One: MultiObjective Performance Optimization for Onert
This issue will focus on the problem of assigning backend (cpu, acl_cl, acl_neon) per operation, such as to optimize performance. The end-goal of the on-going work is to develop a computational algorithm capable of on-device execution. The said algorithm will provide a set of configurations (as opposed to a single configuration) that can be used to adapt system behaviour in two ways, namely, 1. choosing between memory-critical or time-critical profiles at runtime, and 2. implementing application-specific QoS (Quality of Service) guarantees.
Deviating from earlier works, this issue will address a combined optimization of system execution time and memory consumption. Therefore, the notion of optimality here is not a single point, but rather a pareto front.
The following posts should hopefully achieve the following:
- [x] Motivation and Background
describe the motivation for multiobjective optimization, backed with empirical traces from real-world deep learning models - [x] Problem Statement
formulate the multiobjective optimization problem, again with illustrative data from real-world models [ ] Current Progress
track current progress on algorithm development for multiobjective optimization.- [x] Generate backend mapping from decision space, implement brute-force exploration of solution space (#5789)
- [x] Implement random sampling profiler for on-device pareto estimation (#5789)
- [x] Implement Hamming Local Pareto Search Algorithm (#5842)
- [ ] Implement evolutionary algorithms for comparision
- [x] Preliminary profiling results and comparision with evolutionary algorithms for pareto estimation.
- [ ] Results from runtime backend reconfiguration, based on pareto front and observed performance.
- [ ] Related Issue on backend reconfiguration (#6878)
| | Tizen TM4 | Odroid XU4 |
| --| --------------|-------------|
|Mobilenet_V2_1.0_224_quant| :heavy_check_mark: | :heavy_check_mark: |
|InceptionV3| :heavy_check_mark: | :white_check_mark:|
|Posenet| :heavy_check_mark: | :heavy_check_mark: |
|ResNet_V2_101| :white_check_mark: | :white_check_mark: |
 dr-venkman
dr-venkman
All 16 comments
Why Multiobjective optimization
Current approach of optimizing performance minimizes the mean completion time of a graph model. In this context, there are two noteworthy concerns:
- When considering backends such as
cpuandacl_cl, the execution times and memory consumption often have an inverse relation. This is evident from the following figure which plots the combined metric of execution time and memory consumption, for different backend settings:
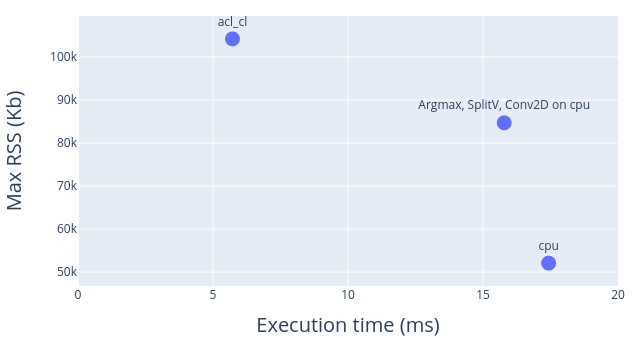
The results are borrowed from execution traces of a real-world model. In the above figure, it can be seen that assigning acl_cl to all operators fetches the best case execution time, but the memory consumption has increased. In contrast, assigning cpu to all operations gives best case performance for memory consumption, but execution time suffers.
In general, it is not immediately clear what the best-case performance is. For example, if the device has limited available memory, it might be practical to switch to a all-cpu setting.
- Tradeoff exploration is not considered.
