One: [luci] How to describe circle operator's profile info
What!
For profiling purpose, each circle node is expected to have _some_ profile info. This is to discuss how it would be described.
Option 1) Make dedicated profile index for each circle operator
5753
Option 2) Use existing operator index
Circle (and tflite) has list of operators:
https://github.com/Samsung/ONE/blob/abb70047faf755bfbd718fbd75afc982953124ea/nnpackage/schema/circle_schema.fbs#L1084-L1085
For example, it will look like
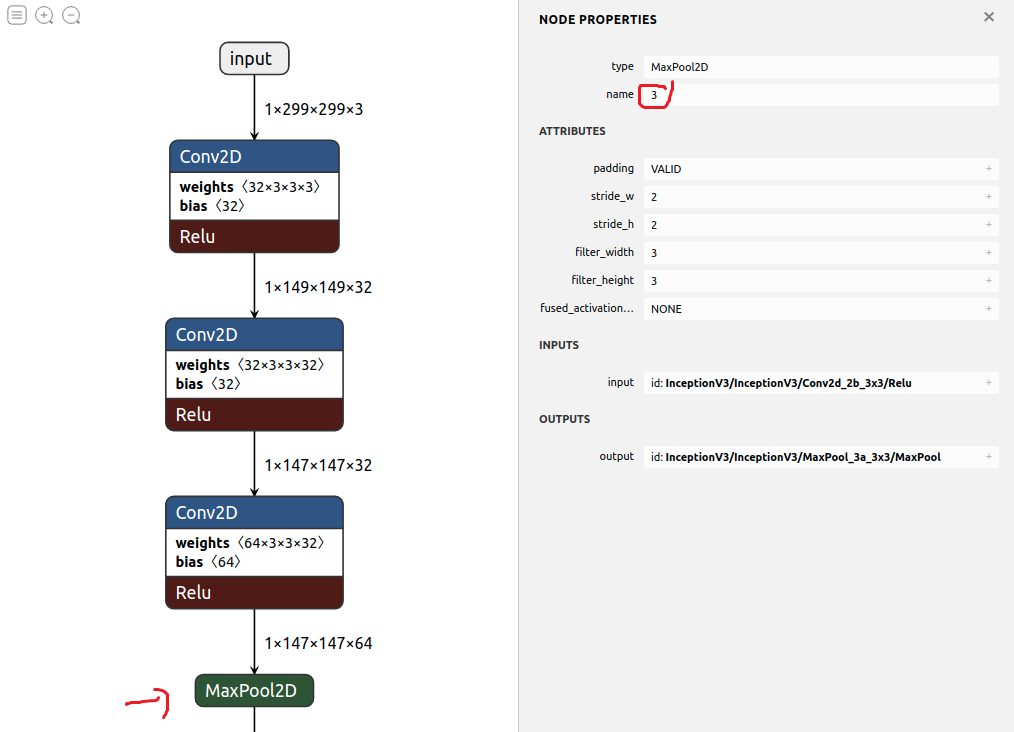
$ tfldump inception_v3.tflite
...
Operators: O(subgraph index : operator index) OpCodeName
Option(values) ... <-- depending on OpCode
I T(tensor index) OperandName <-- as input
O T(tensor index) OperandName <-- as output
O(0:0) CONV_2D
Padding(1) Stride.W(2) Stride.H(2) Dilation.W(1) Dilation.H(1) Activation(RELU)
I T(0:317) input
I T(0:0) InceptionV3/Conv2d_1a_3x3/weights
I T(0:5) InceptionV3/InceptionV3/Conv2d_1a_3x3/Conv2D_bias
O T(0:6) InceptionV3/InceptionV3/Conv2d_1a_3x3/Relu
O(0:1) CONV_2D
Padding(1) Stride.W(1) Stride.H(1) Dilation.W(1) Dilation.H(1) Activation(RELU)
I T(0:6) InceptionV3/InceptionV3/Conv2d_1a_3x3/Relu
I T(0:1) InceptionV3/Conv2d_2a_3x3/weights
I T(0:7) InceptionV3/InceptionV3/Conv2d_2a_3x3/Conv2D_bias
O T(0:8) InceptionV3/InceptionV3/Conv2d_2a_3x3/Relu
O(0:2) CONV_2D
Padding(0) Stride.W(1) Stride.H(1) Dilation.W(1) Dilation.H(1) Activation(RELU)
I T(0:8) InceptionV3/InceptionV3/Conv2d_2a_3x3/Relu
I T(0:2) InceptionV3/Conv2d_2b_3x3/weights
I T(0:9) InceptionV3/InceptionV3/Conv2d_2b_3x3/Conv2D_bias
O T(0:10) InceptionV3/InceptionV3/Conv2d_2b_3x3/Relu
O(0:3) MAX_POOL_2D
Padding(1) Stride.W(2) Stride.H(2) Filter.W(3) Filter.H(3) Activation(NONE)
I T(0:10) InceptionV3/InceptionV3/Conv2d_2b_3x3/Relu
O T(0:15) InceptionV3/InceptionV3/MaxPool_3a_3x3/MaxPool
...
