Onpremise: Provide better guidelines on self-hosted limits
Our intention with self-hosted is to provide a turnkey solution for small workloads, and to leave the provisioning of Sentry for larger workloads as an exercise for the reader. We should be clearer in our docs about what exactly constitutes a "small" workload.
Immediate impetus is @kanadaj's comments:
Sentry has way too many separately moving parts to be easy to maintain on your own
onpremise has way too many ways to break on a sufficiently large deployment
if zookeeper breaks, you basically need a PhD in ZK to fix it
and probably a review of the ZK config cause iirc CH has some recommended configs for ZK
I don't use docker-compose or really any of that
I'm transcribing /onpremise to a kubernetes yml
+1
- Am2020 - forum
 chadwhitacre
chadwhitacre
All 15 comments
Another solution would be to provide a kubernetes yaml instead, as docker-compose doesn't really work for productive use on it's own
 max-wittig
on 5 Jan 2021
max-wittig
on 5 Jan 2021
@max-wittig I've discussed it with Chad, if the docker-compose is rewritten to be using volume mounts instead of custom compiling Dockerfiles to embed the config, it'd be trivial to convert it to kubernetes yaml files, probably even by existing CLI tools assuming they can pick up and embed the required files into ConfigMaps/Secrets.
Even if they can't, it's not hard to automate that.
Another option would be an operator, which is way more overhead to work out, but could help with updates between Sentry versions in the future if a more complex upgrade path is required.
 kanadaj
on 5 Jan 2021
kanadaj
on 5 Jan 2021
Filing for later ...
The 2400MB min RAM requirement in the readme for onpremise seems waaaay below what I'd realistically expect to use
https://discord.com/channels/621778831602221064/621783515423440927/795686074851524700
Intel(R) Xeon(R) Silver 4108 CPU @ 1.80GHz with 4 cores
8 GB of ram
https://discord.com/channels/621778831602221064/621783515423440927/795673428287684639
chadwhitacre
on 5 Jan 2021
If it helps any with the numbers, with a freshly wiped ClickHouse, our own Sentry deployment uses 3.74GB RAM atm, highest I've seen was around the 5-6GB mark. Ingesting ~50-100 errors and 5400 transactions an hour right now, though I expect this to go way up once we have integration for other languages.
EDIT: Correction, it's now sitting at the 6GB mark, mostly stable now.
kanadaj
on 6 Jan 2021
@kanadaj Is that RAM for just ClickHouse? Or the whole kit and kaboodle?
chadwhitacre
on 6 Jan 2021
The whole setup @chadwhitacre
kanadaj
on 6 Jan 2021
@kanadaj
if the docker-compose is rewritten to be using volume mounts instead of custom compiling Dockerfiles to embed the config, it'd be trivial to convert it to kubernetes yaml files, probably even by existing CLI tools assuming they can pick up and embed the required files into ConfigMaps/Secrets.
This is already the case, we have stopped doing this long ago: #407.
 BYK
on 6 Jan 2021
BYK
on 6 Jan 2021
@kanadaj Is that RAM for just ClickHouse? Or the whole kit and kaboodle?
