Neovim: Scrolling with syntax on is super slow
This happens on master branch, with syntax on. See the screencast.
In both casts I just open a file and hold Ctrl-d
- with syntax on - https://asciinema.org/a/oYQbsKaZBFLF1ysXL08VT91jD
with syntax off - https://asciinema.org/a/14vwrWmclNFu2GbAfR0hWnSK8
nvim --version:
ngor:nvim/ (master✗) $ nvim --version [20:50:23]
NVIM v0.4.0-1134-g615fc6826
Build type: Release
LuaJIT 2.0.5
Compilation: /usr/bin/cc -O2 -DNDEBUG -DMIN_LOG_LEVEL=3 -Wall -Wextra -pedantic -Wno-unused-parameter -Wstrict-prototypes -std=gnu99 -Wshadow -Wconversion -Wmissing-prototypes -Wimplicit-fallthrough -Wvla -fstack-protector-strong -fdiagnostics-color=auto -Wno-array-bounds -DINCLUDE_GENERATED_DECLARATIONS -D_GNU_SOURCE -DNVIM_MSGPACK_HAS_FLOAT32 -DNVIM_UNIBI_HAS_VAR_FROM -I/home/ngor/dev/github.com/neovim/neovim/build/config -I/home/ngor/dev/github.com/neovim/neovim/src -I/home/ngor/dev/github.com/neovim/neovim/.deps/usr/include -I/usr/include -I/home/ngor/dev/github.com/neovim/neovim/build/src/nvim/auto -I/home/ngor/dev/github.com/neovim/neovim/build/include
Compiled by ngor@T800
Features: +acl +iconv +tui
See ":help feature-compile"
system vimrc file: "$VIM/sysinit.vim"
fall-back for $VIM: "/usr/local/share/nvim"
Run :checkhealth for more info
Vim (version: ) behaves differently?
nvim version0.3.7works fineOperating system/version:
Linux T800 5.1.12-arch1-1-ARCH #1 SMP PREEMPT Wed Jun 19 09:16:00 UTC 2019 x86_64 GNU/Linux- Terminal name/version: does not matter, happens on all termnals
Steps to reproduce using nvim -u NORC
nvim -u NORC ./big_file.c
# hold ctrl-d
Actual file format does not matter. Confirmed to happen on yaml, xml, c, rust, md files
Actual behaviour
Scrolling progressively slows down making neovim unresponsive
Expected behaviour
Fast scrolling with responsive neovim
 ngortheone
ngortheone
All 45 comments
can you bisect?
 justinmk
on 25 Jun 2019
justinmk
on 25 Jun 2019
I can try, never did it before. Does it mean find commit after which this started to happen?
ngortheone
on 25 Jun 2019
yes
justinmk
on 25 Jun 2019
I purged my ~/.local/share/nvim ~/.config/nvim and ~/.nvim
:scriiptnames
1: /usr/local/share/nvim/runtime/filetype.vim
2: /usr/local/share/nvim/runtime/ftplugin.vim
3: /usr/local/share/nvim/runtime/indent.vim
4: /usr/local/share/nvim/runtime/syntax/syntax.vim
5: /usr/local/share/nvim/runtime/syntax/synload.vim
6: /usr/local/share/nvim/runtime/syntax/syncolor.vim
7: /usr/local/share/nvim/runtime/plugin/gzip.vim
8: /usr/local/share/nvim/runtime/plugin/health.vim
9: /usr/local/share/nvim/runtime/plugin/man.vim
10: /usr/local/share/nvim/runtime/plugin/matchit.vim
11: /usr/local/share/nvim/runtime/plugin/matchparen.vim
12: /usr/local/share/nvim/runtime/plugin/netrwPlugin.vim
13: /usr/local/share/nvim/runtime/plugin/rplugin.vim
14: /usr/local/share/nvim/runtime/plugin/shada.vim
15: /usr/local/share/nvim/runtime/plugin/spellfile.vim
16: /usr/local/share/nvim/runtime/plugin/tarPlugin.vim
17: /usr/local/share/nvim/runtime/plugin/tohtml.vim
18: /usr/local/share/nvim/runtime/plugin/tutor.vim
19: /usr/local/share/nvim/runtime/plugin/zipPlugin.vim
20: /usr/local/share/nvim/runtime/autoload/dist/ft.vim
21: /usr/local/share/nvim/runtime/ftplugin/c.vim
22: /usr/local/share/nvim/runtime/indent/c.vim
23: /usr/local/share/nvim/runtime/syntax/c.vim
Bisecting progress - removal of jemalloc did not affect this.