Let luci node IR to have operator index in tflite/circle input file, just like it imports tensor name to IR.
To be specific, when luci import a circle file from disk, luci node IRs would have an API to get operator index from the source file accordingly.
I imagine something like this, but not sure :
NodeIndex luci::CircleNode::index();
Why?
We need operator index _in IR_ to be used in profiling.
cc @lemmaa
 cgbahk
cgbahk
All 26 comments
cc @llFreetimell @mhs4670go
cgbahk
on 22 Jan 2021
5753 may be related with this :)
 llFreetimell
on 22 Jan 2021
llFreetimell
on 22 Jan 2021
@cgbahk , can you describe what are the requirements of this?
 seanshpark
on 24 Jan 2021
seanshpark
on 24 Jan 2021
I come up with two things as of now.
- add index attribute to
operatortable in schema(#5753)
table Operator {
// Index into the operator_codes array. Using an integer here avoids
// complicate map lookups.
opcode_index:uint;
// Optional input are indicated by -1.
inputs:[int];
outputs:[int];
...
// For profiling
p_index:int; // NOTE HERE
}
It is to literally add index attribute for profiling to operator table in schema. circle2circle generates its index by looping all nodes in the model.
bool generate_profiling_info(loco::Graph *g)
{
int32_t idx = 0;
for (auto node : loco::all_nodes(g))
{
if (luci::CircleNode *circle_node = dynamic_cast<luci::CircleNode *>(node))
circle_node->p_index(idx++);
}
return true;
}
This looks good because there is no implicit things but adding attribute to schema somehow bothers us;-)
- use original operator vector order
The operators in the model always are loaded in the same order. So, when we build the operators, we can just give them its vector index and then, they will keep its index when they become IR. This looks very simple because there needs no change in schema. But it is somehow ambiguous as its index doesn't show up explicitly.
 mhs4670go
on 25 Jan 2021
mhs4670go
on 25 Jan 2021
@cgbahk , can you describe what are the requirements of this?
Sorry for lack of information. Let me specify the requirement I imagine more specifically -> Done
cgbahk
on 25 Jan 2021
@mhs4670go , why are you working on this for circle2circle ?
@lemmaa , as I understand, we are NOT working on circle2circle as of now. Did I misunderstood?
I did not hear any requirements for circle2circle and any deadlines.
seanshpark
on 25 Jan 2021
@seanshpark Well, the only requirement I know is below.
Let luci node IR to have operator index in tflite/circle input file, just like it import tensor name to IR.
Everything else is ambiguous. I'm just using circle2circle because it is easy to implement above idea. We should keep discussing.
mhs4670go
on 25 Jan 2021
I'm just using circle2circle because it is easy to implement above idea.
Can you add this to #5753 main comment?
seanshpark
on 25 Jan 2021
- use original operator vector order
Main comment written by me is only considering 2. from @mhs4670go 's idea.
- add index attribute to
operatortable in schema(#5753)
I never imagine like 1. but this idea looks interesting. :thinking:
cgbahk
on 25 Jan 2021
@cgbahk Actually, I think idea 1 is only valid with circle3 because operators vector sequence in schema is changed when circle1 -> circle3 cause of fussion or sth. Anyway we can add index API.
