Models: [Object Detection] Mobilenet as Backbone for Mask R-CNN
Is it possible to create a config file with Mobilenet V1 or V2 as Backbone /Feature extractor to train a Mask R-CNN Model?
Something like this:
model {
faster_rcnn {
num_classes: 90
image_resizer {
keep_aspect_ratio_resizer {
min_dimension: 800
max_dimension: 1365
}
}
number_of_stages: 3
feature_extractor {
type: 'ssd_mobilenet_v2'
...
 gustavz
gustavz
All 35 comments
Yes but you need to make some changes by yourselves.
We have this feature extractor ready(here) so you can train mobilenet v1 + faster rcnn or mask rcnn by doing the followings:
- Add faster_rcnn_mobilenet_v1 to this mapping
- Set the feature_extractor field to mobilenet v1.
We don't have a config nor pre-trained checkpoint for this model yet, but you can train from scratch by yourselves.
 pkulzc
on 18 Apr 2018
pkulzc
on 18 Apr 2018
Nice! Are there trained weights at least for the mobilenet backbone available, like on imagenet? That would really speed up training :)
And if yes how do I assign them in the config? Something like including ckpt files but set finetune checkpoint to False, right?
gustavz
on 18 Apr 2018
There are pretrained weights for mobilenet v1 in the slim repo: https://github.com/tensorflow/models/tree/master/research/slim
And yes, you point to the mobilenet checkpoint and set "from detection checkpoint" to false, it will load the backbone weights and train the rest from scratch
 nguyeho7
on 18 Apr 2018
nguyeho7
on 18 Apr 2018
Was a bit busy but now i will give it a try.
So i added the feature extractor to the model builder mapping
and created a new config based on mask_rcnn_inception_v2_coco with the following changes (i want to train on low res):
model {
faster_rcnn {
num_classes: 90
image_resizer {
keep_aspect_ratio_resizer {
min_dimension: 256
max_dimension: 512
}
}
number_of_stages: 3
feature_extractor {
type: 'faster_rcnn_mobilenet_v1'
first_stage_features_stride: 16
Do you suggest any other modifications to the parameters?
To which model would a mask_rcnn_mobilenet_v1_coco be the closest concering the config?
Thank you very much @nguyeho7 @pkulzc !
gustavz
on 26 Apr 2018
You probably need to tune learning rate yourself since this is a new model.
pkulzc
on 26 Apr 2018
But taking mask rcnn with inception v2 as starting config fits?
gustavz
on 26 Apr 2018
Yeah that should be fine.
pkulzc
on 26 Apr 2018
Alright. I‘ll take the mobilenet v1 weights as initilization.
Speaking of the learning rate, i‘ll probably have to decrease it compared to the value in the config.
By which factor would you suggest? 10?
Am 26.04.2018 um 17:49 schrieb pkulzc notifications@github.com:
Yeah that should be fine.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub, or mute the thread.
gustavz
on 26 Apr 2018
You can start with 0.001/0.0001 and tune it accordingly. 10 is too high.
pkulzc
on 26 Apr 2018
I meant by factor 10. So 10 times smaller (or bigger) than the current value in the config.
I guess a value bigger than 1 has no mathematical sense :D
gustavz
on 26 Apr 2018
One last question @pkulzc:
i use dataset_tools/download_and_preprocess_mscoco.sh to download coco and create the tf-record files.
Is there also some ready to use script / routine if i don't want to train on all coco classes but for example just on the person class?
What i mean is to use pycocotools to only get the image_ids with persons in them?
gustavz
on 27 Apr 2018
@nguyeho7 when i try to load checkpoint files of mobilenet i get following error:
tensorflow.python.framework.errors_impl.NotFoundError: Unsuccessful TensorSliceReader constructor: Failed to find any matching files for PATH/TO/mobilenet_v1_1.0_224/mobilenet_v1_1.0_244.ckpt
Do you know how to correctly address the checkpoint? Or are there other modifications necessary?
gustavz
on 27 Apr 2018
@GustavZ PATH/TO doesn't really seem correct, are you sure it points at the checkpoint file? absolute paths should be fine
nguyeho7
on 27 Apr 2018
I exchanged my local projects path with PATH/TO as i did not want to post my whole system structure as its damn long and doesn't matter for this cause.
I tried it now for different models and different checkpoints and i am pretty sure it is not possible to load the checkpoints of MNV1 provided in research/slim as backbone for mask rcnn.
Probably the layer names differ or something similar...
EDIT1: Is it the standard way for mask rcnn models to use manually scheduled learning rates and not more advanced methods like exponential_decay_learning_rate ...?