In a multi-objective context, it would be interesting to exploit tradeoffs wherever they present themselves. For example, given two solution points A and B, where A and B differ greatly on one metric than the other, an optimization policy could allow switching from profile A to profile B (or vice-versa). For example, if solution B is slower then A by 10 milliseconds, but fetches a 50% reduction in memory consumption compared to A, an argument can be made to switch to solution B as an optimal setting. This can be seen from the following figure:
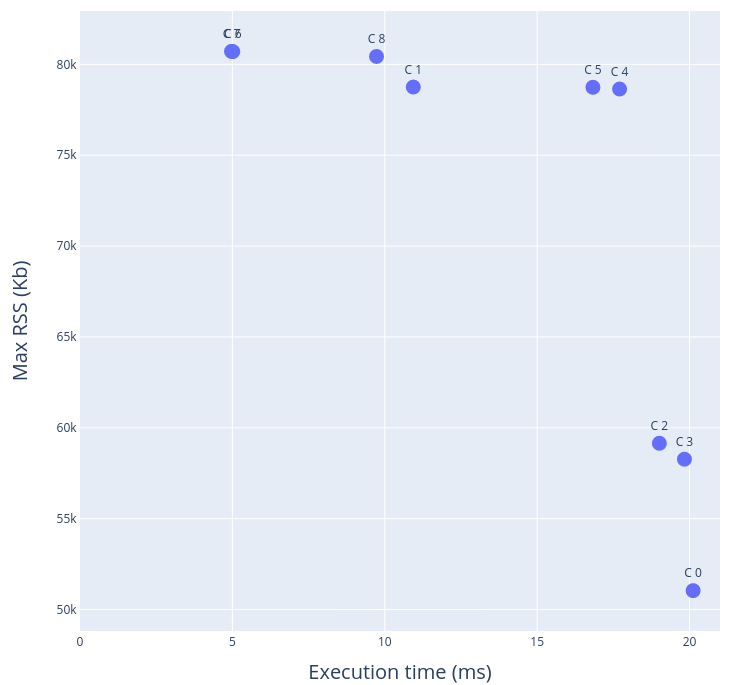
Here, solutions C4 and C2 represent the scenario described above, the difference in their execution times is less than 3 ms, however, by moving from C4 to C2, a memory savings by 25% can be guaranteed. Do note that this observation is specific to a solution space characterization, and therefore, needs to be analyzed on a case-by-case basis for every model.
To summarize, the following points are noted:
while latency forms an obvious choice for optimization, when considering on-device memory consumption, the playground for optimization widens considerably, and several solutions present themselves in place of one.
The choice for a particular setting depends on device-imposed, or application-specific QoS (Quality of Service) constraints. As an example, the latency constraint could be specified as
< 10 mswith a 10% tolerance, while memory constraint can be< 100 Mb, with a 20 % tolerance.
dr-venkman
on 1 Dec 2020
@dr-venkman , thank you for opening the discussion. It would be nice to discuss if I could know what you are ultimately trying to do with this topic. :)
By the way, if you change the list of numbers in the body of the issue to a checkbox, it will be easier to understand your current progress.
 lemmaa
on 9 Dec 2020
lemmaa
on 9 Dec 2020
@dr-venkman , thank you for opening the discussion. It would be nice to discuss if I could know what you are ultimately trying to do with this topic. :)
By the way, if you change the list of numbers in the body of the issue to a checkbox, it will be easier to understand your current progress.
@lemmaa , thank you for your supportive response :). I have added a line or two above regarding the end-objectives, and also used the checkbox approach for hopefully more points that I will be adding soon.
dr-venkman
on 9 Dec 2020
@lemmaa, the result of this work will be a python script implementation of a pareto-front estimation algorithm that can be run on a target device. This algorithm should be supposedly run for each model, per target to find a set of pareto-optimal points. The product owner can then choose from the estimated optimal settings, depending on specific requirements for latency and memory consumption.
This post will cover background and problem statement for the estimation, and then importantly open a discussion for scalability (estimation with large-sized models, increased number of backends). I am at a stage where the said algorithm works well as a proof-of-concept. So, I would appreciate any feedback on scalability when I introduce the topic for discussion.
dr-venkman
on 10 Dec 2020
@lemmaa, the result of this work will be a python script implementation of a pareto-front estimation algorithm that can be run on a target device. This algorithm should be supposedly run for each model, per target to find a set of pareto-optimal points. The product owner can then choose from the estimated optimal settings, depending on specific requirements for latency and memory consumption.
Having that flexibility is very important to us. @periannath seems to be working for a similar purpose, but it would be nice to discuss with each other. I think the following is such an attempt. https://github.com/Samsung/ONE/issues/4869 , https://github.com/Samsung/ONE/issues/5113 .
I feel that the two approaches to the same problem are a little different.
This post will cover background and problem statement for the estimation, and then importantly open a discussion for scalability (estimation with large-sized models, increased number of backends). I am at a stage where the said algorithm works well as a proof-of-concept. So, I would appreciate any feedback on scalability when I introduce the topic for discussion
Yes, scalability is a very important issue. Maybe it is more important to find an effective way to solve this problem. :)
lemmaa
on 10 Dec 2020
@lemma, thank you for the reply. Please find my comments below.
