Models: A more comprehensive documentation for training a model locally (using model_main.py)
Hello everyone,
I have been using the train.py code for training various object detection models. That code was pretty straightforward and the outputs were quite self-explanatory (the code outputted loss values). Now, as far as I have understood, in the new release of Object Detection API (July 13), train.py has moved to legacy and for training a model locally, one must use model_main.py. Unfortunately, I can't really understand the training process in this code. Here are my problems (in training an SSD model on a custom dataset):
1- The code performs evaluation no matter what! I tried to set the parameters max_evals and eval_interval_secs, but they don't seem to be used at all. So, to get around this, I made a small dataset, with only 6 images, to make the evaluation time as low as possible! I really don't want the code to perform any evaluation at all.
2- The are no "Loss/classification_loss", "Loss/localization_loss" or "Loss/total_loss" available in tensorboard for the training process, though they are there for evaluation:
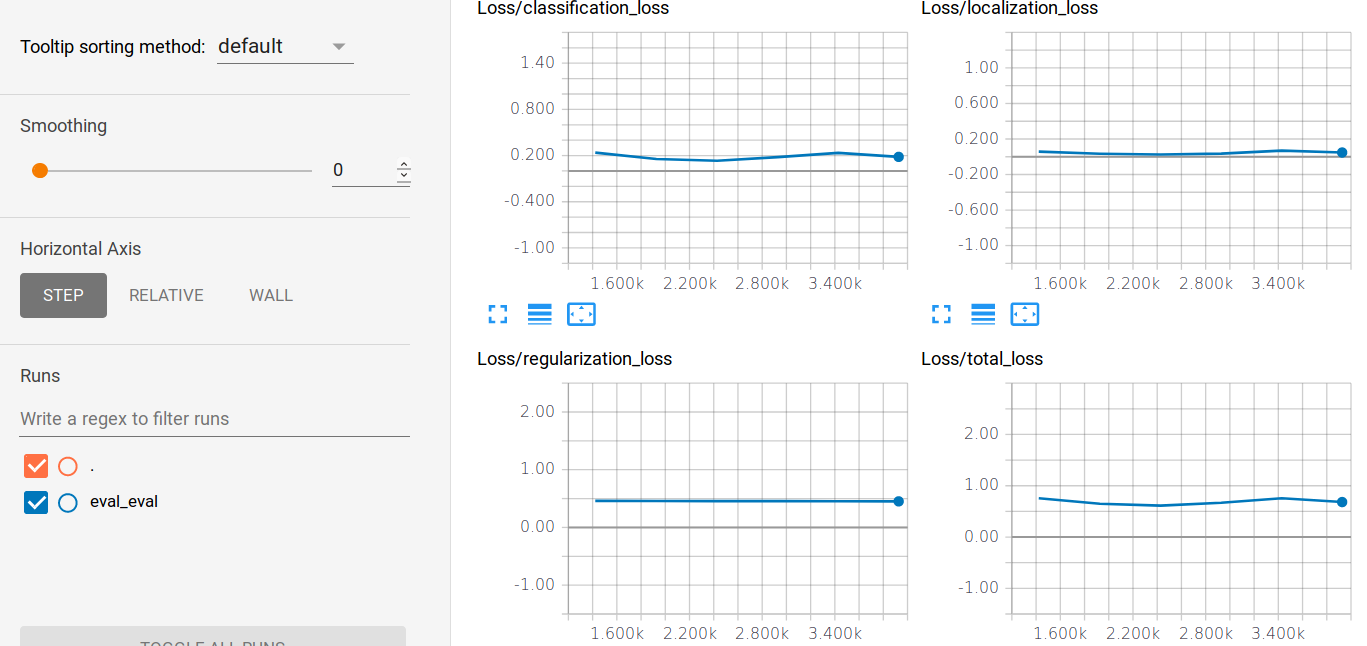
The only thing I see for training is loss1 and loss2 which are exactly the same:
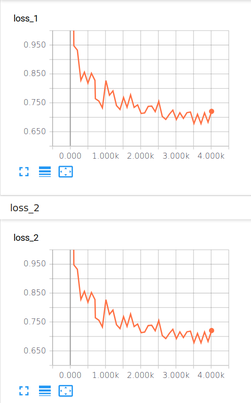
3- During the training process a huge number of lines such as these are displayed before every evaluation:
WARNING:tensorflow:Ignoring ground truth with image id 427235694 since it was previously added
WARNING:tensorflow:Ignoring detection with image id 427235694 since it was previously added
WARNING:tensorflow:Ignoring ground truth with image id 968669325 since it was previously added
WARNING:tensorflow:Ignoring detection with image id 968669325 since it was previously added
WARNING:tensorflow:Ignoring ground truth with image id 1298836725 since it was previously added
WARNING:tensorflow:Ignoring detection with image id 1298836725 since it was previously added
I really have no idea what could these mean!
