One: [Compiler] Propagation of profiling data
What?
Let's propagate profiling data from circle to circle!
How?
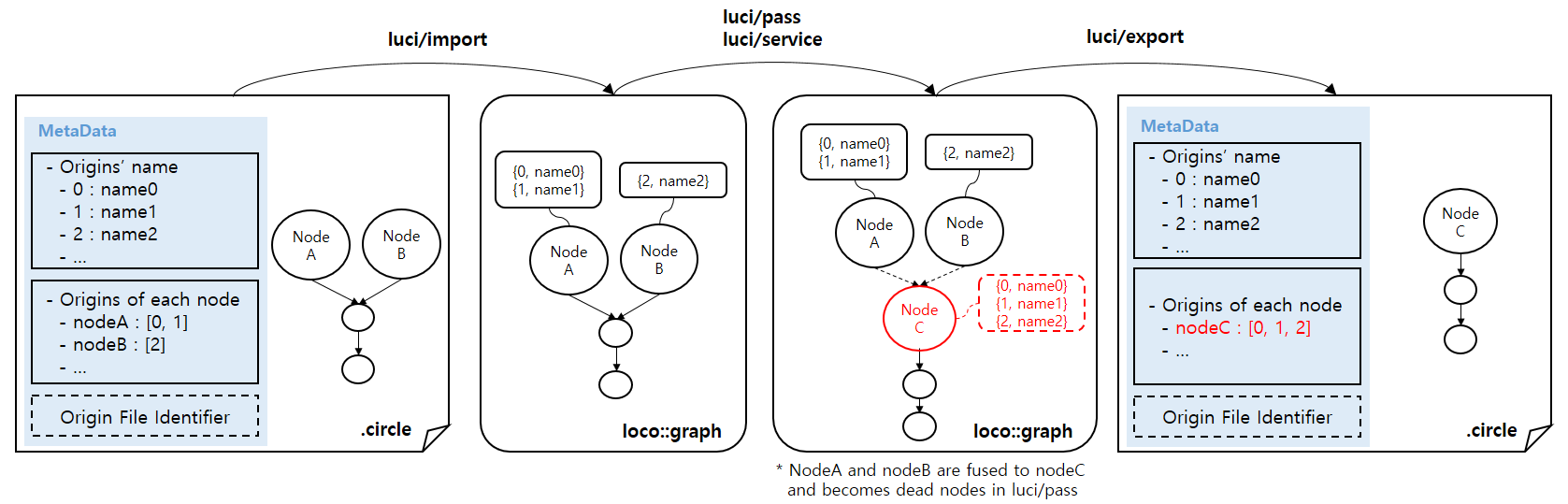
metadata:[Metadata];will be used for storing the origin data in circle file.loco::Annotationwill be used for storing the origin data atCircleNode.
Related Issue/PR
- Draft
- Origin data structure : #6079 (@llFreetimell)
- Infra for import/export : #6101 (@llFreetimell)
- Propagating origin data : #6217 (@mhs4670go)
- Interface to disable/enable profiling in one-cmd : #6186 (@mhs4670go)
- Issue
- No related issue for now
/cc @cgbahk
 llFreetimell
llFreetimell
All 19 comments
Discussion Items
There are some discussion items as following and I made some options for them.
If there are some new ideas, they are always welcome :)
- Do we need to provide intermediate results about profiling data? (High priority)
- Metadata in circle file is enough. Additional results are not needed.
- Let's provide intermediate results about profiling data.
- Someone may not want to include profiling data. Then how can we handle it? (Middle priority)
- Turn on/off at
one-build - Turn on/off at
one-cmds - Always include profiling data
- Turn on/off at
- If we only look at profiling data in circle file, we may confuse which model is the origin of the profiling data. Then what would be proper for identification of origin file? (Middle priority)
md5sumof the origin file.- Inserting some signature to origin file and propagate it.
