Models: Problem with the new train and eval updates
System information
- What is the top-level directory of the model you are using: object_detection
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): no
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Win7
- TensorFlow installed from (source or binary): binary
- TensorFlow version (use command below): 1.4
- Bazel version (if compiling from source):
- CUDA/cuDNN version: 8/6.1
- GPU model and memory: Titan X
- Exact command to reproduce:
Describe the problem
Describe the problem clearly here. Be sure to convey here why it's a bug in TensorFlow or a feature request.
I used to use object detection to fine tune the coco trained model on SSD_Mobilenet with only 3 classes on my data and it worked fine until this new updates of train.py, eval.py, and other dependent files.
the training log used to be like this:
#
WARNING:tensorflow:From C:\TensorflowModels_v0\object_detection\trainer.py:178: create_global_step (from tensorflow.contrib.framework.python.ops.variables) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.train.create_global_step
WARNING:tensorflow:From C:\TensorFlowModels_v0\object_detection\builders\optimizer_builder.py:92: get_or_create_global_step (from tensorflow.contrib.framework.python.ops.variables) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.train.get_or_create_global_step
INFO:tensorflow:Summary name Learning Rate is illegal; using Learning_Rate instead.
WARNING:tensorflow:From C:\TensorFlowModels_v0\object_detection\meta_architectures\ssd_meta_arch.py:607: all_variables (from tensorflow.python.ops.variables) is deprecated and will be removed after 2017-03-02.
Instructions for updating:
Please use tf.global_variables instead.
INFO:tensorflow:Summary name /clone_loss is illegal; using clone_loss instead.
INFO:tensorflow:Restoring parameters from D:/object_detection/models/ssd_mobilenet_v1_coco_11_06_2017/model.ckpt
INFO:tensorflow:Starting Session.
INFO:tensorflow:Saving checkpoint to path D:/object_detection/models0/model.ckpt
INFO:tensorflow:Starting Queues.
INFO:tensorflow:global_step/sec: 0
INFO:tensorflow:Recording summary at step 0.
INFO:tensorflow:global step 1: loss = 22.9493 (30.222 sec/step)
INFO:tensorflow:global step 2: loss = 20.2359 (3.919 sec/step)
INFO:tensorflow:global step 3: loss = 18.7402 (3.793 sec/step)
INFO:tensorflow:global step 4: loss = 17.9404 (3.978 sec/step)
INFO:tensorflow:global step 5: loss = 17.1826 (3.588 sec/step)
INFO:tensorflow:global step 6: loss = 15.8118 (3.605 sec/step)
INFO:tensorflow:global step 7: loss = 15.1282 (3.416 sec/step)
INFO:tensorflow:global step 8: loss = 14.2844 (3.338 sec/step)
INFO:tensorflow:global step 9: loss = 13.7035 (3.416 sec/step)
INFO:tensorflow:global step 10: loss = 14.0352 (3.245 sec/step)
INFO:tensorflow:global step 11: loss = 13.6083 (3.279 sec/step)
INFO:tensorflow:global step 12: loss = 11.4007 (3.323 sec/step)
INFO:tensorflow:global step 13: loss = 11.8029 (3.354 sec/step)
INFO:tensorflow:global step 14: loss = 10.7637 (3.338 sec/step)
INFO:tensorflow:global step 15: loss = 10.5538 (3.370 sec/step)
INFO:tensorflow:global step 16: loss = 9.9638 (3.323 sec/step)
INFO:tensorflow:global step 17: loss = 10.5116 (3.276 sec/step)
INFO:tensorflow:global step 18: loss = 11.0982 (3.338 sec/step)
INFO:tensorflow:global step 19: loss = 9.9132 (3.307 sec/step)
INFO:tensorflow:global step 20: loss = 9.5878 (3.387 sec/step)
#
however when I use the version with recent updates I get this report:
#
WARNING:tensorflow:From research\object_detection\trainer.py:210: create_global_step (from tensorflow.contrib.framework.python.ops.variables) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.train.create_global_step
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:Summary name /clone_loss is illegal; using clone_loss instead.
