- Version: 13.7.0
- Platform: macOS 10.15.5 Beta (19F83c)
What steps will reproduce the bug?
I have code that uses the Amazon Advertising API (ads API). I use the reports section of the ads api to download reports that come as .json.gz files. To handle this in Node.js, I had the following function to fetch the report (via a HTTP get request), and unzip the contents of the JSON.
import request from 'request-promise'; // https://github.com/request/request-promise
const downloadAdsReport = async (url) => new Promise((resolve, reject) => {
const buffer = [];
request.get(url).pipe(createGunzip())
.on('data', (data) => buffer.push(data.toString().replace(/\n/g, '')))
.on('end', () => resolve(JSON.parse(buffer.join(''))))
.on('error', (e) => reject(e));
});
When running this locally, I noticed that after about 60 reports (within the span of ~3 minutes), my wifi became disconnected and I was unable to connect to a new network until stopping the Node.js server I was running. After stopping the server, internet was immediately reconnected. I was able to produce this on 4 separate machines running macOS.
I then noticed similar issues on Linux on GCP (using the official node image as the base image. I had this chunk of code disabled for a while and re-enabled it to inspect usage metrics on GCP. What I noticed time and time again was that as soon as the code started running, I would see memory usage like the following:
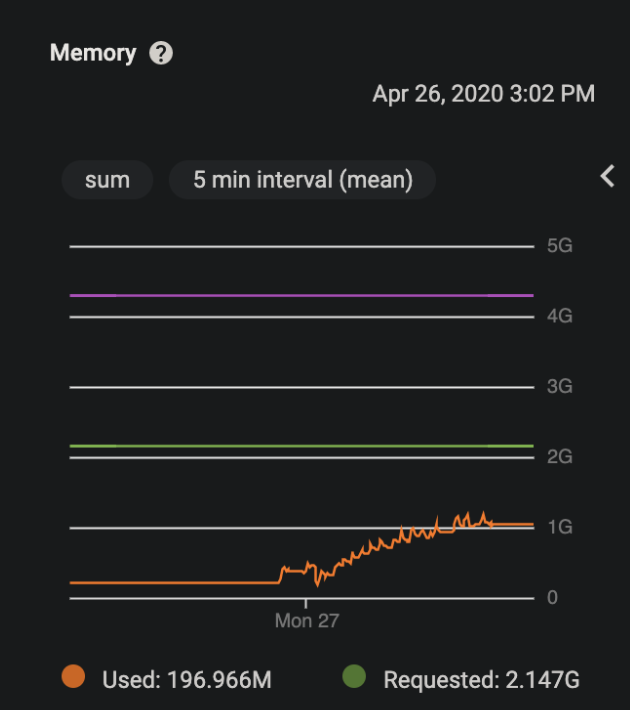
As you can see, the memory starts slowly leaking until finally it flatlines - at which point the server is unable to be pinged and is unable to make HTTP requests to other services (this would seem to mirror the behavior locally where the network disconnects).
As soon as I delete the container and a new one spawns, the memory graph goes back down and starts slowly climbing, and the process is repeated.
I tried to remedy this by substituting that one download function with the following code:
const downloadAdsReport = async (reportId, profileId, accessToken) => {
// Download the ads report in Python
const command = `python3 ${__dirname}/pyAds/download_report.py "${reportId}" "${profileId}" "${accessToken}"`;
const { stdout } = await util.promisify(exec)(command);
return JSON.parse(stdout);
};
This python code just downloads the report and unzips it in python, then prints the JSON output to stdout - which is then captured and parsed in Node.js.
After implementing this Python workaround, both locally and on GCP I am seeing 0 issues. So it seems that there is a major security vulnerability/bug with unzipping json.gz using gunzip.
I tried to reproduce this using a sample api that returns .json.gz files but I was unable to reproduce the same error. I have a sandbox that neatly reproduces the error, though it requires sharing my authentication credentials for the Amazon Ads API which I cannot do.
Additional information
I didn't quite follow the guidelines for formatting this issue because it was hard to place all the information into each section in a coherent way.
 jakeleventhal
jakeleventhal
All 11 comments
Nice Jake, thanks for the diligence.
 riceller
on 11 May 2020
riceller
on 11 May 2020
I have experienced this as well
 urirahimi
on 11 May 2020
urirahimi
on 11 May 2020
This is unrelated, but be aware that pushing data.toString() to the buffer array like that can cause problems with multi-byte characters (if data begins or ends on an incomplete multi-byte character). To solve this, use .setEncoding('utf8') on the readable stream and then data will be a string guaranteed to only contain complete characters.
 mscdex
on 11 May 2020
mscdex
on 11 May 2020
Have you tried node v14.x? Does it still happen when you use node core only (no third party modules)?
mscdex
on 11 May 2020
This is not really a security vulnerability as much as it is an unfortunate memory leak as a side effect of how you're using the streams api...