@lemmaa, the result of this work will be a python script implementation of a pareto-front estimation algorithm that can be run on a target device. This algorithm should be supposedly run for each model, per target to find a set of pareto-optimal points. The product owner can then choose from the estimated optimal settings, depending on specific requirements for latency and memory consumption.
Having that flexibility is very important to us. @periannath seems to be working for a similar purpose, but it would be nice to discuss with each other. I think the following is such an attempt. #4869 , #5113 .
Thank you for the links. Yes, I have very briefly seen them, and will be following further updates in that direction. I think it is very interesting to spot significant differences in optimal points when moving from per-operation type to per operation instance allocations. As a forward reference, this introduces the scalability issue that I was referring to.
I feel that the two approaches to the same problem are a little different.
This post will cover background and problem statement for the estimation, and then importantly open a discussion for scalability (estimation with large-sized models, increased number of backends). I am at a stage where the said algorithm works well as a proof-of-concept. So, I would appreciate any feedback on scalability when I introduce the topic for discussion
Yes, scalability is a very important issue. Maybe it is more important to find an effective way to solve this problem. :)
Yes, at the moment, I do see a tradeoff between efficiency of the algorithm and it's accuracy, especially for very large solution space (2^n, where n > 20).
dr-venkman
on 10 Dec 2020
Multiobjective Problem Statement
From the example above, one can see why it helps to have multiple settings that are relatively optimal with respect to each other. This discussion translates the requirements for multiple settings into a semi-formal problem statement, so that suitable algorithmic solutions may be explored in context.
Note that the notion of performance here is a combination of latency and memory consumption, and therefore, no two final settings will be better off without each other, unless a trade-off policy is implemented. This means that the optimal configuration of backends to operations follows a pareto frontier for the combined performance, as shown below by an illustrative example from a question answering model:
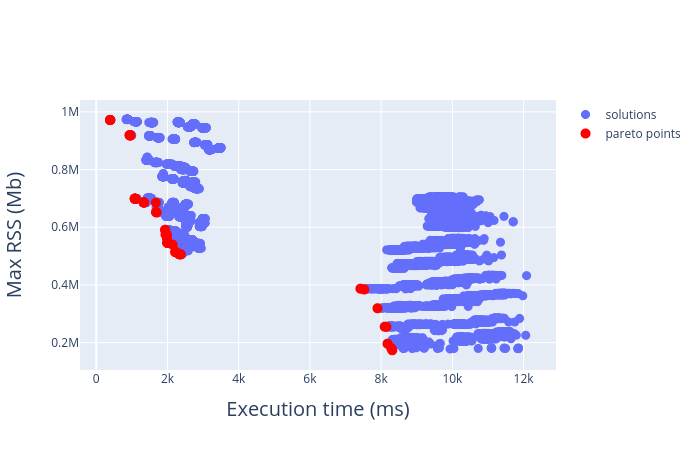
The pareto front above was determined offline by exploring a 8192-point solution space over a reduced set of backend assignment to operation types (as opposed to kernels). The following points are to be noted:
- Each performance point above is a result of a one-to-one configuration map from operations to backends.
- Every configuration map is a vector of
m-arybackend assignments tonoperations, wheremis the number of backends. This means that the solution space will havem**npoints - Every configuration setting is a
m-aryvector that can be mapped to a very large integer space. A pareto estimation algorithm essentially searches over this integer space to find the red-dotted solutions above.
In reality though, estimating the pareto front is non-trivial, and involves two main challenges:
Deep learning model graphs comprises a large number of nodes. For example, the tflite model
InceptionV3that has 126 operation kernels in its graph. Even if we are to consider only two backends, namelycpuandacl_cl, there are2**126possible configurations of backends, which characterizes a very large solution space.Estimating the pareto front directly on target device implies that we cannot evaluate the entire solution space, but only a fraction of it. This will impact estimation accuracy.
Considering the above challenges, the objective of the on-going work is to develop and implement an on-device algorithm (preferably a python script) that will estimate the pareto frontier with good accuracy by sampling only a faction of a very large solution space.
dr-venkman
on 18 Dec 2020
@periannath , thanks for sharing the details of the static scheduler. I am looking at the joint optimization of execution time and peak memory usage, and was wondering if it is possible to estimate the execution time given a backend mapping? The advantage of estimation is that it might save me a lot of profiling overhead especially when a model takes seconds to run.
I understand this requirement is complicated because of two reasons:
- It is different from a static scheduling approach that takes a local optimal decision at every node, given an initial topological ordering.
