Models: multiple image inference for mask-rcnn runs ~10x slower than faster-rcnn for the same image size
System information
- What is the top-level directory of the model you are using: object_detection
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): Yes
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Mint 18.3 Sylvia
- TensorFlow installed from (source or binary): binary
- TensorFlow version (use command below): 1.10.1
- Bazel version (if compiling from source): N/A
- CUDA/cuDNN version: V9.2.148/7.1.4
- GPU model and memory: Quadro GV100 32 GiB
- Exact command to reproduce:
Describe the problem
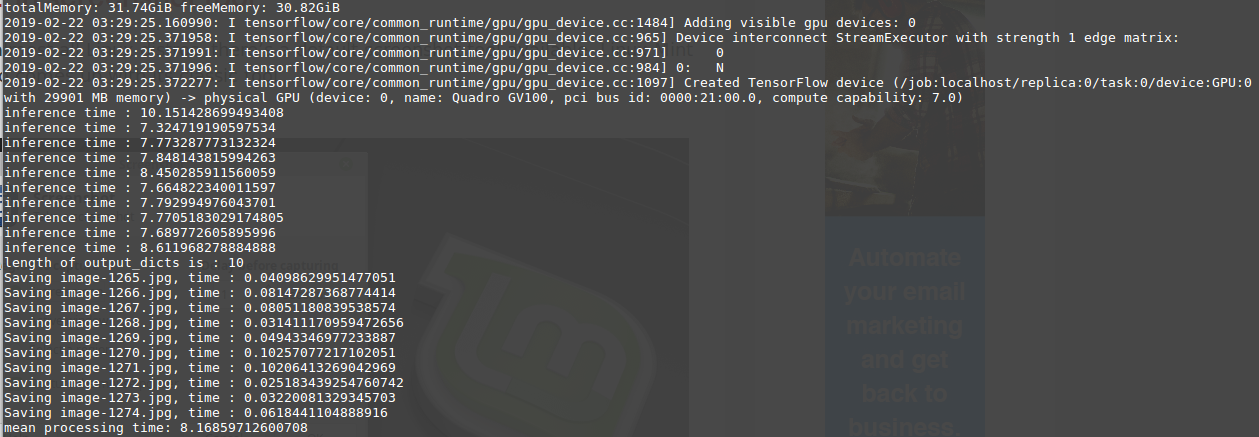
I successfully retrained mask-rcnn and faster-rcnn models with my own custom dataset and I want to run inference for multiple images. I modified the single image inference function from the demo with the code below. I got the following result if I used retrained faster-rcnn resnet101

and the following result if I used retrained mask-rcnn resnet101
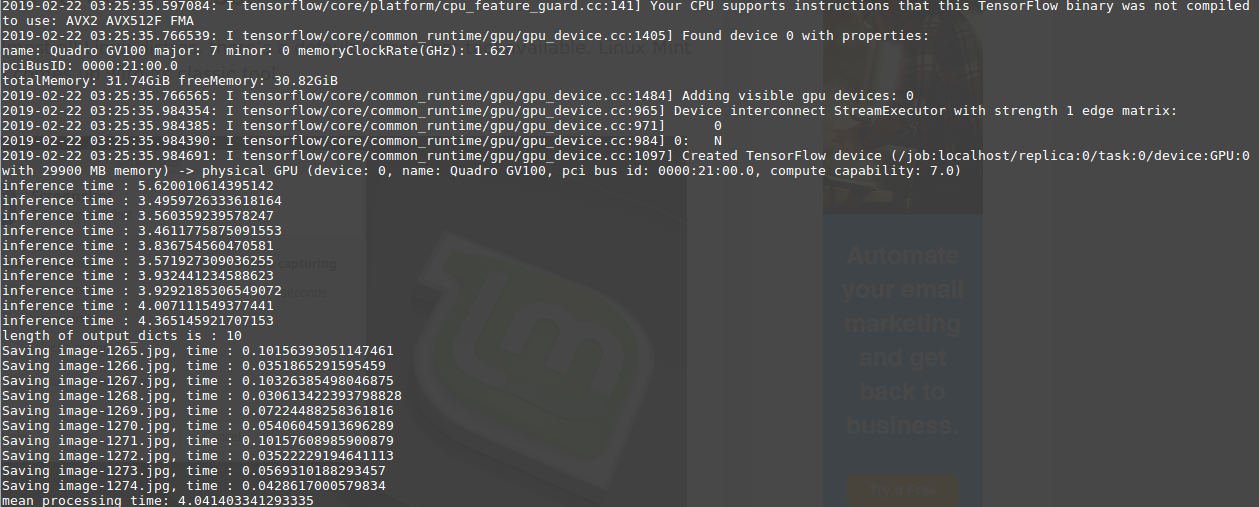
The following if I run with faster-rcnn inception-resnet
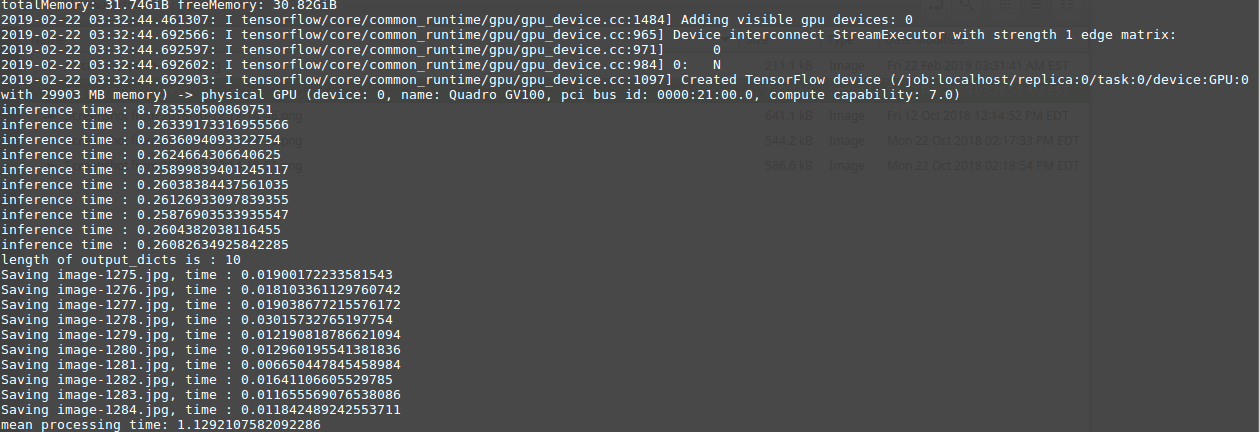
and the following with mask-rcnn inception-resnet
All images have resolution of 1024x768. Please help whether this is the right behavior or not. Thanks
Source code / logs
def run_inference_for_multiple_images(images, graph):
with graph.as_default():
with tf.Session() as sess:
output_dict_array = []
dict_time = []