commit c2343180d74f547d99abcc3c4979a9ebb047af17 (HEAD)
Author: James McCoy <[email protected]>
Date: Sat Jan 19 18:09:52 2019 -0500
Remove support for using jemalloc instead of the system allocator
nvim version 0.3.7 works fine
If 0.3.7 works fine, 0.3.7 is bisect good.
You can bisect the commits.
 Shougo
on 25 Jun 2019
Shougo
on 25 Jun 2019
big_file.c
The big file means eval.c in neovim source code?
I will test it.
Shougo
on 25 Jun 2019
any big file with syntax highlighting on. I am bisecting master branch. Soon I will find out the commit
ngortheone
on 25 Jun 2019
Bisected.
Caused by https://github.com/neovim/neovim/commit/07a182c6b57e13e2563aef667131b976db8711cc
07a182c6b57e13e2563aef667131b976db8711cc is the first bad commit
commit 07a182c6b57e13e2563aef667131b976db8711cc
Author: Jan Edmund Lazo <[email protected]>
Date: Sun Apr 14 22:34:58 2019 -0400
vim-patch:8.0.0647: syntax highlighting can make cause a freeze
Problem: Syntax highlighting can make cause a freeze.
Solution: Apply 'redrawtime' to syntax highlighting, per window.
https://github.com/vim/vim/commit/06f1ed2f78c5c03af95054fc3a8665df39dec362
runtime/doc/options.txt | 10 +++++++---
src/nvim/buffer_defs.h | 1 +
src/nvim/normal.c | 3 +++
src/nvim/regexp.c | 10 ++++------
src/nvim/screen.c | 27 ++++++++++++++++++---------
src/nvim/syntax.c | 20 +++++++++++++++-----
src/nvim/testdir/test_syntax.vim | 34 ++++++++++++++++++++++++++++++++++
7 files changed, 82 insertions(+), 23 deletions(-)
If so, you can configure redrawtime to fix the problem.
Shougo
on 25 Jun 2019
Yes I will try that. But as a user I expected a normal behavior by default. I suspect there is something wrong with the way default value for redrawtime is set.
ngortheone
on 25 Jun 2019
I don't reproduce the problem on Alacritty + -u NORC --noplugin on neovim master.
Shougo
on 25 Jun 2019
NVIM v0.4.0-1134-g615fc6826
It is not the latest version.
My version is:
NVIM v0.4.0-7050-g8cd87af8d
Shougo
on 25 Jun 2019
I built of todays master. Setting redrawtime to a higher value does not help. To a lower - just turns off the syntax.
ngortheone
on 25 Jun 2019
Alacritty + -u NORC --noplugin
Same, but I can reproduce. @justinmk also can't reproduce.
ngortheone
on 25 Jun 2019
I have rebuild neovim.
NVIM v0.4.0-7060-g615fc6826
Why it is 1134?
Shougo
on 25 Jun 2019
Please test Vim8 also.
Shougo
on 25 Jun 2019
Related issue is reported on Vim's issue.
https://github.com/vim/vim/issues/2712
Shougo
on 25 Jun 2019
https://github.com/vim/vim/commit/f3d769a585040ac47f7054057758809024ef6377 is bugfix of 8.0.0647.
It seems already merged.
