Models: Using object_detection/eval.py to eval result ,but it's stuck
Please go to Stack Overflow for help and support:
http://stackoverflow.com/questions/tagged/tensorflow
Also, please understand that many of the models included in this repository are experimental and research-style code. If you open a GitHub issue, here is our policy:
- It must be a bug, a feature request, or a significant problem with documentation (for small docs fixes please send a PR instead).
- The form below must be filled out.
Here's why we have that policy: TensorFlow developers respond to issues. We want to focus on work that benefits the whole community, e.g., fixing bugs and adding features. Support only helps individuals. GitHub also notifies thousands of people when issues are filed. We want them to see you communicating an interesting problem, rather than being redirected to Stack Overflow.
System information
- What is the top-level directory of the model you are using:ea6d6aabe5c121102a645d3f08cf819fa28d2a03
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):Linux Ubuntu 16.04
- TensorFlow installed from (source or binary):binary
- TensorFlow version (use command below):tensorflow-gpu-1.7.0
- Bazel version (if compiling from source):
- CUDA/cuDNN version:CUDA:9.0/cudnn:7.0.5
- GPU model and memory:3*1080Ti/11GB
- Exact command to reproduce:
You can collect some of this information using our environment capture script:
https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh
You can obtain the TensorFlow version with
python -c "import tensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)"
Describe the problem
when i used object_detection/eval.py to eval result, it was stuck at restoring parameters
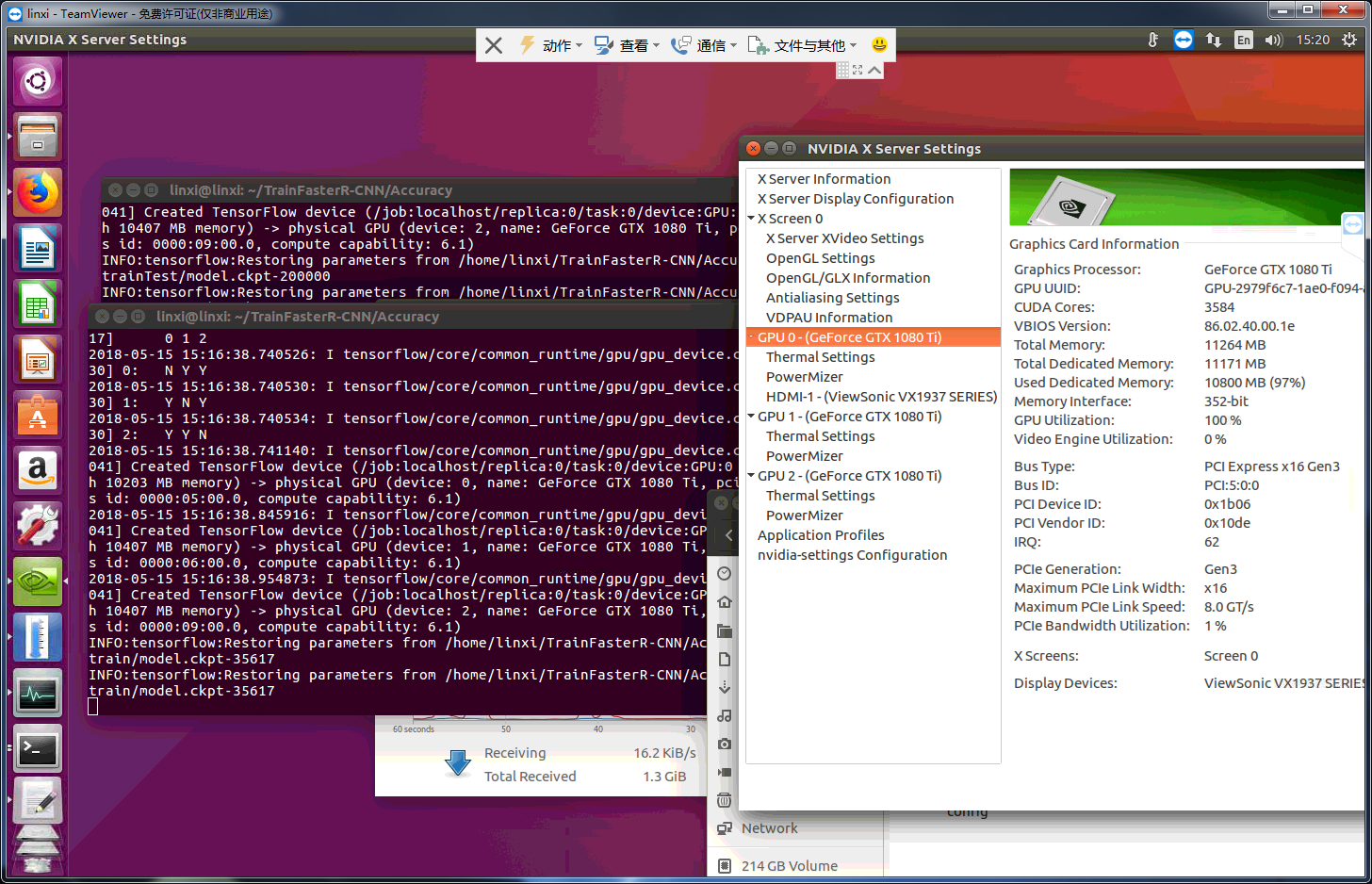
and result liked this permanently:
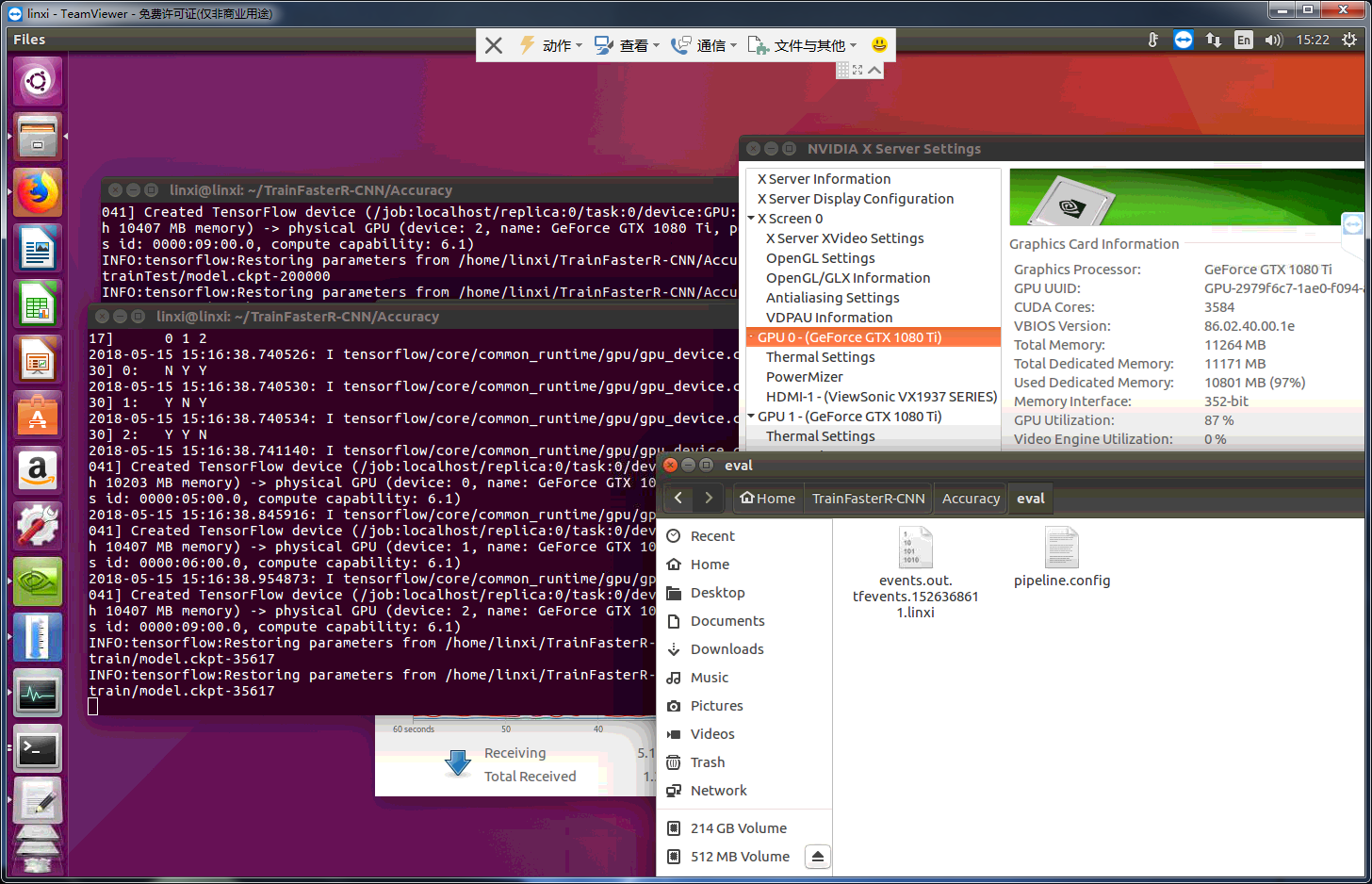
There are my parameters:
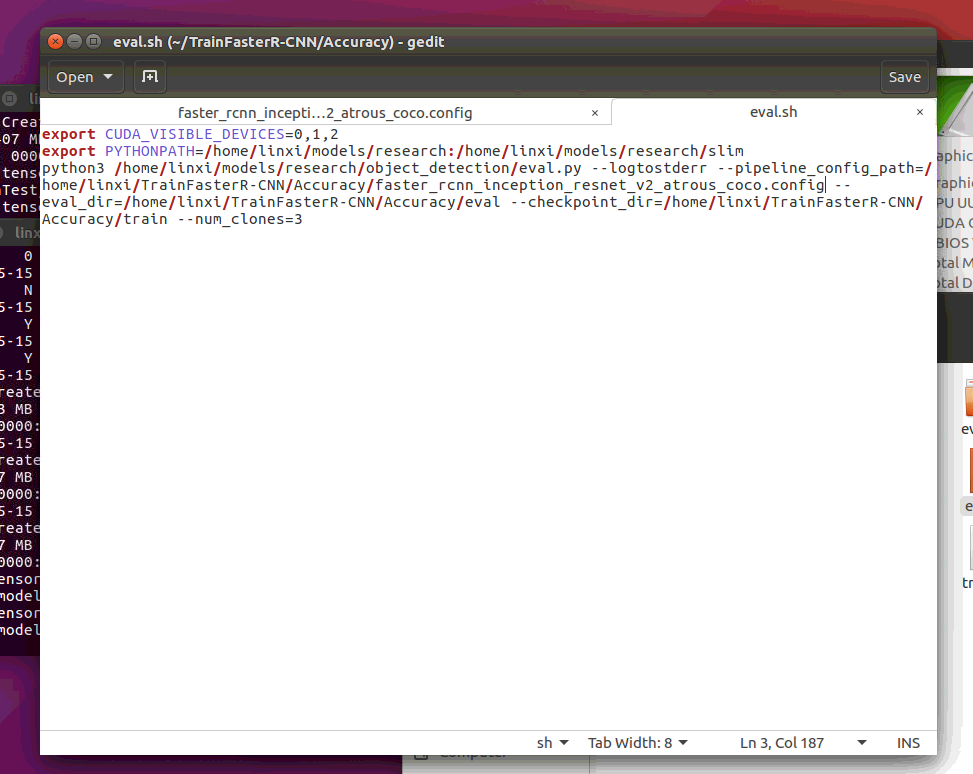
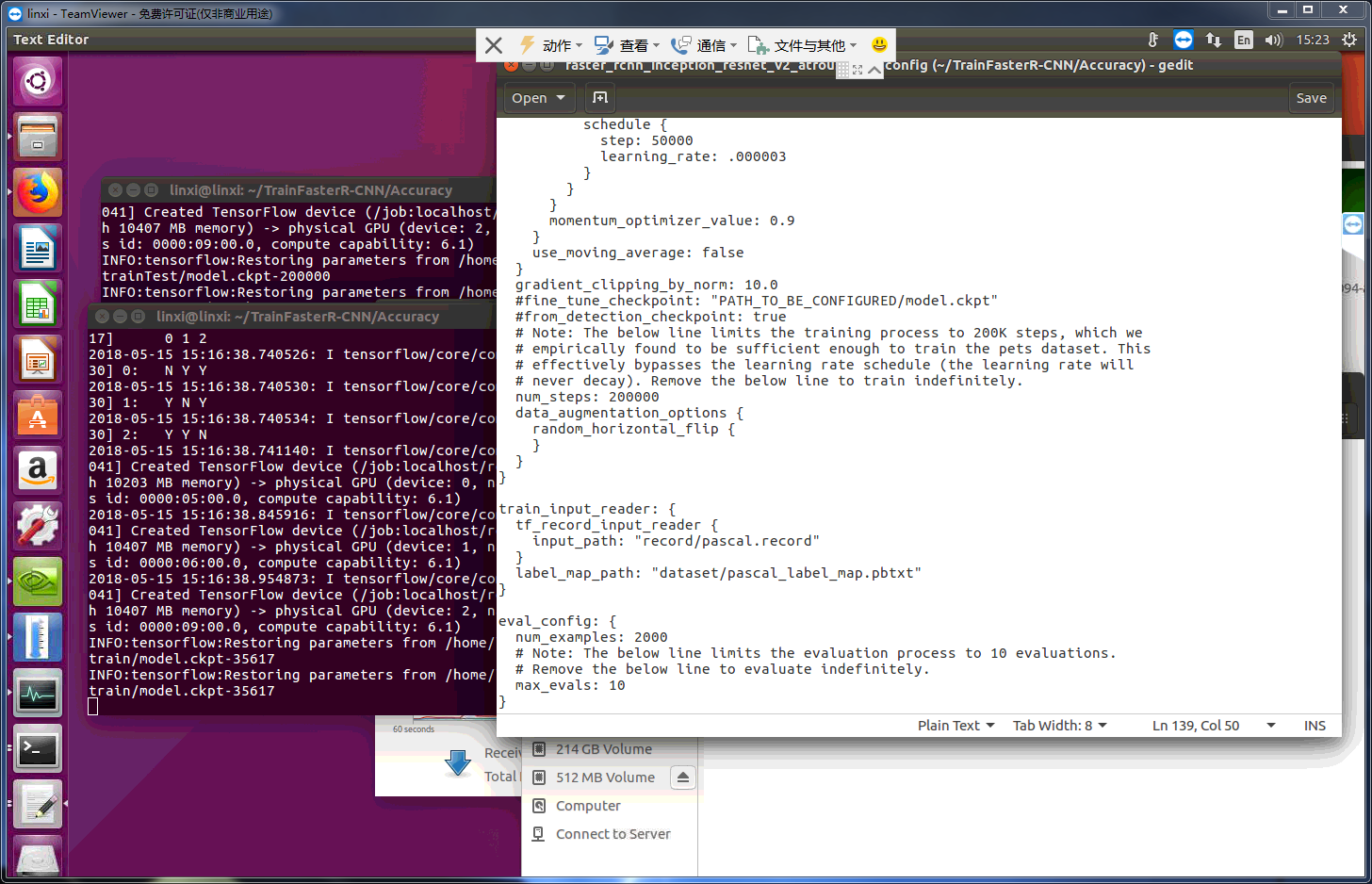
I tried different config,there were stuck.
Source code / logs
Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached. Try to provide a reproducible test case that is the bare minimum necessary to generate the problem.
 a819721810
a819721810
All 19 comments
Please share your config file since I can't see eval_input_reader from your screenshot.
Which checkpoint are you evaling? Is this your own model? Please also share the file structure of your train dir.
