Onnxruntime: Onnx works when CUDAExecutionProvider but crash with CPUExecutionProvider
Describe the bug
After successfully compiling a BERT Pytorch model in an onnx one, the inference works with CUDAExecutionProvider and seems to crash for no reason with CPUExecutionProvider.
Urgency
middle, as many users are using Transformers library... and it seems to be a general issue when doing something else classification / representation retrieving
System information
- Google colab
- K80 GPU
- Onnx runtime gpu 1.3.1 (all dependencies are up to date)
- Transformers 2.11
To Reproduce
from transformers import AutoTokenizer, AutoModelForMultipleChoice
from os import environ
import torch
from psutil import cpu_count
from onnxruntime import InferenceSession, SessionOptions, get_all_providers
model_pt = AutoModelForMultipleChoice.from_pretrained("xlm-roberta-base")
model_pt.to(device="cuda")
model_pt.eval()
tokenizer = AutoTokenizer.from_pretrained("xlm-roberta-base")
text = """The rapid growth of submissions and the increasing popularity of preprints have caused several problems to the current ACL reviewing system. To address these problems, the ACL Committee on Reviewing has been working on two proposals for reforming the reviewing system of ACL-related conferences: short-term and long-term. The following document presents the short-term proposals: https://www.aclweb.org/adminwiki/index.php?title=Short-Term_Reform_Propo... It consists of four complementary actions that can be realistically implemented to improve the ACL review process in the near future (while the committee continues to investigate changes that require a longer lead time). These actions address several of the problems identified in the proposal. The ACL Executive Committee has adopted these proposals. We hope that their implementation will have a quick positive impact on reviewing at ACL conferences."""
# Inputs are provided through numpy array
model_inputs = tokenizer.encode_plus(text=text,
text_pair=text,
add_special_tokens=True,
max_length=16,
pad_to_max_length=False,
return_token_type_ids=False,
return_attention_mask=True,
return_overflowing_tokens=False,
return_special_tokens_mask=False,
return_tensors='pt',
)
#
model_inputs = {k: v.unsqueeze(dim=0).to(device="cuda") for k, v in model_inputs.items()}
with torch.no_grad():
score_pytorch, = model_pt(**model_inputs) # type: torch.Tensor
print(f"score output: {score_pytorch.shape}")
print(f"shape input: {model_inputs['input_ids'].shape}")
print(model_inputs)
print(score_pytorch)
# Constants from the performance optimization available in onnxruntime
# It needs to be done before importing onnxruntime
#environ["OMP_NUM_THREADS"] = str(cpu_count(logical=True))
#environ["OMP_WAIT_POLICY"] = 'ACTIVE'
def create_model_for_provider(model_path: str, provider: str) -> InferenceSession:
assert provider in get_all_providers(), f"provider {provider} not found, {get_all_providers()}"
# Few properties than might have an impact on performances (provided by MS)
options = SessionOptions()
options.intra_op_num_threads = 1
# Load the model as a graph and prepare the CPU backend
return InferenceSession(model_path, options, providers=[provider])
!rm -rf onnx/
!mkdir onnx
# https://github.com/microsoft/onnxruntime/blob/master/onnxruntime/python/tools/transformers/notebooks/PyTorch_Bert-Squad_OnnxRuntime_GPU.ipynb
# from transformers.convert_graph_to_onnx import convert
# convert(framework="pt", model="./output/xlm-r", output="onnx/bert-base-cased.onnx", opset=11)
symbolic_names = {0: 'batch_size', 1: 'answers', 2: 'sequence'}
inputs = {
'input_ids': model_inputs["input_ids"],
'attention_mask': model_inputs["attention_mask"],
}
with torch.no_grad():
torch.onnx.export(model_pt, # model being run
args=tuple(inputs.values()), # model input (or a tuple for multiple inputs)
f="onnx/bert-base-cased.onnx", # where to save the model (can be a file or file-like object)
opset_version=11, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
input_names=['input_ids', # the model's input names
'attention_mask'],
output_names=['score'], # the model's output names
dynamic_axes={'input_ids': symbolic_names, # variable length axes
'attention_mask' : symbolic_names,
'score' : symbolic_names,
},
enable_onnx_checker=False,
verbose=False,
use_external_data_format=False,
)
inputs_onnx = {k: v.detach().cpu().numpy() for k, v in model_inputs.items()}
print(inputs_onnx['input_ids'].dtype)
print(inputs_onnx)
cpu_model = create_model_for_provider("onnx/bert-base-cased.onnx", "CUDAExecutionProvider")
for input_meta in cpu_model.get_inputs():
print(input_meta)
for output_meta in cpu_model.get_outputs():
print(output_meta)
# Run the model (None = get all the outputs)
score_onnx = cpu_model.run(None, inputs_onnx)
del cpu_model
# Print information about outputs
print(f"input size {model_inputs['input_ids'].shape}")
print(f"score output: {score_onnx}")
If you run that code it works.