- There is a permute overhead when considering
acl_clandacl_neonbackends. On this subject, is the permute overhead bounded regardless of the mapping? That is, can we model it as a random variable with a mean and variance? If so, then the static approach or an offline estimation might work very well without needing much runtime profiling. Please let me know your view on this matter.
dr-venkman
on 8 Jan 2021
@dr-venkman
I am looking at the joint optimization of execution time and peak memory usage, and was wondering if it is possible to estimate the execution time given a backend mapping?
It seems that estimation is correct when some conditions are met.
It is different from a static scheduling approach that takes a local optimal decision at every node, given an initial topological ordering.
With 1 or 2 threads, estimation of inference time is quite correct. https://github.com/Samsung/ONE/issues/5118#issuecomment-738507944
When each backend uses 3 or 4 threads, estimation shows errors since context switching overhead is ignored in static backend scheduler.
On this subject, is the permute overhead bounded regardless of the mapping? That is, can we model it as a random variable with a mean and variance?
I'm not sure the meaning of the mapping. Is it means source and destination backend combination? If so, permute overhead should be affected by mapped backends. cpu and acl_cl backends use different padding for tensors so it needs substantial computations. However, cpu and ruy backends can share same tensor so there is not permutation overhead.
I'm thinking of measuring all the permutation time of backend combinations at profile time. This paper (https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8714959) uses that approach.
 periannath
on 8 Jan 2021
periannath
on 8 Jan 2021
@periannath , thanks for your reply, please find my specific remarks below:
@dr-venkman
I am looking at the joint optimization of execution time and peak memory usage, and was wondering if it is possible to estimate the execution time given a backend mapping?
It seems that estimation is correct when some conditions are met.
It is different from a static scheduling approach that takes a local optimal decision at every node, given an initial topological ordering.
With 1 or 2 threads, estimation of inference time is quite correct. #5118 (comment)
When each backend uses 3 or 4 threads, estimation shows errors since context switching overhead is ignored in static backend scheduler.
I see these results come from using cpu, ruy and xxnpack that do not effect a permute overhead. The differences are not that many, looking at the table, save for InceptionV3 with two threads.
On this subject, is the permute overhead bounded regardless of the mapping? That is, can we model it as a random variable with a mean and variance?
I'm not sure the meaning of the mapping. Is it means source and destination backend combination? If so, permute overhead should be affected by mapped backends.
cpuandacl_clbackends use different padding for tensors so it needs substantial computations. However,cpuandruybackends can share same tensor so there is not permutation overhead.
I meant mapping operation kernels to specific backends, but in a way, it does translate to differences between source and destination backend combination. Actually, your definition seems correct, from a viewpoint of estimating the execution time via algorithm.
I'm thinking of measuring all the permutation time of backend combinations at profile time. This paper (https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8714959) uses that approach.
I think this would really help to estimate the end-to-end execution time. Thanks for sharing the paper, I will definitely give it a read. As you will be running Deep RL on a host PC, I thought these works may also interest you:
Reinforced Genetic Algorithm Learning for Optimizing Computation Graphs
A Single-Shot Generalized Device Placement for Large Dataflow Graphs
I am not very sure of 2, as it may not relate to the scale of models that would run on an embedded target.
dr-venkman
on 8 Jan 2021
As you will be running Deep RL on a host PC, I thought these works may also interest you:
1. [Reinforced Genetic Algorithm Learning for Optimizing Computation Graphs](https://www.researchgate.net/publication/343725249_Reinforced_Genetic_Algorithm_Learning_for_Optimizing_Computation_Graphs) 2. [A Single-Shot Generalized Device Placement for Large Dataflow Graphs](https://ieeexplore.ieee.org/document/9162436)I am not very sure of 2, as it may not relate to the scale of models that would run on an embedded target.