 pkulzc
on 15 May 2018
pkulzc
on 15 May 2018
This is my config file
`# Faster R-CNN with Inception Resnet v2, Atrous version;
model {
faster_rcnn {
num_classes: 6
image_resizer {
keep_aspect_ratio_resizer {
min_dimension: 600
max_dimension: 1024
}
}
feature_extractor {
type: 'faster_rcnn_inception_resnet_v2'
first_stage_features_stride: 8
}
first_stage_anchor_generator {
grid_anchor_generator {
scales: [0.25, 0.5, 1.0, 2.0]
aspect_ratios: [0.5, 1.0, 2.0]
height_stride: 8
width_stride: 8
}
}
first_stage_atrous_rate: 2
first_stage_box_predictor_conv_hyperparams {
op: CONV
regularizer {
l2_regularizer {
weight: 0.0
}
}
initializer {
truncated_normal_initializer {
stddev: 0.01
}
}
}
first_stage_nms_score_threshold: 0.0
first_stage_nms_iou_threshold: 0.7
first_stage_max_proposals: 300
first_stage_localization_loss_weight: 2.0
first_stage_objectness_loss_weight: 1.0
initial_crop_size: 17
maxpool_kernel_size: 1
maxpool_stride: 1
second_stage_box_predictor {
mask_rcnn_box_predictor {
use_dropout: false
dropout_keep_probability: 1.0
fc_hyperparams {
op: FC
regularizer {
l2_regularizer {
weight: 0.0
}
}
initializer {
variance_scaling_initializer {
factor: 1.0
uniform: true
mode: FAN_AVG
}
}
}
}
}
second_stage_post_processing {
batch_non_max_suppression {
score_threshold: 0.0
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SOFTMAX
}
second_stage_localization_loss_weight: 2.0
second_stage_classification_loss_weight: 1.0
}
}
train_config: {
batch_size: 3
optimizer {
momentum_optimizer: {
learning_rate: {
manual_step_learning_rate {
initial_learning_rate: 0.0003
schedule {
step: 30000
learning_rate: .00003
}
schedule {
step: 50000
learning_rate: .000003
}
}
}
momentum_optimizer_value: 0.9
}
use_moving_average: false
}
gradient_clipping_by_norm: 10.0
#fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/model.ckpt"
#from_detection_checkpoint: true
num_steps: 200000
data_augmentation_options {
random_horizontal_flip {
}
}
}
train_input_reader: {
tf_record_input_reader {
input_path: "record/pascal.record"
}
label_map_path: "dataset/pascal_label_map.pbtxt"
}
eval_config: {
num_examples: 2000
max_evals: 10
}
eval_input_reader: {
tf_record_input_reader {
input_path: "record/pascal_eval.record"
}
label_map_path: "dataset/pascal_label_map.pbtxt"
shuffle: false
num_readers: 1
}`
I think that i was supposed to check model.ckpt-35617 point ,here is my chekpoint and train dir
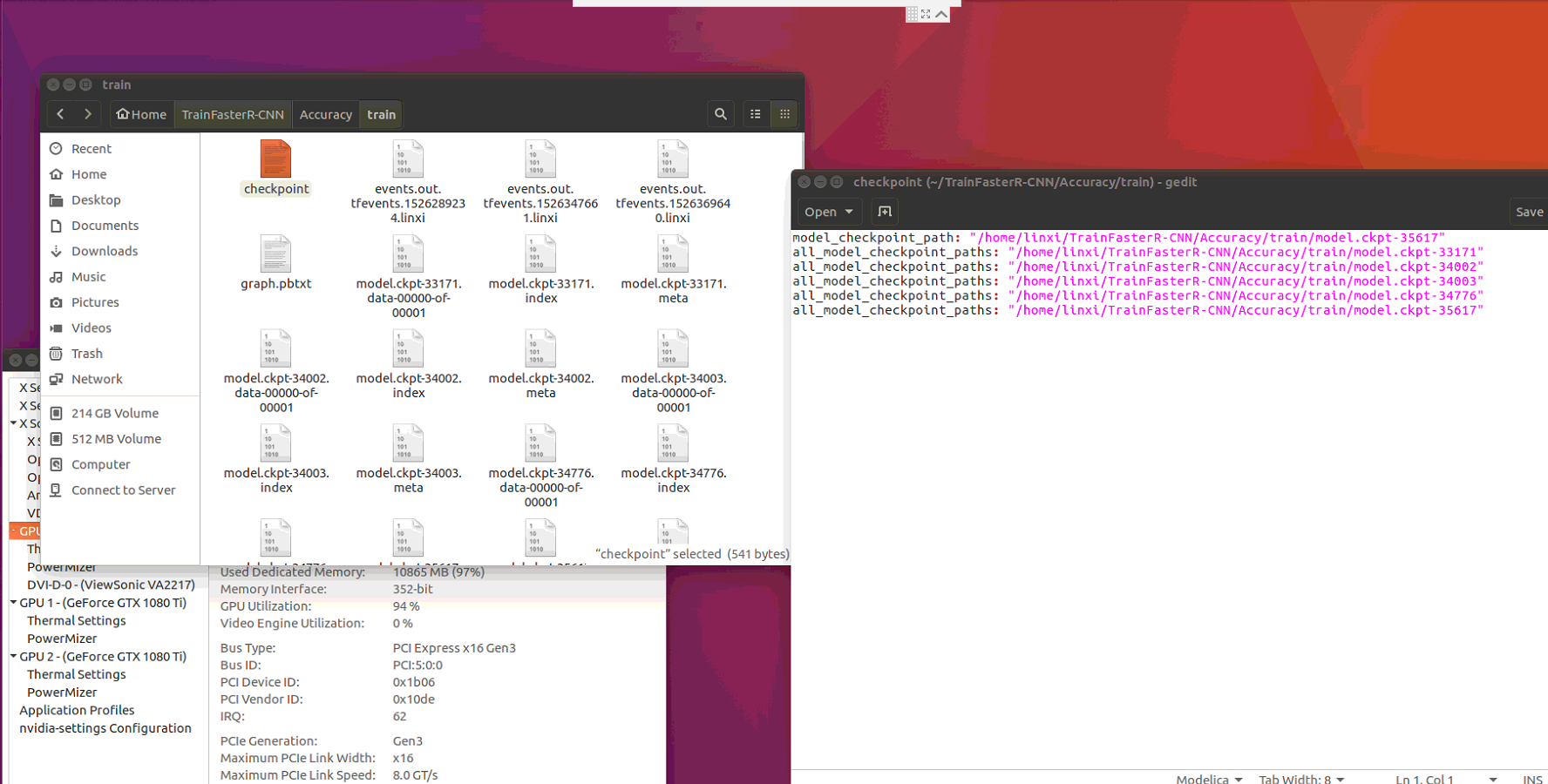
a819721810
on 16 May 2018
And yes, i trained my own model .
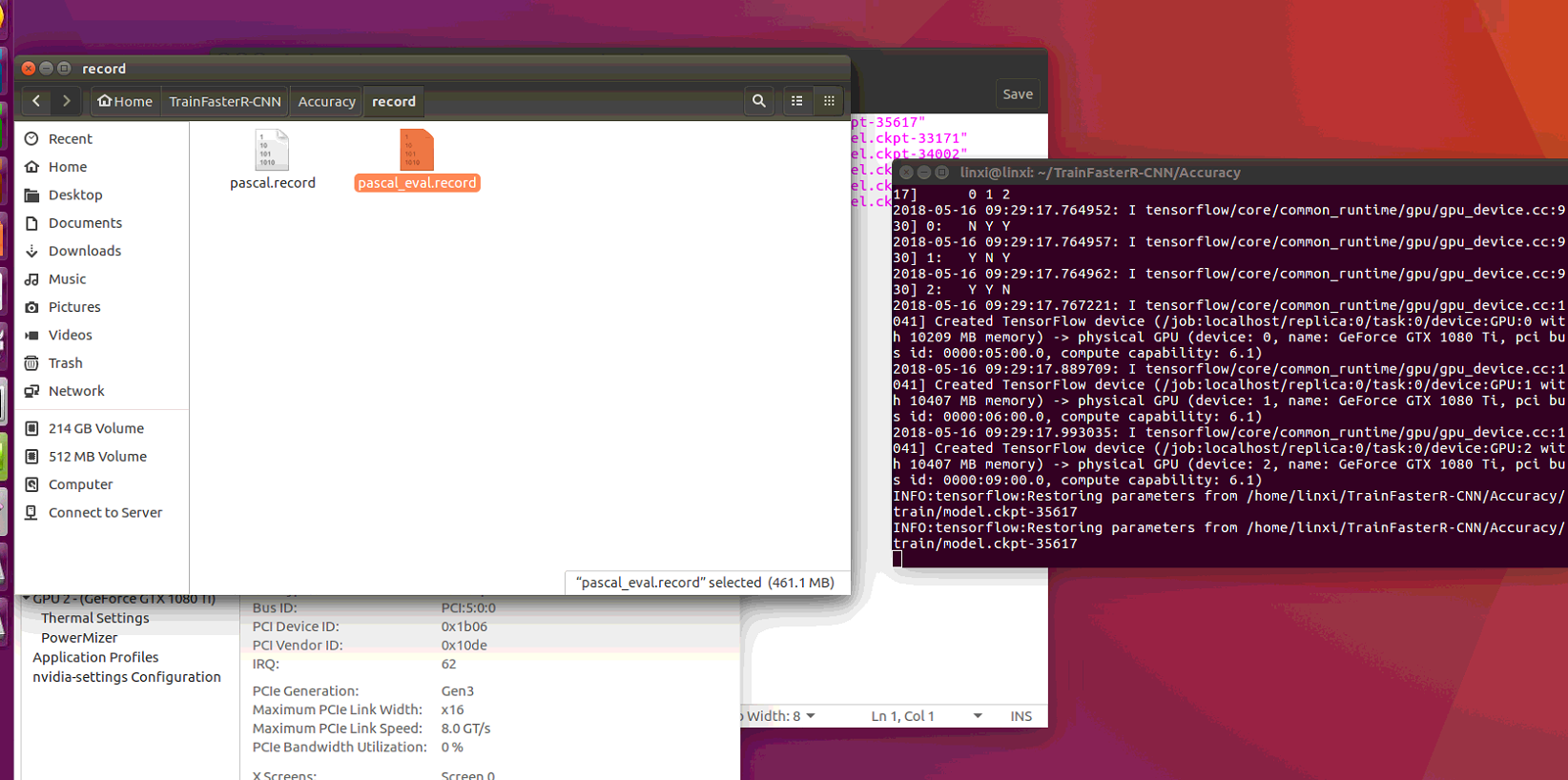
a819721810
on 16 May 2018
After evaling a litter time ,GPU Utilization from about 80% turned zero.