If you replace cpu_model initialization line by
cpu_model = create_model_for_provider("onnx/bert-base-cased.onnx", "CPUExecutionProvider") it will crash with:
score output: torch.Size([1, 1])
shape input: torch.Size([1, 1, 16])
{'input_ids': tensor([[[ 0, 581, 25545, 75678, 111, 1614, 54916, 2, 2, 581,
25545, 75678, 111, 1614, 54916, 2]]], device='cuda:0'), 'attention_mask': tensor([[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]], device='cuda:0')}
tensor([[-0.0059]], device='cuda:0')
int64
{'input_ids': array([[[ 0, 581, 25545, 75678, 111, 1614, 54916, 2, 2,
581, 25545, 75678, 111, 1614, 54916, 2]]]), 'attention_mask': array([[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]])}
NodeArg(name='input_ids', type='tensor(int64)', shape=['batch_size', 'answers', 'sequence'])
NodeArg(name='attention_mask', type='tensor(int64)', shape=['batch_size', 'answers', 'sequence'])
NodeArg(name='score', type='tensor(float)', shape=['batch_size', 'answers'])
---------------------------------------------------------------------------
InvalidArgument Traceback (most recent call last)
<ipython-input-5-c31c618c982c> in <module>()
100 print(output_meta)
101 # Run the model (None = get all the outputs)
--> 102 score_onnx = cpu_model.run(None, inputs_onnx)
103 del cpu_model
104 # Print information about outputs
/usr/local/lib/python3.6/dist-packages/onnxruntime/capi/session.py in run(self, output_names, input_feed, run_options)
109 output_names = [output.name for output in self._outputs_meta]
110 try:
--> 111 return self._sess.run(output_names, input_feed, run_options)
112 except C.EPFail as err:
113 if self._enable_fallback:
InvalidArgument: [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Non-zero status code returned while running Gather node. Name:'Gather_52' Status Message: indices element out of data bounds, idx=1 must be within the inclusive range [-1,0]
Expected behavior
it works with CPU provider like it works with CUDA provider.
Screenshots
N/A
Additional context
N/A
 pommedeterresautee
pommedeterresautee
All 11 comments
Any chance you could share the .onnx model file with the inputs in .pb format ?
 hariharans29
on 22 Jun 2020
hariharans29
on 22 Jun 2020
The non optimized model is that one:
https://itlab-public-data.s3-eu-west-1.amazonaws.com/onnx/bert-base-cased.zip
(same as https://github.com/microsoft/onnxruntime/issues/4293)
Input (16 tokens):
{'input_ids': tensor([[ 0, 581, 25545, 75678, 111, 1614, 54916, 136, 70,
118055, 5700, 2481, 111, 479, 35662, 2]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
This model doesn't use token_type_ids.
pommedeterresautee
on 22 Jun 2020
This is not a bug in the runtime as it seems like the model has had a weird conversion issue pertaining to one of the initializers.
Attention masks can take 2 values - 0 or 1. It seems like the initializer has only data corresponding to mask == 0 and somehow missing stuff pertaining to mask == 1 (which is the provided input).
How did I get to this conclusion ? Please see below -
The Gather node that the exception is being thrown at (marked in red) has a data initializer of shape [1, 768]. Here is the Gather spec: https://github.com/onnx/onnx/blob/master/docs/Operators.md#Gather. The provided masks which flow in as indices of Gather now hold values of 1, which by definition of the spec are outside the range of dim value (axis defaulting to 0).
