Updated 2020/06/24: The test framework now tests the end-to-end quantization steps (fake quantization, record minmax, quantization).
We are implementing post-training quantization (#696). This issue is about quantization-value-test, which tests the quantized values of a circle model.
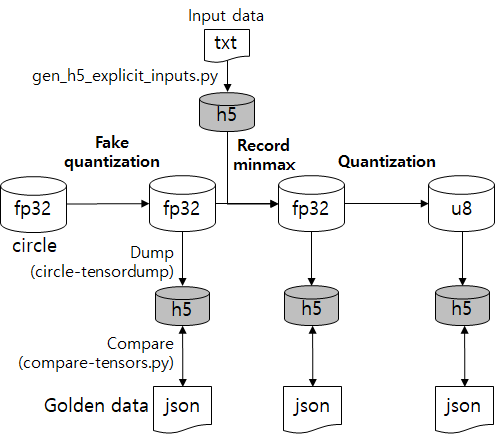
Above figure shows the overview of quantization-value-test. More details about the test process is described below.
Step 1. Fake quantization
Run circle2circle with --quantize_dequantize_weights option.
Dump the fake-quantized model with circle-tensordump.
Compare the dumped model with the expected output in "expected_outputs/
The expected output should include
(1) values of weights (for conv, transposed_conv, depthwise_conv, fc layers)
Step 2. Record moving avg of min and moving avg of max for activations
Run record-minmax with the fake-quantized model (input data is saved in "test_inputs/
Dump the minmax-recorded model with circle-tensordump.
Compare the dumped model with the expected output in "expected_outputs/
The expected output should include
(1) min/max of activations
Step 3. Quantization
Run circle2circle with --quantize_with_minmax option.
Dump the quantized model with circle-tensordump.
Compare the dumped model with the expected output in "expected_outputs/
The expected output should include
(1) scale, zero point of activations
(2) scale, zero point, values of weights
(3) scale, values (weights) of bias
 jinevening
jinevening
All 11 comments
Format of the tensor file (.h5)
We use hdf5 file (.h5) to save tensors. Hierarchy of the file is as below.
Group "/"
ㄴGroup <tensor_name>
ㄴDataset "weights"
ㄴDataset "zero_point" Shape (n)
ㄴDataset "scale" Shape (n)
tensor_name : name of tensor (/ is replaced with _)
weights : weights of the tensor
zero_point : zero points (shape: n = 1 for layer-wise quant, n = dimension of channel for channel-wise quant)
scale : scale (shape: same with zero_point)
Example: tensors related to a conv layer, channel-wise quant for filters and bias
Group "/"
ㄴGroup "conv_filters"
ㄴDataset "weights"
ㄴDataset "zero_point" Shape (3)
ㄴDataset "scale" Shape (3)
ㄴGroup "conv_bias"
ㄴDataset "weights"
ㄴDataset "zero_point" Shape (3)
ㄴDataset "scale" Shape (3)
ㄴGroup "conv_input"
ㄴDataset "weights"
ㄴDataset "zero_point" Shape (1)
ㄴDataset "scale" Shape (1)
...
Note that zero_point and scale of "conv_input" have shape (1), because quantization was applied per layer.
zero_point and scale of "conv_filters" and "conv_bias" have the shape (3), because quantization was applied per channel.
jinevening
on 10 Jun 2020
@mhs4670go , @jinevening
I think I can suppport to make golden set's format as below.
Group "/"
ㄴGroup "conv_filters"
ㄴDataset "weights" : type(uint8, int16)
ㄴDataset "zero_point" Shape (1,3)
ㄴDataset "scale" Shape (1,3)
ㄴGroup "conv_bias"
ㄴDataset "weights" : type(int32)
ㄴGroup "conv_input"
ㄴDataset "zero_point" Shape (1,1)
ㄴDataset "scale" Shape (1,1)
ㄴGroup "conv_output"
ㄴDataset "zero_point" Shape (1,1)
ㄴDataset "scale" Shape (1,1)
Furthermore,
I gonna make golden set 2 things.
- ResNet-50 (layer-wise weight quant / layer-wise act quant )
- MobileNet-v1 (channel-wise weight quant / layer-wise act quant )
If you have some questions, let me know.
 meejeong
on 12 Jun 2020
meejeong
on 12 Jun 2020
@jinevening @meejeong
I have a few questions about hdf5 layout.