INFO:tensorflow:Restoring parameters from D:/object_detection/models/ssd_mobilenet_v1_coco_11_06_2017/model.ckpt
INFO:tensorflow:Starting Session.
INFO:tensorflow:Saving checkpoint to path G:/object_detection/models1/model.ckpt
INFO:tensorflow:Starting Queues.
INFO:tensorflow:global_step/sec: 0
INFO:tensorflow:Recording summary at step 0.
INFO:tensorflow:global step 1: loss = 88.5192 (29.360 sec/step)
INFO:tensorflow:global step 2: loss = 85.8423 (3.781 sec/step)
INFO:tensorflow:global step 3: loss = 74.9890 (3.584 sec/step)
INFO:tensorflow:global step 4: loss = 65.3577 (3.572 sec/step)
INFO:tensorflow:global step 5: loss = 46.6875 (3.479 sec/step)
INFO:tensorflow:global step 6: loss = 37.5350 (3.323 sec/step)
INFO:tensorflow:global step 7: loss = 39.2690 (3.402 sec/step)
INFO:tensorflow:global step 8: loss = 50.3077 (3.310 sec/step)
INFO:tensorflow:global step 9: loss = 28.0526 (3.324 sec/step)
INFO:tensorflow:global step 10: loss = 31.1548 (3.349 sec/step)
INFO:tensorflow:global step 11: loss = 32.1967 (3.335 sec/step)
INFO:tensorflow:global step 12: loss = 34.1146 (3.309 sec/step)
INFO:tensorflow:global step 13: loss = 22.3245 (3.358 sec/step)
INFO:tensorflow:global step 14: loss = 20.3864 (3.393 sec/step)
INFO:tensorflow:global step 15: loss = 21.3323 (3.311 sec/step)
INFO:tensorflow:global step 16: loss = 20.5359 (3.361 sec/step)
INFO:tensorflow:global step 17: loss = 19.8039 (3.393 sec/step)
INFO:tensorflow:global step 18: loss = 20.1648 (3.413 sec/step)
INFO:tensorflow:global step 19: loss = 18.7674 (3.424 sec/step)
INFO:tensorflow:global step 20: loss = 13.9156 (3.356 sec/step)
#
this does not lead to good results. The initial loss seems to be 4 times the loss I used to get. So I had to go back using previous version of object detection.
 starwars110
starwars110
All 27 comments
It looks like similar to issue #2749. I also get very bad mAP
starwars110
on 10 Nov 2017
update:
I tried the new model posted today for ssd_mobilenet_coco but got similar results. It looks like the problem is with box proposals:
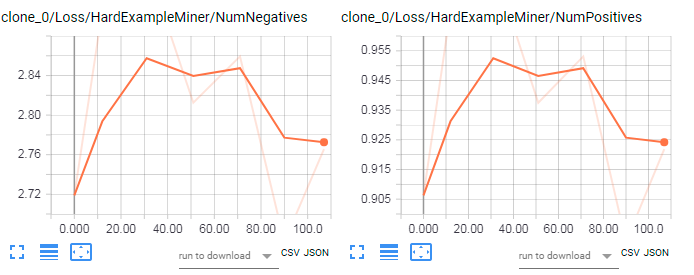
while for previous version I get this:
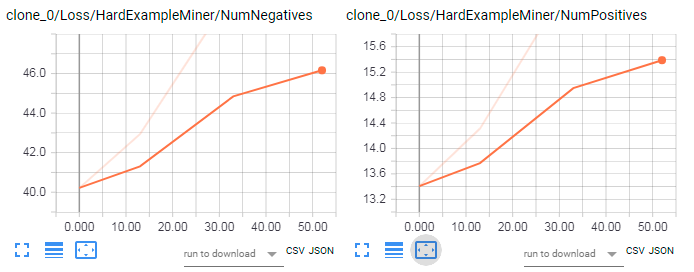
starwars110
on 10 Nov 2017
@starwars110 from what i can tell you are using a older version of the model that might not be compatible with the latest code. Could you please switch to latest in the model zoo and retry ? https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
 tombstone
on 10 Nov 2017
tombstone
on 10 Nov 2017
Greetings everyone, I am getting precisely the same error that @starwars110 is reporting. For reference purposes, based on the advice I updated my model from the detection_model_zoo.md to ssd_mobilenet_v1_coco_2017_11_08.tar.gz.