System information
- What is the top-level directory of the model you are using: models-master/research/object_detection
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): No
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 18.04
- TensorFlow installed from (source or binary): From source
- TensorFlow version (use command below): 1.10.0
- Bazel version (if compiling from source): 0.16.0
- CUDA/cuDNN version: 9.2/7.1
- GPU model and memory: Geforce GTX 1070 8GB
- Exact command to reproduce:
# From the tensorflow/models/research/ directory
PIPELINE_CONFIG_PATH={path to pipeline config file}
MODEL_DIR={path to model directory}
NUM_TRAIN_STEPS=50000
NUM_EVAL_STEPS=2000
python object_detection/model_main.py \
--pipeline_config_path=${PIPELINE_CONFIG_PATH} \
--model_dir=${MODEL_DIR} \
--num_train_steps=${NUM_TRAIN_STEPS} \
--num_eval_steps=${NUM_EVAL_STEPS} \
--alsologtostderr
Describe the problem
Well, I pretty much described the problem above.
 szm-R
szm-R
All 17 comments
Hi @szm2015 , I'm also training a SSD_mobile model with the new api. As your tensorboard tell you the ckpt result, I assume your training procedure works (i.e. the model_main.py works). I think you should double check your tfrecord file if the loss doesn't change. Also remember check your config file and make sure you are using the right class number.
check this for further instruction about how to train a model on customized dataset:
https://github.com/tensorflow/models/tree/master/research/object_detection/g3doc
 nomadseed
on 16 Aug 2018
nomadseed
on 16 Aug 2018
Thank you for your response. I am sure of the TFrecord file, as I have trained several other models with it (all of them, of course, were trained using the old release). As you see the training loss is decreasing, but my question is why there is no classification and localization loss as it used to be and it's just plain loss?! The blue loss that seems constant is the evaluation one which is, likely, being calculated on the very small, dummy validation set I explained about and so doesn't matter to me at all.
szm-R
on 16 Aug 2018
Does num_examples in your config file match the number of validation samples in your TFrecord? I've seen the same warnings when num_examples is greater.
 xrz000
on 17 Aug 2018
xrz000
on 17 Aug 2018
You are right, num_examples does not match the number of images in my
TFrecord file! thank you.
On Fri, Aug 17, 2018 at 7:11 AM, xrz000 notifications@github.com wrote:
Does num_examples in your config file match the number of validation
samples in your TFrecord? I've seen the same warnings when num_examples is
greater.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/tensorflow/models/issues/5112#issuecomment-413741219,
or mute the thread
https://github.com/notifications/unsubscribe-auth/APaJX0TFHbGweOsJGxixb6JQMj-8TolYks5uRi1igaJpZM4WAUyZ
.
szm-R
on 17 Aug 2018
same problem. I need to set num_examples to 1449 (default 8000 for coco) for pascal voc 2012 dataset.
 junweima
on 1 Sep 2018
junweima
on 1 Sep 2018
Hi,could someone kindly to tell me what does the loss1 ,loss2 means ?
 swg209
on 17 Sep 2018
swg209
on 17 Sep 2018
Hi,could someone kindly to tell me what does the loss1 ,loss2 means ?