for image in images:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
start = time.time()
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: np.expand_dims(image, 0)})
end = time.time()
print('inference time : {}'.format(end-start))
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
output_dict_array.append(output_dict)
dict_time.append(end-start)
return output_dict_array, dict_time
the following is the code to run the function
subdir_path = os.path.join(PATH_TO_TEST_IMAGES_DIR, path)
(_, _, filenames) = next(os.walk(subdir_path))
# Listing the result images
result_img_path = os.path.join(PATH_TO_RESULT_IMAGES_DIR, path + mod)
if not os.path.exists(result_img_path):
os.makedirs(result_img_path)
(_, _, filenames_result) = next(os.walk(result_img_path))
batch_size = 10
chunks = len(diff_files) // batch_size + 1
ave_time = []
for i in range(chunks):
batch = diff_files[i*batch_size:(i+1)*batch_size]
images = []
files = []
proc_time = []
for file in batch:
image_path = os.path.join(subdir_path, file)
print('Reading file {}'.format(image_path))
image = cv2.imread(image_path)
image_np = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
images.append(image_np)
files.append(file)
output_dicts, out_time = run_inference_for_multiple_images(images, detection_graph)
print('length of output_dicts is : {}'.format(len(output_dicts)))
if len(output_dicts) == 0:
break
for idx in range(len(output_dicts)):
output_dict = output_dicts[idx]
image_np = images[idx]
file = files[idx]
