Node: vm module should expose V8::ScriptCompiler::CreateCodeCache
Previously, V8 can only create code cache as part of compiling a script. Now V8 can created code cache from an UnboundScript at arbitrary time after compilation.
The advantages are:
- Creating code cache can happen at a later time to unblock script execution.
- The code cache can now include code for functions that have already been compiled and executed, whereas previously we either have the option to only include code for top-level function, or eagerly compile the whole script for caching.
 hashseed
hashseed
All 19 comments
Note that the vm module already uses CreateCodeCache to emulate the deprecated kProduceCodeCache option.
hashseed
on 15 Apr 2018
I was going to do this but iirc got blocked by something, I can take a other look after my plane lands I remember now! we don't store the source text at the moment and I was going to ask people if they felt caching the source text was worth having this feature.
 devsnek
on 16 Apr 2018
devsnek
on 16 Apr 2018
Now that I think about this, we should not actually need to pass the string. I'll fix this.
hashseed
on 16 Apr 2018
Upstream change to no longer require the source to call v8::ScriptCompiler::CreateCodeCache is in flight.
I also prepared a patch to node/master based on that upstream change. You could float that patch for V8 6.6 and 6.7 if you don't want to wait until node/master upgrades to V8 6.8.
hashseed
on 16 Apr 2018
@hashseed i'm finally getting to this 🎉. is the failure of producing a code cache something that can be observed with a TryCatch or should i just make our own "creating code cache failed" error
devsnek
on 25 Apr 2018
We don't throw any exception here. If anything, we'd just return nullptr. Not sure what the best way to report that is.
hashseed
on 25 Apr 2018
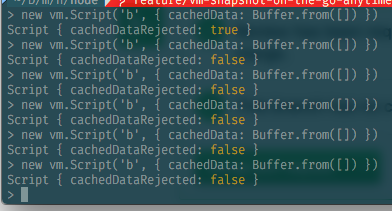
@hashseed i found this interesting behaviour while messing with the existing code (node 10.0.0 release):
devsnek
on 25 Apr 2018
@devsnek I observed the same behavior a while ago. My conjecture is that V8 caches the script corresponding to a specific string, and doesn’t bother checking the validity if it doesn’t need to compile it.
 TimothyGu
on 25 Apr 2018
TimothyGu
on 25 Apr 2018
i don't mind v8 caching but it doesn't reflect the c++ api and is causing me great confusion, specially since i never gave it a valid cache which i assume means its just creating a cache anyway?
devsnek
on 25 Apr 2018
Yeah that's because the first time the cache was rejected, V8 compiled it and cached the result in memory. Further compiles simply hit the in-memory cache and V8 does not bother with the provided code cache.
hashseed
on 25 Apr 2018
@hashseed so just to make sure i understand:
- user passes invalid code cache
- create code cache internally to help out user
- all further scripts created with that string use the internal cache that has been created
assuming the above is accurate, how can node tell v8 not to do that or is there a better way we can expose code caches? maybe vm.Script(source, { useCodeCache: true })?
devsnek
on 25 Apr 2018
- User passes invalid code cache data
- V8 first checks the source string against the in-memory cache, and gets a cache miss
- V8 attempts to use the provided code cache data it, fails, and sets the reject flag
- V8 compiles the source on its own instead, and puts it into the in-memory cache, keyed by the source string
- User passes the invalid code cache with the same source string again
- V8 first checks the source string against the in-memory cache, and gets a cache hit
- V8 ignores the code cache data, and does not set the reject flag
V8 is not helping out the user. It's just that V8 has two tiers of caches, and the code cache is just the second tier. Is it a big issue that V8 would not reject the same code cache twice?
hashseed
on 26 Apr 2018
@hashseed it just isn't providing a consistent interface. v8 doing fancy cache stuff is fine but it doesn't work with the API we have exposed.
devsnek
on 26 Apr 2018
Is it required that an API returns the same result every time? The flag is not called cacheIsValid. It's called cachedDataRejected. Imo it's fine to not reject something that you do not use. Besides, there are many reasons why cache data may be rejected, including V8 flags being changed at runtime.
Also, if V8 does not set the reject flag, it really doesn't break anything if the user provides the same invalid data the next time. I do see where you are coming from, but I don't think it's worth removing the in-memory caching tier (which arguably helps a lot) just to satisfy this requirement.
hashseed
on 26 Apr 2018
it's not the end of the world I suppose, just a difference in opinion (I prefer control over speed). I think for now since I changed the name to "codeCacheUsed" it's a bit less confusing anyway
devsnek
on 26 Apr 2018
(I prefer control over speed).
@hashseed Do you think there's any possible lose in speed with the proposed API changes in #20300?
 jdalton
on 26 Apr 2018
jdalton
on 26 Apr 2018
@jdalton
You mean the API change of cachedDataRejected vs codeCacheUsed? I don't think that makes a difference, it just has easier-to-understand semantics.
Or did you mean using the new createCodeCache() vs producing cache data right after compilation via produce_cached_data option? If you call createCodeCache() right after compiling, there is virtually no difference. If you call it later, and the code cache includes more bytecode, then yes, there is a bit of a trade-off. createCodeCache() gives you the power to make that trade-off.
hashseed
on 26 Apr 2018
Great! Thanks for the review!
jdalton
on 26 Apr 2018
Can this be closed since https://github.com/nodejs/node/pull/20300 was merged?
 guybedford
on 5 Dec 2018
guybedford
on 5 Dec 2018
Related issues
 willnwhite
·
3Comments
willnwhite
·
3Comments
 danielstaleiny
·
3Comments
danielstaleiny
·
3Comments
 danialkhansari
·
3Comments
danialkhansari
·
3Comments
 stevenvachon
·
3Comments
stevenvachon
·
3Comments
 srl295
·
3Comments
srl295
·
3Comments
Most helpful comment
Upstream change to no longer require the source to call
v8::ScriptCompiler::CreateCodeCacheis in flight.I also prepared a patch to node/master based on that upstream change. You could float that patch for V8 6.6 and 6.7 if you don't want to wait until node/master upgrades to V8 6.8.