Nim: `items` is 20%~30% slower than iteration via an index
The items iterator for sequence is very slow compared to iterating via index.
This is particularly visible on objects that are around 1 cache-line (64 byte) (probably because they flush the items that were prefetched during the iteration.
import math, strformat
import random, times
proc warmup*() =
# Warmup - make sure cpu is on max perf
echo "Running warmup to ensure CPU is on max perf if using dynamic frequency"
let start = cpuTime()
var foo = 123
for i in 0 ..< 300_000_000:
foo += i*i mod 456
foo = foo mod 789
# Compiler shouldn't optimize away the results as cpuTime rely on sideeffects
let stop = cpuTime()
echo &"Warmup: {stop - start:>4.4f} s, result {foo} (displayed to avoid compiler optimizing warmup away)\n"
warmup()
# --------------------------------------------------------
type
BigTypeSizeCacheLine = object
# A big ype that almost fill a cache line
x, y, z: float64
r: float64
u, v, w: float64
VariantKind = enum
kBig
VariantCacheLine = object
# A variant that takes the full cache line (due to padding)
case kind: VariantKind
of kBig:
b: BigTypeSizeCacheLine
let n = 1_000_000_0000
proc initBigTypes(): seq[VariantCacheLine] =
for i in 0 ..< 10000:
result.add VariantCacheLine(
kind: kBig,
b: BigTypeSizeCacheLine(
x: rand(1.0), y: rand(1.0), z: rand(1.0),
r: rand(1.0),
u: rand(1.0), v: rand(1.0), w: rand(1.0)
)
)
proc checkValue(big: BigTypeSizeCacheLine) =
# Fake work that cannot be optimized away (without a prover)
doAssert sqrt(
big.x * big.y * big.z *
big.r *
big.u * big.v * big.w
) <= 1.0
proc checkValue(variant: VariantCacheLine) =
case variant.kind
of kBig:
checkValue(variant.b)
proc with_iterator(): float64 =
let s = initBigTypes()
let t = cpuTime()
for big in s: # <-------------------
checkValue(big)
result = cpuTime() - t
proc with_index(): float64 =
let s = initBigTypes()
let t = cpuTime()
for i in 0 ..< s.len:
checkValue(s[i])
result = cpuTime() - t
proc main_cacheline() =
let it = with_iterator()
let idx = with_index()
echo "---------- 56 bytes (+1-byte tag + padding) ----------------"
echo "Iterator: ", round(it*1e3, 3), " ms"
echo "Index: ", round(idx*1e3, 3), " ms"
echo "Speedup: ", round((it - idx)/it * 100, 2), "%"
main_cacheline()
# -------------------------------------------------------------
type
CryptoPrimitive = object
# A 512-bit cryptographic primitive (for example a message signature)
hash: array[64, byte]
VariantCrypto = object
# A variant that distinguish between raw unvalidated data
# and crypto verified data
case validated: bool
of true:
sig: CryptoPrimitive
of false:
raw: array[64, byte]
proc initCrypto(): seq[VariantCrypto] =
for i in 0 ..< 1024:
result.add VariantCrypto(
validated: bool(i mod 2)
)
if result[^1].validated:
for j in 0..<64:
result[^1].sig.hash[j] = byte rand(255)
else:
for j in 0..<64:
result[^1].raw[j] = byte rand(255)
proc checkValue(big: VariantCrypto) =
# Fake work that cannot be optimized away (without a prover)
var sum = 0
if big.validated:
for i in 0 ..< 64:
sum += int(big.sig.hash[i])
else:
for i in 0 ..< 64:
sum += int(big.raw[i])
doAssert sum <= 255 * 64
proc with_iterator_crypto(): float64 =
let s = initCrypto()
let t = cpuTime()
for big in s: # <-------------------
checkValue(big)
result = cpuTime() - t
proc with_index_crypto(): float64 =
let s = initCrypto()
let t = cpuTime()
for i in 0 ..< s.len:
checkValue(s[i])
result = cpuTime() - t
proc main_crypto() =