I am still receiving the same errors.
 rudycazabon
on 10 Nov 2017
rudycazabon
on 10 Nov 2017
I tried the network with the new released ssd_mobilenet_v1_coco_2017_11_08.tar.gz model, but no success.
The old version works well even with this new model. Tried also generating tf records again with the new version, but did not hep.
As my last option, I tried the standard pet detector, but still observed similar behavior in terms of number of boxes.
this might only happens on windows version? since others could make it work on unix.
starwars110
on 11 Nov 2017
I have the same problem with you ,using the ssd_mobilenet_v1_coco_2017_11_08.tar.gz model, get bad mAP(≈0), even replace the 【test.record】 with 【train.record】
and when perform validation,it turns out:
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
2017-11-14 18:51:09.416984: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
2017-11-14 18:51:09.617988: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: GeForce GTX 1080 Ti major: 6 minor: 1 memoryClockRate(GHz): 1.6575
pciBusID: 0000:05:00.0
totalMemory: 10.91GiB freeMemory: 10.44GiB
2017-11-14 18:51:09.618015: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:05:00.0, compute capability: 6.1)
INFO:tensorflow:Restoring parameters from object_detection/400/train/model.ckpt-5000
INFO:tensorflow:Restoring parameters from object_detection/400/train/model.ckpt-5000
WARNING:root:image 0 does not have groundtruth difficult flag specified
2017-11-14 18:51:14.496987: W tensorflow/core/framework/op_kernel.cc:1192] Out of range: FIFOQueue '_3_prefetch_queue' is closed and has insufficient elements (requested 1, current size 0)
[[Node: prefetch_queue_Dequeue = QueueDequeueV2[component_types=[DT_UINT8, DT_STRING, DT_STRING, DT_STRING, DT_FLOAT, DT_FLOAT, DT_BOOL, DT_INT64, DT_INT64, DT_INT64], timeout_ms=-1, _device="/job:localhost/replica:0/task:0/device:CPU:0"](prefetch_queue)]]
#【W the same as above】
#【W the same as above】
#【W the same as above】
、、、、、、
the warning doesn't show on when i use the old version in 2017.09 with 【window10】
- What is the top-level directory of the model you are using: object_detection
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow): no
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): ubuntu16.04
- TensorFlow installed from (source or binary): binary
- TensorFlow version (use command below): 1.4.0
- Bazel version (if compiling from source):
- CUDA/cuDNN version: 8.0/6.0
- GPU model and memory: 1080Ti
I haven`t try old version in this computer
I try to use faster_rcnn_resnet50_coco_2017_11_08.tar.gz(with its .config) instead, that work out and get high accuracy(mAP=0.92), can anybody use the ssd+mobilenet success?
 liuxinyuk
on 14 Nov 2017
liuxinyuk
on 14 Nov 2017
@starwars110 @liuxinyuk we updated the SSD models yet again. Can you please retry and let us know if this solves the problem?
tombstone
on 18 Nov 2017
Still I see the problem for training. But the inference for the updated model now shows the bboxes.
starwars110
on 21 Nov 2017
it works!Thank you!
