Models: Object Detection API 2.0, error with load checkpoints: A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used.
Prerequisites
Please answer the following questions for yourself before submitting an issue.
- [ ] I am using the latest TensorFlow Model Garden release and TensorFlow 2.
- [ ] I am reporting the issue to the correct repository. (Model Garden official or research directory)
- [ ] I checked to make sure that this issue has not already been filed.
1. The entire URL of the file you are using
https://github.com/tensorflow/models/tree/master/research/object_detection
2. Describe the bug
Thanks for releasing the Object Detection API 2.0. I am trying to build the model on my own dataset. I downloaded the trained file from model zoo CenterNet HourGlass104 512x512. Then changed the configure file and test the code. A bug comes.
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.conv_block.norm.moving_variance
W0716 19:56:53.424076 140587994642240 util.py:144] Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.conv_block.norm.moving_variance
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.conv.kernel
W0716 19:56:53.424108 140587994642240 util.py:144] Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.conv.kernel
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.norm.axis
W0716 19:56:53.424140 140587994642240 util.py:144] Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.norm.axis
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.norm.gamma
W0716 19:56:53.424172 140587994642240 util.py:144] Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.norm.gamma
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.norm.beta
W0716 19:56:53.424204 140587994642240 util.py:144] Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.norm.beta
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.norm.moving_mean
W0716 19:56:53.424236 140587994642240 util.py:144] Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.norm.moving_mean
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.norm.moving_variance
W0716 19:56:53.424268 140587994642240 util.py:144] Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.norm.moving_variance
WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
W0716 19:56:53.424301 140587994642240 util.py:152] **A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.**
A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
I do not know how to resolve this issue!
6. System information
- OS Platform and Distribution: Linux Ubuntu 18.04
- TensorFlow installed from (source or binary): installed as the official guide and no error occurs.
- TensorFlow version (use command below): tensorflow 2.2.0
- Python version: 3.6
- CUDA/cuDNN version: CUDA 10.2, CuDNN 7.6
- GPU model and memory: 2x 2080 Ti
 Derekabc
Derekabc
All 119 comments
I'm having the exact same issue.
Folder structure
data/
├── labels.pbtxt
├── train.record
├── test.record
model/ #extracted from http://download.tensorflow.org/models/object_detection/tf2/20200711/efficientdet_d0_coco17_tpu-32.tar.gz
├── saved_model/
├── assets/
├── variables/
├── saved_model.pb
├── checkpoint/
├── checkpoint
├── ckpt-0.data-00000-of-00001
├── ckpt-0.index
├── pipeline.config
train.py # copy of model_main_tf2.py
command run
python train.py --alsologtostderr --model_dir=model/ --pipeline_config_path=model/pipeline.config
Config
...
fine_tune_checkpoint: "model/ckpt-0"
num_steps: 300000
startup_delay_steps: 0.0
replicas_to_aggregate: 8
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
fine_tune_checkpoint_type: "detection"
use_bfloat16: true
fine_tune_checkpoint_version: V2
}
train_input_reader: {
label_map_path: "data/labels.pbtxt"
tf_record_input_reader {
input_path: "data/train.tfrecord"
}
}
eval_config: {
metrics_set: "coco_detection_metrics"
use_moving_averages: false
batch_size: 1;
}
eval_input_reader: {
label_map_path: "data/labels.pbtxt"
shuffle: false
num_epochs: 1
tf_record_input_reader {
input_path: "data/test.tfrecord"
}
}
It does create a /train folder under model but fails with the following output before any learning happens
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._box_predictor._base_tower_layers_for_heads.class_predictions_with_background.4.7.beta
W0717 10:59:19.085086 140059259959104 util.py:144] Unresolved object in checkpoint: (root).model._box_predictor._base_tower_layers_for_heads.class_predictions_with_background.4.7.beta
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._box_predictor._base_tower_layers_for_heads.class_predictions_with_background.4.7.moving_mean
W0717 10:59:19.085122 140059259959104 util.py:144] Unresolved object in checkpoint: (root).model._box_predictor._base_tower_layers_for_heads.class_predictions_with_background.4.7.moving_mean
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._box_predictor._base_tower_layers_for_heads.class_predictions_with_background.4.7.moving_variance
W0717 10:59:19.085184 140059259959104 util.py:144] Unresolved object in checkpoint: (root).model._box_predictor._base_tower_layers_for_heads.class_predictions_with_background.4.7.moving_variance
WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
W0717 10:59:19.085304 140059259959104 util.py:152] A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
Traceback (most recent call last):
File "train.py", line 114, in <module>
tf.compat.v1.app.run()
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/platform/app.py", line 40, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/absl/app.py", line 299, in run
_run_main(main, args)
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/absl/app.py", line 250, in _run_main
sys.exit(main(argv))
File "train.py", line 111, in main
use_tpu=FLAGS.use_tpu)
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/object_detection/model_lib_v2.py", line 569, in train_loop
ckpt.restore(latest_checkpoint)
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/training/tracking/util.py", line 2009, in restore
status = self._saver.restore(save_path=save_path)
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/training/tracking/util.py", line 1304, in restore
checkpoint=checkpoint, proto_id=0).restore(self._graph_view.root)
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py", line 209, in restore
restore_ops = trackable._restore_from_checkpoint_position(self) # pylint: disable=protected-access
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/training/tracking/base.py", line 907, in _restore_from_checkpoint_position
tensor_saveables, python_saveables))
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/training/tracking/util.py", line 289, in restore_saveables
validated_saveables).restore(self.save_path_tensor)
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/training/saving/functional_saver.py", line 281, in restore
restore_ops.update(saver.restore(file_prefix))
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/training/saving/functional_saver.py", line 103, in restore
restored_tensors, restored_shapes=None)
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/distribute/values.py", line 647, in restore
for v in self._mirrored_variable.values))
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/distribute/values.py", line 647, in <genexpr>
for v in self._mirrored_variable.values))
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/distribute/values.py", line 392, in _assign_on_device
return variable.assign(tensor)
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/ops/resource_variable_ops.py", line 846, in assign
self._shape.assert_is_compatible_with(value_tensor.shape)
File "/home/davide/anaconda3/envs/tf2/lib/python3.7/site-packages/tensorflow/python/framework/tensor_shape.py", line 1117, in assert_is_compatible_with
raise ValueError("Shapes %s and %s are incompatible" % (self, other))
ValueError: Shapes (9,) and (810,) are incompatible
WARNING:tensorflow:Unresolved object in checkpoint: (root).save_counter
W0717 10:59:21.835075 140059259959104 util.py:144] Unresolved object in checkpoint: (root).save_counter
WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
W0717 10:59:21.835391 140059259959104 util.py:152] A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
Probably also worth pointing out that I tested the installation successfully with python object_detection/builders/model_builder_tf2_test.py
 davodesign84
on 17 Jul 2020
davodesign84
on 17 Jul 2020
I have the same issue as well.
I tried to load checkpoints from models ssd_mobilenet_v1_fpn_640x640, efficientdet_d0_coco17 and none of the them are loaded properly.
 bobokvsky
on 17 Jul 2020
bobokvsky
on 17 Jul 2020
Issue confirmed for me as well for all pre-trained EfficientDet models in the zoo. Other model types not tested, yet.
W0717 08:31:07.516187 7684 util.py:152] A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
Running model_main_tf2.py fails silently with no error and no traceback, just the above warning.
model_lib_tf2_test.py passes with 3 skips, no failures.
