Models: EfficientDet Training loss=nan
I'm training my custom model with EfficientDet D0 but after 700 steps I am getting loss as nan value. Is there someone who has the same problem?
TensorFlow 2.3.0 with GTX 1060 10.1 CUDA
Here my training overview:
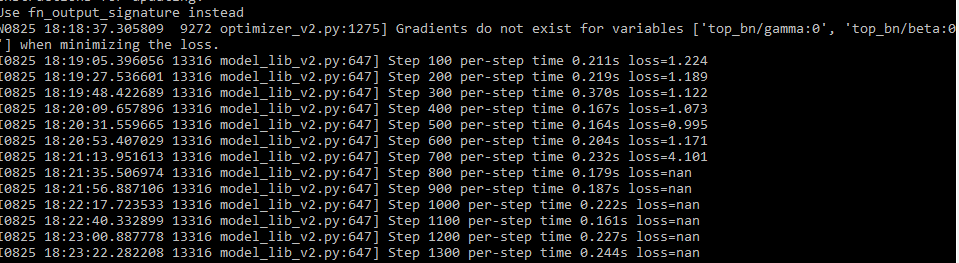
I am using default config file parameters. Image size 512x512 and batch_size 1
 etatbak
etatbak
All 13 comments
I have the same problem with EfficientDet D4.
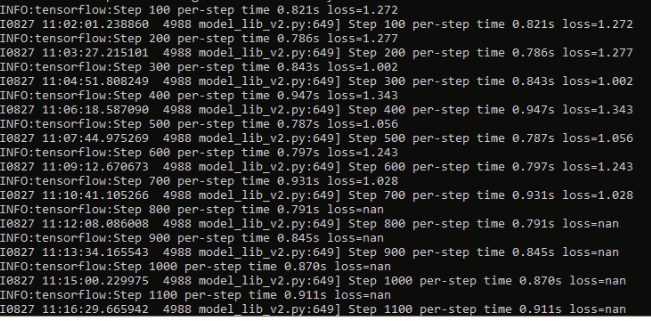
 TolgaBkm
on 27 Aug 2020
TolgaBkm
on 27 Aug 2020
One of my viewers had the same problem. Changing the batch size from 1 to 4 solved the problem
 TannerGilbert
on 27 Aug 2020
TannerGilbert
on 27 Aug 2020
I also have the same problem. I've tried d1 and d2.

Also, it seems that network is not learning at all.. I have a custom .tfrecord dataset. The config file is attached.
 koolvn
on 28 Aug 2020
koolvn
on 28 Aug 2020
I have also tried to increase the batch size to 4. However, I still got loss=NaN around 50k steps of training.
TolgaBkm
on 28 Aug 2020
Try to reduce the learning rate, this should solve the problem. The models are usually trained with a large batchsize, eg.: 128 for efficient_det d3, when adjusting this parameter (eg: 128 -> 4) makes sure to also change the learning rate, since your gradients are a lot noisier. I would divide the learning rate by the same factor.
 geeheim
on 28 Aug 2020
geeheim
on 28 Aug 2020
Try to reduce the learning rate, this should solve the problem. The models are usually trained with a large batchsize, eg.: 128 for efficient_det d3, when adjusting this parameter (eg: 128 -> 4) makes sure to also change the learning rate, since your gradients are a lot noisier. I would divide the learning rate by the same factor.
@greeheim Thank you for an advice! I've never thought that learning rate could cause a problem like that.
Now I'm training EfficientDet D1 on GTX 1080 Ti with batch size = 6 and LR = 0.003 with warmup. It looks promising.
Here's my pipeline config in case anyone ever needs it.
koolvn
on 28 Aug 2020
Try to reduce the learning rate, this should solve the problem. The models are usually trained with a large batchsize, eg.: 128 for efficient_det d3, when adjusting this parameter (eg: 128 -> 4) makes sure to also change the learning rate, since your gradients are a lot noisier. I would divide the learning rate by the same factor.
@greeheim Thank you for an advice! I've never thought that learning rate could cause a problem like that.
Now I'm training EfficientDet D1 on GTX 1080 Ti with batch size = 6 and LR = 0.003 with warmup. It looks promising.
Here's my pipeline config in case anyone ever needs it.
I am getting a similar issue right now tried to reduce the learning rate of the model and training seems working well.
