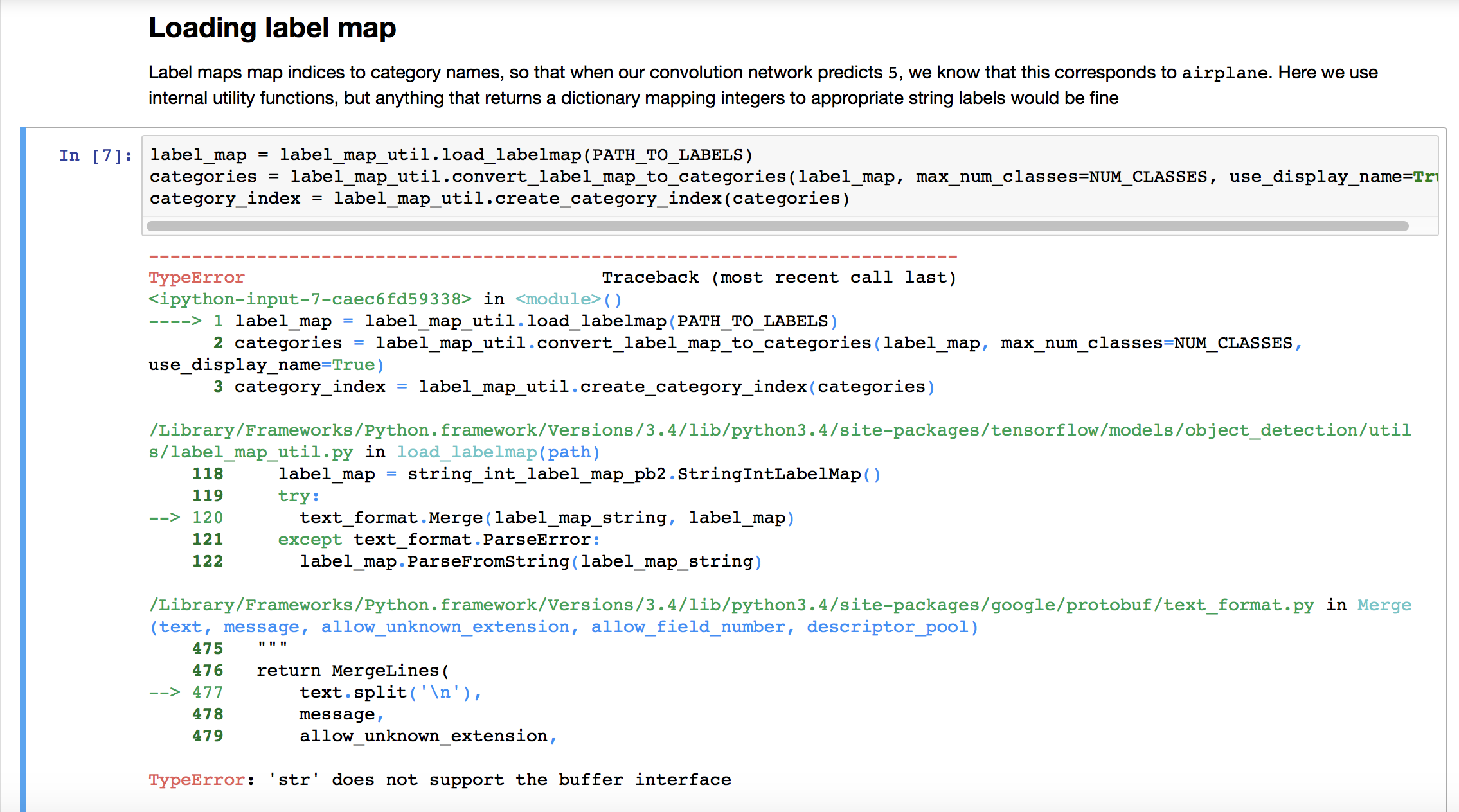
Models: [textsum]:TypeError: 'str' does not support the buffer interface
when i run training command,
$ bazel-bin/textsum/seq2seq_attention \
--mode=train \
--article_key=article \
--abstract_key=abstract \
--data_path=data/training-* \
--vocab_path=data/vocab \
--log_root=textsum/log_root \
--train_dir=textsum/log_root/train
the shell alerts me on data.py file,
Exception in thread Thread-2:
Traceback (most recent call last):
File "/home/led/anaconda2/envs/tensorflow/lib/python3.4/threading.py", line 911, in _bootstrap_inner
self.run()
File "/home/led/anaconda2/envs/tensorflow/lib/python3.4/threading.py", line 859, in run
self._target(self._args, *self._kwargs)
File "/home/led/textsum/textsum/batch_reader.py", line 138, in _FillInputQueue
data.ToSentences(article, include_token=False)]
File "/home/led/textsum/textsum/data.py", line 215, in ToSentences
return [s for s in s_gen]
File "/home/led/textsum/textsum/data.py", line 215, in
return [s for s in s_gen]
File "/home/led/textsum/textsum/data.py", line 189, in SnippetGen
start_p = text.index(start_tok, cur)
TypeError: 'str' does not support the buffer interface
could someone tell me what;s wrong?