EDIT2: Now it runs, idk whats the exact reason but i used those three options in the config:
fine_tune_checkpoint: "PATH/TO/mobilenet_v1_1.0_224/mobilenet_v1_1.0_224.ckpt"
from_detection_checkpoint: false
fine_tune_checkpoint_type: 'classification'
I trained the model for 1.2 Mio Steps right now.
The strange thing is that its frozen graph (pb file) is less than half the size of mask rcnn inception.
But still it is not faster when using a video stream as inference input.
Furthermore the pb file has now nearly the same size as ssd mobilenet, but still it does not run on a jetson tx2 (no faster rcnn & mask rcnn models have fitted on its 8gb shared memory so far).
You give me a hint why this is? Is the frozen model size saying anything at all?
Here you have my losses, i took the following manual scheduled learning rate:
learning_rate: {
manual_step_learning_rate {
initial_learning_rate: .001
schedule {
step: 300000
learning_rate: .0001
}
schedule {
step: 900000
learning_rate: .00001
}
schedule {
step: 1200000
learning_rate: .000001
}
schedule {
step: 2000000
learning_rate: .0000001
}
}
}
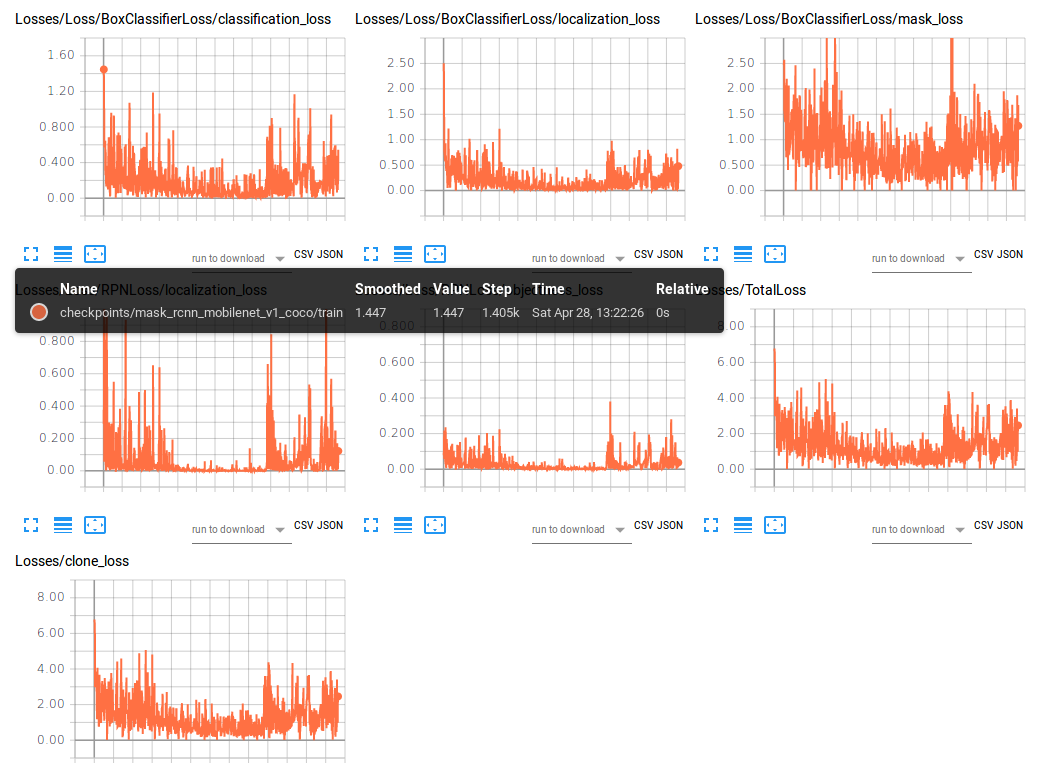
The part where the loss suddently increases is at 900k steps, where the learning rate gets decreased the second time. How can a decrease of the learning rate cause such a behaviour? I thought that is typical for increasing learning rate / too high learning rate in general?
gustavz
on 4 May 2018
Hi @GustavZ , your loss are already pretty small so the jittering might be fine. Do you have reasonable masks now? About the speed issue, you can write a simple file to do benchmarking and see the real time diff.
The benchmarking file should do the followings:
- read 500 image and run with your frozen graph
- wrap your session.run with timer
- compute average inference time
If you see similar numbers for both models, please do this so we can see which op is time consuming.
pkulzc
on 10 May 2018
Hi @pkulzc and @nguyeho7,
I now trained on several input sizes, the smallest one was fixed 400x400 and when i do the tests you suggested i see the following results (tested on my 4GB GTX 1050):
400x400 Mask R-CNN with Mobilenet V1 as Backbone:
[INFO] total detection time for 500 images: 121.777369
[INFO] mean detection time: 0.243554738
[INFO] median detection time: 0.2322465
[INFO] min detection time: 0.214988
[INFO] max detection time: 5.26637
[INFO] std dev detection time: 0.225076163709
[INFO] resulting mean fps: 4.10585319839
[INFO] resulting median fps: 4.30576994702800x1365 mask_rcnn_inception_v2_coco_2018_01_28 (the one from model zoo):
[INFO] total detection time for 500 images: 115.629033
[INFO] mean detection time: 0.231258066
[INFO] median detection time: 0.2218705
[INFO] min detection time: 0.183107
[INFO] max detection time: 6.726007
[INFO] std dev detection time: 0.290974029608
[INFO] resulting mean fps: 4.32417349715
[INFO] resulting median fps: 4.50713366581
Furthermore summarizing and benchmarking the two models give me the following results
400x400 Mask R-CNN with Mobilenet V1 as Backbone:
Found 8653467 (8.65M) const parameters (summarize_graph)
Timings (microseconds): count=96 first=174791 curr=162095 min=130946 max=339842 avg=172224 std=24306
Memory (bytes): count=96 first=551873283 curr=549733895 min=539747075 max=568890883 avg=5.53331e+08 std
6078 nodes observed /executed
Average inference timings in us: Warmup: 4984622, no stats: 101118, with stats: 104571
FLOPs estimate: 383.36B
FLOPs/second: 3.79T800x1365 mask_rcnn_inception_v2_coco_2018_01_28 (the one from model zoo):
Found 15908904 (15.91M) const parameters (summarize_graph)
Timings (microseconds): count=45 first=353213 curr=363873 min=228567 max=530280 avg=347264 std=38947
Memory (bytes): count=45 first=1456984875 curr=1456161831 min=1454797863 max=1528497191 avg=1.46222e+09 std=14557018
6678 nodes observed /executed
Average inference timings in us: Warmup: 5553811, no stats: 191074, with stats: 223100
FLOPs calculation failed with Invalid argument: Tried to fetch data for '^FirstStageFeatureExtractor/Assert/Assert', which produces no output. To run to a node but not fetch any data, pass '^FirstStageFeatureExtractor/Assert/Assert' as an argument to the 'target_node_names' argument of the Session::Run API.
Furthermore i created the TimeLine Json files:
mask_rcnn_json_timeline_files.zip
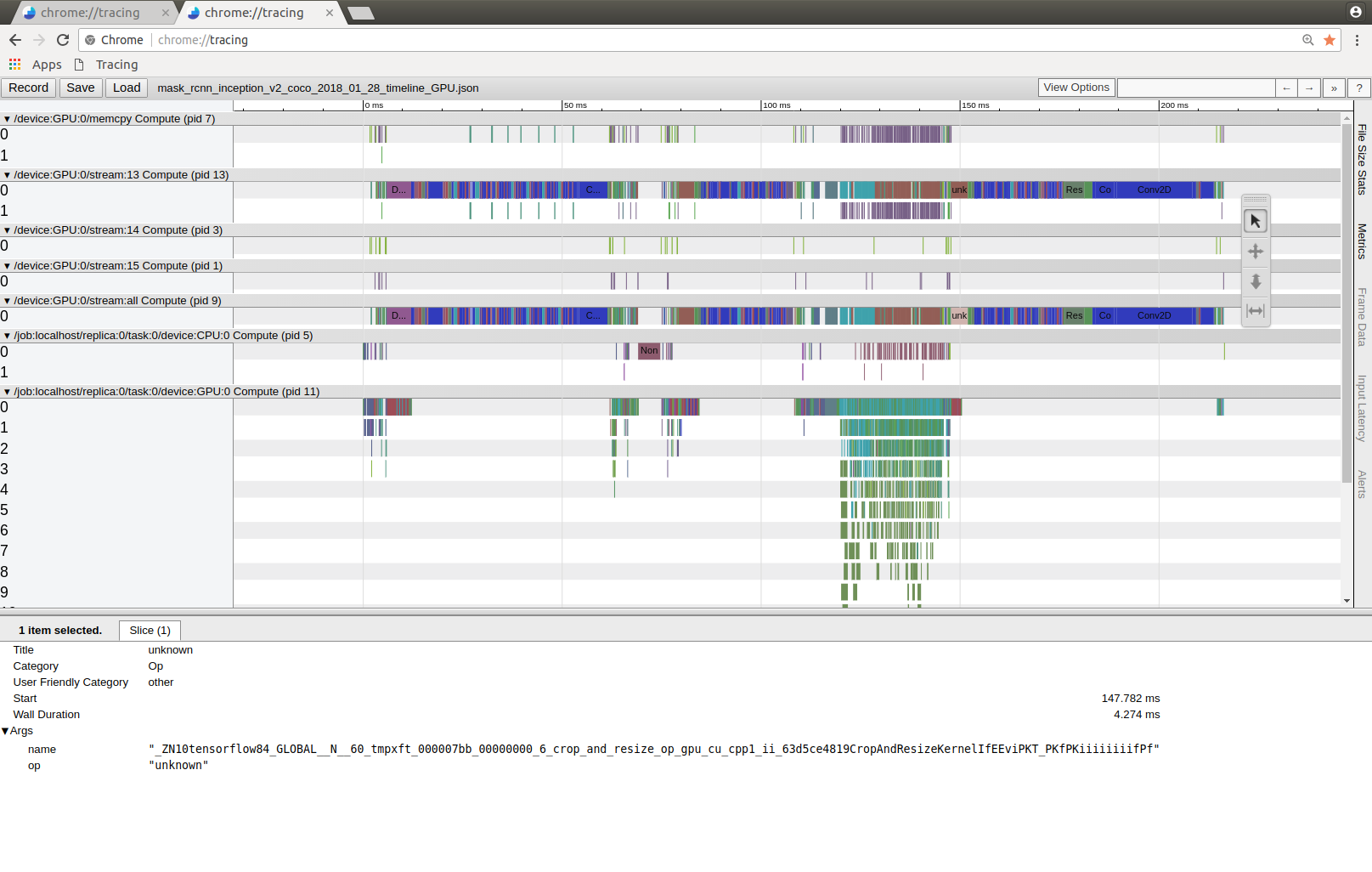
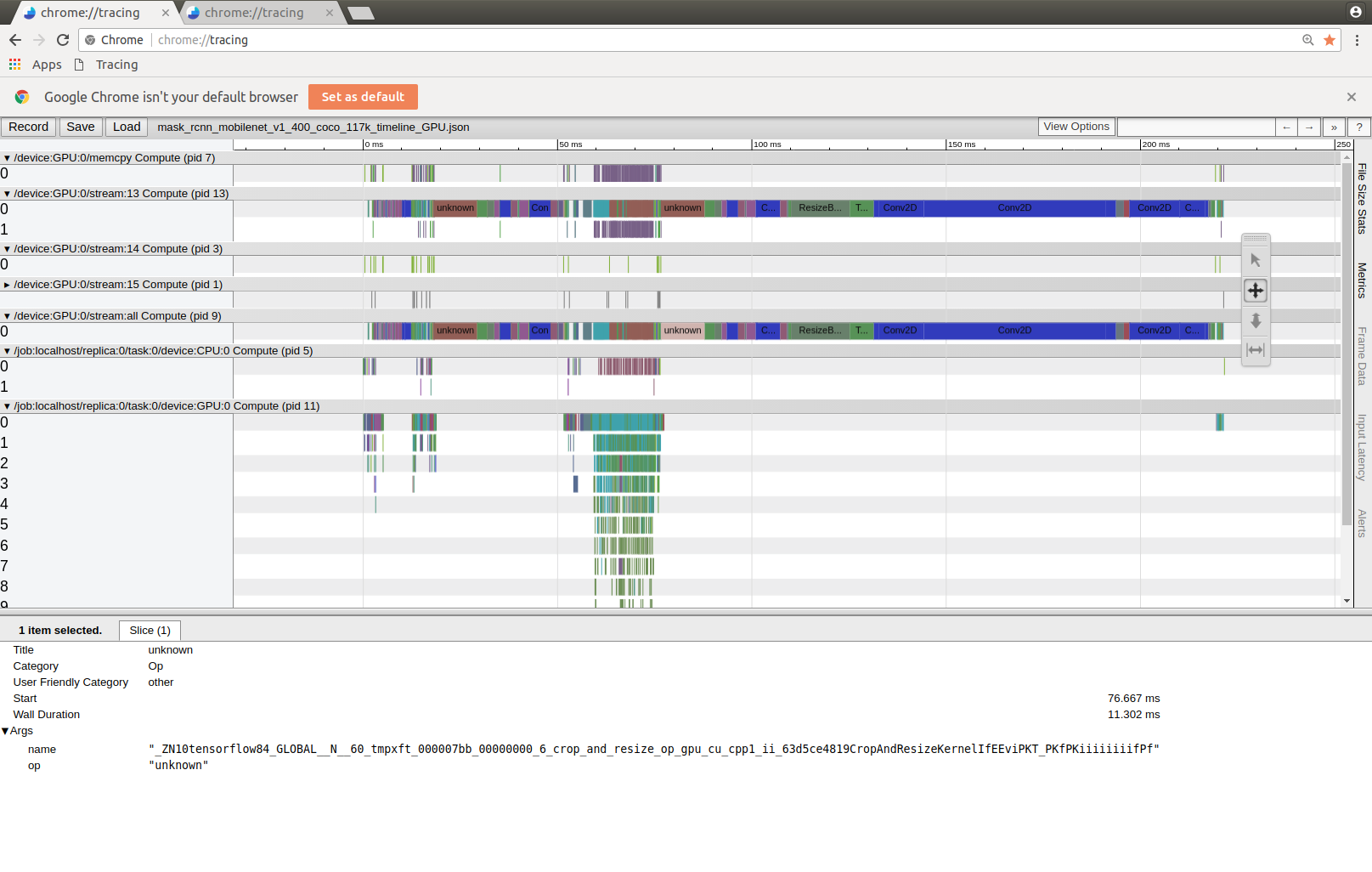
It seems that in the mobilenet version the rear CropAndResizeKernel, ResizeBilinear and CONV2D take much longer than in the default version. Why could that be?
I hope you can gain some information from this test series!
gustavz
on 28 May 2018
@GustavZ Thanks for the great work! I was just wondering, how does it actually look performance wise? mask mAP?) Because I imagined mobilenet would lose too much information for segmentation. But since inception has roughly the same speed it shouldn't matter that much.
nguyeho7
on 28 May 2018
@nguyeho7 I currently have an mAP of around 0.22 @0.5IoU for the 400x400 Model.
But as some classes are near 0mAP, i think this can be increased with overall more training, different learning rate schedules or tuning hyper paramters (maybe even another optimizer?).
If you look at the timeline you see that till the tf.where function (which are the main bottlenet for ssd_mobilenet for incorrect gpu / cpu adressing) the mask_rcnn_mobilenet model is twice as fast, but then it strangely struggles with mainly 3 operations:
- an unknown op named: "_ZN10tensorflow84_GLOBAL__N__60_tmpxft_000007bb_00000000_6_crop_and_resize_op_gpu_cu_cpp1_ii_63d5ce4819CropAndResizeKernelIfEEviPKT_PKfPKiiiiiiiifPf"
- "SecondStageBoxPredictor_1/Conv/Conv2D"
- "SecondStageBoxPredictor_1/ResizeBilinear"
Those take much more time than the default inception model which causes the whole mobilenet model to be as slow as inception at the end. Why could that be?
I also created the TimeLine files for CPU only sessions. And strangely again here the unknown op is not shown at all:
mask_rcnn_json_timeline_CPU.zip
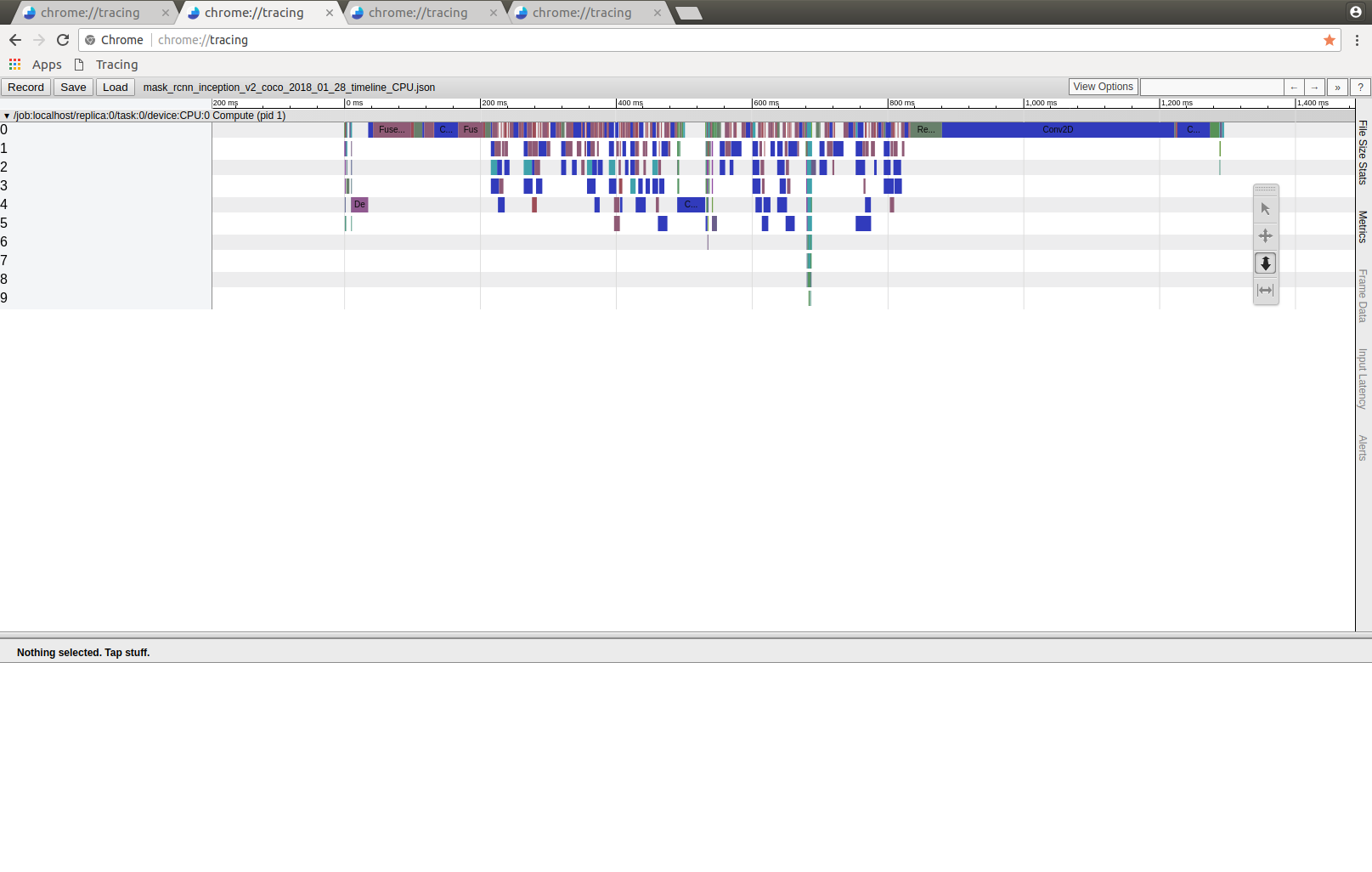
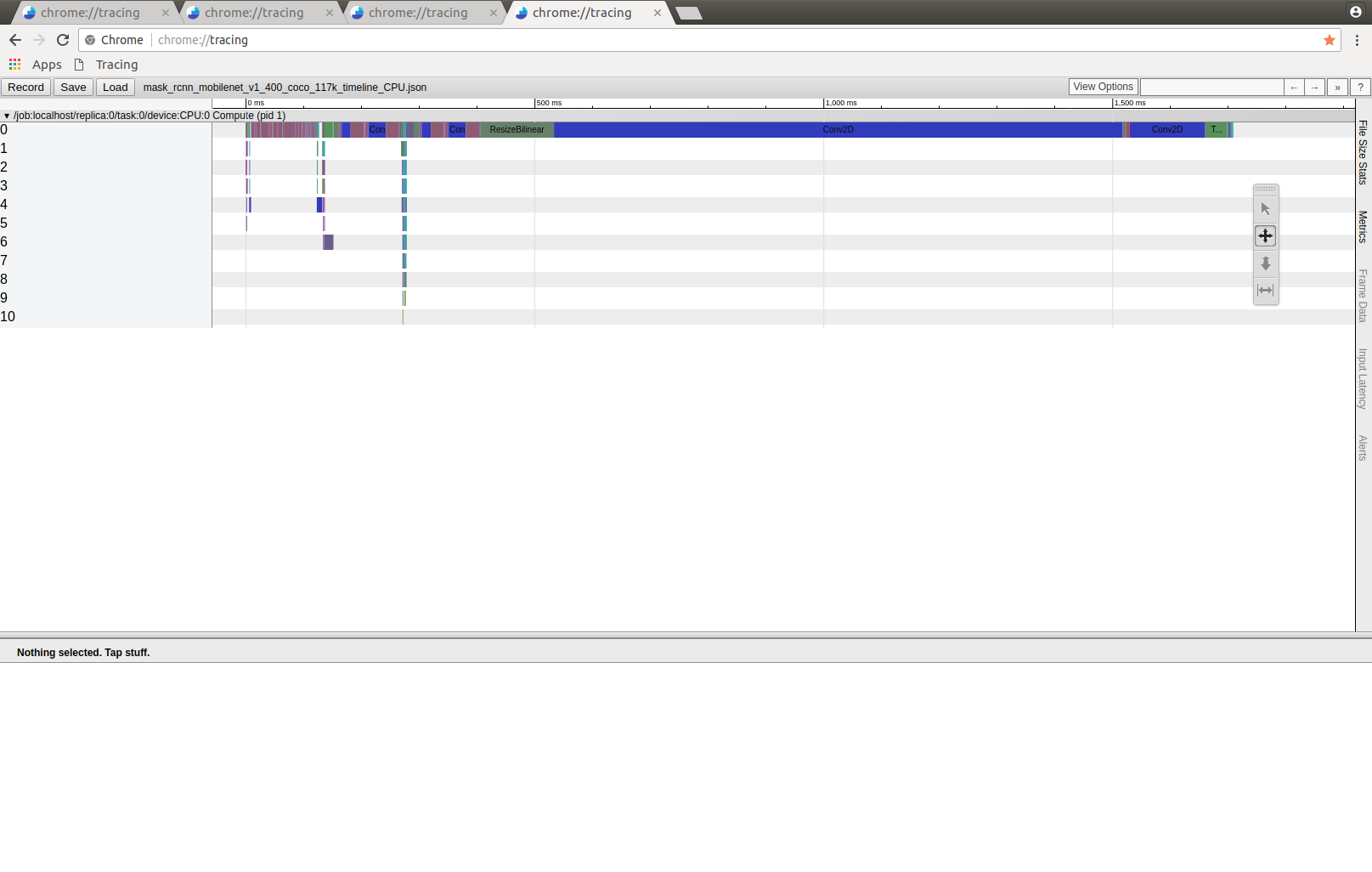
Do you have any thoughts on this?
gustavz
on 28 May 2018
Resize and crop is the ROIpool implementation (probably a GPU version looking at the name..) and the resize billinear could be upsampling?
nguyeho7
on 28 May 2018
yes but why do they take much more computing time for mobilenet as backbone.
I though these operations are not affected by the backbone.
Also the last CONV2D Takes double the time.
EDIT: @nguyeho7 another topic, why are msk rcnn and faster rcnn models only trained with momentum optimizer in the object_detection project? Why are not more advanced optimizers used?
gustavz
on 28 May 2018
@nguyeho7 @pkulzc
I could really need your help understanding why the rear CONV2D takes more than 2 twice the time for the model with mobilenet v1 as backbone. What could be the reason?
gustavz
on 30 May 2018
@GustavZ
May I ask you how you configure the .config file? I use the 'mask_rcnn_inception_v2_coco.config' as you and @pkulzc mentioned above, and the slim mobilenet_v1_1.0_224, I also edited it as you posted:
fine_tune_checkpoint: "PATH/TO/mobilenet_v1_1.0_224/mobilenet_v1_1.0_224.ckpt"
from_detection_checkpoint: false
fine_tune_checkpoint_type: 'classification'
But I sitll got an error as follow:
NotFoundError (see above for traceback): Restoring from checkpoint failed. This is most likely due to a Variable name or other graph key that is missing from the checkpoint. Please ensure that you have not altered the graph expected based on the checkpoint. Original error:
Key FirstStageFeatureExtractor/MobilenetV1/Conv2d_0/BatchNorm/beta not found in checkpoint
[[Node: save/RestoreV2 = RestoreV2[dtypes=[DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, ..., DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_INT64], _device="/job:localhost/replica:0/task:0/device:CPU:0"](_arg_save/Const_0_0, save/RestoreV2/tensor_names, save/RestoreV2/shape_and_slices)]]
Any idea about this? Thank you.
 DontsingListen
on 11 Sep 2018
DontsingListen
on 11 Sep 2018
Guys, do you have any cfg file with the arch of mask rcnn + mobile net v1?
 HikkaV
on 17 Mar 2019
HikkaV
on 17 Mar 2019
Who are u? Why do you always copy to me?
发自我的 iPhone
在 2019年3月17日,21:23,Kovenko Volodymyr notifications@github.com 写道:
Guys, do you have any cfg file with the arch of mask rcnn + mobile net v1?
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub, or mute the thread.
 mchengny
on 17 Mar 2019
mchengny
on 17 Mar 2019
?
On Sun, 17 Mar 2019, 15:36 CHENG Ming, notifications@github.com wrote:
Who are u? Why do you always copy to me?
发自我的 iPhone
在 2019年3月17日,21:23,Kovenko Volodymyr notifications@github.com 写道:
Guys, do you have any cfg file with the arch of mask rcnn + mobile net
v1?—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub, or mute the thread.—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/tensorflow/models/issues/3996#issuecomment-473666446,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ArMCCpVFPr9k0F1YTgS3OAIsPCMerZwFks5vXkTygaJpZM4TX2k5
.
HikkaV
on 17 Mar 2019
I have a repo named tf_models which is a fork of the official tensor flow repo.
It's not uptodate and nearly a year old but there you find the Mask RCNN Mobilenet cfg I used
gustavz
on 17 Mar 2019
For each email you have talked today, you always copy them to me.
发自我的 iPhone
在 2019年3月17日,21:40,Kovenko Volodymyr notifications@github.com 写道:
?
On Sun, 17 Mar 2019, 15:36 CHENG Ming, notifications@github.com wrote:
Who are u? Why do you always copy to me?
发自我的 iPhone
在 2019年3月17日,21:23,Kovenko Volodymyr notifications@github.com 写道:
Guys, do you have any cfg file with the arch of mask rcnn + mobile net
v1?—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub, or mute the thread.—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/tensorflow/models/issues/3996#issuecomment-473666446,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ArMCCpVFPr9k0F1YTgS3OAIsPCMerZwFks5vXkTygaJpZM4TX2k5
.—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub, or mute the thread.
mchengny
on 17 Mar 2019
Who are you talking to @mchengny ?
You probably subscribed the issue, so just remove that and stop spamming
gustavz
on 17 Mar 2019
@gustavz, thank you, can you give me a link, cause I didn't find any cfg, maybe because of my blindness heh, I would appreciate it
HikkaV
on 17 Mar 2019
You can also have a look here for more configs, training scripts and checkpoint files:
https://github.com/gustavz/tf_training
gustavz
on 17 Mar 2019
Thank you very much, u saved me
On Sun, 17 Mar 2019, 16:24 Gustav, notifications@github.com wrote:
>
You can also have a look here for more configs, training scripts and
checkpoint files:
https://github.com/gustavz/tf_training—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/tensorflow/models/issues/3996#issuecomment-473670350,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ArMCCmLh4D73EWvTrjF4VhGPl0j8OHyEks5vXlAAgaJpZM4TX2k5
.
HikkaV
on 17 Mar 2019
Actually, i had another question, how to use your model with opencv? I im
not able to load the config into cv.dnn.readNet. Or your model is not
supposed to work with this framework?
вс, 17 мар. 2019 г. в 16:41, Hikkari Tenshin <[email protected]
:
Thank you very much, u saved me
On Sun, 17 Mar 2019, 16:24 Gustav, notifications@github.com wrote:
>
You can also have a look here for more configs, training scripts and
checkpoint files:
https://github.com/gustavz/tf_training—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/tensorflow/models/issues/3996#issuecomment-473670350,
or mute the thread
https://github.com/notifications/unsubscribe-auth/ArMCCmLh4D73EWvTrjF4VhGPl0j8OHyEks5vXlAAgaJpZM4TX2k5
.
HikkaV
on 18 Mar 2019
I exchanged my local projects path with PATH/TO as i did not want to post my whole system structure as its damn long and doesn't matter for this cause.
I tried it now for different models and different checkpoints and i am pretty sure it is not possible to load the checkpoints of MNV1 provided in research/slim as backbone for mask rcnn.
Probably the layer names differ or something similar...
EDIT1: Is it the standard way for mask rcnn models to use manually scheduled learning rates and not more advanced methods like exponential_decay_learning_rate ...?
EDIT2: Now it runs, idk whats the exact reason but i used those three options in the config:
fine_tune_checkpoint: "PATH/TO/mobilenet_v1_1.0_224/mobilenet_v1_1.0_224.ckpt" from_detection_checkpoint: false fine_tune_checkpoint_type: 'classification'
@gustavz HI! may I ask for a favor? When I set the config like this :
fine_tune_checkpoint: "PATH/TO/mobilenet_v1_1.0_224/mobilenet_v1_1.0_224.ckpt"
from_detection_checkpoint: True
the error happen while training
But when I set the config like you've set,the error gone away,now it runs!!
I'd like to know What does the 'from_detection_checkpoint: True' mean? and why did u set it to false ? and what's the meaning of fine_tune_checkpoint_type: 'classification'?
appreciate for your help!
 Look4-you
on 5 Apr 2019
Look4-you
on 5 Apr 2019
Hi There,
We are checking to see if you still need help on this, as this seems to be considerably old issue. Please update this issue with the latest information, code snippet to reproduce your issue and error you are seeing.
If we don't hear from you in the next 7 days, this issue will be closed automatically. If you don't need help on this issue any more, please consider closing this.
 tensorflowbutler
on 30 Jan 2020
tensorflowbutler
on 30 Jan 2020
Related issues
 amirjamez
·
3Comments
amirjamez
·
3Comments
 25b3nk
·
3Comments
25b3nk
·
3Comments
 jacknlliu
·
3Comments
jacknlliu
·
3Comments
 hanzy123
·
3Comments
hanzy123
·
3Comments
 kamal4493
·
3Comments
kamal4493
·
3Comments
Most helpful comment
Yes but you need to make some changes by yourselves.
We have this feature extractor ready(here) so you can train mobilenet v1 + faster rcnn or mask rcnn by doing the followings:
We don't have a config nor pre-trained checkpoint for this model yet, but you can train from scratch by yourselves.