# Visualization of the results of a detection.
start = time.time()
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks'),
use_normalized_coordinates=True, min_score_thresh=.5,
line_thickness=4, skip_scores=False,
skip_labels=False,
skip_boxes=False)
height, width, chan = image_np.shape
# Saving the processed image
image_np = cv2.cvtColor(image_np, cv2.COLOR_RGB2BGR)
cv2.imwrite(os.path.join(result_img_path, file), image_np)
print('Saving {}, time : {}'.format(file, time.time()-start))
proc_time.append(time.time()-start + out_time[idx])
# count += 1
# SAVING BOUNDING BOX AND CONFIDENCE RATE
boxes = output_dict['detection_boxes']
classes = output_dict['detection_classes']
scores = output_dict['detection_scores']
if len(proc_time) != 0:
mean_batch_time = statistics.mean(proc_time)
print('mean processing time: {}'.format(mean_batch_time))
ave_time.append(mean_batch_time)
proc_time.clear()
output_dicts.clear()
 ronykalfarisi
ronykalfarisi
All 14 comments
I somewhat figured out the problem, but have yet to figure out how to fix it.
if 'detection_masks' in tensor_dict: is the issue. Only my mask models have this. I think we have to reuse the code under this as it's making a new graph (or something similar).
 buroa
on 28 Mar 2019
buroa
on 28 Mar 2019
Hi @buroa thanks for joining. I'm sorry I can't reply to your comment soon since I was very busy.
I don't think that is the problem since if 'detection_masks' in tensor_dict only check whether the key detection_mask is in the dictionary or not. I also did another test on mrcnn inference with the same set of images but difference resolution (batch size of 5). The following is what I found when I did the inference using original size which is 6000x4000
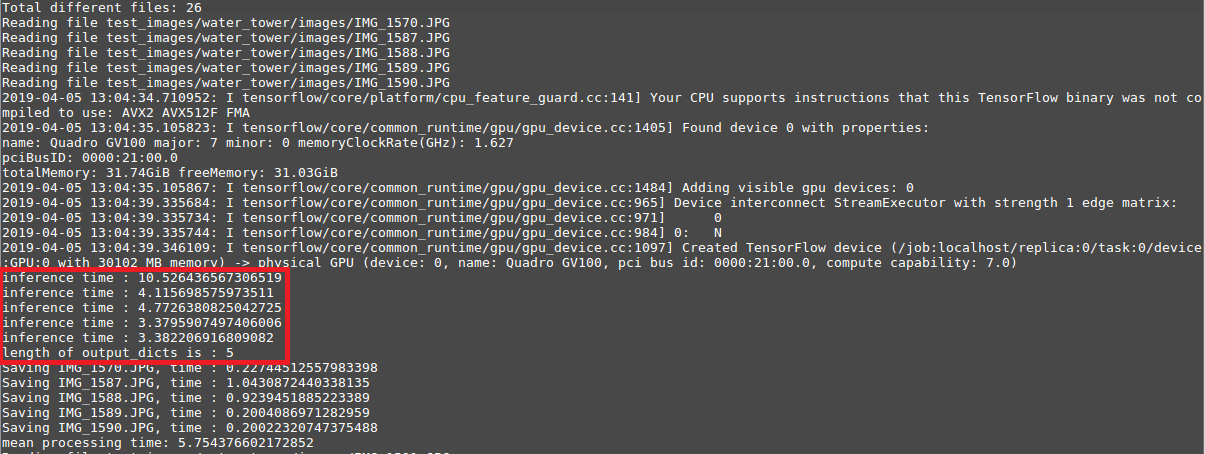
and the following is what I found using resized size of 1024x682

As we can see, the inference time is the same even after the reduction of pixel counts by ~36x
ronykalfarisi
on 5 Apr 2019
Same problem here. Although I have moved "with tf.Session() as sess:" out of the inference function as mentioned in:
https://github.com/tensorflow/models/issues/4355#issuecomment-437536894
the speed is still really slow when running mask rcnn model. Have no idea what's going on.
