Okhttp: Okhttp 3.10.0 Multiple Concurrent POST/PUT Retries
Hello,
We are seeing rare instances of our android app spamming us with requests that look like the following:
h2 2018-09-05T02:38:24.331062Z app/prod-api-alb <userIp> <EndpointIp> 0.003 0.538 0.000 400 400 943 282 "POST https://api... HTTP/2.0"
h2 2018-09-05T02:38:28.557953Z app/prod-api-alb <userIp> <EndpointIp> 0.000 5.009 0.000 503 503 356 244 "POST https://api... HTTP/2.0"
h2 2018-09-05T02:38:28.627333Z app/prod-api-alb <userIp> <EndpointIp> 0.000 5.005 0.000 503 503 39 244 "POST https://api... HTTP/2.0"
h2 2018-09-05T02:38:28.629808Z app/prod-api-alb <userIp> <EndpointIp> 0.004 5.003 0.000 503 503 39 244 "POST https://api... HTTP/2.0"
Those 503's will repeat often hundreds of times essentially DDOS'ing our api. It typically starts with a POST/PUT 400 response to some endpoint, then about 4-5 seconds later 10-20 calls will be made in parallel. These typically all 503 and the cycle continues for quite a while.
I'm assuming this has to do with okhttp retrying failed requests, but I'm unable to duplicate the behavior at all (and it only happens in production one or two times per day. Note that it always seems to occur over http2 as well.
Has anyone seen something like this? Any help is appreciated.
 dmhood
dmhood
All 17 comments
OkHttp won't retry unless there's a connectivity problem on a recycled HTTP/1 connection; that's unlikely to be the cause here.
My guess is there's something in the application code that's retrying?
 swankjesse
on 6 Sep 2018
swankjesse
on 6 Sep 2018
@swankjesse Thanks for the response.
We've audited our application code pretty considerably--although it is a react-native app so I guess it could be something in the react-native layer.
We did ship a new version several days ago with retryOnConnectionFailure set to false and haven't seen the behavior occur again, however.
dmhood
on 9 Sep 2018
Hi. We are also seeing this type of behaviour.
There are bursts of hundreds of POST requests to our backend. It appears that in our backend, the requests time out in the end, while waiting to read the POST body from the request.
We have reviewed our app quite extensively, there should be no reason for this behaviour.
As the problem is quite severe, any help would be greatly appreciated.
Environment: react-native app, android 8.0.x, okhttp 3.10.0.
 mtkopone
on 19 Sep 2018
mtkopone
on 19 Sep 2018
Just an update, in the 12ish days we've had retryOnConnectionFailure set to false, we have yet to see the issue occur again, so it looks like that's fixed it. It's not ideal to have it turned off, but its better than spamming our backend at the moment.
dmhood
on 19 Sep 2018
Thanks for the update. Do you have insight into how clients are observing the failures now? I'm expecting they'll be seeing an increased rate of IOExceptions.
If you have access to any of the client exception stacktraces I'd love to see em. When we don't retry the client gets an exception.
swankjesse
on 19 Sep 2018
I'm on Okhttp 3.9.1 and experiencing the same issue. For quite a while now, our server team has been complaining that Android client is sending too many requests.
Their report shows that one user sent 14000+ requests in 5 minutes.
And usually there has been several instances of this happened in a month.
I set retryOnConnectionFailure to false, and it seemed the issue was fixed, but after 5 minutes or so, the connection goes staled (IO Exception), and all subsequent/same requests will fail.
Now I'm stuck with figuring out how to evict staled connection out of the pool and retry one more time instead of indefinite retries.
 kmspop
on 25 Sep 2018
kmspop
on 25 Sep 2018
FYI, I set retryOnConnectionFailure to false, used an interceptor, and if IO exception is thrown, I call evictAll() and retry the request one more time.
That seemed to fix the issue once and for all.
Not sure if that's a proper way to do, but at least that fixed my issue.
kmspop
on 26 Sep 2018
So, after 1 week in production with retryOnConnectionFailure=false, our servers are now fine.
Our clients are not. We are seen a lot of thrown errors from the react-native fetch-api we are using. The ones we have been able to replicate all only say "TypeError: network request failed".
A surefire way to replicate the "network request failed"-error is to do a fetch in the callback of an incoming websocket message.
mtkopone
on 26 Sep 2018
@mtkopone any chance you could isolate into an executable test case? I don’t use react-native so I need to find a way to reproduce without that. Here’s something to get started: https://gist.github.com/swankjesse/981fcae102f513eb13ed
swankjesse
on 27 Sep 2018
@swankjesse I'll look into that when I have a moment.
As additional info, the websocket->http request failures only occurred when the connections (both websocket & http) were over http. Changing to https and wss made them magically go away :)
mtkopone
on 27 Sep 2018
Maybe a bad gateway? No further action to take on this.
swankjesse
on 4 Nov 2018
@dmhood @mtkopone By chance, were those post/puts doing anything IO related from the device? Such as a file upload?
We are seeing this and as best as we can tell, it is due to the retry logic in RetryAndFollowUpInterceptor that on IOException or RouteException that short circuit early and don't look at the response to do any checking if they should stop retrying.
In our case, we are doing file uploads and the best guess so far is a tmp file that gets removed eagerly or a corrupt inode on a device's file system.
