUS must be explained by amount of data in the DB but also server specs.
They are listed in https://github.com/openfoodfoundation/ofn-install/wiki/Servers-and-domains. But I agree that it looks like this grows hand in hand with the amount of data.
It's all about iterating and testing the results. I suggest we start with https://github.com/openfoodfoundation/ofn-install/issues/273 and check again.
Shall we raise the severity of this then? those numbers show that the app is not accessible at all.
sauloperez
on 21 Nov 2018
I agree monitoring is important but this is different, this is about solving a bug in production. So, I think we need to fix this before improving monitoring.
I agree we need to look at our dev process and improve performance at code level, always and continuously.
I agree metal will not solve all problems. But metal is a quick way to improve the situation.
I'm not sure metal will change things too much
I am pretty sure that if you increase the specs of the servers by a factor of 3 or 4, we will see page load time move to 5seconds. Another natural step we can take is to separate the DBs from the apps, that will also have a massive positive impact on performance.
luisramos0
on 21 Nov 2018
So, I think there are 3 actions here:
- manage performance vs servers cost (this is an ongoing thing), it looks like we very far from appropriate server capacity for the current software solution (for a normal e-commerce website, page load times above 4/5 seconds have to be looked at with priority, ofn is different but the capacity management needs to be done).
- improve monitoring with openfoodfoundation/ofn-install#273
- improve the performance of the app. we need to look at the /shops code and make it faster (lets keep this issue for this part)
luisramos0
on 21 Nov 2018
Ok, understood. Let's move discussions beyond making /shops faster to community.
sauloperez
on 21 Nov 2018
So is there a quick way to tidy up those two n+1 queries @sauloperez ?
 Matt-Yorkley
on 21 Nov 2018
Matt-Yorkley
on 21 Nov 2018
hi all - I agree that this page is a big problem and incredibly slow and off-putting - I hate it and was complaining about it the other day :) However, I have three concerns about prioritising it right now ..
- We haven't prioritised it and there are so many things
- Most enterprises direct people directly to their page and this is why we don't hear user complaints about this. As we are not focused on the 'directory' aspect of OFN at this time, it may not make sense to prioritise this
- These pages /shop and /producers basically DO NOT WORK on mobile and will likely need a complete redesign. For reasons above they are not included in the scope of mobile quick wins, but @yukoosawa have discussed and would be very keen to tackle it
SO I would hesitate to spend time/effort on fixing performance on the page as it is, as I think we'd be better spending time on redesign and rebuild so that it actually works
 kirstenalarsen
on 22 Nov 2018
kirstenalarsen
on 22 Nov 2018
Sure @kirstenalarsen , this is still an S3 unless we change our minds. So there are at least S2s on top of it. We just provided the context needed for anyone to tackle it.
sauloperez
on 22 Nov 2018
Hey @kirstenalarsen
I'd like to clarify that rebuild and redesign are very different and in this case the perf improvement is most probably not related to redesign. Same data will need to be shown: shops with info about them.
So, we can but we shouldnt connect this to redesign.
I'd be interested to know your thoughts about the capacity management. Are we planning to increase server capacity soon to improve website performance or is it not worth the cost?
I understand the decision but I disagree, I think it's unacceptable to live with a broken system. We should begin from a working system and grow from there always. This means I think we should stop every single feature development until we get to a minimal working system: imo these 30secs should be the top priority in our backlog today.
(edited): this problem represents 5% of frontoffice pageviews, matomo is not showing numbers for backoffice. btw, is this intended?
luisramos0
on 22 Nov 2018
I agree @luisramos0 ! "Make what we have great" was something we agreed was a priority, but it never had a concrete form. This is a good example, and I think it should be high priority.
Matt-Yorkley
on 22 Nov 2018
I'd like to clarify that rebuild and redesign are very different and in this case the perf improvement is most probably not related to redesign. Same data will need to be shown: shops with info about them.
So, we can but we shouldnt connect this to redesign.
I thought exactly the same
sauloperez
on 23 Nov 2018
Here come the results of my investigation
Root cause
The actual problem is that in
We load ALL the enterprises so that the frontend can filter them later. Although it's a bit slow this is not yet a problem in Katuma because there are not too many enterprises yet. This is a classic problem of young apps because of this exact same reason. You don't notice when you are loading the DB too much.