OS Platform and Distribution: Windows 10
TensorFlow installed from (source or binary): pip install tensorflow==2.2
TensorFlow version (use command below): tensorflow 2.2.0
Python version: 3.7
CUDA/cuDNN version: CUDA 10.1 / CuDNN 7.6.5
GPU model and memory: 1080 Ti (12Gb -- 8.5 available)
 Shakesbeery
on 17 Jul 2020
Shakesbeery
on 17 Jul 2020
same issue
model:
centernet_resnet50_v1_fpn_512x512_coco17_tpu-8.tar
efficientdet_d0_coco17_tpu-32.tar
ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8.tar
faster_rcnn_resnet50_v1_640x640_coco17_tpu-8.tar
centernet_hg104_512x512_coco17_tpu-8.tar
ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.tar
Windows 10
TensorFlow version (use command below): tensorflow 2.2.0
Python version: 3.7
CUDA/cuDNN version: CUDA 10.1 / CuDNN 7.6.5
GPU : 1660 Ti
 xieyh
on 18 Jul 2020
xieyh
on 18 Jul 2020
I seem to be running into this same issue with loading a config value for Mask RCNN on Mac with TF 2.2.0
I'm using the Mask RCNN models weights from the bottom of the TF2 Model Detection Zoo page and the config example MASK RCNN config sample here. I have the same issue where it I get warnings (~150) for layers failing to load. For example:
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._feature_extractor_for_box_classifier_features.layer_with_weights-14.kernel
W0717 14:29:02.269019 4319387072 util.py:144] Unresolved object in checkpoint: (root).model._feature_extractor_for_box_classifier_features.layer_with_weights-14.kernel
The fine tune checkpoint specified the example .config file uses a filename (inception_resnet_v2.ckpt-1) not in the zipped checkpoint from the model zoo. I'm not sure if that's the problem. Separately, I also noticed that under the train_config, I had to set fine_tune_checkpoint_version: V2 or it` would fail to accept the configuration.
 wronk
on 20 Jul 2020
wronk
on 20 Jul 2020
I have the same kind of issue.
model and checkpoint
SSD MobileNet v2 320x320 from TensorFlow 2 Detection Model Zoo
config
edited this pipeline.config for my local files.
I've changed the parameter in my config file num_classes = 90 to num_classes = 13 for my original dataset.
command
python object_detection/model_main_tf2.py
--pipeline_config_path=/my_model_dir/my_model.config
--model_dir=/my_model_dir/
--alsologtostderr
I get the following error.
W0720 05:36:27.828208 139692008720192 util.py:152] A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
Traceback (most recent call last):
File "object_detection/model_main_tf2.py", line 106, in <module>
tf.compat.v1.app.run()
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/platform/app.py", line 40, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "/usr/local/lib/python3.6/dist-packages/absl/app.py", line 299, in run
_run_main(main, args)
File "/usr/local/lib/python3.6/dist-packages/absl/app.py", line 250, in _run_main
sys.exit(main(argv))
File "object_detection/model_main_tf2.py", line 103, in main
use_tpu=FLAGS.use_tpu)
File "/home/tensorflow/.local/lib/python3.6/site-packages/object_detection/model_lib_v2.py", line 569, in train_loop
ckpt.restore(latest_checkpoint)
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/training/tracking/util.py", line 2009, in restore
status = self._saver.restore(save_path=save_path)
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/training/tracking/util.py", line 1304, in restore
checkpoint=checkpoint, proto_id=0).restore(self._graph_view.root)
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/training/tracking/base.py", line 209, in restore
restore_ops = trackable._restore_from_checkpoint_position(self) # pylint: disable=protected-access
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/training/tracking/base.py", line 907, in _restore_from_checkpoint_position
tensor_saveables, python_saveables))
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/training/tracking/util.py", line 289, in restore_saveables
validated_saveables).restore(self.save_path_tensor)
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/training/saving/functional_saver.py", line 281, in restore
restore_ops.update(saver.restore(file_prefix))
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/training/saving/functional_saver.py", line 103, in restore
restored_tensors, restored_shapes=None)
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/distribute/values.py", line 647, in restore
for v in self._mirrored_variable.values))
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/distribute/values.py", line 647, in <genexpr>
for v in self._mirrored_variable.values))
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/distribute/values.py", line 392, in _assign_on_device
return variable.assign(tensor)
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/ops/resource_variable_ops.py", line 846, in assign
self._shape.assert_is_compatible_with(value_tensor.shape)
File "/home/tensorflow/.local/lib/python3.6/site-packages/tensorflow/python/framework/tensor_shape.py", line 1117, in assert_is_compatible_with
raise ValueError("Shapes %s and %s are incompatible" % (self, other))
ValueError: Shapes (42,) and (273,) are incompatible
If I set in the config file num_classes = 90(default value), the training process starts running.
environment
OS: Ubuntu 18.04
Python: 3.6
TensorFlow: 2.2.0
cuda/cuDNN: 10.0/7.6.5
GPU: RTX 2080Ti
 tnb-wu
on 20 Jul 2020
tnb-wu
on 20 Jul 2020
I seem to be having the same issue as the original poster.
I successfully trained the efficientdet_d0 (from scratch, for +- 5000steps) then tried to train the efficientdet_d1 with the "fine_tune_checkpoint" pointing to the efficientdet_0 final checkpoint but then I also get the warnings and the training does not start:
WARNING:tensorflow:Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.0.bias
W0720 10:31:50.390428 140235167352640 util.py:144] Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.0.bias
WARNING:tensorflow:Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.1.gamma
W0720 10:31:50.390517 140235167352640 util.py:144] Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.1.gamma
WARNING:tensorflow:Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.1.beta
W0720 10:31:50.390611 140235167352640 util.py:144] Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.1.beta
WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
W0720 10:31:50.390712 140235167352640 util.py:152] A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
I'm running this training on a single gpu machine, so I've commented the "sync_replicas" and "replicas_to_aggregate" parameters + I've tuned the hyperparams abit to make the model produce some output (lr & batch size)
 MaesIT
on 20 Jul 2020
MaesIT
on 20 Jul 2020
Same issue:
File "/home/musashi/.virtualenvs/tf2.0/lib/python3.6/site-packages/tensorflow/python/framework/tensor_shape.py", line 1117, in assert_is_compatible_with
raise ValueError("Shapes %s and %s are incompatible" % (self, other))
ValueError: Shapes (36,) and (810,) are incompatible
WARNING:tensorflow:Unresolved object in checkpoint: (root).save_counter
W0721 12:58:29.073055 139770281662272 util.py:144] Unresolved object in checkpoint: (root).save_counter
WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
W0721 12:58:29.073232 139770281662272 util.py:152] A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
 marvision-ai
on 21 Jul 2020
marvision-ai
on 21 Jul 2020
I was able to get passed this error by changing the fine_tune_checkpoint_type to "detection"
UPDATE: I'm running this training on Colab and I keep getting memory allocation issues. I had to resort to running with a batch_size of 1....
Any suggestions?
 BernardinD
on 22 Jul 2020
BernardinD
on 22 Jul 2020
i have the same problems!
 siyangbing
on 22 Jul 2020
siyangbing
on 22 Jul 2020
@BernardinD
I was able to get passed this error by changing the
fine_tune_checkpoint_typeto "detection"
It also worked for me.
UPDATE: I'm running this training on Colab and I keep getting memory allocation issues. I had to resort to running with a batch_size of 1....
Any suggestions?
Why don't you use TPU on Colab?
 nrasadi
on 22 Jul 2020
nrasadi
on 22 Jul 2020
Not a real answer but If you want to train the model anyway. This works.
I have encountered the same situation. Then, I commented
fine_tune_checkpoint_version: V2
fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/ckpt-1"
fine_tune_checkpoint_type: "detection"
(I think this means not using pre-trained model). After this change, I manage to start the training. I will see the results but I am not expecting much :( .
 hasansalimkanmaz
on 23 Jul 2020
hasansalimkanmaz
on 23 Jul 2020
From this notebook:
https://github.com/tensorflow/models/blob/master/research/object_detection/colab_tutorials/eager_few_shot_od_training_tf2_colab.ipynb
We see that they restore the checkpoint with .expect_partial()
However in model_lib_v2.py they load the checkpoint without this. (line 569)
I know that in the first version some variables weren't loaded every time and it was apparently normal if I'm not wrong
 BouleJaune
on 23 Jul 2020
BouleJaune
on 23 Jul 2020
I was able to get passed this error by changing the
fine_tune_checkpoint_typeto "detection"
This works for some models, but others like CenterNet1024 still fail in the same manner.
Shakesbeery
on 23 Jul 2020
Setting/changing the fine_tune_checkpoint_type to detection for MaskRCNN also doesn't seem to work.
wronk
on 24 Jul 2020
I can confirm I am able to reproduce this with the EfficientDet D7 model given in the TF2 model zoo .
Changing fine_tune_checkpoint_type to detection does not solve the issue.
Tensorflow version: latest stable
TFOD installation branch: master
 KNaudin
on 24 Jul 2020
KNaudin
on 24 Jul 2020
@tombstone Hi Vivek, Could you please help us out here.Also please confirm if fine_tune_checkpoint_type to detection not use the pretrained model?
 zishanahmed08
on 24 Jul 2020
zishanahmed08
on 24 Jul 2020
Hello, I'm facing the same issue using "faster_rcnn_resnet101_v1_1024x1024_coco17_tpu-8", "centernet_hg104_1024x1024_coco17_tpu-32", and "efficientdet_d2_coco17_tpu-32". They all have the same sturcture as mentioned below. Also, changing fine_tune_checkpoint_type to detection does not work either.