If that helps, here're some numbers from production:
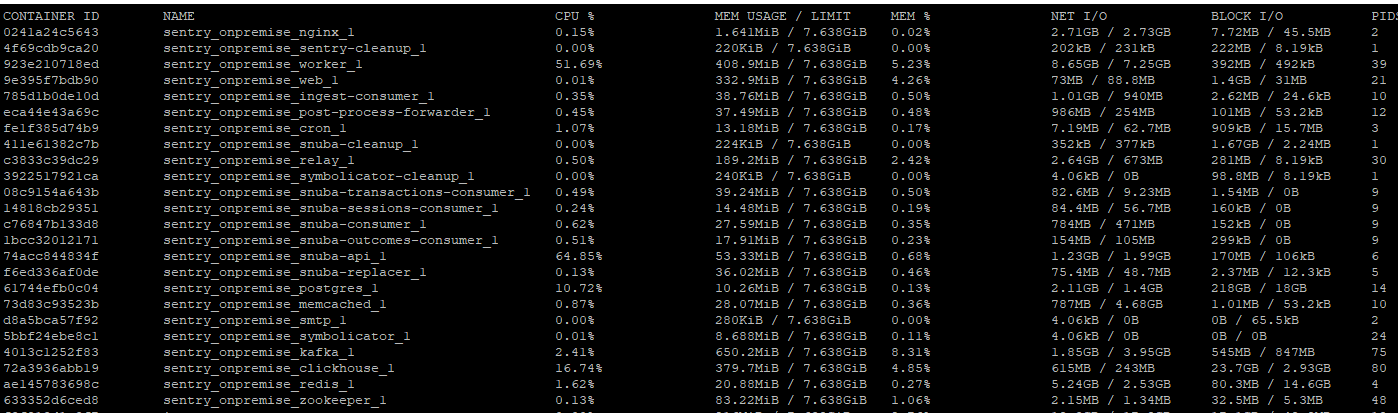
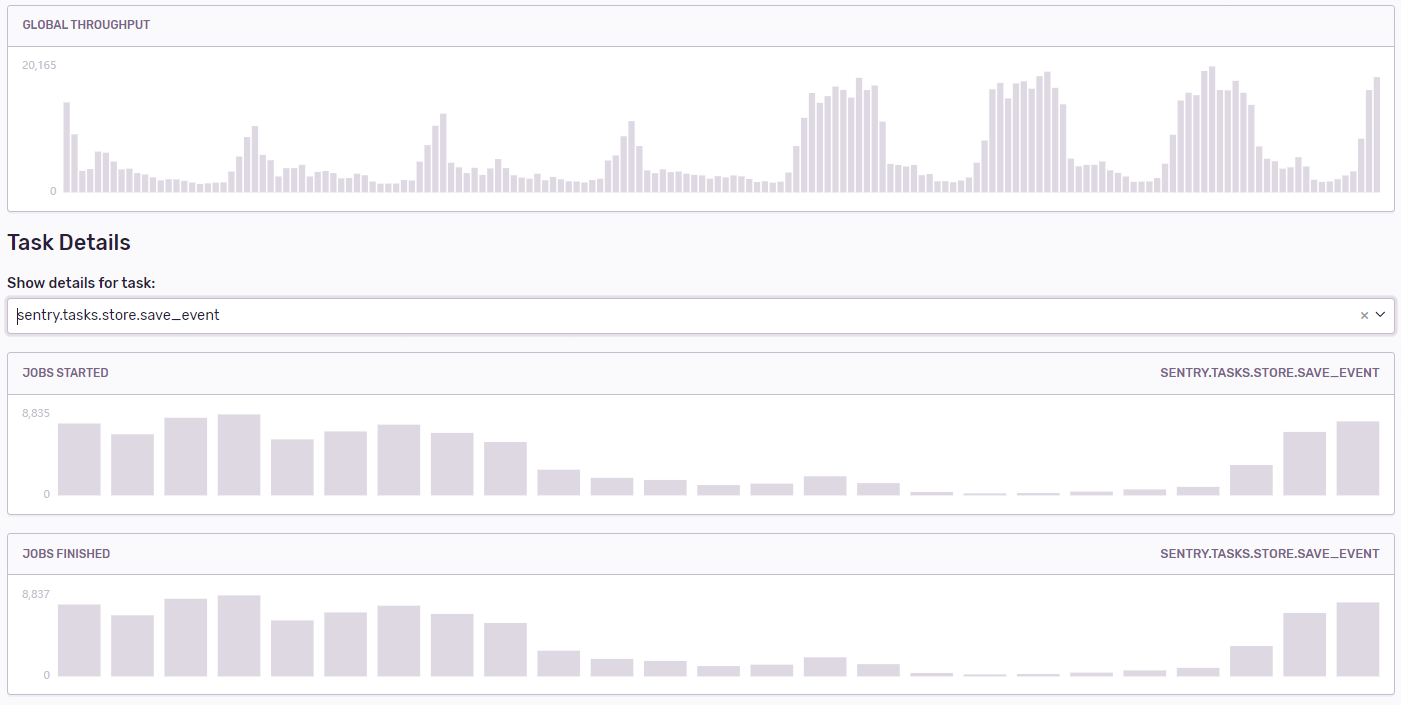
(each bar is 1h)


^ hdd
 lucas-zimerman
on 7 Jan 2021
lucas-zimerman
on 7 Jan 2021
I bumped the RAM requirement on the README to 8 GB, seems safe and easy. Since resource requirements are a function of throughput I'd like to document both sides of the equation, possibly for both real-world and test scenarios. Keeping this open for that.
chadwhitacre
on 7 Jan 2021
Another solution would be to provide a kubernetes yaml instead, as docker-compose doesn't really work for productive use on it's own
For smaller deployments, docker-compose works perfectly. It would be a mistake to assume that everyone has a Kubernetes infrastructure. The small business I work for has GitLab (Omnibus Docker), Sonatype Nexus, and Sentry deployed on a single Linode instance (16GB, 6 cores) using around 9.5GB RAM for all of them, serving a dozen developers and collecting logs/crashes from around 1,000 customer users. It works perfectly, still has room to grow, and we have no reason to need anything more complex for the foreseeable future.