The numbers you shared @luisramos0 totally matched the number of enterprises of each instance. Executing that same query of the injection_helper.rb:
# alpha.katuma.org
irb(main):001:0> Enterprise.activated.includes(address: :state).count
(3.1ms) SELECT COUNT(*) FROM "enterprises" WHERE (sells != 'unspecified')
=> 97
# openfoodnetwork.org.uk
irb(main):001:0> Enterprise.activated.includes(address: :state).count
(3.1ms) SELECT COUNT(*) FROM "enterprises" WHERE (sells != 'unspecified')
=> 1197
# www.openfoodfrance.org
irb(main):001:0> Enterprise.activated.includes(address: :state).count
(2.6ms) SELECT COUNT(*) FROM "enterprises" WHERE (sells != 'unspecified')
=> 626
# openfoodnetwork.org.au
irb(main):001:0> Enterprise.activated.includes(address: :state).count
(5.5ms) SELECT COUNT(*) FROM "enterprises" WHERE (sells != 'unspecified')
=> 2090
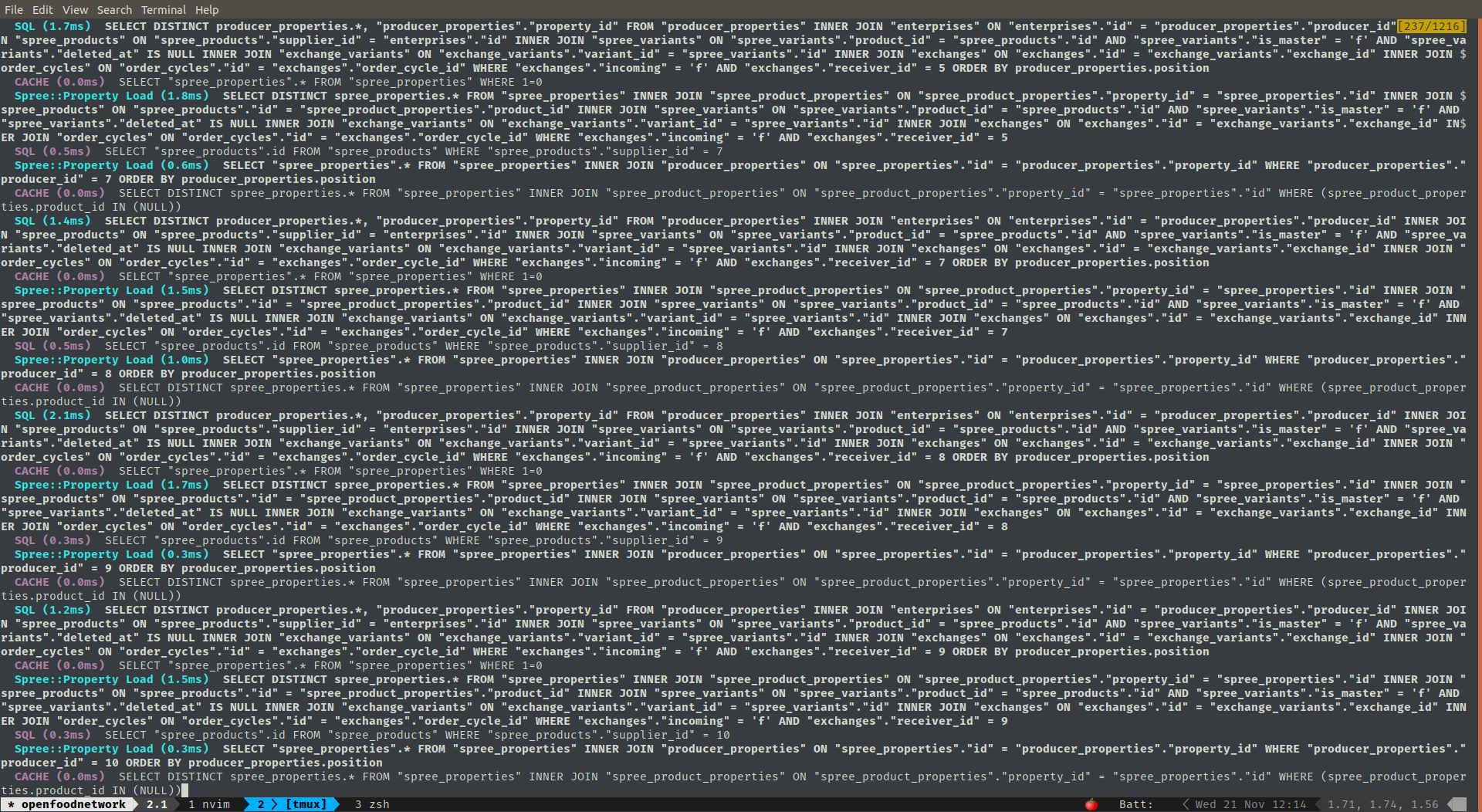
The problem is made worse because for each enterprise we then fetch more data from DB. Even for Katuma we already count the number of SQL queries by hundreds. Above 300 😱
How to mitigate
A way to mitigate this is to remove the many N+1 queries that make this GET /shops request even slower.