If we look at your example, there are several things I see here that are of concern:
import request from 'request-promise'; // https://github.com/request/request-promise
const downloadAdsReport = async (url) => new Promise((resolve, reject) => {
const buffer = [];
request.get(url).pipe(createGunzip())
.on('data', (data) => buffer.push(data.toString().replace(/\n/g, '')))
.on('end', () => resolve(JSON.parse(buffer.join(''))))
.on('error', (e) => reject(e));
});
First, and this is really secondary... your downloadAdsReport should not be defined as an async function. The fact that it returns a Promise is sufficient here.
Second, you are taking each chunk of data given to you by the Gunzip stream and converting it first to a string and then running a regex on it before finally joining those into a single larger string that is then JSON parsed. The result of this is that you end up with multiple copies of the data in memory at a time. Depending on how large these chunks are, that eats up a significant amount of memory that ends up not being freed until your Promise is garbage collected. Do that enough times and you'll very quickly run out of memory. If you're pulling down 600 reports in 3 minutes, it's no surprise why you're seeing the memory issues.
The challenge here is in how you've set up your data processing pipeline. For instance, rather than using the buffer to accumulate then join chunks, if the regular expression is definitely necessary, you should implement a stream.Transform that simply pushes those modified chunks along the pipeline to be accumulated in a final parse. Likewise, instead of using JSON.parse(), you could use a JSON parse that supports streamed input (such as JSONStream). These should yield a significantly improved memory profile.
Lastly, I just wanted to point out that, in the future, if you do believe that you have found a security vulnerability in Node.js, we have a Responsible Disclosure process outlined in our Security policy that asks that you please use our Hackerone program page to submit details. In the case that what you are reporting actually is a security vulnerability, this protects other users from being zero-day'd. Again, however, what you are reporting here does not look like a security issue in Node.js at all.
 jasnell
on 11 May 2020
jasnell
on 11 May 2020
Note taken regarding the streaming, though even if I change the download function to:
const downloadReport = (url) => new Promise((resolve, reject) => {
request.get(url).pipe(createGunzip())
// Do nothing since just testing
.on('data', (data) => data)
.on('end', () => resolve([]))
.on('error', (e) => reject(e));
});
I still see the same error.
Also, I meant to say 60* not 600. Updated the original description to clarify.
jakeleventhal
on 11 May 2020
The reason I thought of it as a security issue is because the issue is causing the machine to disconnect from the internet (both on my laptop and on GCP)
jakeleventhal
on 11 May 2020
I assume by request.get() you're using the request module? Can you put together a reproduction that does not use any external modules?
jasnell
on 11 May 2020
@jasnell I have my sandbox reproducing the error, though it has my developer credentials and I am unable to figure out how to recreate some other way. Do you have an email address I can send this to so that you can see for yourself?
jakeleventhal
on 17 May 2020
@jasnell I have sent the sandbox reproducing the error
jakeleventhal
on 21 May 2020
Thank you. I've got it here but haven't had a chance to take a look. Should be able to later today or tomorrow.
jasnell
on 21 May 2020
Related issues
 dfahlander
·
3Comments
dfahlander
·
3Comments
 fanjunzhi
·
3Comments
fanjunzhi
·
3Comments
 willnwhite
·
3Comments
willnwhite
·
3Comments
 Icemic
·
3Comments
Icemic
·
3Comments
 loretoparisi
·
3Comments
loretoparisi
·
3Comments
Most helpful comment
This is not really a security vulnerability as much as it is an unfortunate memory leak as a side effect of how you're using the streams api...
If we look at your example, there are several things I see here that are of concern:
First, and this is really secondary... your
downloadAdsReportshould not be defined as an async function. The fact that it returns aPromiseis sufficient here.Second, you are taking each chunk of data given to you by the Gunzip stream and converting it first to a string and then running a regex on it before finally joining those into a single larger string that is then JSON parsed. The result of this is that you end up with multiple copies of the data in memory at a time. Depending on how large these chunks are, that eats up a significant amount of memory that ends up not being freed until your Promise is garbage collected. Do that enough times and you'll very quickly run out of memory. If you're pulling down 600 reports in 3 minutes, it's no surprise why you're seeing the memory issues.
The challenge here is in how you've set up your data processing pipeline. For instance, rather than using the buffer to accumulate then join chunks, if the regular expression is definitely necessary, you should implement a
stream.Transformthat simply pushes those modified chunks along the pipeline to be accumulated in a final parse. Likewise, instead of usingJSON.parse(), you could use a JSON parse that supports streamed input (such as JSONStream). These should yield a significantly improved memory profile.Lastly, I just wanted to point out that, in the future, if you do believe that you have found a security vulnerability in Node.js, we have a Responsible Disclosure process outlined in our Security policy that asks that you please use our Hackerone program page to submit details. In the case that what you are reporting actually is a security vulnerability, this protects other users from being zero-day'd. Again, however, what you are reporting here does not look like a security issue in Node.js at all.