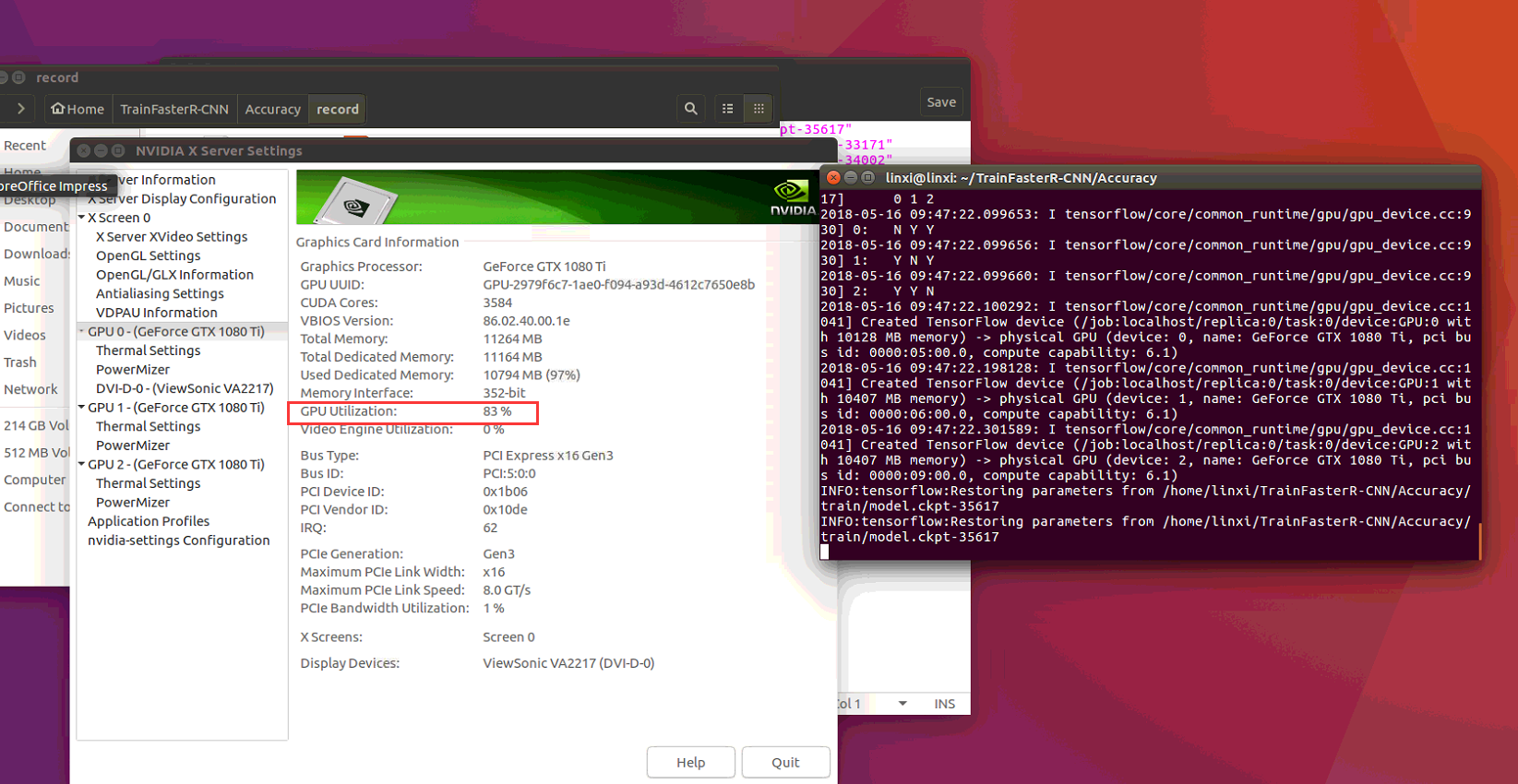
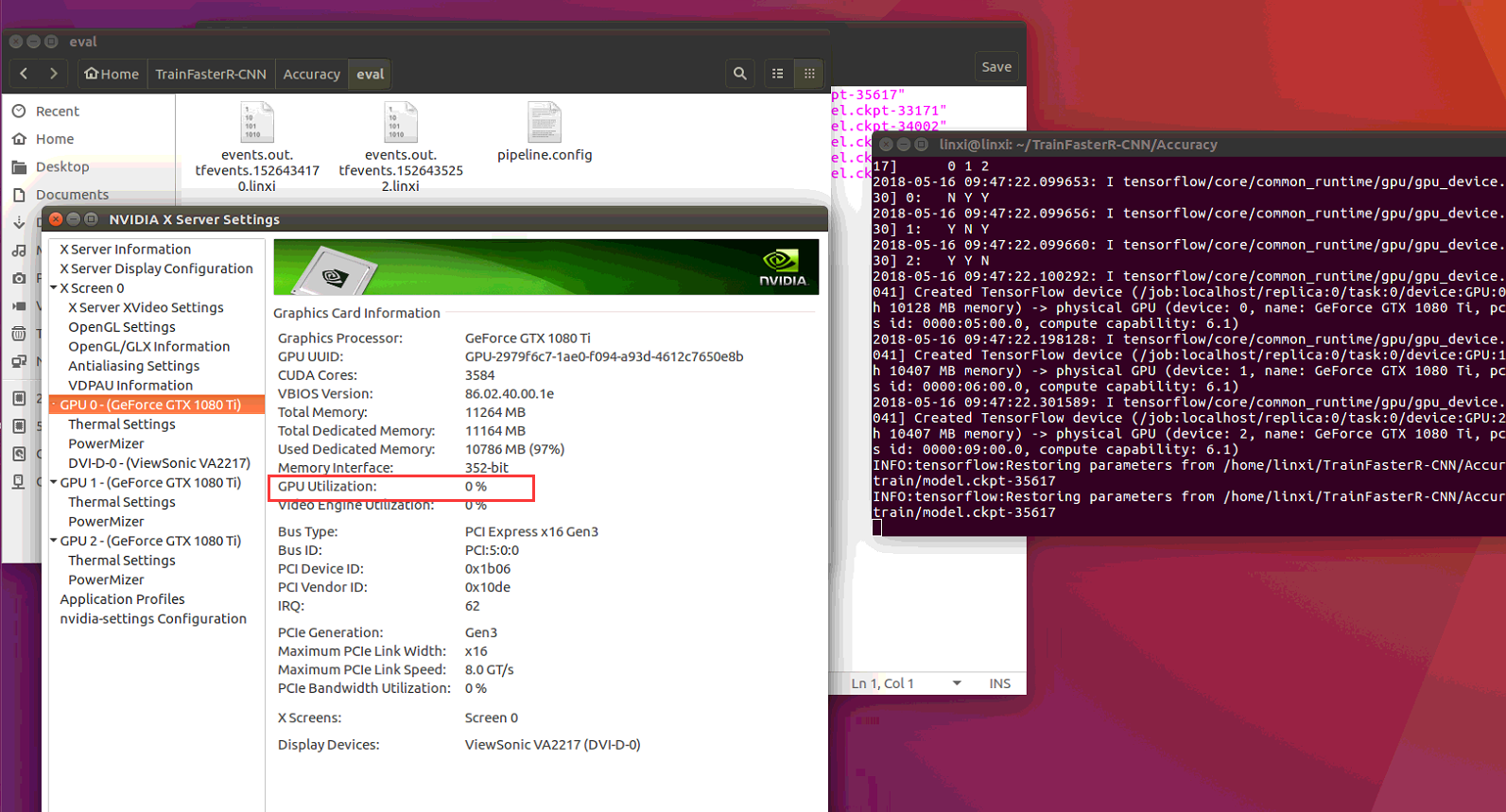
But it was still stuck
a819721810
on 16 May 2018
I didn't see anything obviously wrong, so perhaps try disabling all GPUs and see if it runs with CPU.