I download the tensorflow/models again in 2017.11.21 (also reinstall the Ubuntu16.04 system in this date)
and download the Newest SSD model——ssd_mobilenet_v1_coco_2017_11_17.tar.gz
it gets 0.83 mAP in my own dataset
liuxinyuk
on 22 Nov 2017
Hi!
I am an Electronics Engineer working on a device for visually impaired people. I am just following the tutorials for it. I got this big list of errors. Please can someone guide me through this.
(tensorflow) C:\Users\sushi\AnacondaProjects\Tensorflow\models\research\object_detection>python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_pets.config
WARNING:tensorflow:From C:\Users\sushi\Anaconda3\envs\tensorflow\lib\site-packages\object_detection-0.1-py3.5.egg\object_detection\trainer.py:210: create_global_step (from tensorflow.contrib.framework.python.ops.variables) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.train.create_global_step
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:depth of additional conv before box predictor: 0
Traceback (most recent call last):
File "train.py", line 163, in <module>
tf.app.run()
File "C:\Users\sushi\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\platform\app.py", line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File "train.py", line 159, in main
worker_job_name, is_chief, FLAGS.train_dir)
File "C:\Users\sushi\Anaconda3\envs\tensorflow\lib\site-packages\object_detection-0.1-py3.5.egg\object_detection\trainer.py", line 254, in train
var_map, train_config.fine_tune_checkpoint))
File "C:\Users\sushi\Anaconda3\envs\tensorflow\lib\site-packages\object_detection-0.1-py3.5.egg\object_detection\utils\variables_helper.py", line 122, in get_variables_available_in_checkpoint
File "C:\Users\sushi\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\pywrap_tensorflow_internal.py", line 158, in NewCheckpointReader
return CheckpointReader(compat.as_bytes(filepattern), status)
File "C:\Users\sushi\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\framework\errors_impl.py", line 473, in __exit__
c_api.TF_GetCode(self.status.status))
tensorflow.python.framework.errors_impl.NotFoundError: Unsuccessful TensorSliceReader constructor: Failed to find any matching files for ssd_mobilenet_v1_coco_2017_11_17/model.ckpt
 sushilmdpatil
on 30 Dec 2017
sushilmdpatil
on 30 Dec 2017
@sushilmdpatil your question is better asked on StackOverflow since it is not a bug or feature request. There is also a larger community that reads questions there. Thanks!
 bignamehyp
on 31 Dec 2017
bignamehyp
on 31 Dec 2017
@sushilmdpatil Hello, did you solved this issue ? I'm having the same. Thanks
 Draichi
on 16 Feb 2018
Draichi
on 16 Feb 2018
@Draichi No I couldn't I am planning to use cloud now. So left it completely. I guess you should ask on stackoverflow, the community support there is much better.
sushilmdpatil
on 16 Feb 2018
@liuxinyuk , Hi , i can't not reach to high mAP , please mention your step for eval.py , do you run both train.py and eval.py at the same time ? How many num_steps/batch_size/train_dataset/num_classes did you have?
i and when i run both train and eval at the same time i get this error :
https://stackoverflow.com/questions/49033008/gpu-memory-error-with-train-py-and-eval-py-running-at-the-same-time
 PythonImageDeveloper
on 28 Feb 2018
PythonImageDeveloper
on 28 Feb 2018
@sushilmdpatil @Draichi Could you solve this problem. I am using tensor flow 1.4, model : ssd_mobilenet_v1_coco_2017_11_17.
Inference of existing models are working fine, but re-training of same existing model screws up the results. Any help here is appreciated.
 poddar414
on 13 Mar 2018
poddar414
on 13 Mar 2018
@zeynali ,hello,Did you solve this problem now?
 zhouzhubin
on 24 May 2018
zhouzhubin
on 24 May 2018
@poddar414 it looks like there is a conflict when you try to update a trained model with custom data - and run it in your own machine.
People seem to get more success when doing this on cloud, like google cloud platform, because of modules/libs/packages versions are automacally setted.