- file name.
llFreetimell
on 18 Feb 2021
... of origin file?
whay may be the problems embedding profile data inside circle file?
 seanshpark
on 18 Feb 2021
seanshpark
on 18 Feb 2021
But we still need an answer for good UX.
Can you describe more about what UX you mentioned?
seanshpark
on 18 Feb 2021
Diagram looks a bit strange on what is Node C. I guess you tried to say Node C is fused op for Node A and B, but that was not clear?
 cgbahk
on 19 Feb 2021
cgbahk
on 19 Feb 2021
We may also consider the case when input model has no origin file identifier (e.g. tflite). In that case I guess the compiler would set origin file identifier as the input file.
cgbahk
on 19 Feb 2021
@seanshpark
whay may be the problems embedding profile data inside circle file?
No problem and that is the plan :) The question is about another thing.
If user ask us "What is the origin file of the profiling data?", then we wanna say "Look at the circle file. The answer is in there.".
Then what should be in the circle file? This is the question what I intended :)
Can you describe more about what UX you mentioned?
We should give an option such as --no_profiling_data not to include profiling data in circle file.
But how can we provide this function to users and make it's usage convenient?
This was what I wanted to say :)
llFreetimell
on 19 Feb 2021
@cgbahk
Diagram looks a bit strange on what is Node C. I guess you tried to say Node C is fused op for Node A and B, but that was not clear?
I tried to say "NodeC is generated by some luci/Pass from NodeA and NodeB."
I will update this :)
We may also consider the case when input model has no origin file identifier (e.g. tflite). In that case I guess the compiler would set origin file identifier as the input file.
Of course. That's why I marked it as dashed line :D
For now, the most highest priority is including and propagating profiling data.
llFreetimell
on 19 Feb 2021
Then what should be in the circle file? This is the question what I intended :)
Um? I couldn't catch whay this question or the answer to this question you have in mind could be.
seanshpark
on 19 Feb 2021
@llFreetimell
We should give an option such as --no_profiling_data not to include profiling data in circle file.
I think it should be --profiling_data(option name could be changed). I mean, profile data shouldn't be generated as default.
 mhs4670go
on 19 Feb 2021
mhs4670go
on 19 Feb 2021
But how can we provide this function to users and make it's usage convenient?
This was what I wanted to say :)
Providing --no_profiling_data is one can think of :)
We provide a command line tool that works like this: provide an option for the compiler.
I think the UX you want to think of or provide to the user, maybe better to talk with SDK team.
seanshpark
on 19 Feb 2021
If we decide to provide --no_profiling_data or --profiling_data, we can apply this to many modules as following.
- circle2circle
- circle-quantizer
- one-build
- one-import-circle
- one-import-tf
- ....
Then should we apply --no_profiling_data or --profiling_data to all of them? or only some of them?
It was my point but the word UX may not proper :(
llFreetimell
on 19 Feb 2021
Then should we apply --no_profiling_data or --profiling_data to all of them? or only some of them?
I think you are asking the relation of command lines and executables and the modules and how the command line option works... Is it? or is it not?
Your answer may depend on this...
seanshpark
on 19 Feb 2021
It was my point but the word UX may not proper
I think this is the point that sometimes I ask you again or misunderstand.
Generic words like UX you mean and what I understand differ by experience and this experience sometimes may be huge.
I would like to suggest NOT to use generic or broad words like this but explain what actually you want to do: using module name, executable or class or what ever the name that may not confuse.
seanshpark
on 19 Feb 2021
I think you are asking the relation of command lines and executables and the modules and how the command line option works... Is it? or is it not?
Hmm...? My question is only about "should we introduce --profiling_data to all of the modules or only to some of modules?".
I can't understand why so many relations are mentioned...
I would like to suggest NOT to use generic or broad words like this but explain what actually you want to do: using module name, executable or class or what ever the name that may not confuse.