pkulzc
on 16 May 2018
Using CPU did't work:
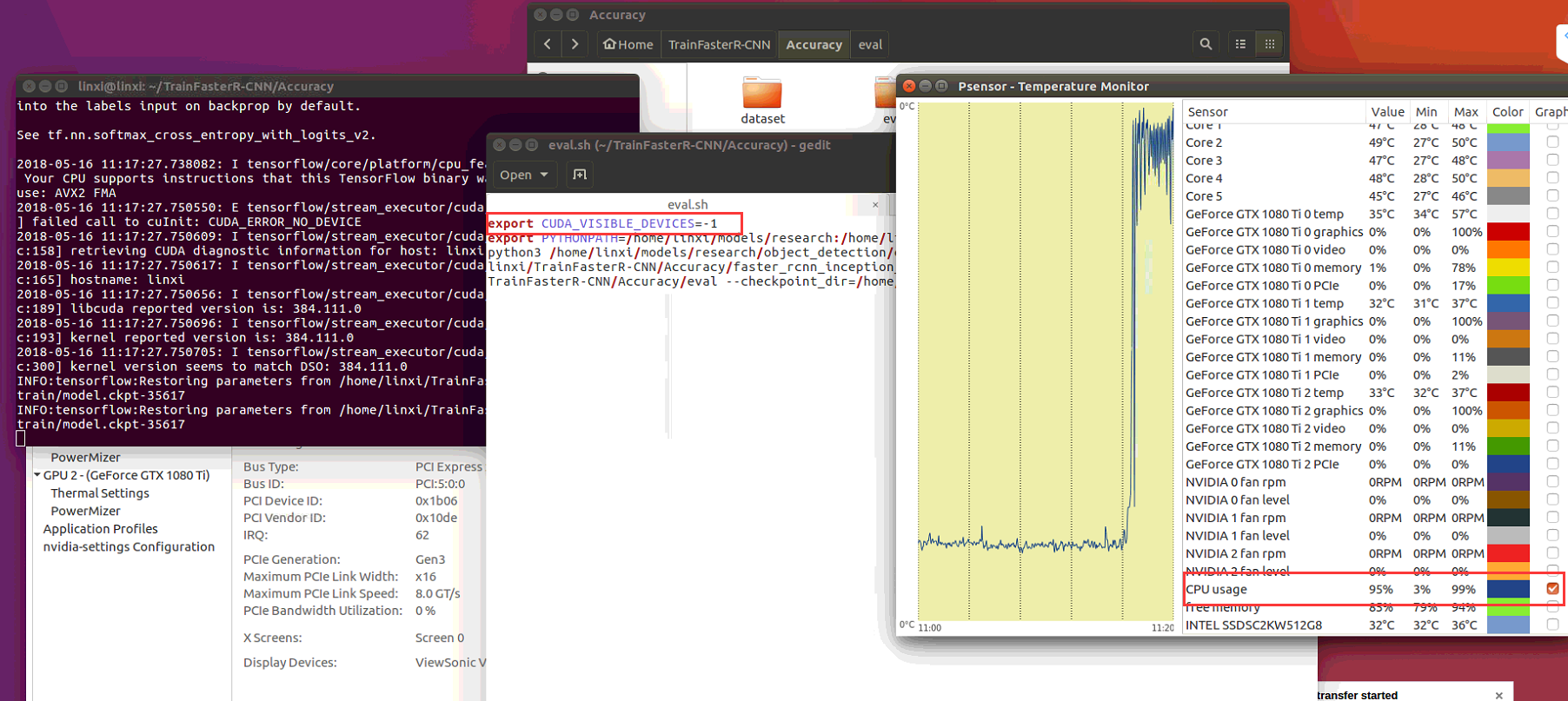
Here is my running state:
./eval.sh
/home/linxi/models/research/object_detection/utils/visualization_utils.py:25: UserWarning:
This call to matplotlib.use() has no effect because the backend has already
been chosen; matplotlib.use() must be called before pylab, matplotlib.pyplot,
or matplotlib.backends is imported for the first time.
The backend was originally set to 'TkAgg' by the following code:
File "/home/linxi/models/research/object_detection/eval.py", line 50, in
from object_detection import evaluator
File "/home/linxi/models/research/object_detection/evaluator.py", line 24, in
from object_detection import eval_util
File "/home/linxi/models/research/object_detection/eval_util.py", line 28, in
from object_detection.metrics import coco_evaluation
File "/home/linxi/models/research/object_detection/metrics/coco_evaluation.py", line 20, in
from object_detection.metrics import coco_tools
File "/home/linxi/models/research/object_detection/metrics/coco_tools.py", line 47, in
from pycocotools import coco
File "/home/linxi/.local/lib/python3.5/site-packages/pycocotools/coco.py", line 49, in
import matplotlib.pyplot as plt
File "/home/linxi/.local/lib/python3.5/site-packages/matplotlib/pyplot.py", line 71, in
from matplotlib.backends import pylab_setup
File "/home/linxi/.local/lib/python3.5/site-packages/matplotlib/backends/__init__.py", line 16, in
line for line in traceback.format_stack()
import matplotlib; matplotlib.use('Agg') # pylint: disable=multiple-statements
WARNING:tensorflow:From /home/linxi/.local/lib/python3.5/site-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.
Instructions for updating:
Use the retry module or similar alternatives.
INFO:tensorflow:Scale of 0 disables regularizer.
INFO:tensorflow:Scale of 0 disables regularizer.
INFO:tensorflow:Scale of 0 disables regularizer.
INFO:tensorflow:Scale of 0 disables regularizer.
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:Scale of 0 disables regularizer.
INFO:tensorflow:Scale of 0 disables regularizer.
WARNING:tensorflow:From /home/linxi/models/research/object_detection/core/box_predictor.py:403: calling reduce_mean (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
INFO:tensorflow:Scale of 0 disables regularizer.
WARNING:tensorflow:From /home/linxi/models/research/object_detection/core/losses.py:317: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Future major versions of TensorFlow will allow gradients to flow
into the labels input on backprop by default.
See tf.nn.softmax_cross_entropy_with_logits_v2.
2018-05-16 11:17:27.738082: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2018-05-16 11:17:27.750550: E tensorflow/stream_executor/cuda/cuda_driver.cc:406] failed call to cuInit: CUDA_ERROR_NO_DEVICE
2018-05-16 11:17:27.750609: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:158] retrieving CUDA diagnostic information for host: linxi
2018-05-16 11:17:27.750617: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:165] hostname: linxi
2018-05-16 11:17:27.750656: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:189] libcuda reported version is: 384.111.0
2018-05-16 11:17:27.750696: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:193] kernel reported version is: 384.111.0
2018-05-16 11:17:27.750705: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:300] kernel version seems to match DSO: 384.111.0
INFO:tensorflow:Restoring parameters from /home/linxi/TrainFasterR-CNN/Accuracy/train/model.ckpt-35617
INFO:tensorflow:Restoring parameters from /home/linxi/TrainFasterR-CNN/Accuracy/train/model.ckpt-35617
a819721810
on 16 May 2018
Still didn't see anything wrong. I suggest you to add multiple tf.logging.info(XXX) to evaluate.py to locate the line that is stuck.
pkulzc
on 16 May 2018
I used tf.logging.info(XXX) to find out ,it seemed that at evaluator.py 258 line metrics = eval_util.repeated_checkpoint_run()->eval.util.py 419 line global_step, metrics = _run_checkpoint_once()->eval.util.py 315 line ,procedure always executes "for batch in range(int(num_batches)):", can not execute "finally" portion ,until i used"ctrl +c" to kill procedure.