Draichi
on 25 May 2018
Hi,I also meet the problem....
I am new to Tensorflow,So I don't know how to solve the problem.
the executed command:python eval.py --logtostderr --pipeline_config_path=ssd_mobilenet_v1_coco.config --checkpoint_dir=./models/train --eval_dir=./models/eval
environment:Windows10,tensorflow1.8,python3.5
the eval.py was download in github in 2018/5/20.
I have used the model which trained based on my own dataset,it works,I can use the model to detect objects ,But I can't use the eval.py to test my accuracy!
 kellenf
on 31 May 2018
kellenf
on 31 May 2018
apparently this new version is conflict with training.
PythonImageDeveloper
on 31 May 2018
Hi,I also meet the problem....
WARNING:tensorflow:From /home/panamon/tamizh/models/research/object_detection/trainer.py:176: create_global_step (from tensorflow.contrib.framework.python.ops.variables) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.train.create_global_step
Traceback (most recent call last):
File "train.py", line 198, in
tf.app.run()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/platform/app.py", line 124, in run
_sys.exit(main(argv))
File "train.py", line 194, in main
worker_job_name, is_chief, FLAGS.train_dir)
File "/home/panamon/tamizh/models/research/object_detection/trainer.py", line 184, in train
data_augmentation_options)
File "/home/panamon/tamizh/models/research/object_detection/trainer.py", line 59, in _create_input_queue
tensor_dict = create_tensor_dict_fn()
File "/home/panamon/tamizh/models/research/object_detection/builders/input_reader_builder.py", line 73, in build
label_map_proto_file=label_map_proto_file)
File "/home/panamon/tamizh/models/research/object_detection/data_decoders/tf_example_decoder.py", line 271, in __init__
use_display_name)
File "/home/panamon/tamizh/models/research/object_detection/utils/label_map_util.py", line 152, in get_label_map_dict
label_map = load_labelmap(label_map_path)
File "/home/panamon/tamizh/models/research/object_detection/utils/label_map_util.py", line 132, in load_labelmap
label_map_string = fid.read()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/lib/io/file_io.py", line 119, in read
self._preread_check()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/lib/io/file_io.py", line 79, in _preread_check
compat.as_bytes(self.__name), 1024 * 512, status)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/framework/errors_impl.py", line 473, in __exit__
c_api.TF_GetCode(self.status.status))
tensorflow.python.framework.errors_impl.NotFoundError: training/object-detection.pbtxt; No such file or directory
 tamizharasank
on 18 Jul 2018
tamizharasank
on 18 Jul 2018
i meet this problem please help me
Traceback (most recent call last):
File "train.py", line 198, in
tf.app.run()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/platform/app.py", line 124, in run
_sys.exit(main(argv))
File "train.py", line 194, in main
worker_job_name, is_chief, FLAGS.train_dir)
File "/home/panamon/tamizh2/object-detection/models/research/object_detection/trainer.py", line 192, in train
clones = model_deploy.create_clones(deploy_config, model_fn, [input_queue])
File "/home/panamon/tamizh2/object-detection/models/research/slim/deployment/model_deploy.py", line 193, in create_clones
outputs = model_fn(args, *kwargs)
File "/home/panamon/tamizh2/object-detection/models/research/object_detection/trainer.py", line 124, in _create_losses
images = tf.concat(images, 0)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/ops/array_ops.py", line 1129, in concat
return identity(values[0], name=scope)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/ops/array_ops.py", line 127, in identity
return gen_array_ops.identity(input, name=name)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/ops/gen_array_ops.py", line 2134, in identity
"Identity", input=input, name=name)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/framework/op_def_library.py", line 513, in _apply_op_helper
raise err
TypeError: Cannot convert a list containing a tensor of dtype
tamizharasank
on 19 Jul 2018
@tamizharasank did you solve this error? I got the same error
 Adibhatt95
on 24 Jul 2018
Adibhatt95
on 24 Jul 2018
Greeting everyone,I had used model_main.py to train a faster_resnet_inception_astrous_coco model ,and I see the mAP value at step 3488 in tensorboard is 0.81, but when I use eval.py to evaluate
the same checkpoint ,I found the mAP is 0.68, Could anybody help me explain? Add: I use the same config file and the same checkpoint file.