let it = with_iterator_crypto()
let idx = with_index_crypto()
echo "---------- 64 bytes (+1-byte tag) ----------------"
echo "Iterator: ", round(it*1e3, 3), " ms"
echo "Index: ", round(idx*1e3, 3), " ms"
echo "Speedup: ", round((it - idx)/it * 100, 2), "%"
main_crypto()
Benchmark on my machine, repeated 5 times via a bash for loop
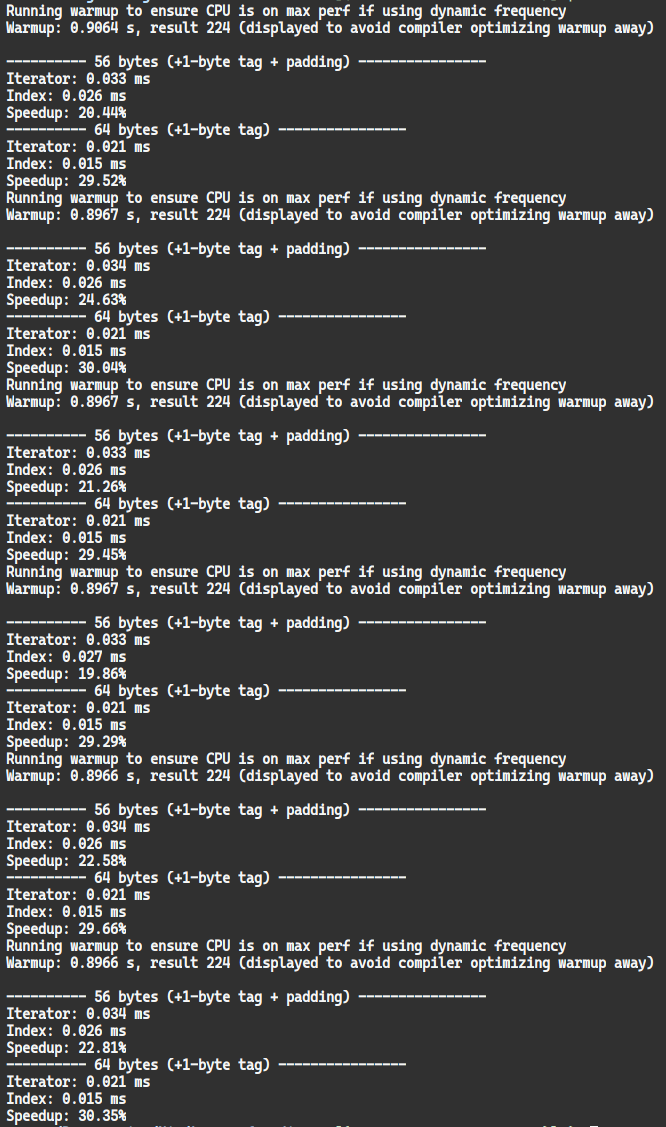
Looking into the generated C code (with -d:danger) this is due to an extra assignment:
N_LIB_PRIVATE N_NIMCALL(NF, with_iterator_crypto__7ulxTAN69bbjasPZaf5U4Dw_3)(void) {
NF result;
tySequence__iksy5MLCk8g4iIFr3fb9bPw* s;
NF t;
NF T5_;
result = (NF)0;
s = initCrypto__dx4Aan6xsXcnZXf3lg5Z5w();
t = cpuTime__9aodCrWXscOGeNVh2cpuZkw();
{
tyObject_VariantCrypto__K8mK9cICDx26SlWO8siUc9cw big;
NI i;
NI L;
NI T2_;
nimZeroMem((void*)(&big), sizeof(tyObject_VariantCrypto__K8mK9cICDx26SlWO8siUc9cw));
i = ((NI) 0);
T2_ = (s ? s->Sup.len : 0);
L = T2_;
{
while (1) {
if (!(i < L)) goto LA4;
big = s->data[i]; // <------------------
checkValue__Y9b2ugRAezbQJvLN60hHNmw((&big)); // <------------------
i += ((NI) 1);
} LA4: ;
}
}
T5_ = (NF)0;
T5_ = cpuTime__9aodCrWXscOGeNVh2cpuZkw();
result = ((NF)(T5_) - (NF)(t));
return result;
}
N_LIB_PRIVATE N_NIMCALL(NF, with_index_crypto__7ulxTAN69bbjasPZaf5U4Dw_4)(void) {
NF result;
tySequence__iksy5MLCk8g4iIFr3fb9bPw* s;
NF t;
NF T5_;
result = (NF)0;
s = initCrypto__dx4Aan6xsXcnZXf3lg5Z5w();
t = cpuTime__9aodCrWXscOGeNVh2cpuZkw();
{
NI i;
NI colontmp_;
NI T2_;
NI i_2;
i = (NI)0;
colontmp_ = (NI)0;
T2_ = (s ? s->Sup.len : 0);
colontmp_ = T2_;
i_2 = ((NI) 0);
{
while (1) {
if (!(i_2 < colontmp_)) goto LA4;
i = i_2;
checkValue__Y9b2ugRAezbQJvLN60hHNmw((&s->data[i])); // <------------------
i_2 += ((NI) 1);
} LA4: ;
}
}
T5_ = (NF)0;
T5_ = cpuTime__9aodCrWXscOGeNVh2cpuZkw();
result = ((NF)(T5_) - (NF)(t));
return result;
}
Recommendation
The iterator should return lent which is dependent on #14420
 mratsim
mratsim
All 7 comments
I have implemented lent T support for iterators. There is another bummer: lent T can't be captured by closures now. This breaks some packages.
I guess we also need https://github.com/nim-lang/RFCs/issues/178 to be implemented to make it happen.
 cooldome
on 21 May 2020
cooldome
on 21 May 2020
note; with var s = initBigTypes() and for big in mitems(s):, speed is same as with index
 timotheecour
on 22 May 2020
timotheecour
on 22 May 2020
note; with
var s = initBigTypes()andfor big in mitems(s):, speed is same as with index
This supports that lent will solve the issue, mitems will iterate with an address instead of a copy.
mratsim
on 22 May 2020
Fwiw I am using mitems for speed more and more often even if I don't need the mutability. Not good.
 Araq
on 22 May 2020
Araq
on 22 May 2020
Can compiler optimizing it automaticly? if developer not intend to mutate data they may not choose to using mitems
 bung87
on 22 May 2020
bung87
on 22 May 2020
@bung87 that's what lent annotations should help with :)
 Yardanico
on 22 May 2020
Yardanico
on 22 May 2020
see https://github.com/nim-lang/Nim/pull/14447 which implements that; only 1 test failing (zero-functional); help welcome (see https://github.com/nim-lang/Nim/pull/14447#issuecomment-634627267)
timotheecour
on 27 May 2020
Related issues
 awr1
·
3Comments
awr1
·
3Comments
 juancarlospaco
·
3Comments
juancarlospaco
·
3Comments
 liquid600pgm
·
3Comments
liquid600pgm
·
3Comments
 teroz
·
3Comments
teroz
·
3Comments
 alaviss
·
3Comments
alaviss
·
3Comments