Shougo
on 25 Jun 2019
Shougo
on 25 Jun 2019
Tested on vim - works fine
VIM - Vi IMproved 8.1 (2018 May 18, compiled Jun 5 2019 14:31:35)
Included patches: 1-1467
Compiled by Arch Linux
Couldn't reproduce on vim. Tried both latest master and the patch that causes neovim to have problems https://github.com/vim/vim/commit/06f1ed2f78c5c03af95054fc3a8665df39dec362
ngortheone
on 25 Jun 2019
I also was not able to reproduce this issue in docker ubuntu:latest image.
This is something related to system libraries
ngortheone
on 25 Jun 2019
@ngortheone could be that high-resolution time is costly (more than usual) for some reason. I've seen this before (years ago). Can you try this patch:
diff --git a/src/nvim/os/time.c b/src/nvim/os/time.c
index 31ef1a0cd695..8a49d3ef1dc0 100644
--- a/src/nvim/os/time.c
+++ b/src/nvim/os/time.c
@@ -35,7 +35,7 @@ void time_init(void)
/// to clock drift. The value is expressed in nanoseconds.
uint64_t os_hrtime(void)
{
- return uv_hrtime();
+ return 42;
}
-
/// Sleeps for `ms` milliseconds.
I had a kernel upgrade and a bunch of other things installed, but not rebooted
As soon as I rebooted - everything started working fine
It looks like Arch just replaces some system things from under the running system, and until you reboot wired things can happen. Another clue was that nobody else was able to reproduce the problem.
ngortheone
on 26 Jun 2019
Logging my findings in case someone else has this problem:
It appears to be kernel related. The issue happens regularly on the latest kernel (I am on Archlinux, latest at the moment of writing this post is is 5.1-something).
Slowness during scrolling in nvim also shows as 100% CPU load in htop. (And most of is colored red - Kernel related activity)
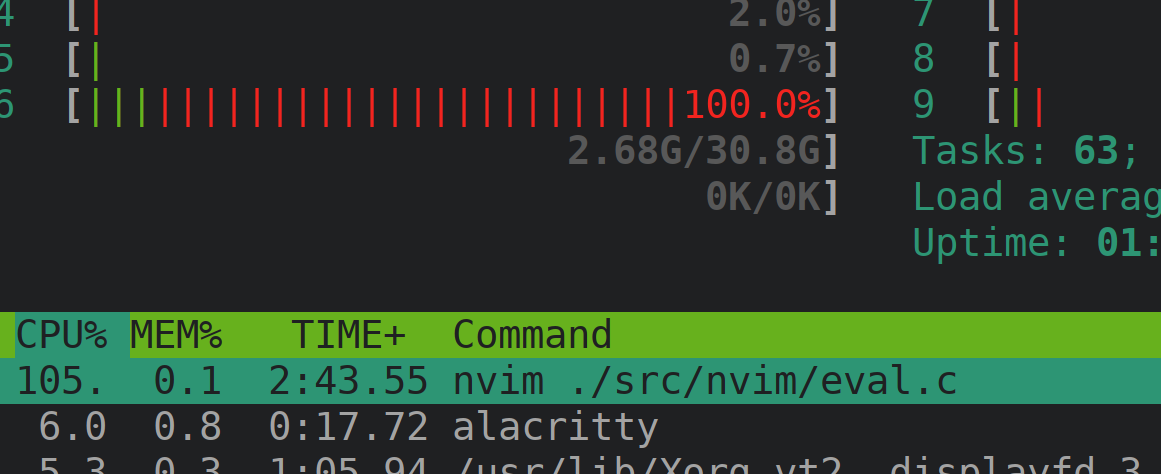
Rebooting the laptop helps for a while, scrolling is fast, CPU load is normal. But then the problem comes back. I was unable to determine what exactly triggers it.
The patch suggested by @justinmk definitely helps to make it batter, but lags do not go away completely. (I suspect there are other places in a codebase where current time is queried)
The patch I bisected earlier (07a182c) helped to bring this problem to the surface, but I now I am convinced that this is not a neovim problem. Most likely it is some sort of regression in latest kernel
I switched to LTS kernel (4.19) and I can't reproduce this problem anymore.