├── checkpoint
│ ├── checkpoint
│ ├── ckpt-0.data-00000-of-00001
│ └── ckpt-0.index
├── pipeline.config
└── saved_model
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
I am using google cloud compute engine for this task.
CPU: N1 type 8-cores
Ram: 40GB
GPU: N/A
OS: Ubuntu 18.04
Python: 3.6
Tensorflow: 2.2
 lakshay1296
on 27 Jul 2020
lakshay1296
on 27 Jul 2020
I got the same error for trying to use both fast rcnn and context rcnn, have anyone solve the issue?
Confirming that change fine_tune_checkpoint_type to detection doesn't help in these cases as well.
 Geoyi
on 27 Jul 2020
Geoyi
on 27 Jul 2020
Good evening everyone, I'm trying to fine tune efficientdet_d4_coco17_tpu-32 and I'm also facing the same issue mentioned above.
raise ValueError("Shapes %s and %s are incompatible" % (self, other))
ValueError: Shapes (224,) and (256,) are incompatible
Tried fine tuning Efficientdet d2 and got the same error
Shapes (112,) and (256,) are incompatible
I realized that the depth of the box_predictor was 224 on effnet d4 and it is 112 on effnet b2.
Still working on a solution
Could this be regarding the .tfrecord file?
 nicholasguimaraes
on 28 Jul 2020
nicholasguimaraes
on 28 Jul 2020
Hello again, I got around this error (ValueError: Shapes (112,) and (256,) are incompatible) setting pad_to_max_dimension to false on my config file.
image_resizer {
keep_aspect_ratio_resizer {
min_dimension: 768
max_dimension: 768
pad_to_max_dimension: false
}
nicholasguimaraes
on 28 Jul 2020
Having the same issue on finetuning CenterNet on COCO17. Also, training from scratch is working fine.
 aabbas90
on 29 Jul 2020
aabbas90
on 29 Jul 2020
@aabbas90 can you please provide the steps to train from the scratch?? i'm also having the same issue. thanks
 Deepthi-Jain
on 29 Jul 2020
Deepthi-Jain
on 29 Jul 2020
Having the same issue on finetuning CenterNet on COCO17. Also, training from scratch is working fine.
can you please provide the steps to train from the scratch?? i'm also having the same issue. thanks
Deepthi-Jain
on 29 Jul 2020
Not a real answer but If you want to train the model anyway. This works.
I have encountered the same situation. Then, I commented
fine_tune_checkpoint_version: V2 fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/ckpt-1" fine_tune_checkpoint_type: "detection"
(I think this means not using pre-trained model). After this change, I manage to start the training. I will see the results but I am not expecting much :( .
can you please let me know what happend to your training?
Deepthi-Jain
on 29 Jul 2020
Not a real answer but If you want to train the model anyway. This works.
I have encountered the same situation. Then, I commented
fine_tune_checkpoint_version: V2 fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/ckpt-1" fine_tune_checkpoint_type: "detection"
(I think this means not using pre-trained model). After this change, I manage to start the training. I will see the results but I am not expecting much :( .can you please let me know what happend to your training?
I gave up with tf object detection api. It took a lot of time for me. I switched to detectron2.
hasansalimkanmaz
on 29 Jul 2020
Not a real answer but If you want to train the model anyway. This works.
I have encountered the same situation. Then, I commented
fine_tune_checkpoint_version: V2 fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/ckpt-1" fine_tune_checkpoint_type: "detection"
(I think this means not using pre-trained model). After this change, I manage to start the training. I will see the results but I am not expecting much :( .can you please let me know what happend to your training?
I set to one field of fine_tune_checkpoint empty i.e. fine_tune_checkpoint: " ". If rest of the things are fine it should train from scratch for you.
aabbas90
on 29 Jul 2020
Maybe it is not intended, but when using tensorflow 2.3 I am actually able to train a model. But I guess this may can result in other problems. My model is still training, I may edit this post, if it's done.
 psychonetic
on 3 Aug 2020
psychonetic
on 3 Aug 2020
Maybe it is not intended, but when using tensorflow 2.3 I am actually able to train a model. But I guess this may can result in other problems. My model is still training, I may edit this post, if it's done.
Are you also able to fine-tune from the provided checkpoints in the API?
aabbas90
on 5 Aug 2020
update to tf 2.3 doesn't solve the problem.
it looks like change fine-tuning mode to "detection" allows to run
training, but I can't say if it saves classes of original model or not.
overall the fine-tuning is made somehow wrong (special format, various
incompatible versions, gpu/tpu) so I changed my pipeline to load
checkpoints to do fine-tuning in my experiments
On Wed, Aug 5, 2020, 08:40 Ahmed Abbas notifications@github.com wrote:
Maybe it is not intended, but when using tensorflow 2.3 I am actually able
to train a model. But I guess this may can result in other problems. My
model is still training, I may edit this post, if it's done.Are you also able to fine-tune from the provided checkpoints in the API?
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/tensorflow/models/issues/8892#issuecomment-669011089,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AALYALREF3CHYHYGECHPR7TR7D5G3ANCNFSM4O5HIKLQ
.
 veonua
on 5 Aug 2020
veonua
on 5 Aug 2020
update to tf 2.3 doesn't solve the problem. it looks like change fine-tuning mode to "detection" allows to run training, but I can't say if it saves classes of original model or not. overall the fine-tuning is made somehow wrong (special format, various incompatible versions, gpu/tpu) so I changed my pipeline to load checkpoints to do fine-tuning in my experiments
…
On Wed, Aug 5, 2020, 08:40 Ahmed Abbas @.*> wrote: Maybe it is not intended, but when using tensorflow 2.3 I am actually able to train a model. But I guess this may can result in other problems. My model is still training, I may edit this post, if it's done. Are you also able to fine-tune from the provided checkpoints in the API? — You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub <#8892 (comment)>, or unsubscribe https://github.com/notifications/unsubscribe-auth/AALYALREF3CHYHYGECHPR7TR7D5G3ANCNFSM4O5HIKLQ .
+1.
I tried multi-gpu training from scratch as I mentioned here: https://github.com/tensorflow/models/issues/5565#issuecomment-669123077. The checkpoint created through this way does not allow fine-tuning on single gpu.
aabbas90
on 5 Aug 2020
i'm getting this same error as well! support needed!
 jrash33
on 7 Aug 2020
jrash33
on 7 Aug 2020
Getting the same warnings when I try to using the initial check point. I am using TF 2.3 and trying to train on a novel data set with 2 classes using ssd_mobilenet_v2_320x320
 wardeha
on 10 Aug 2020
wardeha
on 10 Aug 2020
Can confirm that setting fine_tune_checkpoint_type to "detection" worked for me as well. Successfully trained a SSD Mobilenet V2 fpn and an EfficientDet_D0 on custom dataset. This was also stated in the tutorial https://tensorflow-object-detection-api-tutorial.readthedocs.io/en/latest/index.html . Stable version is 2.2. Maybe those of you trying with 2.3 might give it a try after downgrading to 2.2.
 mosch91-syn
on 10 Aug 2020
mosch91-syn
on 10 Aug 2020
A solution that doesn't work for everyone is not a solution
KNaudin
on 10 Aug 2020
Can confirm that setting fine_tune_checkpoint_type to "detection" worked for me as well. Successfully trained a SSD Mobilenet V2 fpn and an EfficientDet_D0 on custom dataset. This was also stated in the tutorial https://tensorflow-object-detection-api-tutorial.readthedocs.io/en/latest/index.html . Stable version is 2.2. Maybe those of you trying with 2.3 might give it a try after downgrading to 2.2.