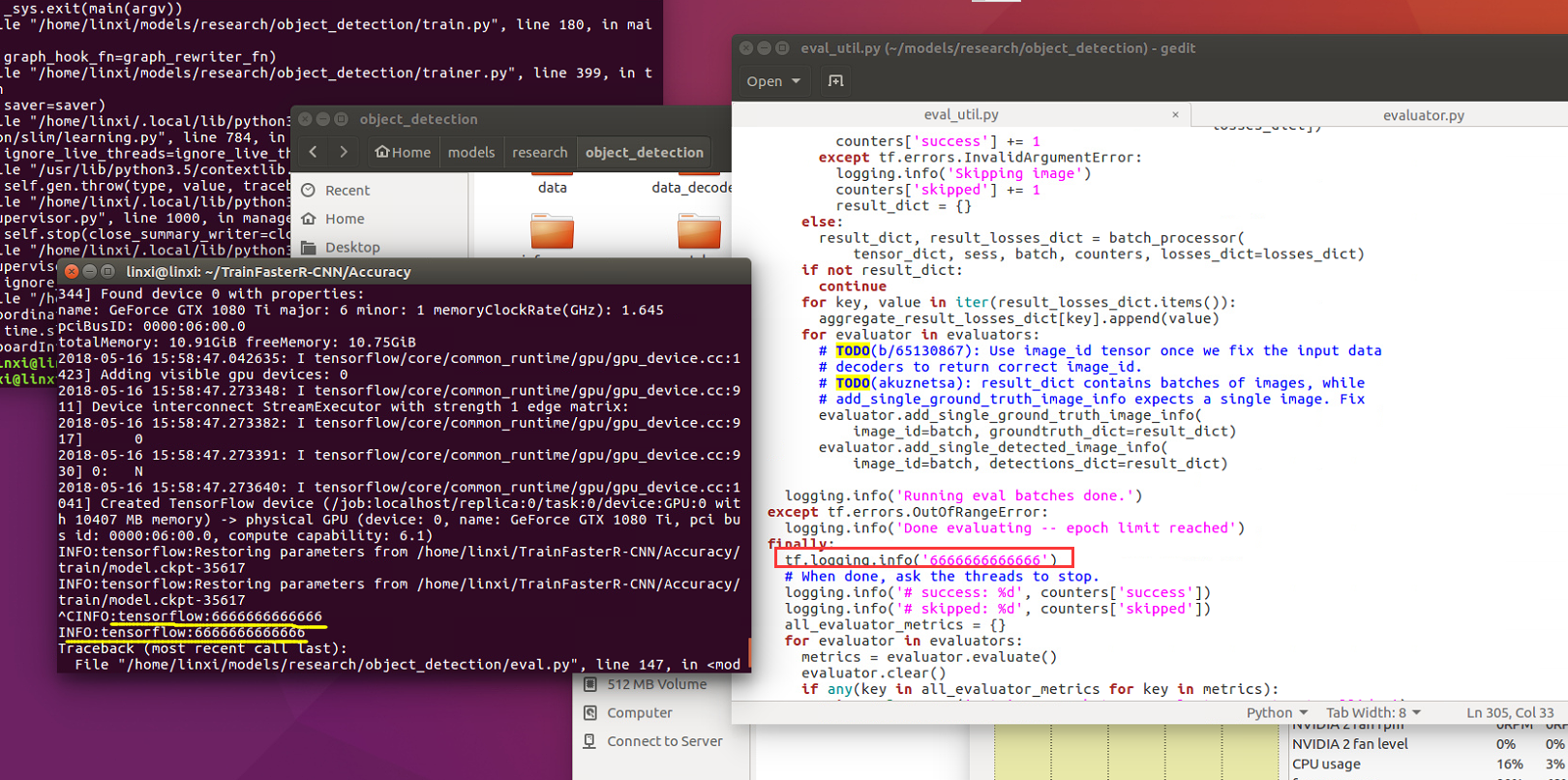
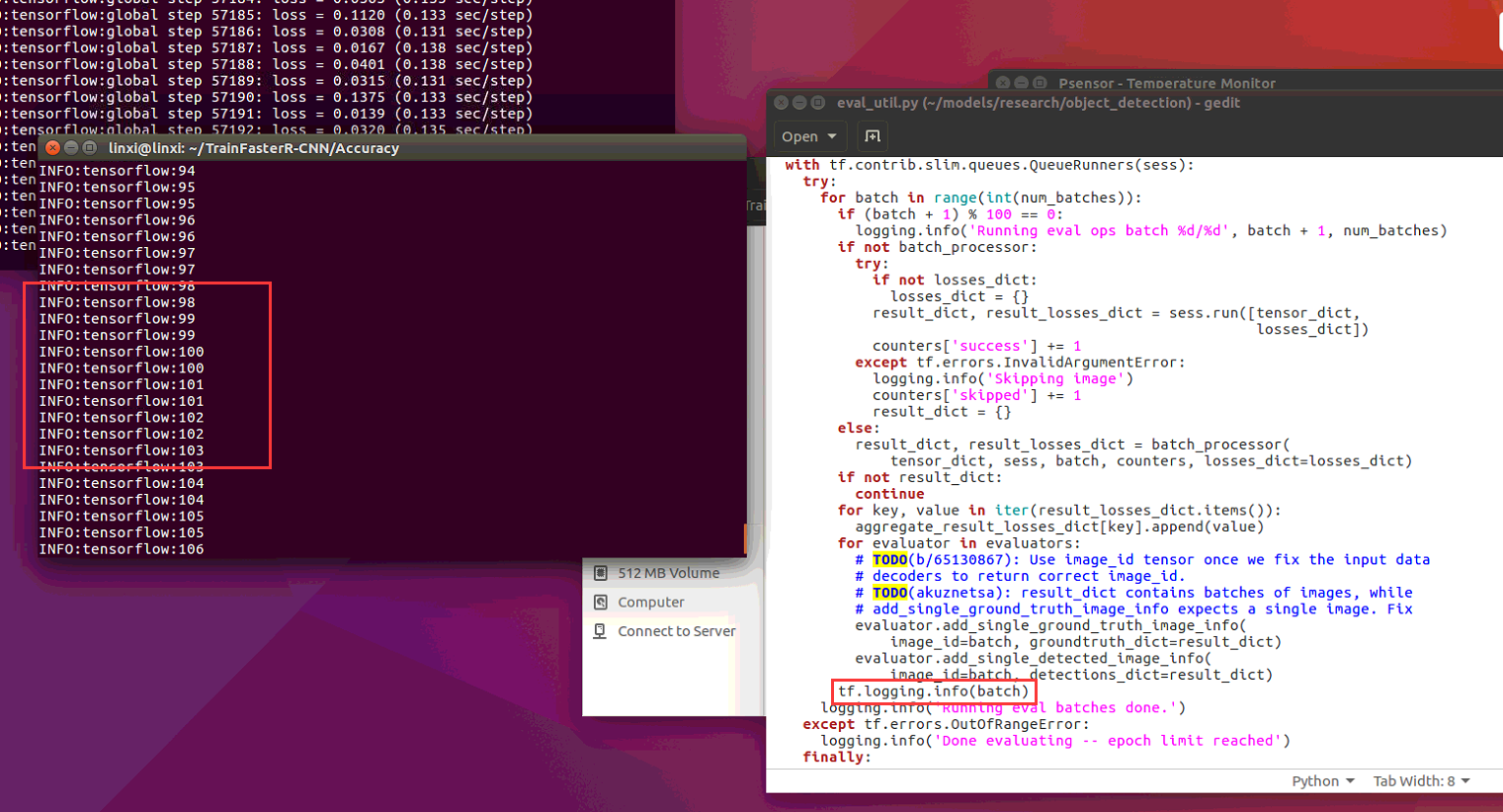
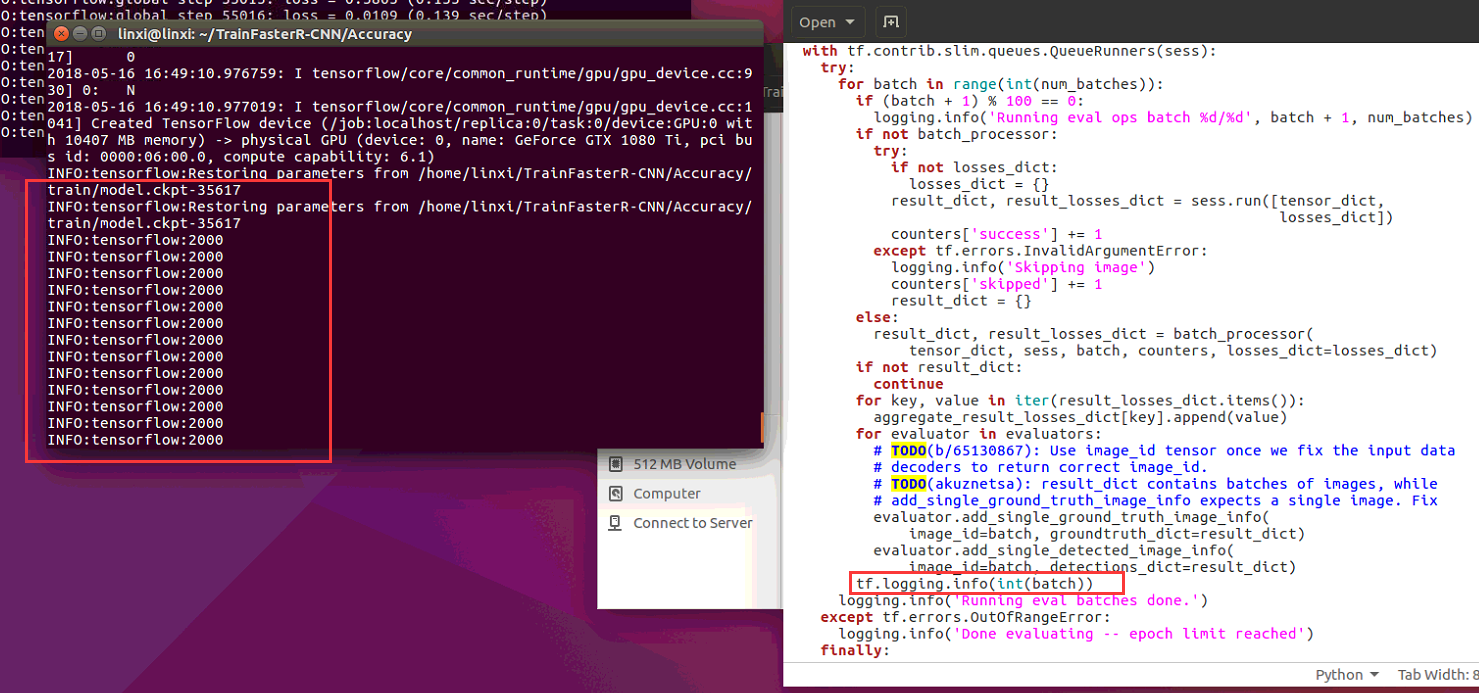
and i did't know why "333333333333333" printed once,and "44444444444444","555555555555","66666666666",print twice.