 Ekko1992
on 9 Apr 2019
Ekko1992
on 9 Apr 2019
Hi @Ekko1992 , can you tell the timing for your mask-rcnn inference? It would be better if the batch size is bigger than one, since the first image will take a lot of time due to the system setting up the resources. Thanks
ronykalfarisi
on 10 Apr 2019
@ronykalfarisi it's about 3-4s per image, just the same as yours. By the way, I'm using Tesla p100 GPU card. According to the official guide, it seems that mask-rcnn with resnet-101 backbone indeed runs slow even on Titan XP(which is 470ms), but I don't think telsa p100 runs 7-8 times slower than Titan XP.
Ekko1992
on 10 Apr 2019
Hi @Ekko1992, this proves my suspicion. As you can see in the beginning of the post, my GPU is Quadro GV100 32 GiB, the best GPU (and the most expensive) currently in the market. However, we got the same result. Therefore, we can conclude that there must be something wrong with the code. It would be nice if some of TF developers can chime in for some discussion.
ronykalfarisi
on 10 Apr 2019
@ronykalfarisi Have you soved it? I met the same problem.
 stq054188
on 5 May 2019
stq054188
on 5 May 2019
@stq054188 solve the issue by moving tensor_dict gathering operations at a preprocess part of inference script.
 DLegushev
on 5 May 2019
DLegushev
on 5 May 2019
Hi @DLegushev , it would be nice if you could share your solutions. The function(s) and how to call it (them). Or you could share the code through GitHub. Thanks
ronykalfarisi
on 5 May 2019
Hi, @ronykalfarisi. Try to move this part of your code outside of cycle for image in images
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
May be it helps you.
DLegushev
on 5 May 2019
@DLegushev & @ronykalfarisi It seems not to improve. Has anyone solved this problem? I'm really in a hurry. Thank you in advance.
stq054188
on 6 May 2019
@stq054188 , The solution of @DLegushev is correct. I made the changes and the inference time using resnet50 as feature extractor reduced from 3-4 seconds per image to 0.3-0.4 seconds per image. The following is the function I use
def run_inference_for_multiple_images(images, graph):
with graph.as_default():
with tf.Session() as sess:
output_dict_array = []
dict_time = []
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in ['num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks']:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(tensor_name)
if 'detection_masks' in tensor_dict:
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, images[0].shape[0], images[0].shape[1])
detection_masks_reframed = tf.cast(tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
for image in images:
# Run inference
start = time.time()
output_dict = sess.run(tensor_dict, feed_dict={image_tensor: np.expand_dims(image, 0)})
end = time.time()
print('inference time : {}'.format(end - start))
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict['detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
output_dict_array.append(output_dict)
dict_time.append(end - start)
return output_dict_array, dict_time
You must be careful when using this function because the assumption taken when using batch size image is all of the images must have the same size. Therefore, there would be an error thrown when one of the image in the batch has different sizes. Though I haven't confirmed this myself.
ronykalfarisi
on 6 May 2019
@ronykalfarisi Can you share your full code for my testing, thanks.
stq054188
on 6 May 2019
@stq054188 , sure. I just uploaded the code into my GitHub profile.
ronykalfarisi
on 6 May 2019
Related issues
 rakashi
·
3Comments
rakashi
·
3Comments
 airmak
·
3Comments
airmak
·
3Comments
 amirjamez
·
3Comments
amirjamez
·
3Comments
 chenyuZha
·
3Comments
chenyuZha
·
3Comments
 XavDCtpz
·
3Comments
XavDCtpz
·
3Comments
Most helpful comment
Hi, @ronykalfarisi. Try to move this part of your code outside of cycle
for image in imagesMay be it helps you.