Thanks to @Shougo and @justinmk who helped me to debug this
ngortheone
on 27 Jun 2019
In any case I think we should switch the profile module to use uv_gettimeofday instead of uv_hrtime, as vim does. There is not much reason to have nanosecond-precision in the profile.c module AFAIK. cc @aktau
Update: It turns out that this is system-dependent because of this libuv code: https://github.com/libuv/libuv/blob/0cdb4a5b4b706d0e09413d9270da28f9a88dc083/src/unix/linux-core.c#L442-L462
/* Prefer CLOCK_MONOTONIC_COARSE if available but only when it has
* millisecond granularity or better. CLOCK_MONOTONIC_COARSE is
* serviced entirely from the vDSO, whereas CLOCK_MONOTONIC may
* decide to make a costly system call.
*/
Micro-benchmark on my system shows negligible differences:
INFO 2019-06-27T23:58:35.471 19361 main:581: 999999 trials of gettimeofday: 3.191380
INFO 2019-06-27T23:58:38.953 19361 main:587: 999999 trials of os_hrtime: 3.481799
INFO 2019-06-27T23:58:41.974 19361 main:593: 999999 trials of os_utime: 3.020392
@ngortheone next time the behavior happens can you build latest master (with https://github.com/neovim/neovim/pull/10356) and compare the behavior?
justinmk
on 29 Jun 2019
@justinmk Thanks. When I rolled my system back to LTS kernel the issue went away.
I will try this soon on latest kernel.
ngortheone
on 1 Jul 2019
It's a bit puzzling. As far as I recall, the vDSO function (see here, it's been in linux since ~forever) just checks the TSC (Time Stamp Counter) register and applies some basic math to it. It probably shouldn't even register as kernel-space time since the vDSO was AFAIK made to avoid the expensive context-switch to kernel space.
So, it seems like something is causing @ngortheone's newer kernel to switch to using the non-vDSO codepath (fallback to libc impl, which does a syscall). If called a lot, this might be slow. At first sight, it sounds like a kernel bug.
Let's look at the relevant libuv implementations:
typedef enum {
UV_CLOCK_PRECISE = 0, /* Use the highest resolution clock available. */
UV_CLOCK_FAST = 1 /* Use the fastest clock with <= 1ms granularity. */
} uv_clocktype_t;
uint64_t uv_hrtime(void) {
return uv__hrtime(UV_CLOCK_PRECISE);
}
uint64_t uv__hrtime(uv_clocktype_t type) {
static clock_t fast_clock_id = -1;
struct timespec t;
clock_t clock_id;
/* Prefer CLOCK_MONOTONIC_COARSE if available but only when it has
* millisecond granularity or better. CLOCK_MONOTONIC_COARSE is
* serviced entirely from the vDSO, whereas CLOCK_MONOTONIC may
* decide to make a costly system call.
*/
/* TODO(bnoordhuis) Use CLOCK_MONOTONIC_COARSE for UV_CLOCK_PRECISE
* when it has microsecond granularity or better (unlikely).
*/
if (type == UV_CLOCK_FAST && fast_clock_id == -1) {
if (clock_getres(CLOCK_MONOTONIC_COARSE, &t) == 0 &&
t.tv_nsec <= 1 * 1000 * 1000) {
fast_clock_id = CLOCK_MONOTONIC_COARSE;
} else {
fast_clock_id = CLOCK_MONOTONIC;
}
}
clock_id = CLOCK_MONOTONIC;
if (type == UV_CLOCK_FAST)
clock_id = fast_clock_id;
if (clock_gettime(clock_id, &t))
return 0; /* Not really possible. */
return t.tv_sec * (uint64_t) 1e9 + t.tv_nsec;
}
Ergo, we can conclude that libuv will return the result of clock_gettime(CLOCK_MONOTONIC, ...) when you invoke uv_hrtime.