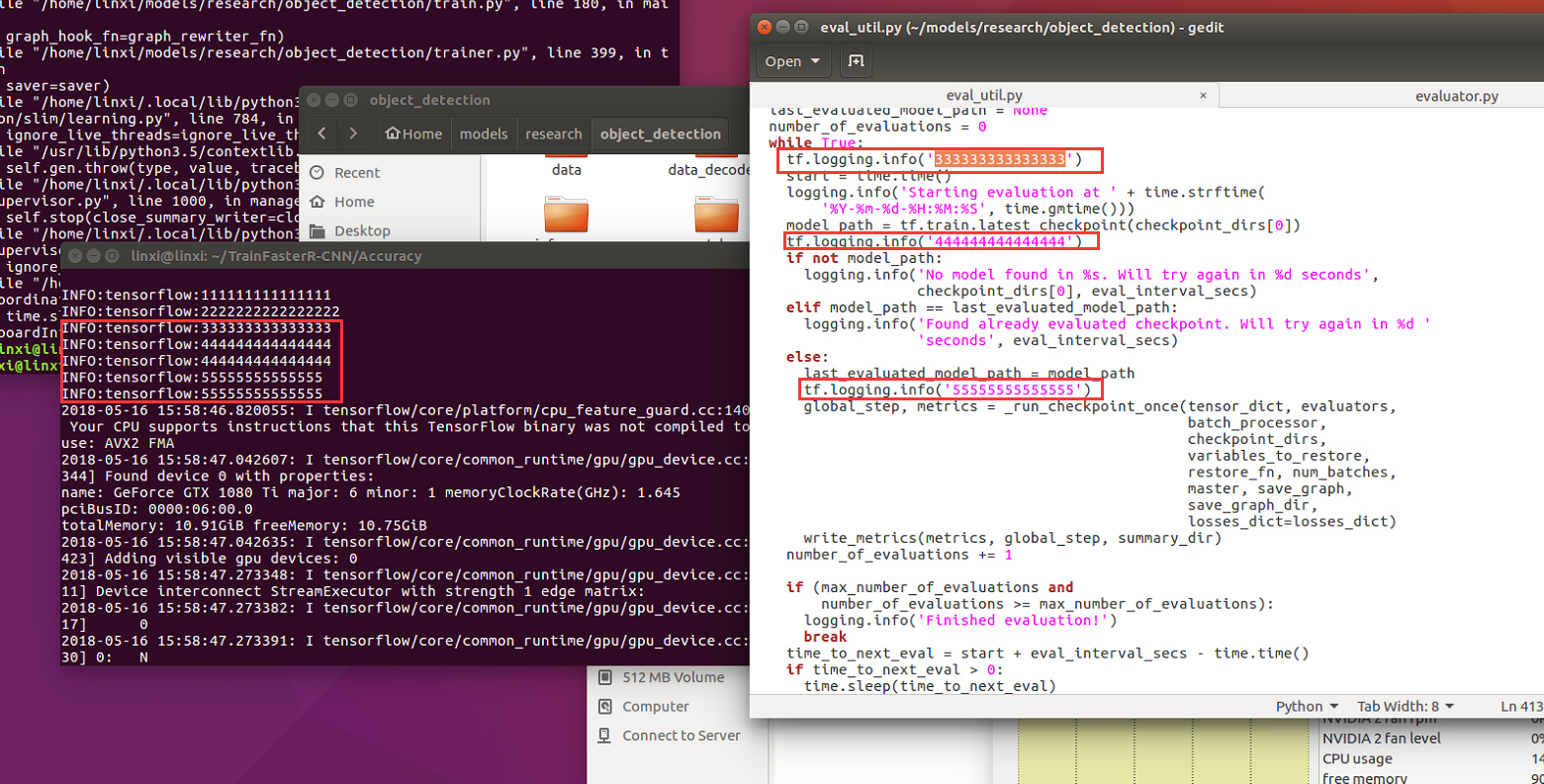
a819721810
on 16 May 2018
I also encountered a problem, it is just like you
 NjuHaoZhang
on 19 May 2018
NjuHaoZhang
on 19 May 2018
I also encountered the same problem,and the map value drawn using tensorboard is just a point rather than a graph. Does anyone know how to solve it? thanks.
 LXWDL
on 22 May 2018
LXWDL
on 22 May 2018
I met this problem also ,and it troubled me long time!
Differently, i have more errors message such as the below image seeing:
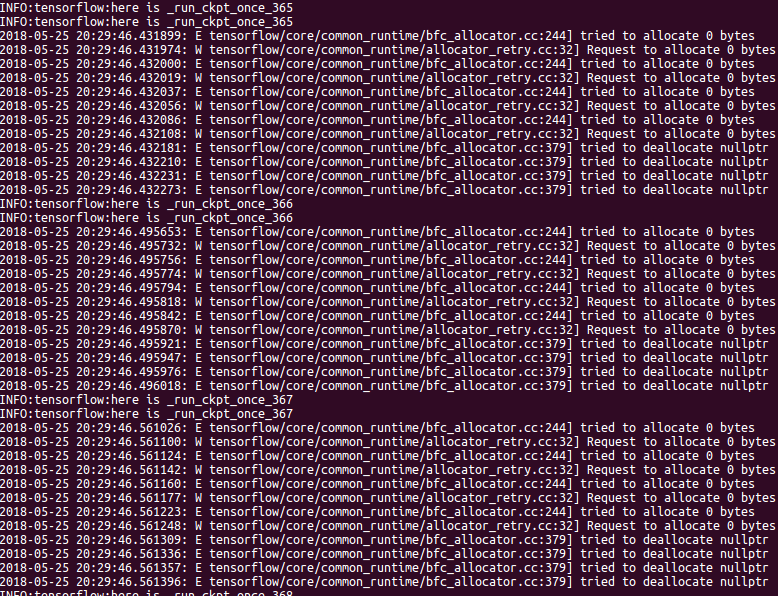
(INFO:tensorflow:here is _run_ckpt_once_366 )--- it is what i add :tf.logging.info('here is _run_ckpt_once_{}'.format(batch)) in eval.util.py 315 line "for batch in range(int(num_batches)):"
 wywywy01
on 25 May 2018
wywywy01
on 25 May 2018
It is not a error i found, it is also in the loop you set a number in the .config file.
I set the eval_config: {
num_examples: 519
max_evals: 1
},it just loop one times and then exit the script, and the 'max_evals' is 'max_number_of_evaluations' in eval_utils.py --->repeated_checkpoint_run(), which control when it skip out the while(true).
why the ' python eval.py' is run long time?
it is we training our model all time and we have see the performance through the tensorboard.
wywywy01
on 25 May 2018
Hi, @wywywy01 ,it is not a error,why i did't produce any result.
a819721810
on 28 May 2018
Hi, @a819721810 , have you ever solved the problem? I encountered the same problem, it was stuck at restoring parameters.
 chenpengf0223
on 28 May 2018
chenpengf0223
on 28 May 2018
Actually,it is producing result,but no information to remind us ."event"file is enough.
Using tensorboard will see the result.