I've been working on solving two for which I'll open a PR likely tomorrow, but there's still another one that could be tackled separately.
I hope this can drop the response time by roughly 30%.
Final solution
The way to solve this once and for all is not to ask for all the enterprises in the system. And that means paginating the list. By doing this we no longer depend on the number of enterprises in the DB. By having a slow number of them shown per page we can be back to real-world response times and can be certain that it won't degrade much over time.
This, however, should be addressed in a separate issue where we investigate what's the best solution in terms of UX. My proposal: "Show more"-like pagination and sort enterprises by distance; the closest first (if it's not too difficult). Keep in mind, that will entail refactoring quite a lot the frontend. AFAIK the filtering is done on the client side and it will be moved to the backend.
sauloperez
on 27 Nov 2018
Nice @sauloperez
Re Final Solution, the map will not want a paginated list of enterprises, it will want all of them. Is it the same endpoint for the map and the shop list?
What about keeping frontend as is and building a backend cache for the enterprises? I think a super fast/cached endpoint with a "full list of enterprises" will always be needed. That way we would not have to mix this with a more expensive frontend/UX rework.
An extra option on top of this is that if the payload is too large for each enterprise in the list, we can create a lightweight version of it that solves these cases (map and shops) in the frontoffice.
luisramos0
on 27 Nov 2018
the map will not want a paginated list of enterprises, it will want all of them. Is it the same endpoint for the map and the shop list?
That's a very good question. I checked and they both depend on #inject_enterprises.
What about keeping frontend as is and building a backend cache for the enterprises? I think a super fast/cached endpoint with a "full list of enterprises" will always be needed.
There are various arguments here. Let's go from abstract to concrete.
First, caching is the last resort on performance optimization because it also brings high cost. Cache expiracy is amongst the biggest headaches in programming. I've seen many hard to spot bugs because of it. So, when you have optimized db access, backend view rendering, frontend asset loading and frontend rendering, then you can think of caching.
OFN's doesn't have a successful experience doing that either. The products cache is a source of trouble both due to many errors reported on Bugsnag and a negative impact on some endpoint's performance. Also, it has operational costs. It requires you to watch after it and iterate because it's hard to get right at the first try.
Even if you go that way, you still risk :boom: the DB on a cache miss. You will still execute those awful queries and so you still have the problem.
Also, from the perspective of the frontend this doesn't scale either. I asked @morantron, a frontend dev good friend of us and he claims that solution does not scale. Already with 2000+ objects on the browser it'll start suffering. He says it's better to get the lat/lng of the maps' viewbox and ask that to the backend.
That being said, when applied at the right moment, caching can make things blazing fast :rocket:
Do you mind moving this high-level discussion to discourse? Let's find the best trade-off.
sauloperez
on 28 Nov 2018
With the shops page I think we need to show all the open shops when the page loads, then we can paginate the closed shops (you have to click to see the closed ones anyway). Is that a good compromise?
Matt-Yorkley
on 28 Nov 2018
But again, when the open shops go up to hundreds? You always need to set a limit for all resources so they don't degrade.
