What?
Let's quantize small weight values to 0.
Why?
Small weights values produces small scales for weights and, therefore, small scales for biases with large quantized value:
https://github.com/Samsung/ONE/blob/2a3e35b1d3c01a850546a6067e1359313e929c5a/compiler/luci/pass/src/QuantizeWithMinMaxPass.cpp#L377-L381
Rounding errors may be significant for values that are too low!
For example, let's take a look at MobileNetV2, which could be obtained using:
$ wget https://storage.googleapis.com/download.tensorflow.org/models/tflite_11_05_08/mobilenet_v2_1.0_224.tgz
$ tar xvzf mobilenet_v2_1.0_224.tgz
Filter №3 of first Conv2d layer of this model has low weights values:
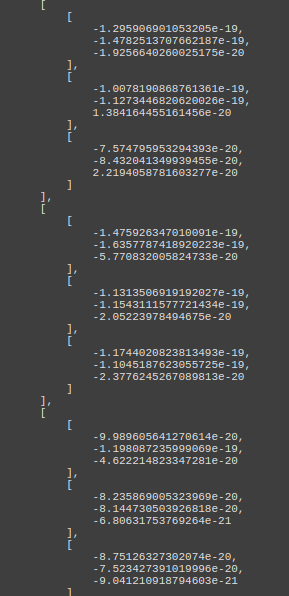
And bias equal to -1.2156529426574707.
After 16bit quantiztion quantized bias value equal to INT64_MIN with low scale: 7.617614820112793e-28, produced by low scales of input and weights. Dequantized value is very different from the original value:
>>> 7.617614820112793e-28 * -9223372036854775808
-7.026009551935886e-09
One possible solution is quantize small values to 0 with scale equal to 1.0 (or may be some another value?).
 Bronnikoff
Bronnikoff
All 6 comments
With changes from #6971 small weights quantizes to 0 with scale 1.0. Bias value for example from https://github.com/Samsung/ONE/issues/6970#issue-916328038 equal to -7967 with scale 0.0001525924017187208.
Dequantized value:
>>> 0.0001525924017187208 * -7967
-1.2157036644930486
+cc @jinevening
 binarman
on 9 Jun 2021
binarman
on 9 Jun 2021
We've faced a similar issue in uint8 quantization.
We decided to use a minimum value for scale to prevent overflow, i.e., scale is set to 1e-5 if it is less than 1e-5.
(1e-5 was determined by some internal experiments.)
See compute_asym_scale_zp
// protect scale from being very low due to overflow
if (scale < 1e-5)
{
scale = 1e-5;
nudged_zero_point = fp32_to_uint8_cast(std::round(qmin_double - rmin / scale));
}
I think we can take a similar approach for int16. But I'm not sure what is the magic number for int16.
@meejeong Can you take a look?
 jinevening
on 10 Jun 2021
jinevening
on 10 Jun 2021
It has similar problems like 8bit.
we changed small weight scale if it was occured to overflow range.
I guess that you change scales of weighttotal(sin x sw) to 1e-15, overflow according to small scale will not appear. (I didn't experiment it yet. I need some time for checking it.)
cc @oj9040
 meejeong
on 10 Jun 2021
meejeong
on 10 Jun 2021
I guess that you change scales of ~weight~total(sin x sw) to
1e-15, overflow according to small scale will not appear.
I made #7017 for this =)
Bronnikoff
on 15 Jun 2021
With #7063 16-bit quantized mobilenetv2 looks repaired:
- Filter №3 has weight scale equal to
9.999999717180685e-10. - Bias of filter has scale equal
1.5259200966590697e-13and quantized value-7966688280576. Dequantized value is valid:
>>> 1.5259200966590697e-13 * -7966688280576
-1.2156529751149208
>>>
- Other filters looks valid.
So, this issue resolved, let's close! =)
Bronnikoff
on 22 Jun 2021
Related issues
 periannath
·
3Comments
periannath
·
3Comments
 seanshpark
·
3Comments
jinevening
·
3Comments
periannath
·
3Comments
seanshpark
·
3Comments
jinevening
·
3Comments
periannath
·
3Comments
 wateret
·
4Comments
wateret
·
4Comments
Most helpful comment
It has similar problems like 8bit.
we changed small weight scale if it was occured to overflow range.
I guess that you change scales of
weighttotal(sin x sw) to1e-15, overflow according to small scale will not appear. (I didn't experiment it yet. I need some time for checking it.)cc @oj9040