Thank you for sharing those papers. I'll read them for sure. :blush:
periannath
on 11 Jan 2021
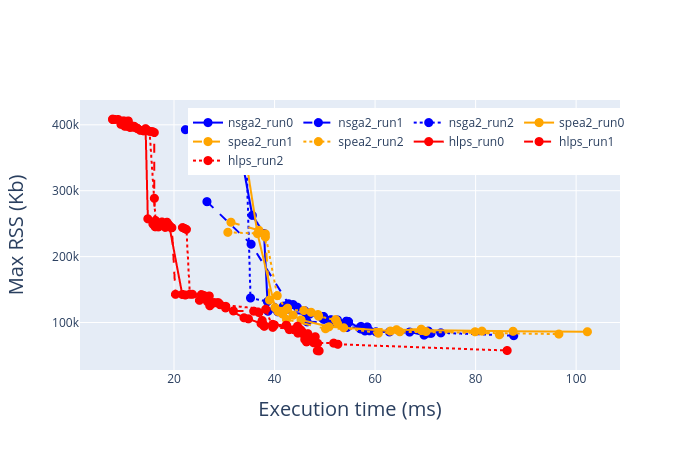
Graph below shows a comparision between HLPS, NSGA2 and SPEA2 on their relative estimation, when tried over MobilenetV2 quantized model. The results come from profiling on a Odroid-XU4 device. (Progress tracked above).
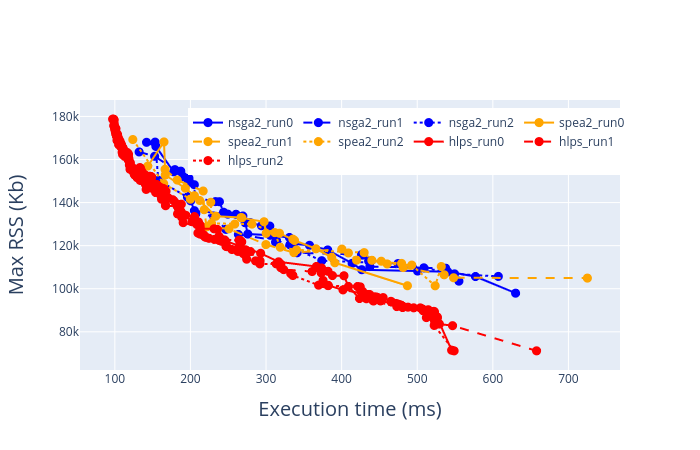
Each algorithm was made to run thrice, and the results of all the runs are plotted together, so that we can also see the variability in between.
Interesting thing to note is that there seems to be a gradual tradeoff characteristic between peak RSS and latency, which allows for run-time adaptation under different system loads. For example, if the available RAM does not allow setting for minimum latency, then the next available minimal latency setting could be selected.
I am currently working on a demo application to showcase the above scenario, and will post the results alongside further performance comparisions.
dr-venkman
on 18 Mar 2021
MobilenetV2 on TM4
dr-venkman
on 22 Mar 2021
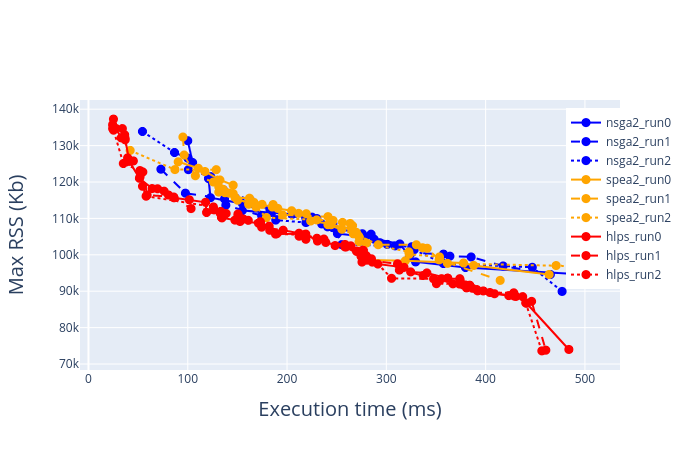
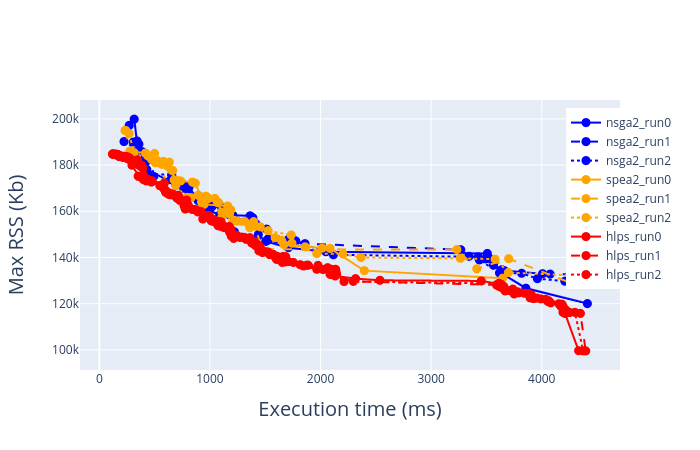
Below are the results of pareto estimation on Pose Estimation Model.