Right resd for this topic. See "Limit everything" in https://johnnunemaker.com/database-performance-simplified/
sauloperez
on 28 Nov 2018
On my side, I agree with @sauloperez, we should limit things, it is the only way to scale. On the other side we need something fast because it is really annoying right now, and cache could help for sure. To put the data for 60 or 30 min in memcache should work the time we find a better option.
 pacodelaluna
on 30 Nov 2018
pacodelaluna
on 30 Nov 2018
This issue is certainly not fixed, stats from this week in uk server:

In France /shops is getting worse from 12/13secs to 16.99secs last week.
luisramos0
on 11 Dec 2018
It's not included in v1.23.1 but we could work on a v1.23.2 to get it sooner.
sauloperez
on 11 Dec 2018
ah, ok. not a problem. I just thought we should check times in matomo.
PR #3151 improves time by 30% which is great! but the pages will still take over 20secs to load. I don't think we should close the issue.
luisramos0
on 11 Dec 2018
I don't think we should close the issue.
Not at all. It's been a good first step that helped identify the source of the performance bottleneck.
As I mentioned, that PR was just a way to mitigate the problem. There's another N+1 I can remove which will reduce the response time even further but we should work on designing the pagination meanwhile and creating the necessary issues to implement it.
thoughts?
sauloperez
on 12 Dec 2018
- removing another N+1 👍
- designing /implementing pagination - to @kirstenalarsen point, I'd leave that for a redesign phase
- I think the next step is to increase server capacity or separate the webapp from the database - have we considered this already? it needs to be done at some point right? 1 server for the app, one server for the db. if we are even considering merging instances (single instance), this will have to be done for sure. so maybe we can start now. create a new server and put the DB in there. that will have a big impact on performance for sure.
I moved this server scaling conversation to discourse: https://community.openfoodnetwork.org/t/ofn-physical-architecture/1523
luisramos0
on 12 Dec 2018
Removing an N+1 it's a must but won't solve the underlying problem.
Splitting our single servers into app server + DB server it's something we'll definitely do at some point but... Comparing implementing pagination vs. implementing a DB server, the former undoubtedly wins; it's way quicker and straightforward. Besides, it has to happen sooner or later. Limits must be put on all endpoints.
sauloperez
on 12 Dec 2018
what do you mean with "wins"?
in terms of estimation, implementing a DB server is a lot smaller, right?
pagination is something that will require UX, right?
luisramos0
on 12 Dec 2018
in terms of estimation, implementing a DB server is a lot smaller, right?
there is where I disagree. To me, it is incomparably harder and longer (by few orders of magnitude :trollface: ) than implementing pagination, which requires moving some logic from the frontend to the backend, let's not forget. And with pagination I mean http://ui-patterns.com/patterns/Pagination.
With my far-from-perfect sysadmin skills these are the steps I foresee this would have:
- Buying a new DB server
- we can do it as we do now, one for each instance
- we can move towards the single-instance and buy a single one that hosts multiple DBs for now. This makes it even harder as nothing on ofn-install is thought for it and we'll need a thorough investigation first.
- Creating a bunch of new ansible roles to provision a DB server
- Refactor ofn-install to treat app server and db server separately
- Defining a strategy to migrate all current instances to the new DB + app server set up.
- Refactor ofn-install and the database.yml to allow setting a different DB server
- Provision all instances for the changes to take effect
- Deploy all instances for the app to connect to a different DB
there might be more though.
Also, the sysadmin processes are one of our weakest points where we're still taking our first steps. Just think of how long is taking us to set up Datadog or provision and deploy all instances, as an example.
I believe we're not ready for such big change on the infrastructure. Many things need to happen at organizational/processes level for a change like this to not take several months and end successfully.
However, I do think having a separate DB server it'll be the next infrastructure change on OFN, but just not now.
sauloperez
on 12 Dec 2018
awesome: I copypasted this conversation to https://community.openfoodnetwork.org/t/ofn-physical-architecture/1523 lets talk there.
the scope of this issue can still include n+1 change (smaller) and the pagination work (not so small). they are all independent tasks btw.
luisramos0
on 12 Dec 2018
It's not included in v1.23.1 but we could work on a v1.23.2 to get it sooner.
It looks like #3151 was merged 7 hours before the last release, doesn't that mean it was included in v1.23.1? It's not in the release notes though.
Matt-Yorkley
on 13 Dec 2018
I did pin the release on a paricular commit before that, so unless I committed a mistake it's not in there.
sauloperez
on 13 Dec 2018
Okay, so when we draft the next release, the usual method of finding PRs by date range based on the last release date won't work correctly? I'll try to remember, I'm doing the next one...