 swg209
on 8 Oct 2018
swg209
on 8 Oct 2018
Best to solve this very simply is to download this file ssd_mobilenet_v1_coco_2017_11_17.tar.gz into your directory and use it in code - it worked for me. Remember mscoco_label_map.pbtxt and ssd_mobilenet_v1_coco.config need to be in data folder
 soumen29dec
on 5 Mar 2019
soumen29dec
on 5 Mar 2019
Hi There,
We are checking to see if you still need help on this, as this seems to be considerably old issue. Please update this issue with the latest information, code snippet to reproduce your issue and error you are seeing.
If we don't hear from you in the next 7 days, this issue will be closed automatically. If you don't need help on this issue any more, please consider closing this.
 tensorflowbutler
on 30 Jan 2020
tensorflowbutler
on 30 Jan 2020
Yes please close the issue for me. Actually i posted solution to the issue
reported by someone else
Thanks!
On Thu, 30 Jan, 2020, 5:02 AM Alfred Sorten Wolf, notifications@github.com
wrote:
Hi There,
We are checking to see if you still need help on this, as this seems to be
considerably old issue. Please update this issue with the latest
information, code snippet to reproduce your issue and error you are seeing.
If we don't hear from you in the next 7 days, this issue will be closed
automatically. If you don't need help on this issue any more, please
consider closing this.—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/tensorflow/models/issues/2761?email_source=notifications&email_token=AK6FAAASSLKO5AUUZNTBFOTRAIGZZA5CNFSM4EDDIZ7KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEKJEZRI#issuecomment-580013253,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AK6FAAADX6DFVJ4BLF5DI4DRAIGZZANCNFSM4EDDIZ7A
.
soumen29dec
on 30 Jan 2020
@starwars110
Is this still an issue?
Please, close this thread if your issue was resolved.Thanks!
 ravikyram
on 10 Jul 2020
ravikyram
on 10 Jul 2020
Related issues
 sun9700
·
3Comments
sun9700
·
3Comments
 dsindex
·
3Comments
dsindex
·
3Comments
 xbcReal
·
3Comments
xbcReal
·
3Comments
 25b3nk
·
3Comments
25b3nk
·
3Comments
 licaoyuan123
·
3Comments
licaoyuan123
·
3Comments
Most helpful comment
i meet this problem please help me to (Tensor is: )
Traceback (most recent call last):
File "train.py", line 198, in
tf.app.run()
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/platform/app.py", line 124, in run
_sys.exit(main(argv))
File "train.py", line 194, in main
worker_job_name, is_chief, FLAGS.train_dir)
File "/home/panamon/tamizh2/object-detection/models/research/object_detection/trainer.py", line 192, in train
clones = model_deploy.create_clones(deploy_config, model_fn, [input_queue])
File "/home/panamon/tamizh2/object-detection/models/research/slim/deployment/model_deploy.py", line 193, in create_clones
outputs = model_fn(args, *kwargs)
File "/home/panamon/tamizh2/object-detection/models/research/object_detection/trainer.py", line 124, in _create_losses
images = tf.concat(images, 0)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/ops/array_ops.py", line 1129, in concat
return identity(values[0], name=scope)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/ops/array_ops.py", line 127, in identity
return gen_array_ops.identity(input, name=name)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/ops/gen_array_ops.py", line 2134, in identity
"Identity", input=input, name=name)
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/framework/op_def_library.py", line 513, in _apply_op_helper
raise err
TypeError: Cannot convert a list containing a tensor of dtype