Now for the vDSOs (extracted from Linux master HEAD, https://github.com/torvalds/linux/blob/master/arch/x86/entry/vdso/vclock_gettime.c at the time of writing):
#define VGTOD_BASES (CLOCK_TAI + 1)
#define VGTOD_HRES (BIT(CLOCK_REALTIME) | BIT(CLOCK_MONOTONIC) | BIT(CLOCK_TAI))
#define VGTOD_COARSE (BIT(CLOCK_REALTIME_COARSE) | BIT(CLOCK_MONOTONIC_COARSE))
notrace int __vdso_clock_gettime(clockid_t clock, struct timespec *ts)
{
unsigned int msk;
/* Sort out negative (CPU/FD) and invalid clocks */
if (unlikely((unsigned int) clock >= MAX_CLOCKS))
return vdso_fallback_gettime(clock, ts);
/*
* Convert the clockid to a bitmask and use it to check which
* clocks are handled in the VDSO directly.
*/
msk = 1U << clock;
if (likely(msk & VGTOD_HRES)) {
return do_hres(clock, ts);
} else if (msk & VGTOD_COARSE) {
do_coarse(clock, ts);
return 0;
}
return vdso_fallback_gettime(clock, ts);
}
notrace int __vdso_gettimeofday(struct timeval *tv, struct timezone *tz)
{
if (likely(tv != NULL)) {
struct timespec *ts = (struct timespec *) tv;
do_hres(CLOCK_REALTIME, ts);
tv->tv_usec /= 1000;
}
if (unlikely(tz != NULL)) {
tz->tz_minuteswest = gtod->tz_minuteswest;
tz->tz_dsttime = gtod->tz_dsttime;
}
return 0;
}
Which shows that for vDSO at least both clock_gettime(CLOCK_MONOTONIC) and gettimeofday() both use the same underlying private vDSO function (do_hres):
clock_gettime(CLOCK_MONOTONIC)->do_hres(CLOCK_MONOTONIC)gettimeofday()->do_hres(CLOCK_REALTIME)
What does that do?
notrace static int do_hres(clockid_t clk, struct timespec *ts)
{
struct vgtod_ts *base = >od->basetime[clk];
u64 cycles, last, sec, ns;
unsigned int seq;
do {
seq = gtod_read_begin(gtod);
cycles = vgetcyc(gtod->vclock_mode); // NOTE(aktau): This is where the magic (reading of TSC register) happens.
ns = base->nsec;
last = gtod->cycle_last;
if (unlikely((s64)cycles < 0))
return vdso_fallback_gettime(clk, ts); // NOTE(aktau): hmm....
if (cycles > last)
ns += (cycles - last) * gtod->mult;
ns >>= gtod->shift;
sec = base->sec;
} while (unlikely(gtod_read_retry(gtod, seq)));
/*
* Do this outside the loop: a race inside the loop could result
* in __iter_div_u64_rem() being extremely slow.
*/
ts->tv_sec = sec + __iter_div_u64_rem(ns, NSEC_PER_SEC, &ns);
ts->tv_nsec = ns;
return 0;
}
notrace static inline u64 vgetcyc(int mode) {
if (mode == VCLOCK_TSC)
return (u64)rdtsc_ordered();
return U64_MAX; // NOTE(aktau): This would trigger the fallback syscall.
}
Whether or not to use the fast approach (read the TSC register) is used depends on gtod->vclock_mode (see the vgetcyc() call). This does not depend (AFAIK) on whether CLOCK_REALTIME or CLOCK_MONOTONIC is used.
My theory is that somehow @ngortheone's system sets gtod->vclock_mode to something that's NOT VLOCK_TSC at some point. Which would cause an extreme rise in the number of syscalls if some program (not named to protect the innocent) would call clock_gettime(2) or gettimeofday(2) a lot. (I'd check dmesg when this slowness happens, likely the kernel logs something when it decides the TSC is not a valid approach anymore.)