First, why do their shapes have one more extra rank? I mean, they have (1,n) shapes not (n). Is there any reasons?
Second, conv_filters got a Dataset whose name is "weights". But so does conv_bias. It seems natural conv_filters got it. but Is it okay to name it weights to bias? maybe this question came up because I'm not familiar with this field yet:)
Third, IIUC, quantization will be applied to only conv-siblings(?) and activation. conv_input and conv_output are activations, aren't they? I'm just confused as of its name:)
 mhs4670go
on 13 Jun 2020
mhs4670go
on 13 Jun 2020
First, why do their shapes have one more extra rank? I mean, they have (1,n) shapes not (n). Is there any reasons?
I decided the shape format, but it seems that the extra rank is unnecessary. It would be better to use just rank 1. Thanks.
Second, ... Is it okay to name it weights to bias? maybe this question came up because I'm not familiar with this field yet:)
It's a naming issue, which is one of the hardest problems :) We can use different names according to operators, but it will be more complicated. I just used the term 'weights' in general to call the buffer of constant tensors. If you have a better name, please suggest one. I'm ok with changing the name if @meejeong agrees.
Third, IIUC, quantization will be applied to only conv-siblings(?) and activation. conv_input and conv_output are activations, aren't they?
Yes, they are activations. Quantization will be applied to all tensors except the outputs of some special Ops such as ArgMax.
jinevening
on 14 Jun 2020
Format of the golden data (.json)
The golden data is saved in expected_output/<recipe_name>/<granularity>/<quantized_type>/<test_name>/<tensor_name>.json.
recipe_name : a recipe saved in res/TensorFlowLiteRecipes
granularity : layer (channel will be supported soon)
quantized_type : uint8 (int16 will be supported soon)
test_name : fake_quantization, record_minmax, quantization
Ex: The golden data of the activation named 'ifm' in the final quantized model is saved in expected_output/Conv2D_004/layer/uint8/quantization/ifm.json.
Contents of ifm.json
{
"scale": 0.09411764705882353,
"zero_point": 0.0
}
Format of the input data (.txt)
The input data is saved in test_inputs/<recipe_name>/<granularity>/<quantized_type>/<record_number>.txt.
recipe_name : a recipe saved in res/TensorFlowLiteRecipes
granularity : layer (channel will be supported soon)
quantized_type : uint8 (int16 will be supported soon)
record_number : index of input record (starting from 0)
The input data is written in the txt file. If the test model has multiple inputs, each input should be saved in different lines.
Ex: The first input data of Conv2D_004 is saved in test_inputs/Conv2D_004/layer/uint8/0.txt.
Contents of 0.txt (Conv2D_004.circle has one input whose shape is (1,4,3,2). The data in the txt file is reshaped when used by record-minmax )
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24
Format of the input data (.txt)
Is this input data format only for small input data or will it be also used for real images?
 seanshpark
on 24 Jun 2020
seanshpark
on 24 Jun 2020
Is this input data format only for small input data or will it be also used for real images?
I didn't consider testing with real images, because this is a unittest for a small model (generated from hand-written recipes).
jinevening
on 24 Jun 2020
Since our quantization algorithm has changed, the test data should be updated.
Changed parts.
- Set the lowest scale value (1e-5)) #3480
- Use percentile when clipping recorded min/max values #3047
jinevening
on 10 Aug 2020
The list of target operators
CIRCLE OP | Status
-- | --
(LWQ) CONV_2D | O
(LWQ) TRANSPOSE_CONV | O
(LWQ) DEPTHWISE_CONV | O
(LWQ) FULLY_CONNECTED | O
(CWQ) CONV_2D | O
(CWQ) TRANSPOSE_CONV | O
(CWQ) DEPTHWISE_CONV | O
(CWQ) FULLY_CONNECTED | O
jinevening
on 10 Aug 2020
I close this issue because all targets are covered.
jinevening
on 19 Aug 2020
Related issues
 ragmani
·
4Comments
jinevening
·
3Comments
ragmani
·
4Comments
jinevening
·
3Comments
 periannath
·
3Comments
periannath
·
3Comments
 lucenticus
·
3Comments
lucenticus
·
3Comments
 hasw7569
·
4Comments
hasw7569
·
4Comments
Most helpful comment
@mhs4670go , @jinevening
I think I can suppport to make golden set's format as below.
Furthermore,
I gonna make golden set 2 things.
If you have some questions, let me know.