mhs4670go
on 26 Jan 2021
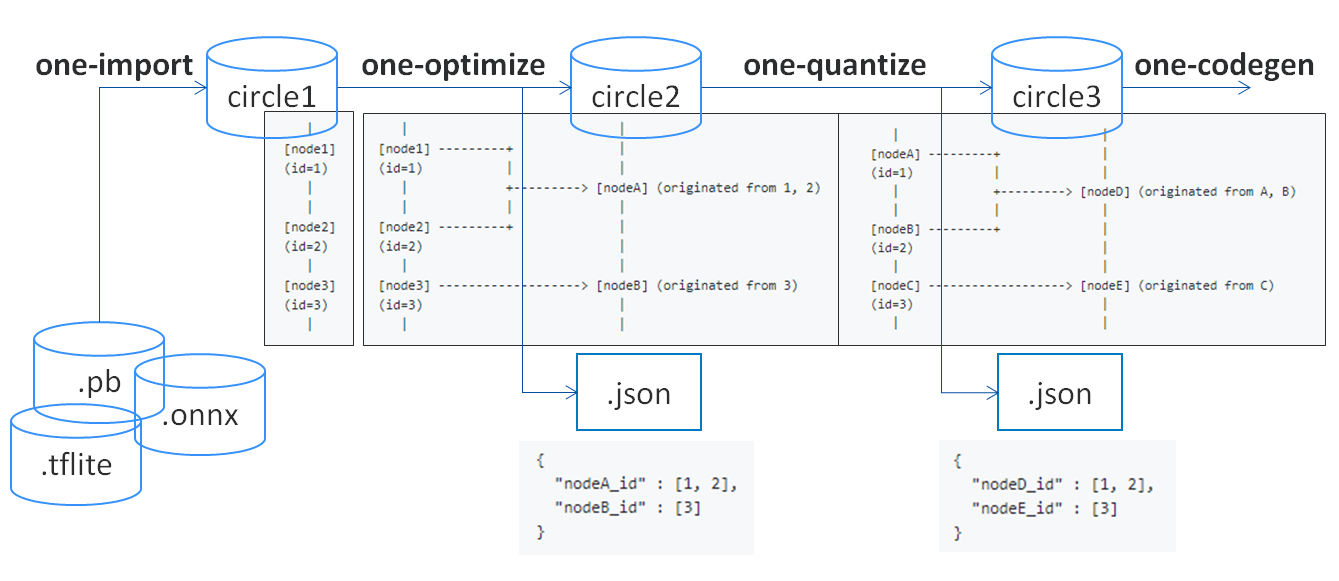
@cgbahk FYI, circle3 is originated from following flow :)
TF/tflite/ONNX -> [one-import-x] -> circle1 -> [one-optimize] -> circle2 -> [one-quantize] -> circle3 -> [one-codegen] -> ~
What?
Following steps show what we want to do.
Step 1. Import circle model
Import circle model and annotate unique id to each node using operator index.
|
[node1]
(id=1)
|
|
[node2]
(id=2)
|
[node3]
(id=3)
|
<circle model>
Step 2. Graph Transform
During graph transforms, record which node was origin.
| |
[node1] ---------+ |
(id=1) | |
| +---------> [nodeA] (originated from 1, 2)
| | |
[node2] ---------+ |
(id=2) |
| |
[node3] -------------------> [nodeB] (originated from 3)
(id=3) |
| |
<circle model> ---- codegen ----> <code>
Step 3. Mapping Information
After graph transformation is finished, create mapping information file.
(Following example is written as json)
{
"nodeA_id" : [1, 2],
"nodeB_id" : [3]
}
How?
Unique node id
There are three candidates for unique node id.
- Operator Index (Draft)
- (pros) Hashing for getting integer id is not needed.
- (pros) Uniqueness is always guaranted.
- (cons) Order of exported nodes and in-memory IR are different. i.e, We can know id of new node only at export step.
- Tensor Name
- Exactly opposite of pros and cons of operator index
- Adding new attribute to circle schema (Draft)
- (pros) Getting and setting id can be done easily.
- (cons) Low flexibility.
For now, operator index is considered primarily.
- Operator Index (Draft)
Recording origin
loco::Annotationis considered for recording origin information to each node.
Please refer to Draft for detailed example code.Propagation of origin
The origin of new node in transformed graph can be inferred only in each transformation pass.
Thus we should implement origin propagation logic at each transformation pass.Saving mapping information
There are two options for saving mapping information
Saving as json file
- Example
json { "nodeA_id" : [1, 2], "nodeB_id" : [3] } - (pros) External json file is not influenced by circle schema.
- (pros) Profiler can use profiling information easily.
- (cons) Additional steps to export external file is needed.
- (cons) Managing many files can be burden.
- Example
Saving in circle model file
circle schema has
Metadatatype andmetadatafield for saving additional data.table Metadata { // A human readable string to uniquely identify a Metadata. name:string; // An index to the buffers table. buffer:uint; } table Model { // ... // Metadata about the model. metadata:[Metadata]; }- (pros) We can include profiling data in circle model file without any schema changes.
- (pros) Additional steps to read/write external file is not needed.
- (cons) Profiler should deal with FlatBuffer compiler. Or we should provide additional tools for extracting as external file.
- (cons) A lot of code changes may be needed.
llFreetimell
on 26 Jan 2021
@cgbahk @mhs4670go I summarized out discussion result and added my own thoughts. If there are something strange, let me know :)
llFreetimell
on 26 Jan 2021
mhs4670go
on 26 Jan 2021
@seanshpark @lemmaa Please review this comment.
In short, there are only two things to decide.
- [] : our choice
1. profiling info medium, i.e., where to store
In schema or [file]
2. identifier
[operator index] or tensor name or brand new attribute
mhs4670go
on 27 Jan 2021
Hard to give opinion for these reasons.
- what is the scope of this task?
- what is the purpose or big picture of this task?
- why do you consider transformations and exports?
seanshpark
on 27 Jan 2021
@seanshpark
First, the final goal is to keep operators' identifier in the original model until passed to the code generator. Because users want to know where it comes from when they see this node in the optimized or modified model rather original one.