BTW, we see this at a lot higher impact, thousands of requests until the device crashes. We have confirmed that we are sending status codes that should cause the device to short circuit retries, and as far as we can tell, it isn't the application code sending those 1000s of requests.
 addisonj
on 6 Dec 2018
addisonj
on 6 Dec 2018
Super interesting @addisonj. Could be causing the RetryAndFollowUpInterceptor to interpret a client-side failure as a server-side failure.
swankjesse
on 6 Dec 2018
@swankjesse we are working on getting a minimal repro up today, not sure of what the fix would be, but will share details as we have them :)
addisonj
on 6 Dec 2018
Ok we have a fix in place with #4523. Let me know what else you need.
 feathj
on 3 Jan 2019
feathj
on 3 Jan 2019
Here is a gist of how we were able to repro:
https://gist.github.com/feathj/a60ba9ad8a0b1d61dc74f3e20832f56b
feathj
on 3 Jan 2019
We also run into the same issue as @addisonj in uploading file as well. We have audit our app extensively. We have narrowed down to similar area in RetryAndFollowUpInterceptor and that IOException or RouteException short circuit.
here is the stacktrace of the issue
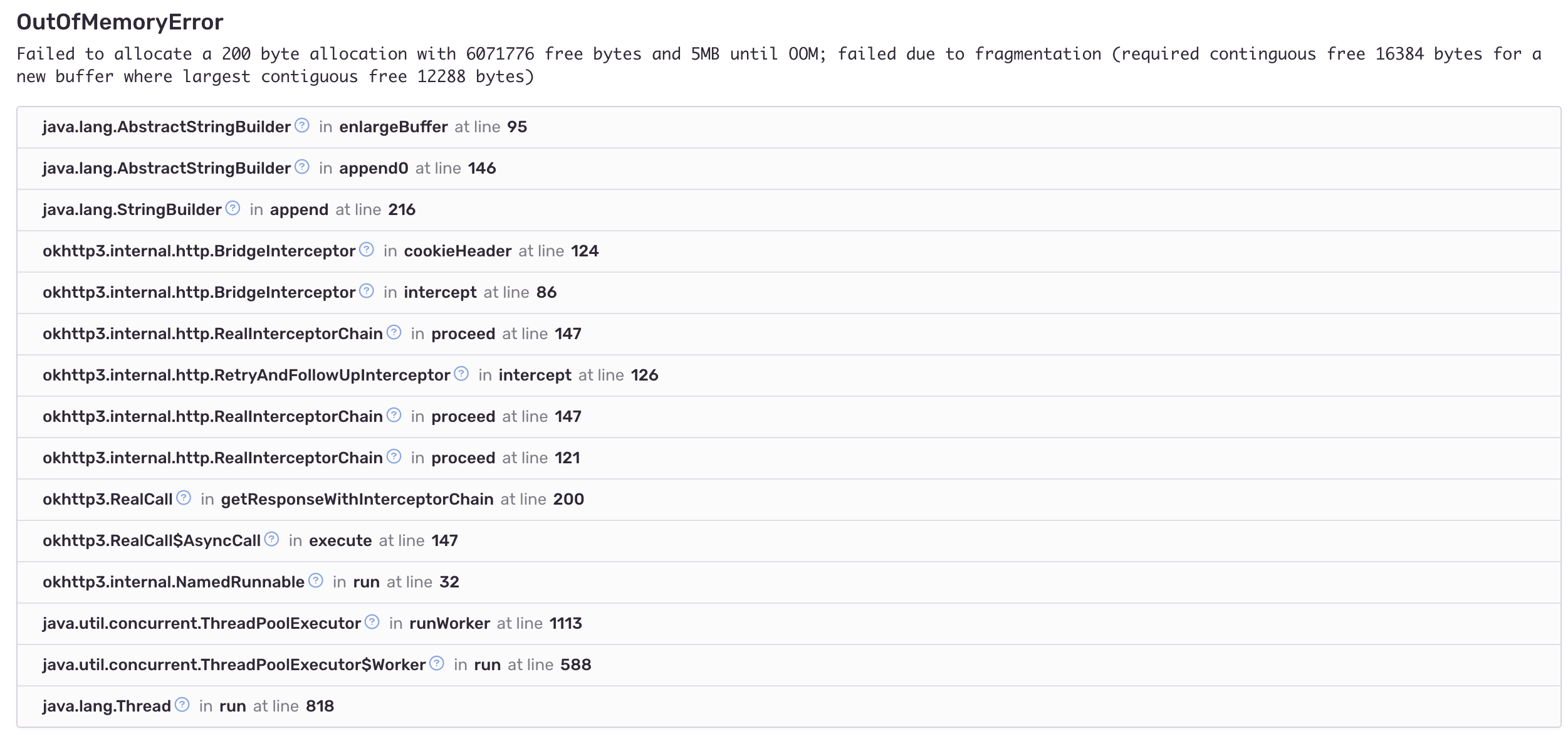
Any update on the PR or mitigation we can put in place in the meantime?
 yuit
on 9 Jan 2019
yuit
on 9 Jan 2019
Related issues
 rfc2822
·
3Comments
rfc2822
·
3Comments
 NitzDKoder
·
3Comments
NitzDKoder
·
3Comments
 albka1986
·
3Comments
albka1986
·
3Comments
 maoai-xianyu
·
3Comments
maoai-xianyu
·
3Comments
 SandroMachado
·
3Comments
SandroMachado
·
3Comments
Most helpful comment
Hi. We are also seeing this type of behaviour.
There are bursts of hundreds of POST requests to our backend. It appears that in our backend, the requests time out in the end, while waiting to read the POST body from the request.
We have reviewed our app quite extensively, there should be no reason for this behaviour.
As the problem is quite severe, any help would be greatly appreciated.
Environment: react-native app, android 8.0.x, okhttp 3.10.0.