Same for learning_rate and learning_rate_1 - what are these?
 yangsiyu007
on 18 Sep 2018
yangsiyu007
on 18 Sep 2018
I have this exact confusion as well. Have you figured any thing out?
 jtavrisov
on 30 Oct 2018
jtavrisov
on 30 Oct 2018
Hi guys, I have the same questions, what are loss1 and loss2? And for that matter, all the other metrics tracked on tensorboard? Also, currently I can only see one image on tensorobard under images, do you know how I can see more?
 lucaruzzola
on 10 Jan 2019
lucaruzzola
on 10 Jan 2019
I wanna add that I would very much like to have metrics on the training set too and that there is currently not enough documentation, we should collectively try to write some, I am available to help for the little experience that I have if someone wants to do this.
lucaruzzola
on 10 Jan 2019
Any update on this question? Has anyone understood the meaning of all the plots in the new API tensorboard?
 freelist
on 12 Feb 2019
freelist
on 12 Feb 2019
same, model_main doesn't work as the now legacy train.py. it suddenly stops for me, and it's difficult to modify setting (disable evaluations, set checkpoints to keet, etc)
 JoseLuisFriedrich
on 20 Mar 2019
JoseLuisFriedrich
on 20 Mar 2019
Hi guys, I have the same questions, what are loss1 and loss2? And for that matter, all the other metrics tracked on tensorboard? Also, currently I can only see one image on tensorobard under images, do you know how I can see more?
Hi guys, I have the same questions, what are loss1 and loss2? And for that matter, all the other metrics tracked on tensorboard? Also, currently I can only see one image on tensorobard under images, do you know how I can see more?
Hello,
You can view more images in tensorboard by specifying num_visualizations: -- in eval_config under the configuration file.
eval_config: {
num_examples: 100
num_visualizations: 10
...
...
}
 ebinzacharias
on 8 Jul 2019
ebinzacharias
on 8 Jul 2019
Hi There,
We are checking to see if you still need help on this, as this seems to be considerably old issue. Please update this issue with the latest information, code snippet to reproduce your issue and error you are seeing.
If we don't hear from you in the next 7 days, this issue will be closed automatically. If you don't need help on this issue any more, please consider closing this.
 tensorflowbutler
on 30 Jan 2020
tensorflowbutler
on 30 Jan 2020
Hi there,
I have the same issue, loss_1=loss_2.
I am using tensorflow-gpu1.14.0. and I did training also using tensorflow-gpu1.15.0.
I am using model_main.py, I have 104 validation example ,so I mad num_examples: 104; all comigrations supposed to work well; but the issue still the same ( loss_1=loss_2)
 leedo-hub
on 19 Feb 2020
leedo-hub
on 19 Feb 2020
I have an issue of getting the same performance with model_main as I got with train.py. The loss seems to improve at a much slower rate using the same config file.
 thagstrom123
on 24 Aug 2020
thagstrom123
on 24 Aug 2020
I have the same issue, loss_1=loss_2. And I review my code , I think it is because I add summary for loss for two times in different way. I wrote tf.summary.scalar('loss', loss) as well as train_file = os.path.join(FLAGS.output_dir, "train.tf_record")
file_based_convert_examples_to_features(
train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file). After delete the first line , there is only one loss in tensor board.
 Berlin-98
on 3 Dec 2020
Berlin-98
on 3 Dec 2020
Related issues
 dsindex
·
3Comments
dsindex
·
3Comments
 chenyuZha
·
3Comments
chenyuZha
·
3Comments
 mbenami
·
3Comments
mbenami
·
3Comments
 licaoyuan123
·
3Comments
licaoyuan123
·
3Comments
 kamal4493
·
3Comments
kamal4493
·
3Comments
Most helpful comment
Hi,could someone kindly to tell me what does the loss1 ,loss2 means ?