With this goal, two things arises. What is identifier? and How to give them this?
profiling info medium, i.e., where to store
identifier
This is why I asked you to review the above things.
what is the scope of this task?
Actually current scope is very ambiguous and "scope" needs granularity level as well. As of now, we are thinking of things ONE needs to do for keeping operators' identifier and related APIs that code generator can easily take identifier.
what is the purpose or big picture of this task?
Above final goal is our purpose.
why do you consider transformations and exports?
To achieve final goal, operators' identifier in the original model must be kept to the end. If we didn't consider transformation, the identifier would be gone when its operator is fused. And if we didn't consider exports, the identifier would be gone when its operator is exported.
mhs4670go
on 27 Jan 2021
May I ask what is the dead line besides what or how to do?
seanshpark
on 27 Jan 2021
May I ask what is the dead line besides what or how to do?
As of now,
- Setting operators' identifier during import + APIs that code generator can easily take identifier + related code generator(not ONE) works : merged until 10th Feb.
- Others : Not determined.
llFreetimell
on 27 Jan 2021
Setting operators' identifier during import + APIs that code generator can easily take identifier + related code generator(not ONE) works : merged until 10th Feb.
OK thanks, so I think this is VERY tight schedule.
Setting operators' identifier during import
I think this can be decided inside ONE.
APIs that code generator can easily take identifier
I think this needs requirments from the backend. @cgbahk wrote as NodeIndex luci::CircleNode::index();
related code generator(not ONE) works
This is up to backend participants.
So from the @mhs4670go question
- profiling info medium, i.e., where to store
ONE only needs to return index. I don't know how above item is related with the index
- identifier
This is already given as a requirement by @cgbahk
So, if you can provide how the profiling info medium and the Index is related, it would help for me.
seanshpark
on 27 Jan 2021
Another quenstion, as I know @llFreetimell and @mhs4670go are working on this task.
Are you both be working ONLY on ONE repo or in the backend also?
I assume @cgbahk will be working on the backend.
seanshpark
on 27 Jan 2021
Are you both be working ONLY on ONE repo or in the backend also?
@cgbahk is designing overall structures in the backend and some of related things are not fixed yet.
Until most of related things are fixed and overall design is finished, I think there is nothing special to help him :(
So If there are something we can help for backend in the near future, we may work for it at that time.
For now, we are to think about following things.
- Which format would we save profiling information and how to generate it?
- How can we connect full profiling information?
- How can we propagate profiling information from TF/ONNX node to circle node?
- etc
Of course, if something urgent but not expected thing happens, we will do that first :)
llFreetimell
on 27 Jan 2021
To me, first it requires some design work to process profile data in backend (what we usually said as 'infrastructure'). So that is primary goal as of now.
After that we have some 'scalable' tasks (to deliver profile info in each fuse/fold/etc passes), both on ONE compiler and backend. The amount of the task is not specified. We have no concrete plan for that yet.
cgbahk
on 27 Jan 2021
Thanks for describing the plan.
So what's the objective for "until 10th Feb." due?
- 'infrastructure' proposal
- 'infrastructure' finish
- 'infrastructure' finish + 'deliver profile info in each fuse/fold/etc passes' best practice
- 'infrastructure' finish + 'deliver profile info in each fuse/fold/etc passes' finish
seanshpark
on 27 Jan 2021
So what's the objective for "until 10th Feb." due?
To make (somewhat publicly acceptable) answer for this question is one of my goal in this sprint :smile:
Currently my personal expectation is close to
'infrastructure' finish + 'deliver profile info in each fuse/fold/etc passes' best practice
But should be specified more.
Doesn't matter what it would be, on ONE compiler side, this is only requirement from my understanding for "until 10th Feb." due:
Setting operators' identifier during import + APIs that code generator can easily take identifier
cgbahk
on 28 Jan 2021
I can say this issue is DONE by #5914 #5928, as it fulfills
Setting operators' identifier during import + APIs that code generator can easily take identifier
As next step, we have to make decision on circle to circle & model to circle profile info propagation.
- https://github.com/Samsung/ONE/issues/5794#issuecomment-767467328
- https://github.com/Samsung/ONE/issues/5794#issuecomment-767512659
As I understand we haven't made a consensus on that. It would be better to make a new issue for that purpose when necessary
If there's no opinion against, I would close this issue shortly. Thanks all for discussion and contribution :)
cgbahk
on 10 Feb 2021
Related issues
 hasw7569
·
4Comments
hasw7569
·
4Comments
 kishcs
·
3Comments
kishcs
·
3Comments
 periannath
·
3Comments
periannath
·
3Comments
 YongseopKim
·
3Comments
YongseopKim
·
3Comments
 KimDongEon
·
4Comments
KimDongEon
·
4Comments