Can you please point to the commit of this repo you are using, I had already tried on 2.2 version with same issue. Moreover, which kind of training hardware are you using is it single-gpu, multi-gpu or TPU? Thanks!
aabbas90
on 10 Aug 2020
Please note that the claim mentioned here: https://github.com/tensorflow/models/issues/8967#issuecomment-665082686 is not true as I was not able to fine-tune even by setting fine_tune_checkpoint_type: "fine_tune".
aabbas90
on 11 Aug 2020
I can comment on the CenterNet issues:
"detection"checkpoints are currently supported by hourglass models. The error messages are pointing towards the fact that the checkpoints weights are not in the right format. We currently only support one "detection" type checkpoint with the hourglass model. It is the ExtrementNet checkpoint from the TF2 Zoo. Once you download an unzip the file, the path should point to/path/to/file/extremenet/ckpt-1- Once #9089 is in,
"fine_tune"checkpoints will be supported for all CenterNet models. For "fine_tune", the path should point to a CenterNet* checkpoint of the same type in the TF2 Zoo. For example/path/to/file/centernet_hg104_512x512_coco17_tpu-8/checkpoint/ckpt-0 "classification"is supported for ResNet based feature extractors and you can use this script to create them.
 vighneshbirodkar
on 11 Aug 2020
vighneshbirodkar
on 11 Aug 2020
Just to report, changing the fine_tune_checkpoint_type to "detection" works for me for both faster rcnn resnet and ssd mobilenet.
 missmantou
on 13 Aug 2020
missmantou
on 13 Aug 2020
@aabbas90 's comment is fixed with
https://github.com/tensorflow/models/commit/fd6987fafb615427316c0bfac6fdb185273fcfcc
vighneshbirodkar
on 14 Aug 2020
For further clarifications, it would be helpful if we knew the exact contents of the config being used along with a link to which checkpoint you are using.
vighneshbirodkar
on 14 Aug 2020
- I am able to fine_tune
centernet_resnet50_v1_fpn_512x512_coco17_tpu-8by the associatedpipeline.configand pre-trained model from TF2 model zoo. Where I use:fine_tune_checkpoint_type: "fine_tune") - Carrying the same procedure on
efficientdet_d0_coco17_tpu-32from TF2 model zoo, fine-tuning does not work but detection does.
@vighneshbirodkar: I see a conflicting definition betweendetectionandfine_tunecheckpoint types comparing https://github.com/tensorflow/models/blob/2bef12e6fd830df331a858a3ca29a18357551e16/research/object_detection/meta_architectures/ssd_meta_arch.py#L1319-L1329 with https://github.com/tensorflow/models/blob/2bef12e6fd830df331a858a3ca29a18357551e16/research/object_detection/meta_architectures/center_net_meta_arch.py#L3006-L3024
SSD is loading everything in detection mode, whereas CenterNet is loading only the feature extractor. - @vighneshbirodkar could you also please clarify which config files should a user start from:
a. The ones given inside the repo i.e., in https://github.com/tensorflow/models/tree/master/research/object_detection/configs/tf2
b. Or by the config files from the downloaded models from TF2 model zoo. Note that these config files have different parameters at-least forefficientdet_d0.
aabbas90
on 14 Aug 2020
- Great, that is the intended usage. You should also be able to use detection with the extrement checkpoint.
SSD is not loading the whole model, the lines
fake_model = tf.train.Checkpoint(
_feature_extractor=self._feature_extractor)
return {'model': fake_model}
ensure that only the feature extractor is loaded.
- I would start with the ones in configs/tf2
vighneshbirodkar
on 14 Aug 2020
I have sucessfully fine-tuned the 1024 version of faster rcnn and efficientdet.
However, when I am fine-tuning CenterNet HourGlass104 1024x1024, I find the same issue and my program will automatically get killed.
I am training on a RTX 2080 Ti.
Update:
After reinstall the latest version of object detection api, and modify the config file from "detection" to "fine_tune", the issue disappeared, and I am now trainig cernet as expected.
- Once #9089 is in,
"fine_tune"checkpoints will be supported for all CenterNet models.
 fclof
on 18 Aug 2020
fclof
on 18 Aug 2020
@fclof Are you observing very slow convergence on CenterNet? I have tried fine-tuning both efficientdet_d0 and centerNet_hourglass, efficientDet converges really well while CenterNet is not showing any signs of convergence. Thanks!
aabbas90
on 18 Aug 2020
What batch size and learning rate are you using @aabbas90 ?
vighneshbirodkar
on 18 Aug 2020
What batch size and learning rate are you using @aabbas90 ?
@vighneshbirodkar : batch_size : 8, learning_rate : 5e-4
I have also tried centernet_resnet50_v1_fpn_512x512 and also do not see convergence after one day of training on a relatively simpler dataset than COCO2017. Specifically, the object_center loss almost always remain above 2.0, while for efficientDet_d0 the total loss dips very fast already after one hour of training.
aabbas90
on 19 Aug 2020
Hi everyone, I'm experiencing the same issue seen here.
System information
OS Platform and Distribution: Ubuntu 18.04
TensorFlow installed from (source or binary): Installed using pip in a virtualenv.
TensorFlow version: tensorflow 2.3.0
Python version: 3.6.10
CUDA/cuDNN version: CUDA 10.1, CuDNN 7.6.5
GPU model and memory: RTX 2070 Super, 8GB VRAM
Object Detection API: latest - models @ 40e124320636797487b4db476511bf7147616a93
Models Tested
- Faster R-CNN ResNet50 V1 1024x1024
- Faster R-CNN ResNet101 V1 1024x1024
- SSD ResNet101 V1 FPN 1024x1024 (RetinaNet101)
- CenterNet HourGlass 104 1024x1024.
- Edit: EfficientDet D4 1024x1024 as well
For all of the above I'm seeing the incompatible shapes error when restoring the checkpoints. In all cases the fine_tune_checkpoint_type was set to detection, _except_ for CenterNet HourGlass, which was set to fine_tune. When running CenterNet HourGlass with detection, I get a different error: AssertionError: Some Python objects were not bound to checkpointed values, likely due to changes in the Python program.
In all cases, the failure occurs when trying to restore the checkpoints. I've downloaded my checkpoints from the TF2 Model Zoo, and I've modified the configs found in configs/tf2.
In all cases I've set my batch sizes to be 2 just to try and get anything running. I have changed a few settings in my config files, such as:
- num_classes: 1
- num_steps: 20000
- fine_tune_checkpoint_type, as mentioned above.
- learning_rate. I modified this to be a manual_step_learning_rate.
- use_bfloat16: false.
Happy to provide more information - any help would be much appreciated!
 navganti
on 20 Aug 2020
navganti
on 20 Aug 2020
What batch size and learning rate are you using @aabbas90 ?
@vighneshbirodkar : batch_size : 8, learning_rate : 5e-4
I have also triedcenternet_resnet50_v1_fpn_512x512and also do not see convergence after one day of training on a relatively simpler dataset than COCO2017. Specifically, theobject_centerloss almost always remain above 2.0, while forefficientDet_d0the total loss dips very fast already after one hour of training.
UPDATE: Even though the loss is not decreasing much as per my expectations, however, the evaluation metrics on test data still look very promising therefore I think this is no longer an issue.
aabbas90
on 20 Aug 2020
@navganti Which checkpoint did you download for CenterNet and what is your exact checkpoint type and checkpoint path ?
vighneshbirodkar
on 20 Aug 2020
@vighneshbirodkar
The checkpoint I used was centernet_hg104_1024x1024_coco17_tpu-32.tar.gz. I did one experiment with the checkpoint type as detection, and one with it as fine_tune. The checkpoint path I used was /path/to/centernet_hg104_1024x1024_coco17_tpu-32/checkpoint/ckpt-0.
navganti
on 20 Aug 2020
As I mentioned in https://github.com/tensorflow/models/issues/8892#issuecomment-671983240, fine_tune should work. What is the error you are getting ? Could you paste/link it there ?
vighneshbirodkar
on 20 Aug 2020
The error I'm getting is the following: ValueError: Shapes (1,) and (90,) are incompatible.
With the following warning: WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
The traceback goes all the way back to ckpt.restore(latest_checkpoint) in train_loop.
navganti
on 20 Aug 2020
The .config file I'm using is not the one that was included in the centernet_hg104_1024x1024_coco17_tpu-32 folder - I modified the one from configs/tf2
navganti
on 20 Aug 2020
Can you share the full log ? I think this error is due to mis-matching label sizes somewhere.
vighneshbirodkar
on 20 Aug 2020
Here's the full traceback @vighneshbirodkar. Thanks so much for your help, I really appreciate it!