Based on that theory, I don't think the nvim workaround for this (switching to gettimeofday) will help much.
Similarly, if true, this problem isn't solved and there are only two ways to do so:
- Call the time functions less often.
- Fix the kernel (and tell people not to use a broken kernel range)
My money is on a kernel regression.
References:
- An example program which shows the difference in speed between vDSO and non-vDSO (for
gettimeofday(2): http://man7.org/tlpi/code/online/dist/vdso/gettimeofday.c.html - The kernel sources
 aktau
on 2 Jul 2019
aktau
on 2 Jul 2019
@aktau thank you! I assumed it was a kernel bug or system quirk, but...
Based on that theory, I don't think the nvim workaround for this (switching to
gettimeofday) will help much.
Vim (which has the same patch) did not have the issue when @ngortheone checked it on the same system. Admittedly we didn't trace both cases, but it's less work to just wait-and-see: if it happens again, then we know the problem wasn't solved. (Update: reverted in https://github.com/neovim/neovim/pull/10488)
for vDSO at least ...
The problem is:
- when vDSO is not in effect.
- I don't know what circumstances lead to that (though curious). Is it safe to assume it's always working (except for kernel regressions)?
- performance of
uv_hrtimeon other systems (BSD/Windows/etc.).
I didn't/can't thoroughly measure those cases. But if the problem can be solved at negligible cost, we should just pay the negligible cost, right?
IMO the cost is negligible because:
- The change is easily revertible (if wait-and-see fails).
- It's ok if VimL/syntax/
--startuptimeprofiling is "sloppy" as long as it's not "broken".
It's quite possible that I'm wrong, counterarguments welcome :)
justinmk
on 2 Jul 2019
Vim (which has the same patch) did not have the issue when @ngortheone checked it on the same system. Admittedly we didn't trace both cases, but it's less work to just wait-and-see: if it happens again, then we know the problem wasn't solved.
Yes, I'm curious too. If the problem can be reproduced on a slow system with nvim but not with vim, I'd certainly check whether one is making many more timing-related calls than the other.
The problem is:
- when vDSO is not in effect.
- I don't know what circumstances lead to that (though curious). Is it reasonable to assume it's always working (except for kernel regressions)?
I've been thinking about this. Given the minor implementation differences between clock_gettime and gettimeofday in the vDSO lib, I'm assuming that the in-kernel implementations also have similar performance.
- performance of uv_hrtime on other systems (BSD/Windows/etc.).
Certainly, that's something I haven't checked out for all systems. However, nvim has been using uv_hrtime for a while now without complaints (it'd be silly if the function to get a high-resolution time were itself so slow that it would impact your profiling). On Windows (if I recall), it uses QueryPerformanceCounter, which is fast. I also remember making a PR with an optimization for the macOS version (which uses mach "syscalls"), and it was also in the nanosecond range.
I didn't/can't thoroughly measure those cases. But if the problem can be solved at negligible cost, we should just pay the negligible cost, right?
Yes. If the problem can be fixed in this way. I'm curious whether your change does indeed fix it (reverse bisection).
aktau
on 2 Jul 2019
@ngortheone have you been able to:
- Test the Neovim patch on the new kernel where you first experienced the issue?
- Check your dmesg log for time (TSC) related messages when the issue occurs?
- Give us an strace -c output from an nvim with the issue and a vim8 that doesn't have the issue?
