Onnxruntime: Different output when running on CUDA (compared to CPU and keras)
Describe the bug
When running our model with CUDAExecutionProvider, the output is a lot different, compared to CPUExecutionProvider (which is very similar to output of keras model).
Output on CPU:
In [38]: y_cpu[0][:10]
Out[38]:
array([ 4.0727073e-01, -8.2996595e-01, 7.8839634e-04, -7.4903473e-02,
-2.8189439e-01, 3.4575549e-01, -9.9872723e-02, -1.3427838e+00,
-7.6851761e-01, -5.5652875e-01], dtype=float32)
Output on CUDA:
In [39]: y_cuda[0][:10]
Out[39]:
array([-0.50394744, -0.51779425, -0.37129185, -0.84176487, -0.6755803 ,
-1.3122077 , -0.13547337, -1.1968514 , 0.8614615 , -0.21983027],
dtype=float32)
Output on Keras:
In [40]: y_keras[0][:10]
Out[40]:
array([ 4.0726936e-01, -8.2997078e-01, 7.8449666e-04, -7.4905433e-02,
-2.8189561e-01, 3.4576070e-01, -9.9873461e-02, -1.3427850e+00,
-7.6851660e-01, -5.5653584e-01], dtype=float32)
System information
- Ubuntu 20.04
pip install onnxruntime-gpu- ONNX Runtime version: 1.4.0/1.5.2
- Python version: 3.7.6
- CUDA/cuDNN version: 10.1/10.2
- GPU model and memory: RTX1080ti
To Reproduce
Attaching the keras and onnx models as well as input example.
Files
Expected behavior
Expect the outputs of the model to be very similar when running with CPU and CUDA execution providers.
 bazukas
bazukas
All 6 comments
Thanks. I will take a look.
 hariharans29
on 13 Nov 2020
hariharans29
on 13 Nov 2020
Hi - Thanks for sharing the model. I have a feeling the reason for the diffs in the results of the CUDA EP when compared with the CPU EP is that the CUDA EP is not handling the auto_pad attribute in the pooling layers correctly (still running tests to confirm this)-
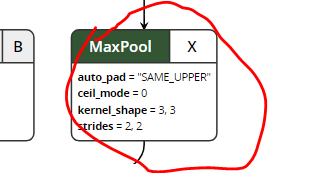
I ll confirm that this is the case and if this is the reason - I ll propose a fix for this.
hariharans29
on 17 Nov 2020
I'm not too sure, but the problem might be with the keras2onnx tool we used to convert to onnx.
When converting to tf format and then using the tf2onnx tool, we don't see the same problem anymore.
bazukas
on 18 Nov 2020
The model as is works correctly with the CPU EP right ? The CUDA EP produces incorrect results with the same model. So I wouldn't think this is a converter issue. This definitely warrants investigation and is most likely an ORT bug.
Each converter is nuanced and probably produces different model "flavors" . tf2onnx probably produces a model that doesn't trigger the bug in the CUDA EP, something which the model produces by keras2onnx does.
hariharans29
on 18 Nov 2020
I found the node causing the diffs - it is from the only BatchNorm node in the model. I ll update this when I send out a PR for the fix.
hariharans29
on 4 Dec 2020
The BatchNorm CUDA kernel has conditional logic to invoke the training cudnn logic just by the mere presence of the optional outputs in the BN node (https://github.com/onnx/onnx/blob/master/docs/Operators.md#BatchNormalization) – https://github.com/microsoft/onnxruntime/blob/14f6eb14b1a0da7fc580f550f660ef248e8a552f/onnxruntime/core/providers/cuda/nn/batch_norm.cc#L112.
Yours seems to be a model that has a BN node with the optional outputs. ? AFAIK this isn’t making the model invalid for inferencing. The diffs are because the the training branch is invoked leaving the output y with garbage (other training outputs are well populated).
The fix probably involves moving away from non-robust branching conditions and differentiating between the kernel class instance when being used in an InferenceSession vs TrainingSession (i.e.) invoke training paths only when the kernel is being used in a TrainingSession.
I ll try and push a fix for this. Thanks for bringing this up!
hariharans29
on 11 Dec 2020
Related issues
 Hramchenko
·
4Comments
Hramchenko
·
4Comments
 daquexian
·
5Comments
daquexian
·
5Comments
 Exlsunshine
·
4Comments
Exlsunshine
·
4Comments
 pengwa
·
3Comments
pengwa
·
3Comments
 klimentij
·
5Comments
klimentij
·
5Comments