Traceback (most recent call last):
File "object_detection/model_main_tf2.py", line 113, in <module>
tf.compat.v1.app.run()
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/platform/app.py", line 40, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/absl/app.py", line 299, in run
_run_main(main, args)
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/absl/app.py", line 250, in _run_main
sys.exit(main(argv))
File "object_detection/model_main_tf2.py", line 110, in main
record_summaries=FLAGS.record_summaries)
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/object_detection/model_lib_v2.py", line 579, in train_loop
ckpt.restore(latest_checkpoint)
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/training/tracking/util.py", line 2118, in restore
status = self.read(save_path, options=options)
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/training/tracking/util.py", line 2035, in read
return self._saver.restore(save_path=save_path, options=options)
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/training/tracking/util.py", line 1320, in restore
checkpoint=checkpoint, proto_id=0).restore(self._graph_view.root)
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/training/tracking/base.py", line 209, in restore
restore_ops = trackable._restore_from_checkpoint_position(self) # pylint: disable=protected-access
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/training/tracking/base.py", line 914, in _restore_from_checkpoint_position
tensor_saveables, python_saveables))
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/training/tracking/util.py", line 297, in restore_saveables
validated_saveables).restore(self.save_path_tensor, self.options)
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/training/saving/functional_saver.py", line 340, in restore
restore_ops = restore_fn()
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/training/saving/functional_saver.py", line 316, in restore_fn
restore_ops.update(saver.restore(file_prefix, options))
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/training/saving/functional_saver.py", line 111, in restore
restored_tensors, restored_shapes=None)
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/distribute/values.py", line 890, in restore
for v in self._mirrored_variable.values))
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/distribute/values.py", line 890, in <genexpr>
for v in self._mirrored_variable.values))
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/distribute/values_util.py", line 195, in assign_on_device
return variable.assign(tensor)
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/ops/resource_variable_ops.py", line 858, in assign
self._shape.assert_is_compatible_with(value_tensor.shape)
File "/home/nav/.pyenv/versions/anomaly_detection/lib/python3.6/site-packages/tensorflow/python/framework/tensor_shape.py", line 1134, in assert_is_compatible_with
raise ValueError("Shapes %s and %s are incompatible" % (self, other))
ValueError: Shapes (1,) and (90,) are incompatible
WARNING:tensorflow:Unresolved object in checkpoint: (root).save_counter
W0820 10:53:18.252379 140516305961088 util.py:150] Unresolved object in checkpoint: (root).save_counter
WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
W0820 10:53:18.252644 140516305961088 util.py:158] A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
@navganti Notice that the problem is happening and ckpt.restore(latest_checkpoint). This is not loading the fine tune checkpoint, but rather a latest checkpoint from your training directory. My guess is you did some amount of training with num_classes=90, and then switched the config to be num_classes=1. I would suggest you use a different model directory and try again.
vighneshbirodkar
on 20 Aug 2020
@vighneshbirodkar I see that, but unfortunately I have no other checkpoints in my MODEL_DIR, and have done no prior training.
Within my MODEL_DIR I have the following files:
centernet_hg104_1024x1024_coco17_tpu-32.configcheckpointckpt-0.data-00000-of-00001ckpt-0.index
I believe this is the correct folder structure recommended here? The training script did create a train directory in this folder.
I did do a test where I had the 3 checkpoint files placed in a separate checkpoint directory within this folder, and set that as the MODEL_DIR instead. No luck in that test either though.
navganti
on 20 Aug 2020
You're not wrong though in that this previous checkpoint was trained with 90 classes, and now I'm trying to use 1.
In my config file I've specified:
fine_tune_checkpoint_version: V2fine_tune_checkpoint: /path/to/centernet_hg104_1024x1024_coco17_tpu-32/ckpt-0"fine_tune_checkpoint_type: "fine_tune"
Is there anything else I need to do in order to specify that I want to fine tune, so it doesn't try to restore this checkpoint as the latest_checkpoint?
navganti
on 20 Aug 2020
Your model dir should be empty when starting training. Note that in the directory structure example we say "created by training job". We periodically write the weights to model dir, in case training is interrupted and we have to resume. Because you had placed pre-trained checkpoint files in model dir, the script thinks that it is a previously stored checkpoint and tries to restore from it (and fails because the checkpoint has 90 classes). Your config file is correct. Just make sure that.
- Model dir is empty at the start of training. The training script will write files there as it runs.
- Make sure
fine_tune_checkpointpoints to a completely different directory not related to model dir.
So basically, just point model dir to a new empty folder.
vighneshbirodkar
on 20 Aug 2020
...yikes. That makes a lot of sense, definitely feel a little silly. Thank you @vighneshbirodkar, so sorry to take up your time with that.
All of the models that I tested before are now training.
navganti
on 21 Aug 2020
I am closing this as of now. If someone is still running into an error, feel free to re-open with the config and the full log.
vighneshbirodkar
on 21 Aug 2020
Just to report, changing the fine_tune_checkpoint_type to "detection" works for me for both faster rcnn resnet and ssd mobilenet.
For me works, the training process starts correctly! :+1:
 ambigus9
on 25 Aug 2020
ambigus9
on 25 Aug 2020
Hi,
I am trying to use centernet for one my projects. Current I was just testing it out on the normal RBC dataset, but I am getting checkpoint related error when using the CentreNet Model. I am attaching my config and log file(sorry for the long file, its just repeated errors).
Config.txt
Error_CenterNet.txt
 HadesReturns
on 25 Aug 2020
HadesReturns
on 25 Aug 2020
@HadesReturns
As I mentioned in my comment you should set fine_tune_checkpoint_type to "fine_tune".
vighneshbirodkar
on 25 Aug 2020
@HadesReturns
As I mentioned in my comment you should set fine_tune_checkpoint_type to "fine_tune".
Hey Vignesh
Thanks a lot for your help, I was apparently changing the wrong parameter of the fine_tune_checkpoint when setting it to fine_tune. Its all working now, thanks a ton for your help.
HadesReturns
on 26 Aug 2020
@HadesReturns
As I mentioned in my comment you should set fine_tune_checkpoint_type to "fine_tune".Hey Vignesh
Thanks a lot for your help, I was apparently changing the wrong parameter of the fine_tune_checkpoint when setting it to fine_tune. Its all working now, thanks a ton for your help.
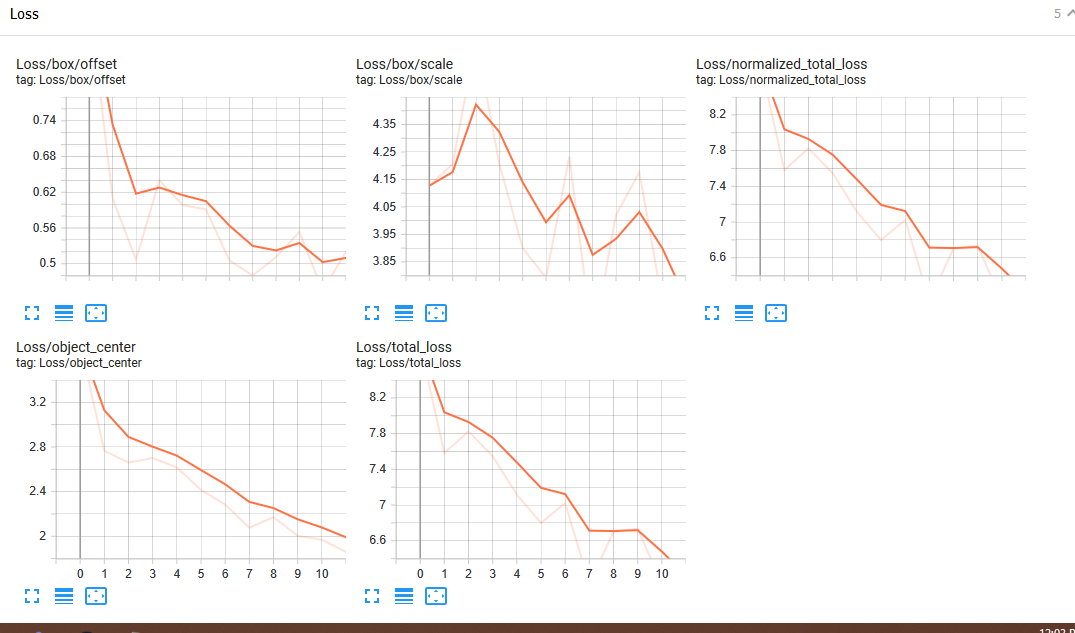
Also @vighneshbirodkar do you have any idea how I can obtain mAP score for CentreNet when training the model as I only get loss values and few images in tensorboard.
Log.txt
HadesReturns
on 26 Aug 2020
@HadesReturns You need to launch a separate eval job for that.
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_training_and_evaluation.md#evaluation
vighneshbirodkar
on 26 Aug 2020
@HadesReturns You need to launch a separate eval job for that.