It would help a lot for us to decide whether we should roll back and try something different.
aktau
on 6 Jul 2019
Not sure if the cause is related, as the reproduction steps are also different, but I'm also experiencing scrolling regression with syntax enabled, in 0.4.0 vs 0.3.8 on macOS.
nvim --version:
NVIM v0.4.0-1234-g1b99aa8c5
Build type: Release
LuaJIT 2.0.5
Compilation: /Applications/Xcode-10.1.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/clang -U_FORTIFY_SOURCE -D_FORTIFY_SOURCE=1 -O2 -DNDEBUG -DMIN_LOG_LEVEL=3 -Wall -Wextra -pedantic -Wno-unused-parameter -Wstrict-prototypes -std=gnu99 -Wshadow -Wconversion -Wmissing-prototypes -Wimplicit-fallthrough -Wvla -fstack-protector-strong -fdiagnostics-color=auto -DINCLUDE_GENERATED_DECLARATIONS -D_GNU_SOURCE
-DNVIM_MSGPACK_HAS_FLOAT32 -DNVIM_UNIBI_HAS_VAR_FROM -I/Users/travis/build/neovim/bot-ci/build/neovim/build/config -I/Users/travis/build/neovim/bot-ci/build/neovim/src -I/Users/travis/build/neovim/bot-ci/build/neovim/.deps/usr/include -I/usr/local/opt/gettext/include -I/usr/include -I/Users/travis/build/neovim/bot-ci/build/neovim/build/src/nvim/auto -I/Users/travis/build/neovim/bot-ci/build/neovim/build/include
Compiled by [email protected]
Features: +acl +iconv +tui
See ":help feature-compile"
system vimrc file: "$VIM/sysinit.vim"
fall-back for $VIM: "/share/nvim"
Run :checkhealth for more info
- Vim (version: ) behaves differently?
_nvim version0.3.8works fine_ - Operating system/version:
macOS Catalina 10.15 Beta (19A501i) (Beta 3) - Terminal name/version: doesn't seem to be relevant, I can reproduce it on my iTerm2 setup as well as stock
Terminal.app
Steps to reproduce using nvim -u NORC
I'm testing on a neovim config file with ~940 lines, using a measure command to precisely compare timing.
nvim -u NORC init.vim
:let g:profstart=reltime() | for i in range(1,900) | exec "normal \<C-E>" | redraw | endfor | echo reltimestr(reltime(g:profstart)) . ' seconds'
Example output for nvim 0.4.0:
1.150760 seconds
Example output for nvim 0.3.8:
0.495297 seconds
there's also some difference with homebred-installed vim 8.1.1600 (when using -u DEFAULTS), e.g. 0.387572 seconds
 dmcyk
on 7 Jul 2019
dmcyk
on 7 Jul 2019
@dmcyk
- try the patch given in
https://github.com/neovim/neovim/issues/10328#issuecomment-505648021 - also revert 50a4b32
(This will break reltime() I think. So you will need to make a human judgment.) If it is still slow, then your issue is off topic .
justinmk
on 7 Jul 2019
Scrolling seems marginally faster with the patch, maybe even no difference.
Visibly slower than 0.3.8, regardless.
Those results come from tests on macOS Catalina though, now I tested also on another machine running Mojave (because I couldn't compile neovim on Catalina) and difference there is very marginal.
Also it seems to be quite faster on Mojave - ~0.24 vs ~0.28 sec - 0.3.8 vs 0.4.0.
Maybe it's just beta issues, I will check again once Catalina is actually released.
dmcyk
on 7 Jul 2019
@dm1try could be runtime/syntax stuff. Open an issue with full details including steps to reproduce.
justinmk
on 8 Jul 2019
Something I came across today: someone analyzed the different ways of fetching time and compared them (Linux and macOS): https://stackoverflow.com/a/12480485. I found it interesting that macOS now implements clock_gettime(3) (a POSIX API) too.
aktau
on 8 Jul 2019
@aktau @justinmk
Sorry for late reply.
The problem still happening on today's master build
:version
NVIM v0.4.0-1256-g564d415d2
uname -a
Linux T800 5.1.16-arch1-1-ARCH #1 SMP PREEMPT Wed Jul 3 20:23:07 UTC 2019 x86_64 GNU/Linux
This is what I see in dmesg on latest kernel.
dmesg | grep TSC
[ 0.002665] tsc: Detected 2592.000 MHz TSC
[ 0.594826] TSC deadline timer enabled
[ 163.591720] tsc: Marking TSC unstable due to clocksource watchdog
[ 163.591747] TSC found unstable after boot, most likely due to broken BIOS. Use 'tsc=unstable'.