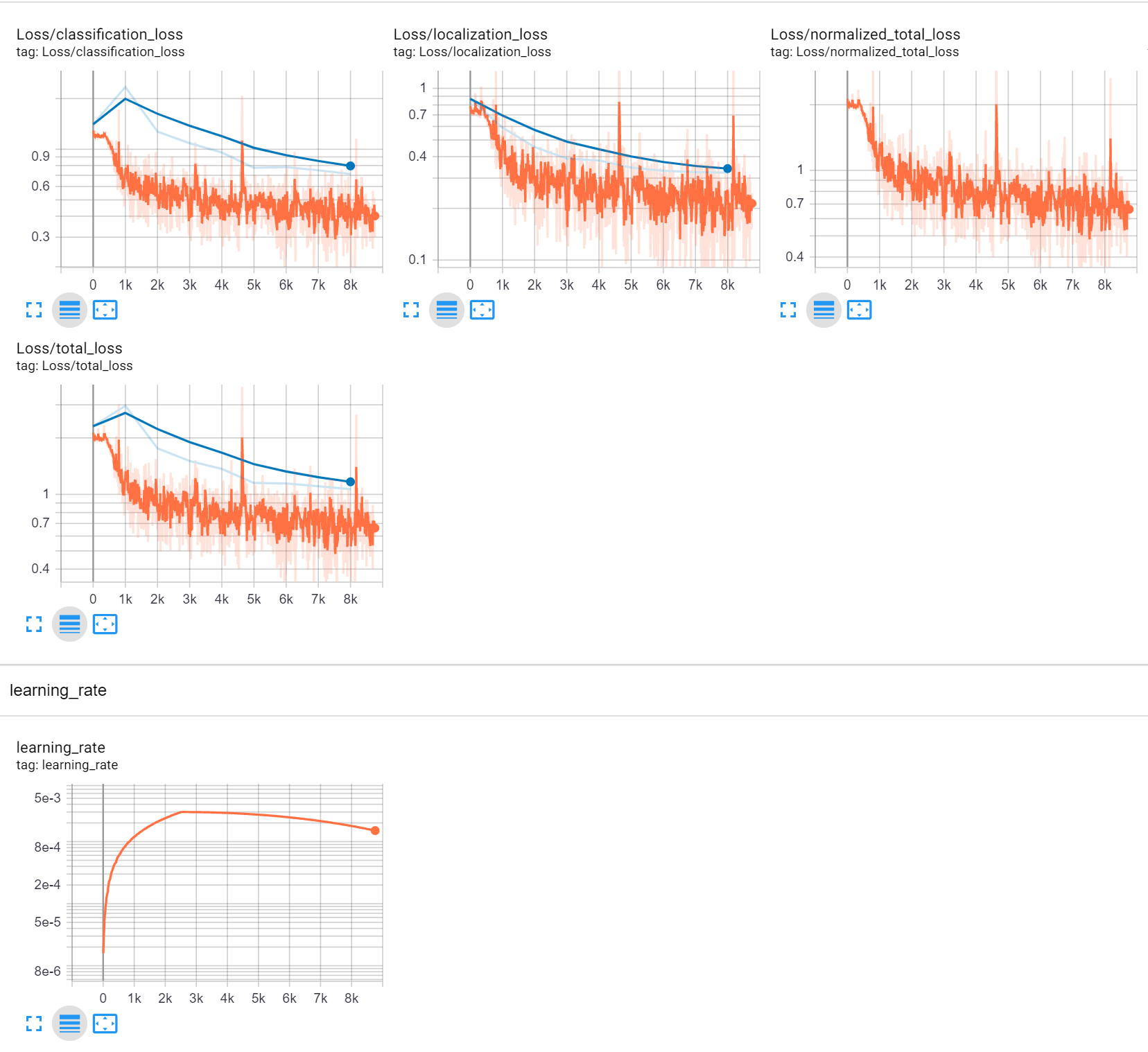
Those blue lines are on tensorboard logs record, is it testing metrics? how do i get it while training?
I am only able to get training metrics am using COCO metrics.
also on evaluation am able to get only single point after training. how to get this graph
 aafaqin
on 12 Oct 2020
aafaqin
on 12 Oct 2020
@aafaqin If you're using tf2 then you should run a separate evaluation process to get those blue lines in tensorboard.
Use smth like this
# eval
python models/research/object_detection/model_main_tf2.py --pipeline_config_path=$PIPELINE_CONFIG --model_dir=$MODEL_DIR --checkpoint_dir=$MODEL_DIR --alsologtostderr
@aafaqin If you're using tf2 then you should run a separate evaluation process to get those blue lines in tensorboard.
Use smth like this# eval python models/research/object_detection/model_main_tf2.py --pipeline_config_path=$PIPELINE_CONFIG --model_dir=$MODEL_DIR --checkpoint_dir=$MODEL_DIR --alsologtostderr
@koolvn I am still not able to see those blue lines....is it after some steps or epochs or so ? also for tensorboard which logdir to use ? /train or /eval ....I can see 2 logs dirs.
 adityap27
on 23 Nov 2020
adityap27
on 23 Nov 2020
@adityap27 are you running evaluation task in parallel with training?
Yes, it'll make evaluate every 1000 steps as far as I can remember
Also you have to specify evaluation dataset in your config file

koolvn
on 23 Nov 2020
@aafaqin are you running evaluation task in parallel with training?
Yes, it'll make evaluate every 1000 steps as far as I can remember
Also you have to specify evaluation dataset in your config file
My config file matches with you.
Also same with me. Evaluates after 1000 steps.
I ran after training finishes. (serial manner) I will try parallel.
Also currently with logdir as /train I get train loss in Tensorboard and with /eval I get only eval mAP, I can't get eval loss.
So what logdir you used with tensorboard ? /train ?
adityap27
on 23 Nov 2020
@adityap27 You _have to_ run eval task in parallel (I also tried to run eval task after the training is finished but it gave me results only for the last step)
Actually I use $MODEL_DIR as a --logdir in tensorboard
The /eval and /train are subfolders in $MODEL_DIR
koolvn
on 23 Nov 2020
val and /train are subf
Thanks @koolvn ,
Running eval job in parallel and using $MODEL_DIR as a --logdir in tensorboard. These both worked for me to get nice graphs..!!
adityap27
on 23 Nov 2020
Related issues
 25b3nk
·
3Comments
25b3nk
·
3Comments
 xbcReal
·
3Comments
xbcReal
·
3Comments
 XavDCtpz
·
3Comments
XavDCtpz
·
3Comments
 frankkloster
·
3Comments
frankkloster
·
3Comments
 Mostafaghelich
·
3Comments
Mostafaghelich
·
3Comments
Most helpful comment
Try to reduce the learning rate, this should solve the problem. The models are usually trained with a large batchsize, eg.: 128 for efficient_det d3, when adjusting this parameter (eg: 128 -> 4) makes sure to also change the learning rate, since your gradients are a lot noisier. I would divide the learning rate by the same factor.