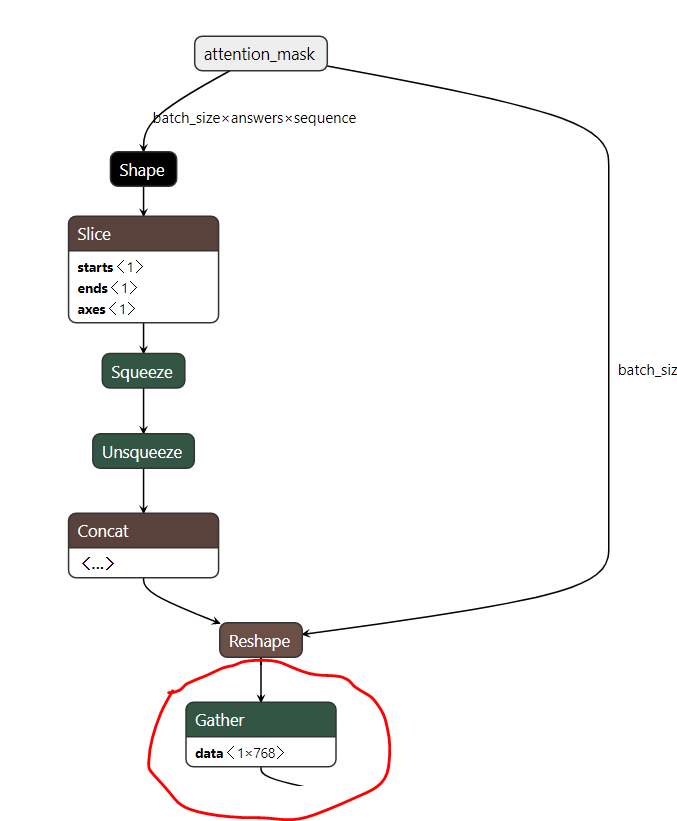
This initializer needs to have been of shape [2, 768] and it is missing a set of 768 values corresponding to mask == 1.
To further add justification, I took another BERT based onnx model to see if I could confirm this suspicion and sure enough that model had masks fed into a Gather node that had an initializer of shape [2, 768] -
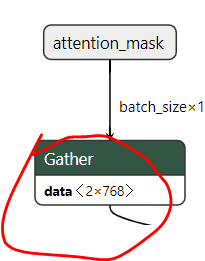
Please open an issue with the Torch ONNX exporter project with these details.
P.S. - As for the model only failing in the CPU EP, the CUDA EP by design doesn't throw when it notices an index out of bound, it treats it as a no-op (i.e.) the output value is 0. This is because the operation is performed on multiple CUDA threads, whereas CPU has validation logic which throws. This design is common across other frameworks - pasting tf link - https://www.tensorflow.org/api_docs/python/tf/gather.
Closing as this is a converter issue and not an ORT issue.
CC: @neginraoof @spandantiwari for the PyTorch export issue
hariharans29
on 24 Jun 2020
Thank you a lot for the tip!
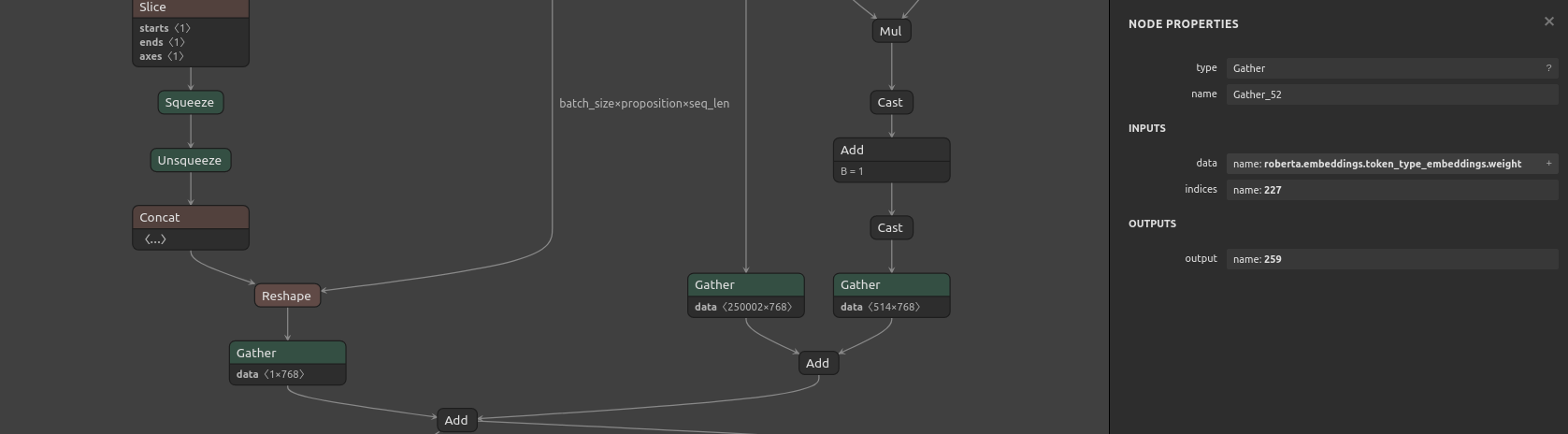
Going deeper, I realize that the Gather operation is linked to roberta.embeddings.token_type_embeddings.weight matrix... but this model (and all Roberta based AFAIK) doesn't use token type input (as you can see in the code above, during input generation we set this parameter: return_token_type_ids=False,).
