Models: INFO:tensorflow:Summary name /clone_loss is illegal (Object Detection)
System information:
tensorflow version:1.3.0
platform:ubuntu16.04
python version:python2.7
Dataset:Oxford-IIIT pet dataset
memory:16G
Describe the problem:
I want use pet-train-model(object detection), and use Oxford-IIIT pet dataset, but I don't know how to slove this problem
code:
object_detection/train.py \
--logtostderr \
--pipeline_config_path=/notebooks/models/research/20171102/faster_rcnn_resnet152_pets.config \
--train_dir=/notebooks/models/research/20171102
This step is very slow, and I have the next error/output:
‘
INFO:tensorflow:Scale of 0 disables regularizer.
INFO:tensorflow:Scale of 0 disables regularizer.
INFO:tensorflow:Scale of 0 disables regularizer.
INFO:tensorflow:Scale of 0 disables regularizer.
INFO:tensorflow:Scale of 0 disables regularizer.
INFO:tensorflow:depth of additional conv before box predictor: 0
INFO:tensorflow:Scale of 0 disables regularizer.
INFO:tensorflow:Summary name /clone_loss is illegal; using clone_loss instead.
/usr/local/lib/python2.7/dist-packages/tensorflow/python/ops/gradients_impl.py:95: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
"Converting sparse IndexedSlices to a dense Tensor of unknown shape. "
INFO:tensorflow:Restoring parameters from /notebooks/models/research/20171102/model.ckpt-0
INFO:tensorflow:Starting Session.
INFO:tensorflow:Saving checkpoint to path /notebooks/models/research/20171102/model.ckpt
INFO:tensorflow:Starting Queues.
INFO:tensorflow:global_step/sec: 0
INFO:tensorflow:Recording summary at step 0.
INFO:tensorflow:global step 1: loss = 399077933056.0000 (119.271 sec/step)’
INFO:tensorflow:Error reported to Coordinator:
[[Node: CheckNumerics = CheckNumerics[T=DT_FLOAT, message="LossTensor is inf or nan.", _device="/job:localhost/replica:0/task:0/cpu:0"](total_loss)]]
Caused by op u'CheckNumerics', defined at:
File "/usr/lib/python2.7/runpy.py", line 174, in _run_module_as_main
"__main__", fname, loader, pkg_name)
File "/usr/lib/python2.7/runpy.py", line 72, in _run_code
exec code in run_globals
...
InvalidArgumentError (see above for traceback): LossTensor is inf or nan. : Tensor had NaN values
[[Node: CheckNumerics = CheckNumerics[T=DT_FLOAT, message="LossTensor is inf or nan.", _device="/job:localhost/replica:0/task:0/cpu:0"](total_loss)]]
 CoderGxw
CoderGxw
All 14 comments
Can you please sync models to HEAD and run with tensorflow 1.4 to see if you can reproduce this issue? Thanks.
 bignamehyp
on 7 Nov 2017
bignamehyp
on 7 Nov 2017
I'm on HEAD and TF 1.4, and can reproduce this error with ResNet-101.
 ZizhengTai
on 7 Nov 2017
ZizhengTai
on 7 Nov 2017
Some people say this is because the memory is not enough,But I set the virtual memory (SWAP)60G still can not solve this problem
CoderGxw
on 8 Nov 2017
Is the model in /notebooks/models/research/20171102 an official Google model and a customized model? This question is better asked in stackoverflow.
bignamehyp
on 8 Nov 2017