Also found somewhat relevant bug description https://bugs.launchpad.net/ubuntu/+source/linux-signed-hwe/+bug/1821441
Will check if I see the same on lts kernel
EDIT:
Not happening on LTS kernel.
~ dmesg | grep TSC
[ 0.002600] tsc: Detected 2592.000 MHz TSC
[ 0.609907] TSC deadline timer enabled
~ uname -a
Linux T800 4.19.57-1-lts #1 SMP Wed Jul 3 16:05:59 CEST 2019 x86_64 GNU/Linux
I also notice slowness in firefox and other apps. So I am convinced now that this is not a neovim problem.
ngortheone
on 10 Jul 2019
cat /proc/cpuinfo | grep "model name" | head -n1
model name : Intel(R) Core(TM) i7-8850H CPU @ 2.60GHz
Also this looks very relevant
https://bugzilla.kernel.org/show_bug.cgi?id=203183
ngortheone
on 10 Jul 2019
@ngortheone thanks for the tests! This basically confirms all the suspicions I had.
Now there is only one remaining question: why on earth does regular Vim (8) not get slow even if it has (ostensibly) the same patch? @ngortheone: can you confirm that Vim 8 is still fine after the TSC was found to be unstable?
If Vim 8 is still fine, can you please get us comparative strace traces?
$ strace -o nvim.strace -c nvim
$ strace -o vim.strace -c vim
It's ~important to perform similar actions in both runs, as that will allow us to compare relative counts better.
My current hypothesis is that for some reason Vim 8 is calling gettimeofday much less often than Neovim.
@justinmk what about reverting the clock_gettime() -> gettimeofday() patch, as it doesn't help and only serves to make time less granular and subject to time resets? For profiling and duration timing, we want monotonic timing, not gettimeofday.
aktau
on 11 Jul 2019
(Also, for architectures or systems that don't have a TSC-alike and need to use a syscall, (neo)vim with this timer patch will necessarily be really slow at scrolling. It may be worthwhile in general to invest some effort into calling these functions less often.)
aktau
on 11 Jul 2019
I am seeing something similar going on with NVIM 0.4.2,
[ 70.652589] tsc: Marking TSC unstable due to clocksource watchdog
[ 70.652630] TSC found unstable after boot, most likely due to broken BIOS. Use 'tsc=unstable'.
 SamSaffron
on 19 Sep 2019
SamSaffron
on 19 Sep 2019
Scrolling for my on my slow Apple Macbook is FAR slower with Nvim 0.4.2 compared with 0.3.8.
With a Ruby Rspec file I get smooth scrolling with Neovim 0.3.8 and Vim 8.1.X; CPU usage at around 20%, all good.
With Neovim 0.4.2 I get the the CPU up to 100% (just by scrolling), and it is very janky and stuttery.
Something is definitely amiss with regards to scrolling + syntax highlighting for the 0.4.X series on Mac.
Should I open a new issue for that scroll performance regression on Mac?
 bluz71
on 25 Sep 2019
bluz71
on 25 Sep 2019
@bluz71
A new / separate issue would be good - but needs more info.
Might be / is likely related to runtime updates.
Can you test with a recent Vim also?
And/or git-bisect this? (check updates for rspec files first maybe)
Please provide this is a new issue then.
Apart from that:
While the information here is certainly useful for debugging, we should use new / separate issues for new issues.
 blueyed
on 25 Sep 2019
blueyed
on 25 Sep 2019
Related issues
 phmarek
·
50Comments
phmarek
·
50Comments
 ghost
·
48Comments
ghost
·
48Comments
 dvidsilva
·
63Comments
aktau
·
103Comments
dvidsilva
·
63Comments
aktau
·
103Comments
 tjdevries
·
47Comments
tjdevries
·
47Comments