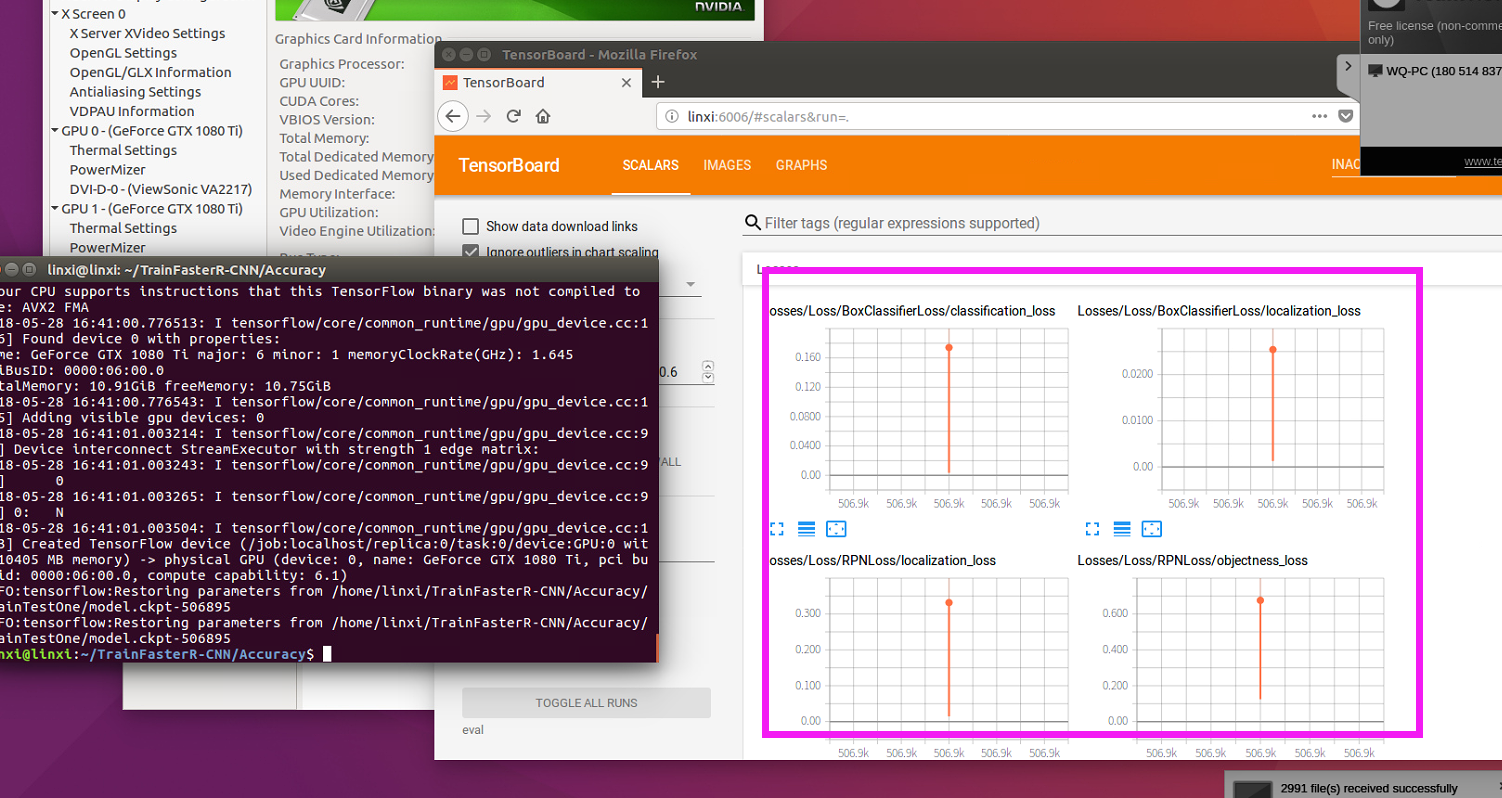
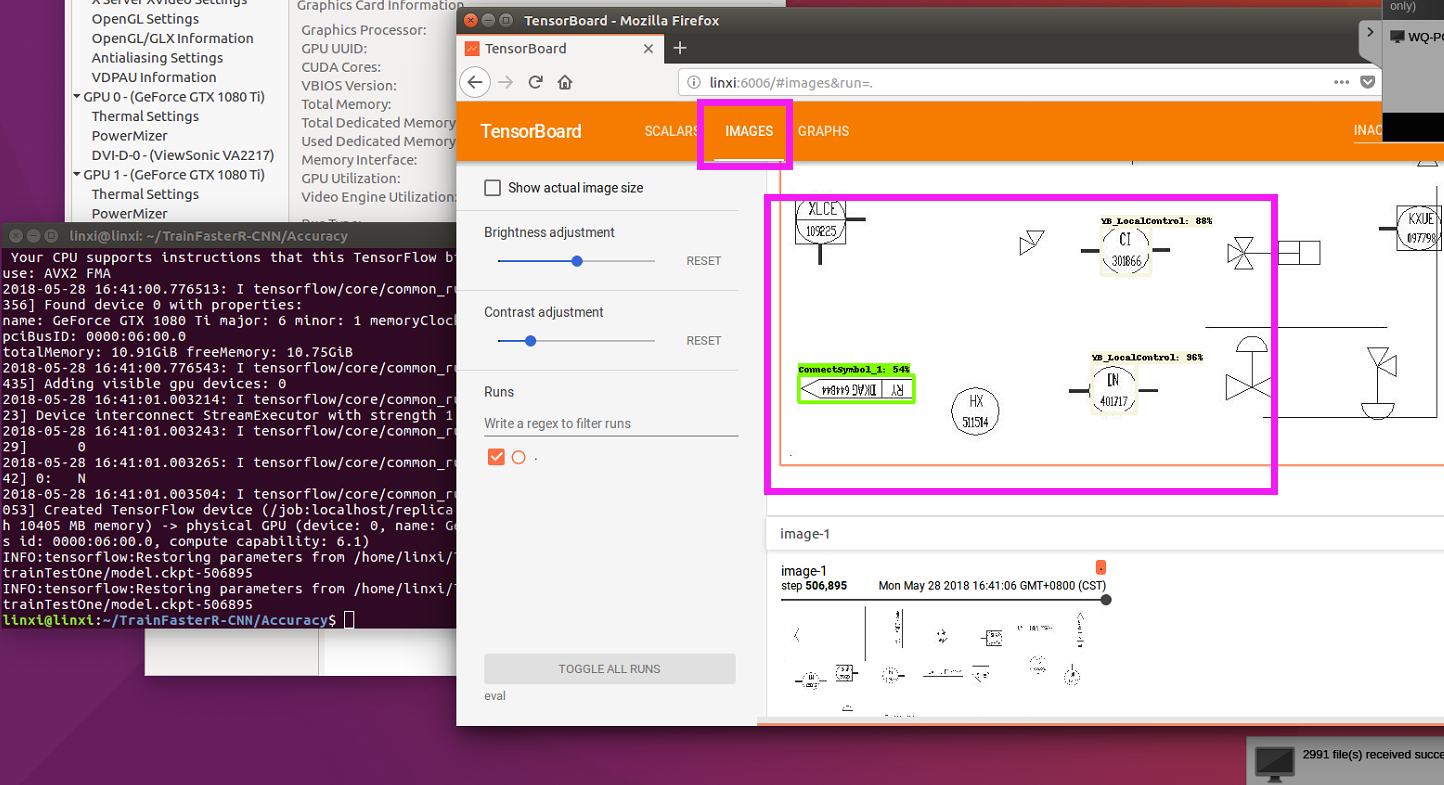
@wywywy01 's word is correct,
"num_examples":Indicate how many picture you want to be checked.
"max_evals":loop times.
when procedure is running,it always shows“INFO:tensorflow:Restoring parameters......”,but it's actually running,no stuck and it just don't show information to remind us.You also can get result from tensorboard. @chenpengf0223 @MrWanter
a819721810
on 28 May 2018
when we run our --train.py, it need some time to produce the model parameter in your setting val dir.
And after a model is saved in the val dir through several training steps there will be a line or a dot of loss appeared in your tensorboard you can observe the result from tensorboard just wait a time before the model is saved .
wywywy01
on 1 Jun 2018
I encountered the same problem. It didn't return any information after INFO:tensorflow:Restoring parameters.......According to what you said, i can get some results on Tensorboard. However ,i am still confused :
Why it can not get any information on the terminal?
Why is there nine images in Tensorboard? I run the eval.py on 4000+ images
How can i get the test result ,like the mAP score?
Looking forward to your reply @a819721810 @wywywy01
 songzenghui
on 19 Jun 2018
songzenghui
on 19 Jun 2018
Why it can not get any information on the terminal?
because function“logging.info()...” has some problem that cannot print any result.
Why is there nine images in Tensorboard? I run the eval.py on 4000+ images
it is default to 10,you maybe set it in eval.py.
How can i get the test result ,like the mAP score?
Tensorboard "SCALARS" has point that indicate mAP score. @songzenghui
a819721810
on 19 Jun 2018
I was having the same problem. I ran eval.py and it was stuck at "Restoring parameters from...". What was wrong in my case were the tfrecord files for evaluation. I didn't realize they were 0KB. After generating the correct tfrecord files, everything worked as expected.
 anamaqueda
on 11 Apr 2019
anamaqueda
on 11 Apr 2019
Related issues
 kamal4493
·
3Comments
kamal4493
·
3Comments
 XavDCtpz
·
3Comments
XavDCtpz
·
3Comments
 25b3nk
·
3Comments
25b3nk
·
3Comments
 xbcReal
·
3Comments
xbcReal
·
3Comments
 hanzy123
·
3Comments
hanzy123
·
3Comments
Most helpful comment
I also encountered a problem, it is just like you