Pose estimation on TM4
Pose estimation on Odroid-XU4
dr-venkman
on 26 Mar 2021
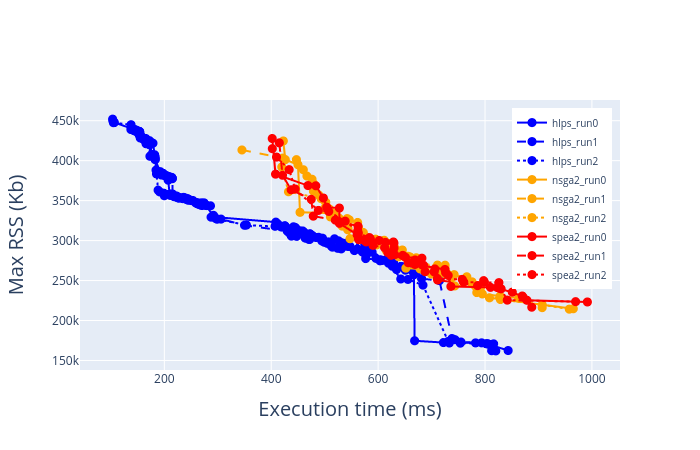
Below are the results of pareto estimation on InceptionV3
InceptionV3 on TM4
dr-venkman
on 12 Apr 2021
Pareto-front based Backend Reconfiguration
Based on the pareto-front estimated above, a lookup of
The figure below shows one such scenario, where MobilenetV2_quant runs concurrently with InceptionV3. The performance points from a pareto-front based scheduler (red triangles) are contrasted against a static backend setting for low latency (all GPUs, and shown by a green square).
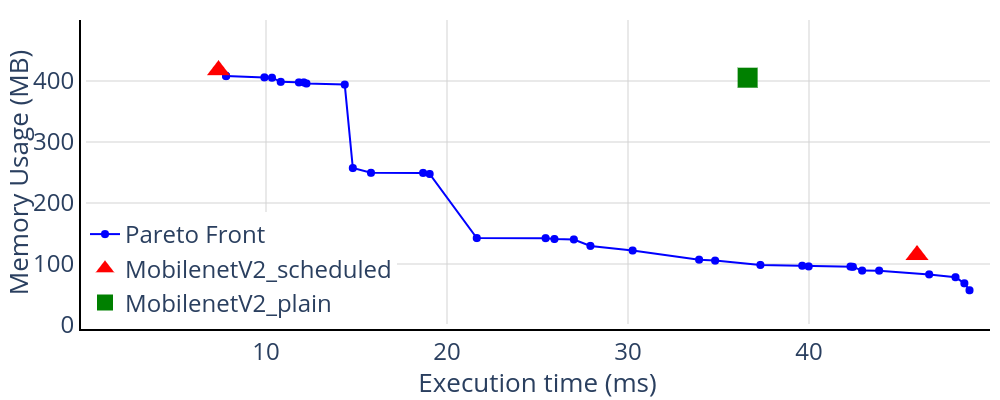
How does the pareto scheduler work?
At present, every session monitors its own performance independently of each other, and reconfigures backends when either latency suffers, or more memory becomes available. In the above scenario, InceptionV3 takes a larger share of the GPU, thereby causing latency to increase to a mean value of ~36 ms (See MobilenetV2_plain). The pareto scheduler uses this observation to change backend settings to a configuration whose latency is about that value, but with a reduced memory consumption. Later, when InceptionV3 is closed, the released memory is picked up by MobilenetV2_scheduled to revert to a all-GPU configuration (shown by the marker on the top left).
As far as end-to-end latency goes, the table below summarizes the results (values in seconds):
| | All GPU | Pareto-scheduled |
| --| --------------|------------------|
|InceptionV3| 24.2 | 22.7 |
|MobilenetV2| 24.2| 24.5 |
dr-venkman
on 21 May 2021
Related issues
periannath
·
3Comments
 wateret
·
4Comments
wateret
·
4Comments
 YongseopKim
·
3Comments
YongseopKim
·
3Comments
 lucenticus
·
3Comments
lucenticus
·
3Comments
 KimDongEon
·
4Comments
KimDongEon
·
4Comments