So basically it's using a matrix which should not be here (it's here because of the Roberta class inheritance from Bert class in Transformers). Clearly, it doesn't make any sense.
pommedeterresautee
on 24 Jun 2020
I tried your repro script, and I'm seeing the error below when running pytorch model:
IndexError: index out of range in self: from torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
Looks like attentions_mask and input_type_ids are swapped in BertModel. Can you confirm this?
 neginraoof
on 24 Jun 2020
neginraoof
on 24 Jun 2020
I get the same error only if I run pytorch on CPU (which I was not doing). I checked on my machine and a fresh one from our cloud.
It seems to match the explanation of @hariharans29 about most ML frameworks don't error on out of range when you are on GPU.
@neginraoof did you modified the code I posted to run torch on CPU?
Regarding the input_type_ids, I will work on it and report here... but it seems crazy to me they did such mistake and no one noticed.
pommedeterresautee
on 24 Jun 2020
I copied your script and just changed CUDA to CPU, and hit this error on PyTorch.
I think the problem happens when passing inputs_ids and attention_masks as a tuple, instead of dict, for ONNX export.
This could be due to lack of support for named optional parameters for model export. I'll look more into this.
neginraoof
on 24 Jun 2020
Yes, this is actually a known missing feature in exporter.
Can you try the workaround below (using a wrapper class) to export the model?
class MyAutoModel(torch.nn.Module):
def __init__(self):
super(MyAutoModel, self).__init__()
self.auto_model = AutoModelForMultipleChoice.from_pretrained("xlm-roberta-base")
def forward(self,
input_ids,
attention_mask=None,
labels=None,
position_ids=None,
head_mask=None,
inputs_embeds=None):
return self.auto_model(input_ids,
token_type_ids=None,
attention_mask=attention_mask,
labels=labels,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds)
model = MyAutoModel()
# try export ...
The custom class didn't fixed it. It seems to be related : https://github.com/huggingface/transformers/issues/4523 (but right the workaround doesn't work may be because here token ids is of no use unlike classical BERT?)
pommedeterresautee
on 24 Jun 2020
Ok it also requires to reverse input as described in the issue linked in the previous message...
from transformers import AutoTokenizer, AutoModelForMultipleChoice
from os import environ
import torch
from psutil import cpu_count
from onnxruntime import InferenceSession, SessionOptions, get_all_providers
class MyAutoModel(torch.nn.Module):
def __init__(self):
super(MyAutoModel, self).__init__()
self.auto_model = AutoModelForMultipleChoice.from_pretrained("xlm-roberta-base")
def forward(self,
input_ids,
token_type_ids=None,
attention_mask=None,
labels=None,
position_ids=None,
head_mask=None,
inputs_embeds=None):
print("0---")
print(input_ids)
print("1---")
print(attention_mask)
print("2---")
print(token_type_ids)
print("3---")
return self.auto_model(input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_mask,
labels=labels,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds)
model_pt = MyAutoModel()
# model_pt.to(device="cuda")
model_pt.eval()
tokenizer = AutoTokenizer.from_pretrained("xlm-roberta-base")
text = """The rapid growth of submissions and the increasing popularity of preprints have caused several problems to the current ACL reviewing system. To address these problems, the ACL Committee on Reviewing has been working on two proposals for reforming the reviewing system of ACL-related conferences: short-term and long-term. The following document presents the short-term proposals: https://www.aclweb.org/adminwiki/index.php?title=Short-Term_Reform_Propo... It consists of four complementary actions that can be realistically implemented to improve the ACL review process in the near future (while the committee continues to investigate changes that require a longer lead time). These actions address several of the problems identified in the proposal. The ACL Executive Committee has adopted these proposals. We hope that their implementation will have a quick positive impact on reviewing at ACL conferences."""