 18811376770
18811376770
All 12 comments
That looks like you are using an older not python 3 compatible version of textsum. @nealwu, perhaps can comment. He checked this in:
https://github.com/tensorflow/models/commit/66eb101896a1b7c1691c7416668776ea60ddb78f
Could you please specify what version of textsum you are using i.e. git describe in the root of the models directory.
 aselle
on 25 Apr 2017
aselle
on 25 Apr 2017
That commit was a modification from this pull request: https://github.com/tensorflow/models/pull/1244.
@studynon, did you ever run into an issue like this?
 nealwu
on 26 Apr 2017
nealwu
on 26 Apr 2017
@aselle
commit d6bee2c713c6aed6522ab32c34b57412d0216d95
Author: Neal Wu neal@nealwu.com
Date: Wed Apr 5 17:22:27 2017 -0700
18811376770
on 26 Apr 2017
Perhaps the model is still not fully compatible with Python 3. It seems like you need to convert the string into bytes in this case. @aselle, do you know how to do that while maintaining Python 2 compatibility?
nealwu
on 26 Apr 2017
@nealwu, I've only dabbled with python2 vs python3, but as far as I know the usual approach is to use six functionality as much as possible instead of the python functionality directly. Maybe this
http://six.readthedocs.io/#binary-and-text-data
?
aselle
on 26 Apr 2017
@18811376770 could you try using six.b() to convert the string to bytes? If that fixes your problem, please submit a pull request for it and we'll merge.
nealwu
on 26 Apr 2017
The following changes help me to run the code in python3. Basically it calls the str.decode() and str.encode() functions in python3:
At around line 189 in data.py:
start_p = text.index(start_tok.encode(), cur)
# start_p = text.index(start_tok, cur)
end_p = text.index(end_tok.encode(), start_p + 1)
At around line 194 in batch_reader.py:
element = ModelInput(enc_inputs, dec_inputs, targets, enc_input_len,
dec_output_len, ' '.join([sent.decode() for sent in abstract_sentences]),
' '.join([sent.decode() for sent in abstract_sentences]))
 catfalls
on 20 Jun 2017
catfalls
on 20 Jun 2017
The above changes don't work for me. It brings new bugs to the model. My solution is
At around line 189 in data.py:
#start_p = text.index(start_tok, cur)
start_p = text.index(start_tok.encode(), cur)
#end_p = text.index(end_tok, start_p + 1)
end_p = text.index(end_tok.encode(), start_p + 1)
At last line in data.py:
#return [s for s in s_gen]
return [s.decode() for s in s_gen]
 skpenn
on 29 Aug 2017
skpenn
on 29 Aug 2017
Could I know how can I fix this issue?
 YiHuang2015
on 1 Sep 2017
YiHuang2015
on 1 Sep 2017
@YiHuang2015 I would suggest asking on StackOverflow.
nealwu
on 2 Sep 2017
Thanks...I will
YiHuang2015
on 5 Sep 2017
This question is better asked on StackOverflow since it is not a bug or feature request. There is also a larger community that reads questions there. Thanks!
 karmel
on 24 Feb 2018
karmel
on 24 Feb 2018
Related issues
 nmfisher
·
3Comments
nmfisher
·
3Comments
 airmak
·
3Comments
airmak
·
3Comments
 xbcReal
·
3Comments
xbcReal
·
3Comments
 dsindex
·
3Comments
dsindex
·
3Comments
 atabakd
·
3Comments
atabakd
·
3Comments
Most helpful comment
The above changes don't work for me. It brings new bugs to the model. My solution is
At around line 189 in data.py:
At last line in data.py: