Models: tfnightly - Unknown command line flag 'logtostderr'
System information
OS Platform and Distribution: Windows 10 64 Bit
TensorFlow installed from (source or binary): binary
TensorFlow version :1.5.0-dev20171115'
Python version 3.5.2(v3.5.2:4def2a2901a5, Jun 25 2016, 22:18:55)
GPU: nVidia GeForce 755M 2GB
CPU: Intel x64-64 Intel Core i5-4200M CPU @ 2.50Ghz, 8GB memory
Describe the problem
So, I have the same problem as described in #2653
https://github.com/tensorflow/models/issues/2653
The solution given in that is to try and install tf nightly @AlgorithmR, @radzfoto. I did that as shown below:

When I try to run the following code now:
C:\Users\kannan\Documents\MD Learning\models\research\object_detection>train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_pets.config
I get the following error:
FATAL Flags parsing error: Unknown command line flag 'logtostderr'
Pass --helpshort or --helpfull to see help on flags.
Any idea how to solve this?
 kannan60
kannan60
All 12 comments
I can confirm that this issue appears while using the latest commit to tensorflow/models (commit #1440), as well as using tf_nightly_gpu-1.5.0.dev20171115.
This was not an issue when using tf_nightly_gpu-1.5.0.dev20171027 and tensorflow/models from October 30th 2017 (commit #1370).
I haven't been able to find the culprit yet, but a temporary workaround is to omit --logtostderr for now.
 Adrrei
on 16 Nov 2017
Adrrei
on 16 Nov 2017
Hey @AlgorithmR ! Thanks for the reply! I omitted --logtostderr and tried the same command. I probably ended up with a memory allocation error from the looks of it as seen here in the PDF attached below. I know it is really long. To make it easy, I have highlighted the important errors: Page 1, 2, 106, 107, 111 and 115.
Any idea how to get around this? I am using a batch size of 1 and it possibly can't go any lower. I have used around 187 images with two classes labelled in each image. All my images are 960 by 720 pixels each. My GPU compute capability is 3.0
kannan60
on 16 Nov 2017
Have you modified the config file (ssd_mobilenet_v1_pets.config)?
Looking at the error log you submitted it seems like the batch size is 24, judging by 'Resource exhausted: OOM when allocating tensor with shape[24,19,19,256]', which is the default batch size in the config file.
Can you double check your config file?
Adrrei
on 16 Nov 2017
@AlgorithmR Oh my god...You are right!!!! *THE SAVIOUR! * I just changed it to '1' now and it is training. By the way, what do I lose by not using the logtostderr command? and when do you know the training is sufficient? 300 steps have been executed and the loss rate is around 40-3 (keeps fluctuating). To stop the training it is ctrl + c, yes?
kannan60
on 16 Nov 2017
@kannan60 I'm glad the issue is resolved!
You might want to increase the batch size as high as you can to decrease the fluctuations of the results, but in the long run the end-results are more or less the same. The research on whether one should choose a low or high batch size is still in the early stages.
I believe logtostderr writes debug information to a temporary file, but I'm not 100% sure regarding this.
Generally speaking, the lower the loss the better. There's really no way of knowing when you have the optimal result just looking at loss and training steps however. If you run the command 'tensorboard --logdir=path-to-training-and-testing-checkpoints' in a command prompt, and then open 'http://localhost:6006/#scalar' in your browser, you'll see the precision of your network. At some point it reaches its peak and starts to lose precision, and that's when you've found an optimal model. You also need to take overfitting into consideration.
Seeing as you installed TensorFlow using the nighthly version, you'll need to install tensorboard separately if you haven't already. You can do this with pip: 'pip install tensorflow-tensorboard'.
If you head over to 'models\research\object_detectionprotos' you'll find a file called 'train.proto'. Here you can change the 'keep_checkpoint_every_n_hours' default value from 1000 to something more suitable like 1 for instance (depending on how much storage you have). This allows you to for instance train your model over night, and then choose a checkpoint that is closer to the optimal one instead of always having to monitor the progress. Otherwise it'll just keep the 5(?) latest checkpoints and delete the old ones.
And yes, you can terminate the training by using 'CTRL + C'. :)
Adrrei
on 16 Nov 2017
Heyy @AlgorithmR! So, I followed your steps and ended up with the loss_rate graph as shown.
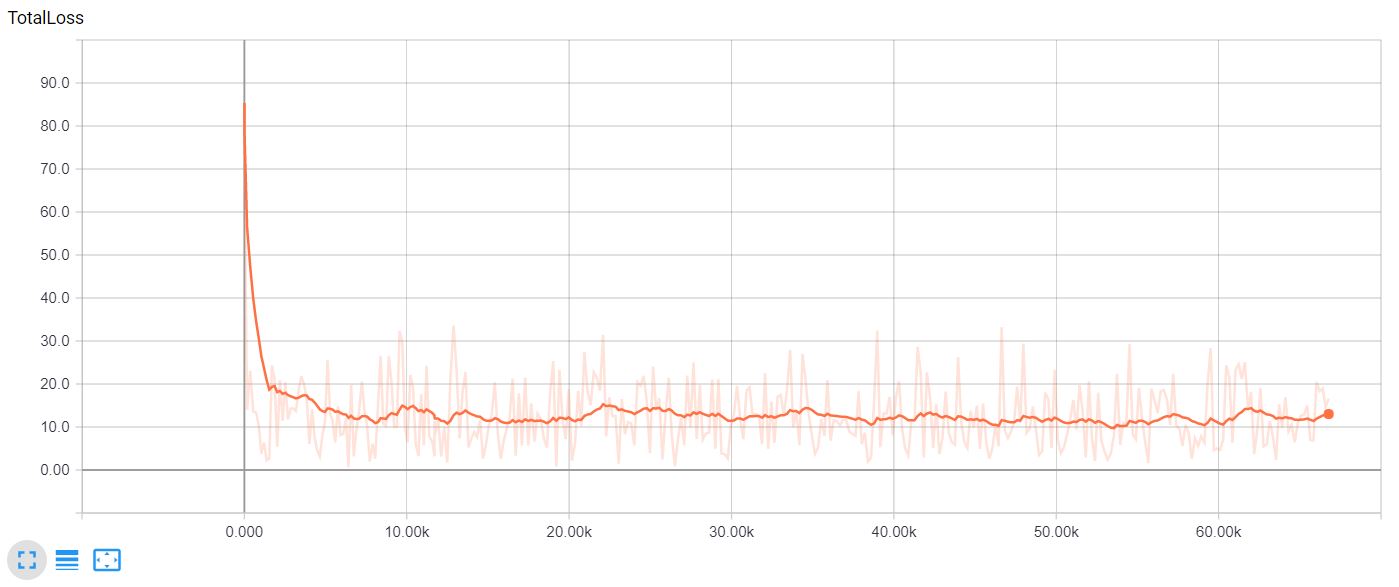
It has been running for well over 12 hours now with a batch size of 1(just to check if it works or not). As you can see the lowest loss is still around 10. Sentedx recommends it to be less than two for a robust model. It is still running. Maybe, I should leave it for one more day to see the progress? If not, I should try increasing the batch size, yeah? Coming to think of it, the problem could be because I am trying to differentiate two classes that are very similar to each other(crops and weeds). What are your recommendations?
Yes, you are right. It keeps the latest 5 checkpoints and deletes the other ones automatically. If I were to train again with a different batch size, would it overwrite these files?
kannan60
on 17 Nov 2017
There are too many factors to know for sure what the ideal solution is. You could try to evaluate the data and see how it performs. That'll give you the mAP (mean average precision) for all of the classes. You can then use this data to see whether or not you should keep training.
You also have to keep in mind how large your dataset is. If you train too much on the same dataset it will overfit, which could ruin the model. Ideally you want to run both the training and the testing simultaneously (train.py and eval.py), as you can then continuously monitor and track the progress of the model. This may, however, not be possible depending on how much memory your GPU has (2 GB isn't a lot for this type of work, but it works for simpler architectures).
If you start evaluating now it'll only evaluate the latest checkpoint. I submitted a pull request a couple of weeks ago (allowing you to evaluate multiple checkpoints) at once. Nothing fancy, but gets the job done for my purposes. That way you won't have to modify the checkpoint file.
If you alter the parameters for the model it should just keep going from whichever checkpoint you're currently at (but will still only keep the latest five unless you change that behavior).
The best way is to just experiment. Write down your configurations and see how changing various parameters alters the results. There's a lot you can configure in your '.config' file. For instance, adding
data_augmentation_options {
random_horizontal_flip {
}
}
in your train_config: { ... } for ssd_mobilenet_v1_pets.config is usually a good idea.
Adrrei
on 17 Nov 2017
@AlgorithmR Thank you so much for that! Really appreciate your help :) So, I finally stopped training and the loss rate was around 8. I anyway tried testing my model with a few test images. I followed through sentdex tutorial 6 on object detection API. However, there are no bounding boxes drawn on any of the images after testing. There is no error also in the jupyter notebook. I have a doubt regarding the object-detection.pbtxt file though. I have been using pycharm for all .py and .config files basically through the tutorial series. Is this the way to create the .pbtxt file for multiple classes?

I am not sure why there are no bounding boxes. Maybe I should try training the model with a higher batch size as well.
kannan60
on 17 Nov 2017
@kannan60 Your pbtxt file is setup correctly. Have you also specified '2' classes in the .config file? If you're not getting any bounding boxes it might mean that A) there's not enough data to train the model, B) the model is overfitting, C) you haven't trained enough, or D) your model is somewhat accurate, but doesn't find anything for your specific test set.
How many images do you have for training? What does the mAP graph show?
Adrrei
on 17 Nov 2017
@AlgorithmR Hey! So, I tried running the classic mac_and_cheese dataset to make sure the method is working. I got decent results for mac and cheese images(mostly 98% over). However, it classified pizza and burgers as macncheese. Luckily, it did not classify anything for the dog image. Btw, I was able to use TF v 1.4 this time around and I had no trouble getting it to work. I even uninstalled the TF Nightly build. Also, I was able to use --logtostderr this time around surprisingly! I had to, however, reduce the batch size to 5 and train for about six hours to get this result.
So, now coming to the crop and weed problem. I should perhaps try using a batch size of 5 to see what I end up with. So, here is a random image that is in the training dataset.

As you can see the bigger vegetation are the crops and the smaller ones are the weeds. I managed to manually label around 187 such images (at least 10 bounding boxes per image). As mentioned earlier, the images are all 960 by 720 pixels. Even the testing dataset is very similar to the training dataset. I am surprised it did not come up with any bounding boxes. Btw, how do I check the mAP graph? I could not find that graph on the tensorboard. I was only tracking the total loss to be less than 1.5~2.
I am also working on using segmentation techniques to completely isolate the crop and weed before it is fed into the network for training. I am not too sure if that will make any difference. I will post the results of the segmented image in the next reply. I can get more data for training. How will I know if the model is overfitting? But, even if does overfit, should it not at least draw the bounding box around everything it sees?
kannan60
on 20 Nov 2017
Update:
I cannot see the images and the IOU chart. What I get in the images tab is “No image data was found”. While in the scalar tab the “Precision” section is missing together with PerformanceByCategory and maybe others (but I have Loss, TotalLoss, Learning_Rate, batch, queue , etc,…).
kannan60
on 23 Nov 2017
Hi There,
We are checking to see if you still need help on this, as this seems to be considerably old issue. Please update this issue with the latest information, code snippet to reproduce your issue and error you are seeing.
If we don't hear from you in the next 7 days, this issue will be closed automatically. If you don't need help on this issue any more, please consider closing this.
 tensorflowbutler
on 30 Jan 2020
tensorflowbutler
on 30 Jan 2020
Related issues
 licaoyuan123
·
3Comments
licaoyuan123
·
3Comments
 xbcReal
·
3Comments
xbcReal
·
3Comments
 Mostafaghelich
·
3Comments
Mostafaghelich
·
3Comments
 sun9700
·
3Comments
sun9700
·
3Comments
 chenyuZha
·
3Comments
chenyuZha
·
3Comments
Most helpful comment
@kannan60 I'm glad the issue is resolved!
You might want to increase the batch size as high as you can to decrease the fluctuations of the results, but in the long run the end-results are more or less the same. The research on whether one should choose a low or high batch size is still in the early stages.
I believe logtostderr writes debug information to a temporary file, but I'm not 100% sure regarding this.
Generally speaking, the lower the loss the better. There's really no way of knowing when you have the optimal result just looking at loss and training steps however. If you run the command 'tensorboard --logdir=path-to-training-and-testing-checkpoints' in a command prompt, and then open 'http://localhost:6006/#scalar' in your browser, you'll see the precision of your network. At some point it reaches its peak and starts to lose precision, and that's when you've found an optimal model. You also need to take overfitting into consideration.
Seeing as you installed TensorFlow using the nighthly version, you'll need to install tensorboard separately if you haven't already. You can do this with pip: 'pip install tensorflow-tensorboard'.
If you head over to 'models\research\object_detectionprotos' you'll find a file called 'train.proto'. Here you can change the 'keep_checkpoint_every_n_hours' default value from 1000 to something more suitable like 1 for instance (depending on how much storage you have). This allows you to for instance train your model over night, and then choose a checkpoint that is closer to the optimal one instead of always having to monitor the progress. Otherwise it'll just keep the 5(?) latest checkpoints and delete the old ones.
And yes, you can terminate the training by using 'CTRL + C'. :)