# Inputs are provided through numpy array
model_inputs = tokenizer.encode_plus(text=text,
add_special_tokens=True,
max_length=16, # short to make print easy
pad_to_max_length=False,
return_token_type_ids=True,
return_attention_mask=True,
return_overflowing_tokens=False,
return_special_tokens_mask=False,
return_tensors='pt',
)
#
model_inputs = {k: v.unsqueeze(dim=0) for k, v in model_inputs.items()} # .to(device="cuda")
with torch.no_grad():
score_pytorch, = model_pt(**model_inputs) # type: torch.Tensor
print(score_pytorch)
def create_model_for_provider(model_path: str, provider: str) -> InferenceSession:
assert provider in get_all_providers(), f"provider {provider} not found, {get_all_providers()}"
# Few properties than might have an impact on performances (provided by MS)
options = SessionOptions()
options.intra_op_num_threads = 1
# Load the model as a graph and prepare the CPU backend
return InferenceSession(model_path, options, providers=[provider])
!rm -rf onnx/
!mkdir onnx
symbolic_names = {0: 'batch_size', 1: 'answers', 2: 'sequence'}
# order issue
inputs = {
'input_ids': model_inputs["input_ids"],
'attention_mask': model_inputs["token_type_ids"],
'token_type_ids': model_inputs["attention_mask"],
}
with torch.no_grad():
torch.onnx.export(model_pt, # model being run
args=tuple(inputs.values()), # model input (or a tuple for multiple inputs)
f="onnx/bert-base-cased.onnx", # where to save the model (can be a file or file-like object)
opset_version=11, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
input_names=['input_ids', # the model's input names
'attention_mask',
'token_type_ids',
],
output_names=['score'], # the model's output names
dynamic_axes={'input_ids': symbolic_names, # variable length axes
'attention_mask' : symbolic_names,
'token_type_ids': symbolic_names,
'score' : symbolic_names,
},
enable_onnx_checker=False,
verbose=False,
use_external_data_format=False,
)
inputs_onnx = {k: v.detach().cpu().numpy() for k, v in inputs.items()}
cpu_model = create_model_for_provider("onnx/bert-base-cased.onnx", "CPUExecutionProvider")
# Run the model (None = get all the outputs)
score_onnx = cpu_model.run(None, inputs_onnx)
# Print information about outputs
print(f"score output: {score_onnx}")
It will print:
tensor([[[ 0, 581, 25545, 75678, 111, 1614, 54916, 136,
70, 118055, 5700, 2481, 111, 479, 35662, 2]]])
1---
tensor([[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]])
2---
tensor([[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]])
3---
tensor([[0.1764]])
0---
tensor([[[ 0, 581, 25545, 75678, 111, 1614, 54916, 136,
70, 118055, 5700, 2481, 111, 479, 35662, 2]]])
1---
tensor([[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]])
2---
tensor([[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]])
3---
/usr/local/lib/python3.6/dist-packages/torch/tensor.py:467: RuntimeWarning: Iterating over a tensor might cause the trace to be incorrect. Passing a tensor of different shape won't change the number of iterations executed (and might lead to errors or silently give incorrect results).
'incorrect results).', category=RuntimeWarning)
score output: [array([[0.17644826]], dtype=float32)]
-> 0.1764 in both pytorch and onnx runtime!
Tks a lot for the help!
pommedeterresautee
on 24 Jun 2020
Thanks @neginraoof for the help and thanks @pommedeterresautee for confirming that it works now.
hariharans29
on 25 Jun 2020
Related issues
 diwakar-ravichandran
·
5Comments
diwakar-ravichandran
·
5Comments
 JammyZhou
·
3Comments
JammyZhou
·
3Comments
 pengwa
·
3Comments
pengwa
·
3Comments
 dashesy
·
6Comments
dashesy
·
6Comments
 Exlsunshine
·
4Comments
Exlsunshine
·
4Comments