One: [imgdata2hdf5] Python script to convert raw image data to hdf5
The input dataset for the argument of record-minmax has the form of hdf5. Users may have difficulty in making hdf5 file, so we will provide imgdata2hdf5.py, a Python script that converts raw data to hdf5 (only for image data for now)
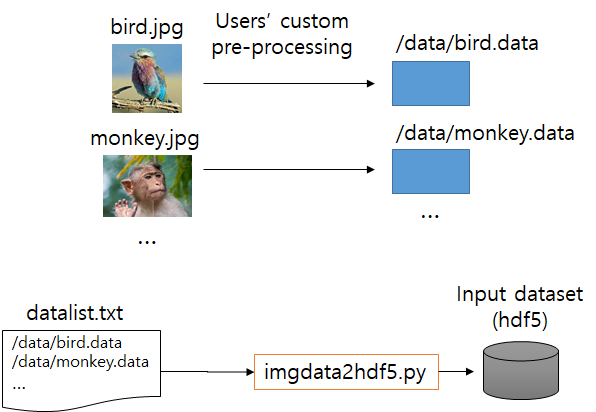
Input of imgdata2hdf5.py : data list (text file)
Output of imgdata2hdf5.py : hdf5 file which can be used by record-minmax
 jinevening
jinevening
All 12 comments
Example
python imgdata2hdf5.py \
> --data_list=/tmp/imgdata/datalist.txt
> --output_path=/tmp/imgdata/imgdata.hdf5
Contents of datalist.txt
/tmp/imgdata/data/bird.data
/tmp/imgdata/data/monkey.data
bird.data and monkey.data are raw image data provided by users.
Arguments
-h, --help Show this help message and exit
-l DATA_LIST, --data_list DATA_LIST
Path to the text file which lists the absolute paths of the image data files to be converted.
-o OUTPUT_PATH, --output_path OUTPUT_PATH
Path to the output hdf5 file.
Just curious. if we gather all the image files in the input_path, then data_list is needless.
if some files are tobe exluced then not all files are used so list is needed. is this the reason of data_list file existance?
just another thought, if data_list all items has absolute path then input_path maybe needless.
if there are hundreds or thousands images, preparing this data_list is a task.
I think not doing this task would help users...
or is there some simple way for this?
 seanshpark
on 16 Jul 2020
seanshpark
on 16 Jul 2020
if some files are tobe exluced then not all files are used so list is needed. is this the reason of data_list file existance?
Yes. data_list is for allowing users to exclude un-wanted files.
just another thought, if data_list all items has absolute path then input_path maybe needless.
I agree with you.
if there are hundreds or thousands images, preparing this data_list is a task.
I think not doing this task would help users...
or is there some simple way for this?
I agree that it can be a burden for some users. Using data_list is an idea from @lemma (AFAIK, SNPE quantization tool supports such an interface). @lemmaa what do you think of this issue?
jinevening
on 16 Jul 2020
@jinevening , @seanshpark , shouldn't we support both --input_path and --data_list?
Both have their own advantages. --input_path eliminates the inconvenience of list creation, and --data_list supports selective test set configuration without moving the target file. (You can mix and use data from multiple directories)
Basically, I expect to use one of them exclusively according to users choice.
If both are used, --input_path can be used to set the BASE_PATH, and --data_list can be used to select only the necessary data in the path. Of course, this is a problem that can be solved by writing two --data_lists, so we don't care to support this cae. :)
 lemmaa
on 16 Jul 2020
lemmaa
on 16 Jul 2020
AFAIK, SNPE quantization tool supports such an interface
@jinevening , FYI, SNPE supports only --data_list. :)
https://developer.qualcomm.com/docs/snpe/tools.html#tools_snpe-dlc-quantize
--input_list=<val> Path to a file specifying the trial inputs. This file should be a plain text file,
containing one or more absolute file paths per line. These files will be taken to constitute
the trial set. Each path is expected to point to a binary file containing one trial input
in the 'raw' format, ready to be consumed by SNPE without any further modifications.
This is similar to how input is provided to snpe-net-run application.
@lemma, using only one looks good. from the example @jinevening provided didn't reflect this. from only with the option description, it is bit hard to understand. it would be better to provide examples so that users can choose.
seanshpark
on 16 Jul 2020
@seanshpark I've updated the example
jinevening
on 16 Jul 2020
@jinevening What about supporting:
- preprocessing
- network types other than image classification
- multiple inputs
Or is it planned for very limited uses?
I had other idea in mind. May be write a python module which the user can import and use for feeding images to the quantizer tool? This is more flexible and hides hdf5 dependency. There are many possible implementations. For example:
import one
c = one.quantizer.DataSetContainer()
for ... # For each dataset
# The user prepares data themselves, e.g. reads a file and preprocesses it as needed.
input1_data = ...
input2_data = ...
c.add({"input1": input1_data, "input2": input2_data}) # Add a single set of inputs.
ds.save("path/to/output/file")
or
import one
model = one.load_model("path/to/model.circle")
quantizer = one.Quantizer(model)
for ... # For each dataset
# The user prepares data themselves, e.g. reads a file and preprocesses it as needed.
input1_data = ...
input2_data = ...
quantizer.refine({"input1": input1_data, "input2": input2_data}) # Updates min/max using single set of inputs.
quantized_model = quantizer.quantize() # Uses min/max to quantize the model.
one.save_model(quantized_model, "path/to/quantized_model.circle")
This solves all the above problems and also hides dependency on hdf5, thus more flexible. The latter also avoids saving the data into files at all and passes it in-memory.
 s-barannikov
on 16 Jul 2020
s-barannikov
on 16 Jul 2020
@jinevening What about supporting:
- preprocessing
- network types other than image classification
- multiple inputs
Or is it planned for very limited uses?
imgdata2hdf5 is a tool for image data (as its name implies). It would be good to make a general tool (raw data -> hdf5), but I have no plan for that now (this tool is for user convenience, so I made it as simple as possible).
Your Python interface looks very convenient (it looks similar to the Python interface of TFLite quantizer). If the Python interface is supported, we will not need translation (data -> hdf5) tools. I thought users can easily generate hdf5 file by just packaging raw data at the end of their pre-processing Python scripts. But everybody except me thinks that users will have difficulty on making the hdf5 file, so I'm ok to remove hdf5 in the tool chain (it will make the release process much easier as well).
jinevening
on 17 Jul 2020
@jinevening
I see, thanks.
s-barannikov
on 18 Jul 2020
I close this issue because this job is done.
jinevening
on 20 Jul 2020
I leave this comment to share example images.
jinevening
on 6 Nov 2020
Related issues
 KimDongEon
·
4Comments
KimDongEon
·
4Comments
 mhs4670go
·
4Comments
seanshpark
·
3Comments
seanshpark
·
3Comments
mhs4670go
·
4Comments
seanshpark
·
3Comments
seanshpark
·
3Comments
 periannath
·
3Comments
periannath
·
3Comments