Matt-Yorkley
on 13 Dec 2018
Hey @Matt-Yorkley we discussed the release process a bit here and added a part under "Draft a new release..." bullet here that for consistency we should pin the release to the last merge commit and not master
So I think finding the PR range to include still works when creating a draft release, but that result changes of course if more PRs are merged. That was also part of the rationale behind pinning the release.
 sigmundpetersen
on 14 Dec 2018
sigmundpetersen
on 14 Dec 2018
nice catch @Matt-Yorkley . Don't forget to update the wiki once you do.
sauloperez
on 14 Dec 2018
Yes I understand now, you're right of course. 🙈
sigmundpetersen
on 14 Dec 2018
So we need to use the date range from the _date of the last commit included in last release_ then?
sigmundpetersen
on 14 Dec 2018
Righto, so this hasn't had any action for 22 days. @sauloperez should I move it back to the dev ready column, or is there a PR not attached to this issue that has been worked on in the last 3 weeks?

toottoot
 daniellemoorhead
on 8 Jan 2019
daniellemoorhead
on 8 Jan 2019
Ok, so I created #3305 with the shippable stuff I worked on in December but there won't be any improvement yet.
I also wanted to create an epic to implement frontend pagination but I think it needs a bit more investigation, planning and scheduling. Without pagination, the problem won't be solved. What's the right way? a GH project is an epic enough?
sauloperez
on 10 Jan 2019
Moving back to the Dev ready as I'm not working on this one. IMO this deserves to wait for the performance voted candidate to start.
sauloperez
on 19 Feb 2019
Pau did some great work on this but we still have a slow Shops page. I would like to look at the different approaches to see which one leads us to a solution.
Loading fewer enterprises
One identified problem is that we load all enterprises. We could only load open shops for the Shops page. That is 1% of all currently loaded enterprises in Australia.
This is different for the Map page. The map shows only visible enterprises though. That is less than half of the currently loaded enterprises.
Avoiding N+1 queries
The inefficient use of the database seems to be the biggest impact on performance. Querying all enterprises takes less than two seconds. But rendering it all with many additional queries takes 30 seconds.
I don't know how much we can save but I would guess that we could reduce the load time to 30% or 40%. It would help in combination with all other solutions as well.
Caching
This is a last resort approach as it adds complexity and is likely to be buggy. The update of the cache would still be slow but using the cache could reduce the loading time to something like 10%.
Changing the UX and features
We can reduce the data to load by reducing the data to show. Very few people see the unfolded enterprise box and pay attention to the producers of a shop. By removing that part of the UX we can further reduce the loaded data.
Throwing metal at it
More memory doesn't make the processing faster. We need faster CPUs. Scaling up with AWS is pretty expensive. In Australia, we use Rimu Hosting and already use the fastest servers they have.
Separating our database server from our application server could help. But the connection delay may make it worse again.
Conclusion
My perception is that avoiding n+1 queries is the easiest way to have an impact without changing any of the frontend code. Reducing the amount of enterprises loaded is another good one. But it may need some update of the processing logic as well. If there are some particular slow queries, we may decide to cache them in a simple way.
 mkllnk
on 12 Apr 2019
mkllnk
on 12 Apr 2019
Great investigation @mkllnk I also think these are more or less all the categories of solutions that we can explore and combine.
I put this on hold until the gathering to have an in-depth discussion to decide which path we take, as this is one of our next priorities once we get over the upgrade (goal num. 3).
Let's keep thinking about it meanwhile.
sauloperez
on 12 Apr 2019
yeah, great Maikel. there's also the pagination of the enterprises call.
I think this is a great opportunity for API both for
- "Loading fewer enterprises" - api endpoint filter
- "Caching" - caching is a fundamental part of any workable API
- "Pagination" - pagination is a must have in the API
So we could start with building these things in the enterprises endpoint which is a relatively simple API use case :-)
luisramos0
on 12 Apr 2019
Related issues
 shen-sat
·
3Comments
shen-sat
·
3Comments
 sstead
·
4Comments
sstead
·
4Comments
 lin-d-hop
·
3Comments
lin-d-hop
·
3Comments
 kristinalim
·
3Comments
shen-sat
·
3Comments
kristinalim
·
3Comments
shen-sat
·
3Comments