Octoprint: 403 error on websocket when hostname case does not match
What were you doing?
When using the octopod iPhone app where the URL to connect to the octoprint server has a different case than the hostname configured on the machine (an octopi in this case), the octopod client gets a "Not refreshing" error and the octoprint repeatedly logs show:
2020-04-13 11:56:36,579 - tornado.access - WARNING - 403 GET /sockjs/websocket (::ffff:192.168.1.1) 1.56ms
(After much trial and error) I found that the hostname on the machine is configured as "3dprinterpi.example.com" (it's not really example.com, but you get the picture. The important info is the hostname is all lowercase). In my octopod printer config, i had the hostname set as "http://3dPrinterPi.example.com". This seems to cause the 403 errors. If I change the hostname to "http://3dprinterpi.example.com", it works.
I reported this to Octopod (https://github.com/gdombiak/OctoPod/issues/298), but it seems this might a tornado issue or how octoprint is using tornado.
This is from @gdombiak:
TL;DR: According to the specification, clients (like OctoPod) should be able to send uppercase/lowercase/any mix and things should still work. This could be a Tornado issue or maybe some validation done by OctoPrint? I never looked at that part of OctoPrint's code to know what is going on.
To Reproduce:
- Configure octopod client to use a URL where the case is different than the case defined on the octoprint server.
- Try to connect to the octoprint server using the Octopod client.
What did you expect to happen?
the octopod client should function normally (get and set data, control the printer, etc).
What happened instead?
The octopod client gets the initial data, but all subsequent websocket requests get a 403 error. The octopod client no longer gets any data.
Did the same happen when running OctoPrint in safe mode?
I haven't tried. It's running a 8 hour print. This likely has nothing to do with safe mode. But I'll try when it's done and update this issue.
Version of OctoPrint
1.4.0
Operating System running OctoPrint
Octopi-0.17.0
Printer model & used firmware incl. version
Printrbot play. Marlin (unsure of firmware version, but shouldn't matter for this issue as i'm not getting that far)
Browser and version of browser, operating system running browser
Not applicable (Not on browser)
Link to octoprint.log
Link to contents of terminal tab or serial.log
nothing as the client can't get to it.
Link to contents of Javascript console in the browser
Not applicable (Not on browser)
Screenshot(s)/video(s) showing the problem:
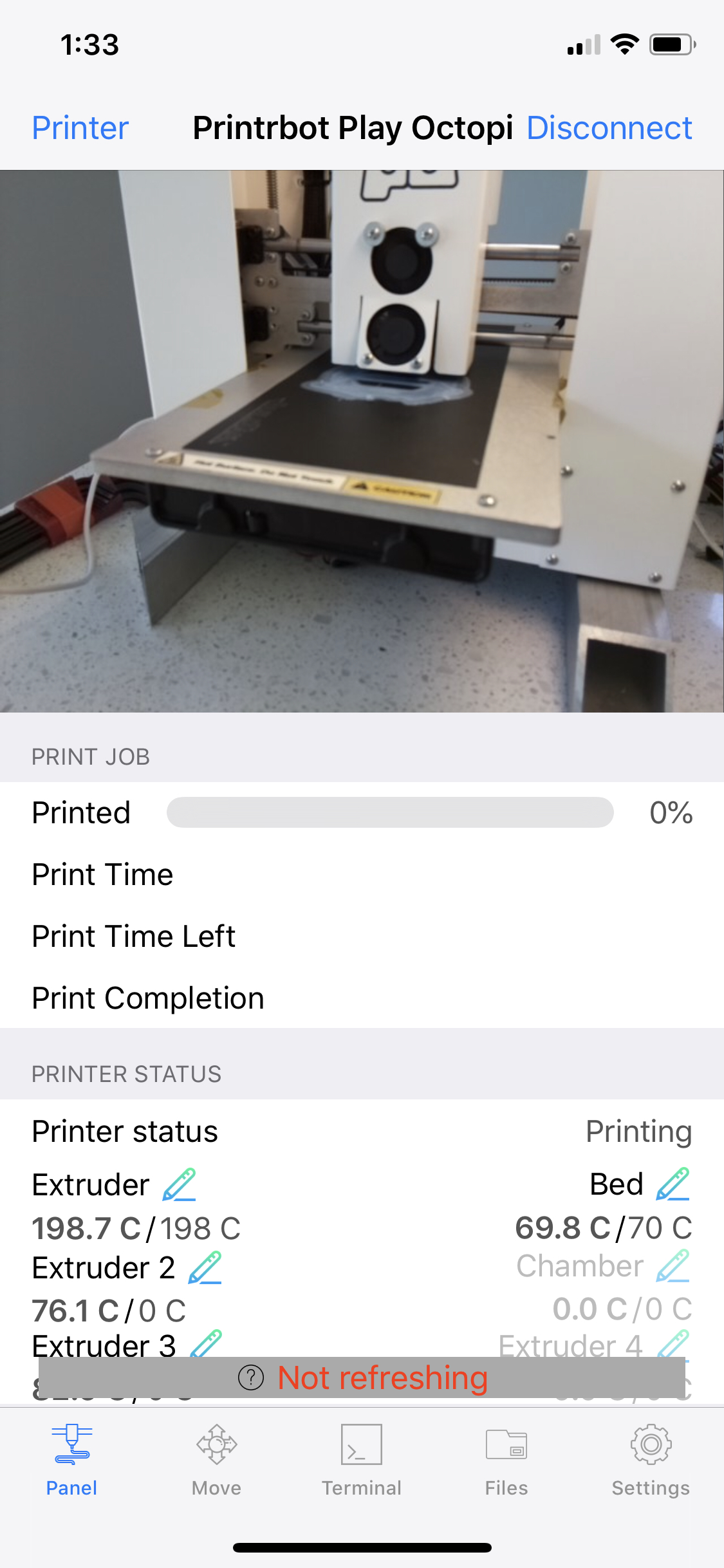
I have read the FAQ. Yup.