All right, I see it.
llFreetimell
on 19 Feb 2021
First, AFAIK, SDK team only uses one-build.
Second, input of the one-build could be not only circle1(model before quantized) but also circle2(optimized model), circle3(quantized model) - this is our goal of this issue. It will be extended to .tflite, .onnx, .pb later
Then should we apply --no_profiling_data or --profiling_data to all of them? or only some of them?
It can be divided into two things. one-cmds is just a script that runs drivers, i.e., an interface. So, let's say drivers and scripts. Then, I think all driver that proceeds both of import and export steps should have profile option. And, scripts is what we need to discuss about.
Here's what I think it could be.
1. one-build only have profile option
[profile] ## note here
profile_info=True
[one-build]
one-import-tf=True
one-import-tflite=False
one-import-bcq=False
one-optimize=True
one-quantize=False
one-pack=False
one-codegen=False
[one-import-tf]
input_path=inception_v3.pb
output_path=inception_v3.circle
input_arrays=input
input_shapes=1,299,299,3
output_arrays=InceptionV3/Predictions/Reshape_1
converter_version=v2
[one-optimize]
input_path=inception_v3.circle
output_path=inception_v3.opt.circle
2. one-cmds have profile option
[one-build]
one-import-tf=True
one-import-tflite=False
one-import-bcq=False
one-optimize=True
one-quantize=False
one-pack=False
one-codegen=False
[one-import-tf]
input_path=inception_v3.pb
output_path=inception_v3.circle
input_arrays=input
input_shapes=1,299,299,3
output_arrays=InceptionV3/Predictions/Reshape_1
converter_version=v2
profile_info=True // note here
[one-optimize]
input_path=inception_v3.circle
output_path=inception_v3.opt.circle
profile_info=True // note here
Actually, two option have same internal implementation. The only difference is how it looks(how to use, an interface).
So,
What is the intermediate/final results? What should be provided for users? (High priority)
The results users want to know are original node identifier and the relation between original node with instructions. There's no need to show intermediate results.
Someone may not want to include profiling data. Then how can we handle it? (Middle priority)
Introducing option not to include profiling data is one of the solution. But we still need an answer for good UX.
driver's having options seems natural. What I think UX would be is like above. After reaching a consensus, we can talk to SDK team about it.
What would be proper for identification of origin file? (Middle priority)
We need to find an answer for a question, "What is the origin file of this profiling data?"
One of the solution is md5sum
md5sum looks good. This is also what we can talk about with SDK.
mhs4670go
on 19 Feb 2021
@jinevening I've been working on this issue and I will propagate profile information during optimization. Operators set its profile information when they are imported. And when they are fused or changed into a new one, their info should be copied as well. I mean, the nodes that I need to take care about is a newly one. IIUC, I think there's no fusion, fission or change in quantizaion. Please let me know if I am wrong.
mhs4670go
on 2 Mar 2021
IIUC, I think there's no fusion, fission or change in quantizaion. Please let me know if I am wrong.
Unfortunately, new nodes are created when weights/bias are quantized. But fortunately, the new nodes are created only via luci::clone or create_empty_const_from in QuantizeWithMinMax.cpp.
I think it would be enough to change those functions to copy the profile information when creating a new node.
 jinevening
on 2 Mar 2021
jinevening
on 2 Mar 2021
@jinevening Oh, thank you for comments. Actually, the information exists in the operators. So, weights/bias nodes can be skipped as of now.
mhs4670go
on 2 Mar 2021
Related PRs are all merged, done :)
llFreetimell
on 15 Mar 2021
Related issues
 periannath
·
3Comments
periannath
·
3Comments
 kishcs
·
3Comments
kishcs
·
3Comments
 binarman
·
3Comments
binarman
·
3Comments
 hasw7569
·
4Comments
hasw7569
·
4Comments
 underflow101
·
4Comments
underflow101
·
4Comments
Most helpful comment
Related PRs are all merged, done :)