Hi @CoderGxw - we have not released any pre-trained models for Resnet 152 and the default Faster R-CNN configs don't like to be trained from scratch --- I recommend trying with Resnet 101 and making sure that you've downloaded the pre-trained model to initialize from.
 jch1
on 9 Nov 2017
jch1
on 9 Nov 2017
@bignamehyp Thank you for your suggestion, sorry for posting the issue in the wrong place ,and next time I will pay attention it. I upgraded all the software and then failed to reproduce the problem,I think this problem may be due to my previous software version。The environment version I am using now is:python3.5 / tensorflow1.4 / ubuntu17.04 / swap(100G)
CoderGxw
on 15 Nov 2017
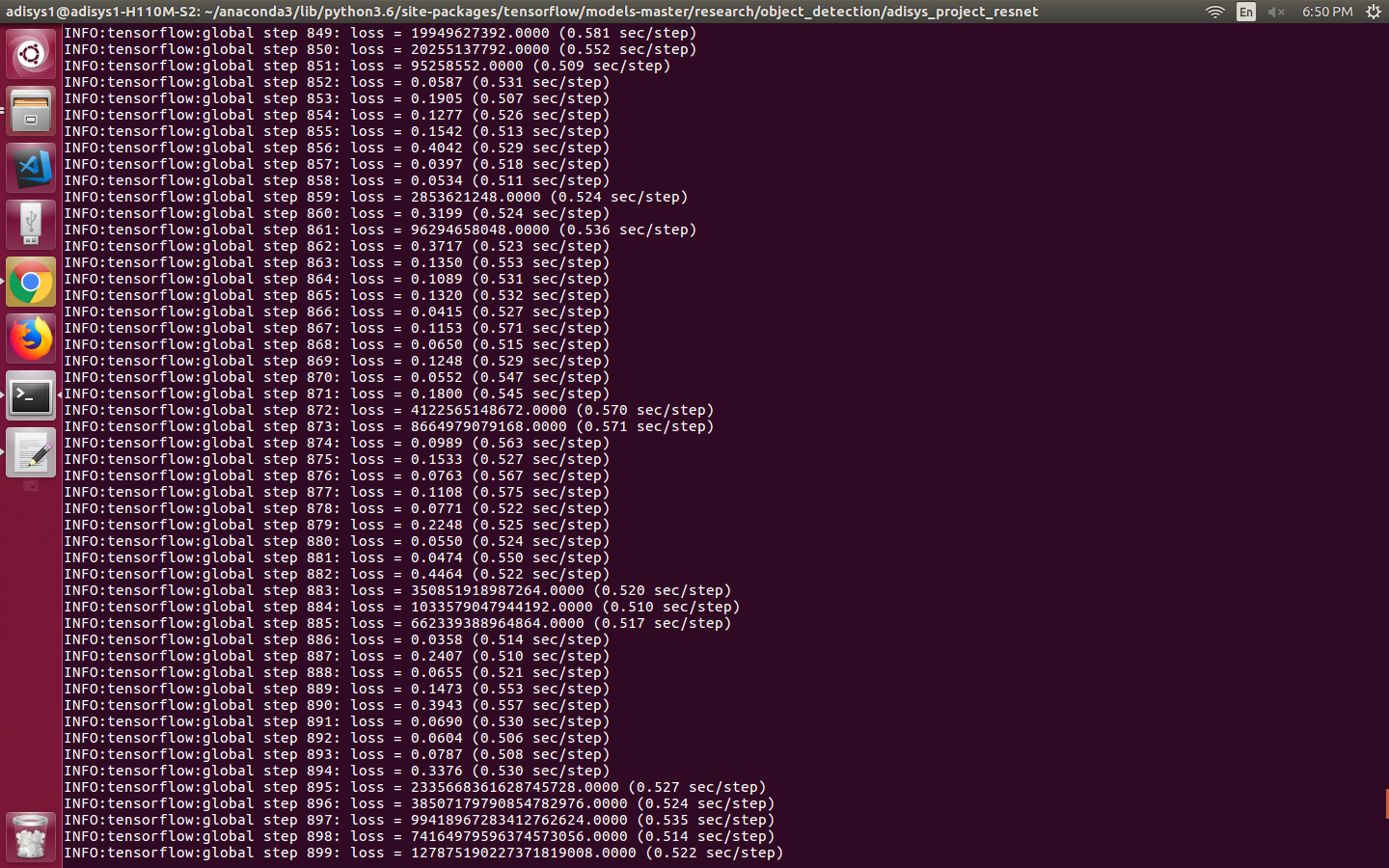
My system configurations:
Tensorflow gpu 1.5
Cuda 9.0/9.1
GTX 1050 Ti
The training worked well whileon cpu, but with gpu all though the speed is high, the lossess are bizzare.
Kindly suggest, as to what might be the cause?
 imvinaypatil
on 20 Feb 2018
imvinaypatil
on 20 Feb 2018
@imvinaypatil I also occoured this situation when traing a image classifiter using slim, and configuring the "num_classes" according to my task worked. I think modifying the "num_classes=N"(noted that the default number class N probably isn't consist on your task) in your *.config file may help.
 DontsingListen
on 7 Mar 2018
DontsingListen
on 7 Mar 2018
hi @DontsingListen I too am having the same problem and have tried your suggestion, but in vain. My num_classes is set to 1 in the pipeline.config file. I am using the faster rcnn resnet 50 model.
 sjaiswal25
on 8 Mar 2018
sjaiswal25
on 8 Mar 2018
same problem with @imvinaypatil =(
 AlekseySh
on 20 Apr 2018
AlekseySh
on 20 Apr 2018
@imvinaypatil You solved this problem?
AlekseySh
on 20 Apr 2018
Hey,
No have not been able to do it until now. oops that question was for vinay :grinning:
@AlekseySh we can coordinate and solve this problem for the greater good?
On Fri 20 Apr, 2018, 8:19 PM Aleksey, notifications@github.com wrote:
@imvinaypatil https://github.com/imvinaypatil You solved this problem?
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/tensorflow/models/issues/2694#issuecomment-383120552,
or mute the thread
https://github.com/notifications/unsubscribe-auth/Ajc5mf25i5Y6wEw1t-GO-5YBZFUwCkUiks5tqfV0gaJpZM4QQrmi
.
sjaiswal25
on 20 Apr 2018
anyone has a solution in the offering?
sjaiswal25
on 16 May 2018
Hi There,
We are checking to see if you still need help on this, as this seems to be considerably old issue. Please update this issue with the latest information, code snippet to reproduce your issue and error you are seeing.
If we don't hear from you in the next 7 days, this issue will be closed automatically. If you don't need help on this issue any more, please consider closing this.
 tensorflowbutler
on 30 Jan 2020
tensorflowbutler
on 30 Jan 2020
Related issues
 mbenami
·
3Comments
mbenami
·
3Comments
 atabakd
·
3Comments
atabakd
·
3Comments
 25b3nk
·
3Comments
25b3nk
·
3Comments
 trungdn
·
3Comments
trungdn
·
3Comments
 dsindex
·
3Comments
dsindex
·
3Comments
Most helpful comment
I'm on HEAD and TF 1.4, and can reproduce this error with ResNet-101.