 SuperTango
SuperTango
All 15 comments
I can reproduce.
 kantlivelong
on 13 Apr 2020
kantlivelong
on 13 Apr 2020
Narrowed down to:
check_origin in tornado changes origin to lowercase but then pulls the host value from headers without making it lowercase.
kantlivelong
on 14 Apr 2020
Good finding @kantlivelong. That would do it!
 gdombiak
on 14 Apr 2020
gdombiak
on 14 Apr 2020
Meh... this is kinda ugly, especially since that is still present in current Tornado sources.
I'm unsure whether I should fix that by monkey patch all over or just within the vendored sockjs tornado binding.
 foosel
on 15 Apr 2020
foosel
on 15 Apr 2020
Without looking much into this and without knowing much .... how about:
- Make a PR in tornado with the proper fix
- Apply same fix in local tornado (that will eventually be mute once PR is processed)
I made big assumptions here so could be way wrong. :)
gdombiak
on 15 Apr 2020
For now I'll see if I can do 2. and if so and it looks stable write me a reminder to look into 1. once I no longer feel like I'm drowning.
The problem is that upgrading Tornado last time was a bit of a mess that had to be rolled back due to a memory leak that was discovered, and some further backwards compatibility issues that mean it's not just as easy as upping a dependency number.
foosel
on 16 Apr 2020
Drowning feeling is not good. Go for the simple solution that works and unblocks people. I like your approach and reminder to eventually update tornado version since it is a PIA. This issue should be raised with Tornado dev so they are aware of it.
gdombiak
on 16 Apr 2020
I've pushed the above commit. Would be great if someone who can easily reproduce the issue (I can't right now) could cross check that the change really solves the problem. Technically it should, but you never know.
Also, @kantlivelong, if you could throw a skeptical eye on my replacement of the check_origin function, that would be awesome ^^
foosel
on 16 Apr 2020
Gina, is the fix using the "Host" header in the comparison? Looking at the code (which I think will let the request work) it seems that it is comparing against the url used for the request. Reminding again: I'm not a Python dev so might be misreading the code.
gdombiak
on 16 Apr 2020
@gdombiak it's intentional as we found out that tornado's implementation of check_origin doesn't actually seem to be RFC6454 compliant.
kantlivelong
on 16 Apr 2020
Yep. As far as I understand full_url it uses the Host header and some other bits to restructure the full URL, including ports and scheme (which need to be compared).
foosel
on 16 Apr 2020
Oh, good to know. Didn't check the source for full_url. I thought it was similar to how Java works but it is not. :) Thanks for clarifying it.
Gaston
gdombiak
on 16 Apr 2020
I verified the fix worked on my machine. Thank you very much! 👍
SuperTango
on 16 Apr 2020
@foosel code looks good and my tests passed.
kantlivelong
on 16 Apr 2020
Perfect, that's ready for 1.4.1 then.
foosel
on 17 Apr 2020
Related issues
 Givemeyourgits
·
76Comments
foosel
·
58Comments
Givemeyourgits
·
76Comments
foosel
·
58Comments
 gege2b
·
64Comments
gege2b
·
64Comments
 devsfan1830
·
55Comments
devsfan1830
·
55Comments
 foulowl
·
58Comments
foulowl
·
58Comments
Most helpful comment
Narrowed down to:
https://github.com/OctoPrint/OctoPrint/blob/5596daf34668b90fa851ff2b3b0f1730413c7d69/src/octoprint/vendor/sockjs/tornado/websocket.py#L23
check_originin tornado changesoriginto lowercase but then pulls the host value from headers without making it lowercase.See https://github.com/tornadoweb/tornado/blob/8e9e75502ff910629663c4cdd7779d43ea2dd150/tornado/websocket.py#L358