I have no problem with also providing a kubernetes YAML file, except that I suspect it's a bad idea to have two options that will end up diverging from each other.
 kohenkatz
on 11 Jan 2021
kohenkatz
on 11 Jan 2021
The small business I work for has GitLab (Omnibus Docker), Sonatype Nexus, and Sentry deployed on a single Linode instance (16GB, 6 cores) using around 9.5GB RAM for all of them, serving a dozen developers and collecting logs/crashes from around 1,000 customer users. It works perfectly, still has room to grow, and we have no reason to need anything more complex for the foreseeable future.
Love it. Thanks for the real-world numbers @kohenkatz! 👍 Seems to line up with the 8 GB RAM minimum recommendation we just went with (since you're running additional services on the same box). How many errors and transactions per hour you are processing? That will help us compare apples to apples with @kanadaj @lucas-zimerman and others.
chadwhitacre
on 11 Jan 2021
Hello folks!
First of all, thanks for your amazing work. Sentry is a great tool!
Related to the discussion about having/not having a Kubernetes version of the Sentry stack.
IMHO, the point of having a k8s version is about standardization of infrastructure resources. I mean, if the 'default' way of running your workloads is to run everything within Kubernetes clusters because that is the way your company works, it is expected that you avoid not following this pattern. It's not a requirement to reach a crazy scale to start thinking about Kubernetes deployments, but it's true that Kubernetes will help you on this matter. For me, it's perfectly acceptable to have a small instance of Sentry consuming some idle resources from an already provisioned Kubernetes cluster and scale it as you push more events to Sentry.
[edit] Of course that a Kubernetes version would not replace the docker-compose version and vice-versa. They would focus on different use-cases.
I would love to contribute to the project if it makes sense to have a 'Kubernetes Installer' version.
 diegocn
on 12 Jan 2021
diegocn
on 12 Jan 2021
How many errors and transactions per hour you are processing?
Right now, not very many, only a few dozen. We had previously been processing a lot of errors, but most of them have been fixed in the last 1-2 months, and I don't have data older than that. We have currently turned performance monitoring back off, since a lot of our mobile app users are on very poor network connections so my boss decided to try reducing our bandwidth usage as much as possible. While I don't have the numbers from when we had it enabled, I don't think that RAM usage was significantly higher than it is now.
kohenkatz
on 12 Jan 2021
I think we can now close this after #836, and #844. What do you think @chadwhitacre?
BYK
on 12 Feb 2021
Sounds good, always more we can do but hopefully this dispels 80% of the mystery for people now.
chadwhitacre
on 15 Feb 2021
Related issues
 TheRatG
·
4Comments
TheRatG
·
4Comments
 meriturva
·
6Comments
meriturva
·
6Comments
 wodCZ
·
5Comments
wodCZ
·
5Comments
 kh0r
·
5Comments
kh0r
·
5Comments
 adrielliu
·
3Comments
adrielliu
·
3Comments
Most helpful comment
Hello folks!
First of all, thanks for your amazing work. Sentry is a great tool!
Related to the discussion about having/not having a Kubernetes version of the Sentry stack.
IMHO, the point of having a k8s version is about standardization of infrastructure resources. I mean, if the 'default' way of running your workloads is to run everything within Kubernetes clusters because that is the way your company works, it is expected that you avoid not following this pattern. It's not a requirement to reach a crazy scale to start thinking about Kubernetes deployments, but it's true that Kubernetes will help you on this matter. For me, it's perfectly acceptable to have a small instance of Sentry consuming some idle resources from an already provisioned Kubernetes cluster and scale it as you push more events to Sentry.
[edit] Of course that a Kubernetes version would not replace the docker-compose version and vice-versa. They would focus on different use-cases.
I would love to contribute to the project if it makes sense to have a 'Kubernetes Installer' version.