Background
In inference models (tflite or circle), batchnorm is usually fused with the preceding CONV layer for better performance.
ResNet V2 has non-trivial structure called _pre-activation_ to improve model generalization. (<-> activation after CONV, i.e., post-activation). (paper link: https://arxiv.org/pdf/1603.05027v3.pdf)
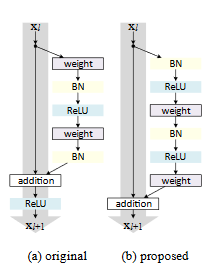
In post-activation models (a), tflite_convert automatically fuses batchnorm into the preceding CONV layer (depicted as weight).
In pre-activation models (b), however, it is not simple to fuse batchnorm computations into nearby CONV layers.
Goal
Introduce a new pass named FusePreActivationBatchNormPass that fuses batchnorm computations of pre-activations into nearby CONV layers. And finally remove all batchnorm computations in ResNet V2.
Progress
- [x] Add
FusePreActivationBatchNormPassin luci - [x] Add test (luci)
- [x] Add test (dredd)
- [x] Add a pass to fuse remaining activation functions (
FuseActivationFunctionPass) #4833 - [x] Add a pass to change negative values in gamma to positive (
MakeBatchNormGammaPositivePass) - [x] Update one-cmds
CC @periannath
 jinevening
jinevening
All 5 comments
Performance measurement
- Model : ResNet v2
Device : S20+ exynos
| Backend | Before fusion | After fusion | Speedup |
|--|--|--|--|
| cpu | 478.5 | 469.0 | 1.02 |
| acl_cl | 143.1 | 134.8 | 1.06 |
Device : odroid-xu4
| Backend | Before fusion | After fusion | Speedup |
|--|--|--|--|
| cpu | 1254.1 | 1224.4 | 1.02 |
| acl_cl | 662.4 | 651.4 | 1.02 |
 periannath
on 28 Oct 2020
periannath
on 28 Oct 2020
I close this issue as all tasks are done.
To sum up, we could successfully fuse 17 out of 17 pre-activations in ResNet50 V2. The performance improvement in onert is shown in the above table.
jinevening
on 4 Nov 2020
I close this issue as all tasks are done.
last one is not checked :)
 seanshpark
on 4 Nov 2020
seanshpark
on 4 Nov 2020
last one is not checked :)
I forgot to check the box. Thanks! :)
jinevening
on 4 Nov 2020
Performance comparison of quantized model
- Model : ResNet v2
- CPU doesn't support RELU for uint8
Device : S20+ exynos
| Backend | Before fusion | After fusion | Speedup |
|--|--|--|--|
| acl_cl | 53.6 | 50.7 | 1.06
Device : odroid-xu4
| Backend | Before fusion | After fusion | Speedup |
|--|--|--|--|
| acl_cl | 1113.2 | 1092.8 | 1.02
periannath
on 13 Nov 2020
Related issues
 underflow101
·
4Comments
periannath
·
3Comments
seanshpark
·
3Comments
underflow101
·
4Comments
periannath
·
3Comments
seanshpark
·
3Comments
 YongseopKim
·
3Comments
YongseopKim
·
3Comments
 kishcs
·
3Comments
kishcs
·
3Comments
Most helpful comment
Performance measurement
Device : S20+ exynos
| Backend | Before fusion | After fusion | Speedup |
|--|--|--|--|
| cpu | 478.5 | 469.0 | 1.02 |
| acl_cl | 143.1 | 134.8 | 1.06 |
Device : odroid-xu4
| Backend | Before fusion | After fusion | Speedup |
|--|--|--|--|
| cpu | 1254.1 | 1224.4 | 1.02 |
| acl_cl | 662.4 | 651.4 | 1.02 |