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_training_and_evaluation.md#evaluation
Thanks a lot
HadesReturns
on 26 Aug 2020
 serenadeRay
on 10 Sep 2020
serenadeRay
on 10 Sep 2020
How is this closed? The error still occurs
 turowicz
on 11 Sep 2020
turowicz
on 11 Sep 2020
@turowicz What is the config you are using and what checkpoint have you downloaded to use with it ?
vighneshbirodkar
on 11 Sep 2020
I am using the Efficientnet D1 checkpoint and config from the TF2 Model Zoo.
turowicz
on 11 Sep 2020
Can you copy paste the contents of the config file ? Or share it through a gist ?
vighneshbirodkar
on 11 Sep 2020
@vighneshbirodkar here: https://github.com/tensorflow/models/issues/9229
turowicz
on 11 Sep 2020
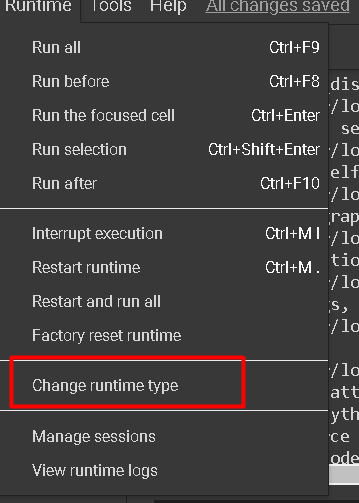
i had similar issues but i set my runtime to GPU in colab and it was resolved. i actually did select it initially
 iamreechi
on 20 Sep 2020
iamreechi
on 20 Sep 2020
Is there any documentation about the configuration files? I could not find much apart from a few questions at stackoverflow and some blog posts on medium.
What is the difference between setting fine_tune_checkpoint_type to fine_tune instead of detection?
 dkk
on 22 Sep 2020
dkk
on 22 Sep 2020
@dkk there's the protos folder, it has explanations to the config elements (only learned that recently)
maybe that could help you
models/research/object_detection/protos
 Maioy97
on 23 Sep 2020
Maioy97
on 23 Sep 2020
@HadesReturns
As I mentioned in my comment you should set fine_tune_checkpoint_type to "fine_tune".
thanks, it works for center_net_hourglass104_512x512_coco17_tpu-8
 yuezhilanyi
on 29 Sep 2020
yuezhilanyi
on 29 Sep 2020
I am trying to train the model using ssd_mobilenet_v2_320x320_coco17_tpu-8.
In the config file I need to update "fine_tune_checkpoint", where do I find this?
I have downloaded the pre-trained model from "http://download.tensorflow.org/models/object_detection/tf2/20200711/ssd_mobilenet_v2_320x320_coco17_tpu-8.tar.gz".
This gives me in this loaded model a folder called checkpoint with the below files in it:
checkpoint
ckpt-0.data-00000-of-00001
cpkt-0.index
Is this what I use? If yes how?
Because when I point "fine_tune_checkpoint" to "2. ckpt-0.data-00000-of-00001" it gives me an error saying file cant be read (incorrect file type)
 AbhishekLahiri86
on 10 Oct 2020
AbhishekLahiri86
on 10 Oct 2020
@AbhishekLahiri86
You should set config file as follows:
fine_tune_checkpoint: "my_model/pre_trained_models/ssd_mobilenet_v2_320x320_coco17_tpu-8/checkpoint/ckpt-0"
Also, remember set additional parammeters like:
fine_tune_checkpoint_type: "detection"
this will fix it
use fine_tune_checkpoint_type: "fine_tune" instead of fine_tune_checkpoint_type: "detection"
 vamshi-rvk
on 16 Oct 2020
vamshi-rvk
on 16 Oct 2020
this will fix it
use fine_tune_checkpoint_type: "fine_tune" instead of fine_tune_checkpoint_type: "detection"
This didn't fix it for me.
 kdpuddin98
on 19 Oct 2020
kdpuddin98
on 19 Oct 2020
I meet this problem.too. but I can continue to run the script, do I need to fix it?
 pc-mysql
on 23 Oct 2020
pc-mysql
on 23 Oct 2020
@pc-mysql It depends of you, Are getting detections on infer step?
ambigus9
on 23 Oct 2020
@vighneshbirodkar I'm having the same issue trying to fine tune CenterNet HourGlass 1024x1024 but I'm a little confused by your comment https://github.com/tensorflow/models/issues/8892#issuecomment-677849457
I always have the following files in the folder:
"/content/models/research/pretrained_model/checkpoint/ckpt-0"
checkpoint
ckpt-0.data-00000-of-00001
cpkt-0.index
So I deleted the files and ran the script again and now I got another error message:
RuntimeError: Unsuccessful TensorSliceReader constructor: Failed to find any matching files for /content/models/research/pretrained_model/checkpoint/ckpt-0
I'm not understanding why I can't make CenterNet 1024x1024 work but both Resnet50 and Resnet101 work for me.
my config.
pipeline - Copy.config.txt
Could you please help me out?
 gilmotta
on 26 Oct 2020
gilmotta
on 26 Oct 2020
@gilmotta
See https://github.com/tensorflow/models/issues/8892#issuecomment-677849457
vighneshbirodkar
on 26 Oct 2020
@vighneshbirodkar Sorry to bother you but the checkpoint folder and my_model dir are both empty like you said in #8892 .
My folders are as follows:
Config filer:
{'/content/driving-object-detection/models/tf2/centernet_hg104_1024x1024_coco17_tpu-32/pipeline.config'}
My Model folder:
{'/content/driving-object-detection/training/'} (empty)
Checkpoint folder:
{''/content/driving-object-detection/models/tf2/centernet_hg104_1024x1024_coco17_tpu-32/checkpoint'} (empty)
fine_tune_checkpoint: "/content/driving-object-detection/models/tf2/centernet_hg104_1024x1024_coco17_tpu-32/checkpoint"
fine_tune_checkpoint_type: "detection"
fine_tune_checkpoint_version: V2
But I am getting the following error message:
ValueError: Couldn't find 'checkpoint' file or checkpoints in given directory /content/driving-object-detection/models/tf2/centernet_hg104_1024x1024_coco17_tpu-32/checkpoint
gilmotta
on 27 Oct 2020
I had the same problem. Changing fine_tune_checkpoint_type: "classification" to fine_tune_checkpoint_type: "detection" in the config file, solved my problem. After solving the above problem, training job work but my model did not converge so I decreased the leraning_rate and momentum. After decreasing the learning_rate and momentum my model converged.
fine_tune_checkpoint_type: "detection"
NOTE: If you got a resource exhausted error (OOM error) decrease the batch_size in the config file.
NOTE: If you use TensorFlow 2 make sure that you are using the config files inside the configs/tf2 directory.
The final config file is like below:
```
SSD with Resnet 50 v1 FPN feature extractor, shared box predictor and focal
loss (a.k.a Retinanet).
See Lin et al, https://arxiv.org/abs/1708.02002
Trained on COCO, initialized from Imagenet classification checkpoint
Train on TPU-8
#
Achieves 34.3 mAP on COCO17 Val
model {
ssd {
inplace_batchnorm_update: true
freeze_batchnorm: true
num_classes: 3
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
use_matmul_gather: true
}
}
similarity_calculator {
iou_similarity {
}
}
encode_background_as_zeros: true
anchor_generator {
multiscale_anchor_generator {
min_level: 3
max_level: 7
anchor_scale: 4.0
aspect_ratios: [1.0, 2.0, 0.5]
scales_per_octave: 2
}
}
image_resizer {
fixed_shape_resizer {
height: 640
width: 640
}
}
box_predictor {
weight_shared_convolutional_box_predictor {
depth: 256
class_prediction_bias_init: -4.6
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.0004
}
}
initializer {
random_normal_initializer {
stddev: 0.01
mean: 0.0
}
}
batch_norm {
scale: true,
decay: 0.997,
epsilon: 0.001,
}
}
num_layers_before_predictor: 4
kernel_size: 3
}
}
feature_extractor {
type: 'ssd_resnet50_v1_fpn_keras'
fpn {
min_level: 3
max_level: 7
}
min_depth: 16
depth_multiplier: 1.0
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.0004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
scale: true,
decay: 0.997,
epsilon: 0.001,
}
}
override_base_feature_extractor_hyperparams: true
}
loss {
classification_loss {
weighted_sigmoid_focal {
alpha: 0.25
gamma: 2.0
}
}
localization_loss {
weighted_smooth_l1 {
}
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
normalize_loc_loss_by_codesize: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
}
}
train_config: {
fine_tune_checkpoint_version: V2
fine_tune_checkpoint: "./test_data/ssd_resnet50/checkpoint/ckpt-0"
fine_tune_checkpoint_type: "detection"
batch_size: 10
sync_replicas: true
startup_delay_steps: 0
replicas_to_aggregate: 5
use_bfloat16: true
num_steps: 100000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
random_crop_image {
min_object_covered: 0.0
min_aspect_ratio: 0.4
max_aspect_ratio: 3.0
min_area: 0.5
max_area: 1.0
overlap_thresh: 0.0
}
}
optimizer {
momentum_optimizer: {
learning_rate: {
cosine_decay_learning_rate {
learning_rate_base: .0005
total_steps: 100000
warmup_learning_rate: .0001
warmup_steps: 1000
}
}
momentum_optimizer_value: 0.5
}
use_moving_average: false
}
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
}
train_input_reader: {
label_map_path: "./test_images/label_map.pbtxt"
tf_record_input_reader {
input_path: "./test_images/coco_train.record-00000-of-00001"
}
}
eval_config: {
metrics_set: "coco_detection_metrics"
use_moving_averages: false
}
eval_input_reader: {
label_map_path: "./test_images/label_map.pbtxt"
shuffle: false
num_epochs: 1
tf_record_input_reader {
input_path: "./test_images/coco_val.record-00000-of-00001"
}
}
 ali1366
on 27 Oct 2020
ali1366
on 27 Oct 2020
@gilmotta The checkpoint folder should not be empty. I never said that. It should point to the checkpoint you want to initialize from. You should set
fine_tune_checkpoint: "/path/to/pretrained/ckpt-0"
fine_tune_checkpoint_type: "detection"
fine_tune_checkpoint_version: V2
Where contents of folder /path/to/pretrained/ are
checkpoint
ckpt-0.data-00000-of-00001
cpkt-0.index
Here "/path/to/pretrained/ckpt-0" does not point to a single file, but a directory and a prefix of files to choose from. In this case, TF will understand that the checkpoint should be loaded from files cpkt-0.index and ckpt-0.data-00000-of-00001.
vighneshbirodkar
on 28 Oct 2020
@gilmotta The checkpoint folder should not be empty. I never said that. It should point to the checkpoint you want to initialize from. You should set
fine_tune_checkpoint: "/path/to/pretrained/ckpt-0" fine_tune_checkpoint_type: "detection" fine_tune_checkpoint_version: V2Where contents of folder
/path/to/pretrained/arecheckpoint ckpt-0.data-00000-of-00001 cpkt-0.indexHere
"/path/to/pretrained/ckpt-0"does not point to a single file, but a directory and a prefix of files to choose from. In this case, TF will understand that the checkpoint should be loaded from filescpkt-0.indexandckpt-0.data-00000-of-00001.
thank you, I am still debugging my issue. Like I said my folder structure works with other models. "centernet_hg104_1024x1024_coco17_tpu-32" is the only one giving me grief!
gilmotta
on 28 Oct 2020
@ali1366 Thank you! I am looking into your suggestions.
gilmotta
on 28 Oct 2020
@gilmotta
Hey, thanks for the help! I am still having the same issue, even though i setup everything as described:
fine_tune_checkpoint: "/XXX/XX/XX/models/research/object_detection/centernet_hg104_512x512_coco17_tpu-8/checkpoint/ckpt-0"
num_steps: 10
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
fine_tune_checkpoint_type: "detection"
fine_tune_checkpoint_version: V2
This is the folder structure:
This is the error:
W1112 09:25:02.748407 4558241216 util.py:150] Unresolved object in checkpoint: (root).model._feature_extractor._network.hourglass_network.1.inner_block.0.inner_block.0.inner_block.0.inner_block.0.decoder_block.1.skip.norm.moving_variance
WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
W1112 09:25:02.748445 4558241216 util.py:158] A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
 sajadghawami
on 12 Nov 2020
sajadghawami
on 12 Nov 2020
@sajadghawami
As I mentioned in https://github.com/tensorflow/models/issues/8892#issuecomment-671983240
For center net while using pretrained models you need to set fine_tune_checkpoint_type: "fine_tune"
vighneshbirodkar
on 12 Nov 2020
@gilmotta
For Center Net pre trained models please see
https://github.com/tensorflow/models/issues/8892#issuecomment-671983240
vighneshbirodkar
on 12 Nov 2020
@vighneshbirodkar
Thanks for the quick reply!
I am still getting the same error with this config:
fine_tune_checkpoint: "/XXX/xx/xx/machinelearning/models/research/object_detection/centernet_hg104_512x512_coco17_tpu-8/checkpoint/ckpt-0"
num_steps: 10
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
fine_tune_checkpoint_type: "fine_tune"
fine_tune_checkpoint_version: V2
This is the error:
WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
W1112 14:31:34.511536 4565011904 util.py:158] A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
WARNING:tensorflow:From /XXX/xxx/.pyenv/versions/3.7.4/lib/python3.7/site-packages/tensorflow/python/util/deprecation.py:574: calling map_fn_v2 (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Use fn_output_signature instead
W1112 14:31:54.515602 123145355005952 deprecation.py:506] From /XXX/xxx/.pyenv/versions/3.7.4/lib/python3.7/site-packages/tensorflow/python/util/deprecation.py:574: calling map_fn_v2 (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Use fn_output_signature instead
In the https://github.com/tensorflow/models/issues/8892#issuecomment-671983240 you mention that hourglass supports detection, but it does not. Neither does fine_tune...
I am a little bit confused now :D
sajadghawami
on 12 Nov 2020
@sajadghawami That is just a warning. If you notice the script still continues executing beyond the checkpoint warning. It is happening because inside that checkpoint there are some variables which are not loaded. For example, weights in the classification layer or the optimizer related variables. If your training fails, there must be some other error that is reported later on.
Both detection and fine_tune should work
detection -> For the ExtremeNet CenterNet checkpoint
fine_tune -> For the other CenterNet based checkpoints.
vighneshbirodkar
on 12 Nov 2020
@vighneshbirodkar
ah i see! thank you very much!... Oddly enough, i am seeing a training result:
But the CLI does not show whether or not it's training, which is weird combined with the warnings mentioned above.
This is the command i am using:
python model_main_tf2.py \
--pipeline_config_path=training/centernet_hg104_512x512_coco17_tpu-8.config \
--model_dir=result/ \
--logtostderr
The last output in the CLI is this:
W1112 15:12:56.441341 4649586112 util.py:150] Unresolved object in checkpoint: (root).model._prediction_head_dict.box/offset.1.layer_with_weights-1.bias
WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
W1112 15:12:56.441509 4649586112 util.py:158] A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
WARNING:tensorflow:From /Users/gilga/.pyenv/versions/3.7.4/lib/python3.7/site-packages/tensorflow/python/util/deprecation.py:574: calling map_fn_v2 (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Use fn_output_signature instead
W1112 15:13:13.530333 123145586790400 deprecation.py:506] From /Users/gilga/.pyenv/versions/3.7.4/lib/python3.7/site-packages/tensorflow/python/util/deprecation.py:574: calling map_fn_v2 (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Use fn_output_signature instead
And then it just... stops. No output about the learning.
sajadghawami
on 12 Nov 2020
@sajadghawami There might be no logs because you only train for 10 steps and the log is only printed every 100 steps. Can you set num_steps: 1000 and wait for about 15-20 mins to see what happens ?
vighneshbirodkar
on 12 Nov 2020
@vighneshbirodkar
yeah you were right! I was training for only ten steps to see if the config works at all.
It does, and i am getting an output.
Thank you very much! :)
sajadghawami
on 12 Nov 2020
@vighneshbirodkar Thanks for your help. I'm up and running. The training and fine_tuned folders must start empty. I'm saving all of my files to Google Drive during training and I'm able to resume where it left off.
gilmotta
on 17 Nov 2020
Training failed when I tried to load checkpoint from model root folder. When I moved them to separate folder within model root folder and updated fine_tune_checkpoint accordingly, training process started. Warning, that not all checkpoint values were used, is still present.
 maesaer
on 17 Nov 2020
maesaer
on 17 Nov 2020
I think, wether or not you put the stuff in the right folder does not belong here...
As stated before, what concerns me more are these errors:
W1116 17:25:29.473061 140110117582720 util.py:150] Unresolved object in checkpoint: (root).model._groundtruth_lists
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._box_predictor
W1116 17:25:29.473445 140110117582720 util.py:150] Unresolved object in checkpoint: (root).model._box_predictor
WARNING:tensorflow:Unresolved object in checkpoint: (root).model._batched_prediction_tensor_names
And when create the inference graph with exporter_main_v2.py i get the following:
WARNING:tensorflow:Skipping full serialization of Keras layer <object_detection.meta_architectures.ssd_meta_arch.SSDMetaArch object at 0x146b525f8>, because it is not built.
W1116 21:18:20.631738 4644916672 save_impl.py:78] Skipping full serialization of Keras layer <object_detection.meta_architectures.ssd_meta_arch.SSDMetaArch object at 0x146b525f8>, because it is not built.
WARNING:tensorflow:Skipping full serialization of Keras layer <tensorflow.python.keras.layers.convolutional.SeparableConv2D object at 0x1474de860>, because it is not built.
A whole bunch of these errors, and then:
W1116 21:18:21.347824 4644916672 save_impl.py:78] Skipping full serialization of Keras layer <tensorflow.python.keras.layers.core.Lambda object at 0x14777b588>, because it is not built.
2020-11-16 21:18:29.002420: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Unsupported signature for serialization: (([(<tensorflow.python.framework.func_graph.UnknownArgument object at 0x14b8376d8>, TensorSpec(shape=(None, 80, 80, 32), dtype=tf.float32, name='image_features/0/1')), (<tensorflow.python.framework.func_graph.UnknownArgument object at 0x14b837748>, TensorSpec(shape=(None, 40, 40, 96), dtype=tf.float32, name='image_features/1/1')), (<tensorflow.python.framework.func_graph.UnknownArgument object at 0x14b837a58>, TensorSpec(shape=(None, 20, 20, 1280), dtype=tf.float32, name='image_features/2/1'))], False), {}).
I could not try out that model yet to validate if this error can simply be ignored.
sajadghawami
on 17 Nov 2020
Having to manually update the continuation checkpoint is a pain in the ass. I wish it worked like TF 1.x and picked up the latest one automatically.
turowicz
on 19 Nov 2020
@turowicz I am not sure what you are referring to, the TF2 binary also picks up the latest checkpoint automatically.
vighneshbirodkar
on 19 Nov 2020
@vighneshbirodkar you are literally the person who wasn't able to help me fix it here: https://github.com/tensorflow/models/issues/9229#issuecomment-716793855
If you know how to make it pick up the most recent automatically on restart I will be very greatful.
turowicz
on 19 Nov 2020
@turowicz Oh yeah, sorry, I didn't make that connection. It seems it is only restricted to EfficientDet. We are still working on ironing out some bugs in the EfficientDet training setup and don't have a fix yet.
vighneshbirodkar
on 19 Nov 2020
ah OK I understand.
turowicz
on 19 Nov 2020
@turowicz i am using MobileNetV2 and it picks it up without problems...
sajadghawami
on 19 Nov 2020
@vighneshbirodkar I am having the same issue using EfficientDet. Although, having set the checkpoints and checkpoint type as "detection"
 Rishav-hub
on 1 Dec 2020
Rishav-hub
on 1 Dec 2020
What problem are you referring to ? If you are getting the same message as what's mentioned in the title it is just a warning and can be ignored. If you training is not resuming correctly as @turowicz mentions, we don't have a fix yet.
vighneshbirodkar
on 1 Dec 2020
This is all OK, the problem should only exist for EfficientNet
turowicz
on 2 Dec 2020
This is all OK, the problem should only exist for EfficientNet
Yeah I am having it with EfficientDet
Rishav-hub
on 2 Dec 2020
I ran into this situation as well, but I found a thing is that if I change the num_steps in the config file to a larger number than I set before, like I first trained it with 3000 and then I changed to 3500, it does resume training. If I didn't change the value, it always stops with the same message '**A checkpoint was restored ...'. Will keep looking into this.
 escrowdis
on 5 Dec 2020
escrowdis
on 5 Dec 2020
@escrowdis I am not sure exactly what you are doing but num_steps is the total numbers of steps. If you set num_steps to 3000 steps and train for 2000 steps, after resuming the model will only train for a 1000 more steps. If you set num_steps to 3000 and try to resume training after training for 3000 steps, the training code will exit without doing any training.
vighneshbirodkar
on 5 Dec 2020
@escrowdis I am not sure exactly what you are doing but
num_stepsis the total numbers of steps. If you setnum_stepsto 3000 steps and train for 2000 steps, after resuming the model will only train for a 1000 more steps. If you setnum_stepsto 3000 and try to resume training after training for 3000 steps, the training code will exit without doing any training.
Hi @vighneshbirodkar,
Thank you for your prompt reply. Sorry I'm newbie to this and I think that's what I to say. Because I couldn't tell from the provided message that is my command or script incorrect or does it already complete the training with the specified steps. I found this conversation and thought it's related.
...
WARNING:tensorflow:Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.6.0.1.0.bias
W1205 22:39:53.164153 140311875868544 util.py:150] Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.6.0.1.0.bias
WARNING:tensorflow:Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.6.0.1.1.gamma
W1205 22:39:53.164235 140311875868544 util.py:150] Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.6.0.1.1.gamma
WARNING:tensorflow:Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.6.0.1.1.beta
W1205 22:39:53.164330 140311875868544 util.py:150] Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.6.0.1.1.beta
WARNING:tensorflow:Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.0.kernel
W1205 22:39:53.164407 140311875868544 util.py:150] Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.0.kernel
WARNING:tensorflow:Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.0.bias
W1205 22:39:53.164493 140311875868544 util.py:150] Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.0.bias
WARNING:tensorflow:Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.1.gamma
W1205 22:39:53.164572 140311875868544 util.py:150] Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.1.gamma
WARNING:tensorflow:Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.1.beta
W1205 22:39:53.164649 140311875868544 util.py:150] Unresolved object in checkpoint: (root).optimizer's state 'momentum' for (root).model._feature_extractor._bifpn_stage.node_input_blocks.7.0.1.1.beta
WARNING:tensorflow:A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
W1205 22:39:53.164726 140311875868544 util.py:158] A checkpoint was restored (e.g. tf.train.Checkpoint.restore or tf.keras.Model.load_weights) but not all checkpointed values were used. See above for specific issues. Use expect_partial() on the load status object, e.g. tf.train.Checkpoint.restore(...).expect_partial(), to silence these warnings, or use assert_consumed() to make the check explicit. See https://www.tensorflow.org/guide/checkpoint#loading_mechanics for details.
Also have a question want to clear if anyone has the time, thanks.
Do I have to change the path of fine_tune_checkpoint if I want to resume the training?
I transfer learn a pretrained model using the below command. If the session was interrupted on Colab, I should have some checkpoint files (checkpoint, chkp-x.index, and ckpt-x.data-xxxxxxx) in the folder 'aaa/model/model_name'. If I want to resume the training with the same command, should I change the value of fine_tune_checkpoint from aaa/pretrained/model_name/checkpoint/ckpt-0 to aaa/model/model_name/ckpt-x? Or the script will detect the latest checkpoint automatically?
! python model_main_tf2.py \
--alsologtostderr \
--model_dir=aaa/model/model_name \
--pipeline_config_path="aaa/pretrained/model_name/pipeline.config"
# in the pipeline.config
fine_tune_checkpoint: "aaa/pretrained/model_name/checkpoint/ckpt-0"
Thanks!
escrowdis
on 5 Dec 2020
@escrowdis No, to resume training you have to run the exact same command with the same config. The training script will use the latest checkpoint files instead of the fine tune checkpoint.
vighneshbirodkar
on 6 Dec 2020
Good to know that, thank you so much!
escrowdis
on 6 Dec 2020
@vighneshbirodkar what is the difference btw detection and classification here? On reading train.proto, it seems that in detection task, the meta architecture (feature extractors)weights are not changed. So how is the transfer learning occuring here? only on the box predictors?
 dragonnikkirocks
on 8 Dec 2020
dragonnikkirocks
on 8 Dec 2020
Related issues
 sun9700
·
3Comments
sun9700
·
3Comments
 dsindex
·
3Comments
dsindex
·
3Comments
 hanzy123
·
3Comments
hanzy123
·
3Comments
 rakashi
·
3Comments
rakashi
·
3Comments
 nmfisher
·
3Comments
nmfisher
·
3Comments
Most helpful comment
I was able to get passed this error by changing the
fine_tune_checkpoint_typeto "detection"UPDATE: I'm running this training on Colab and I keep getting memory allocation issues. I had to resort to running with a batch_size of 1....
Any suggestions?