Mne-python: ICA arguments (once again)
There's been an extensive discussion on the ICA arguments in #4856. As a result, the documentation was improved to clarify the use of the n_components, max_pca_components, and n_pca_components arguments of mne.preprocessing.ICA.
An info box in the current docs now reads:
[For] rank-deficient data such as EEG data after average reference or interpolation, it is recommended to reduce the dimensionality (by 1 for average reference and 1 for each interpolated channel) for optimal ICA performance (see the EEGLAB wiki).
However, after reading that, I didn't really know which of the three abovementioned parameters to adjust. I eventually figured, based on @cbrnr's comments in #4856 and by playing around a little, that it's probably max_pca_components -- at least if I want to achieve "EEGLAB-like" behavior. The respecting EEGLAB wiki section reads:
There are thus some cases in which the rank reduction arising from use of average reference is not detected. In this case, the user should reduce manually the number of components decomposed. For example, when using 64 channels enter, in the option edit box, "'pca', 63".
I was wondering if we could make this connection to EEGLAB behavior more explicit, to make the transition from EEGLAB to MNE-Python easier for users. Specifically,
- state that "reduce the dimensionality" most likely means adjusting
max_pca_components(and leavingn_components,n_pca_componentsat their respective defaults) - state that this would resemble the functionality of the
pcaparameter of EEGLAB'spop_runica()
Further, I found it interesting that both the EEGLAB and MNE-Python docs only explicitly mention the issue of dimensionality reduction following _average referencing_ (and interpolation), since with the reference-free EEG setup we're using in our lab (actiCHamp), dimensionality reduction occurs when setting _any_ reference:
data = mne.io.read_raw_brainvision(infile, preload=True)
rank_before_ref = mne.compute_rank(data)['eeg']
data.set_eeg_reference(['Oz'])
rank_after_ref = mne.compute_rank(data)['eeg']
print(f'Rank before referencing: {rank_before_ref}')
print(f'Rank after referencing: {rank_after_ref}')
Produces:
...
Rank before referencing: 64
Rank after referencing: 63
Wonder if that could and should also be mentioned in the docs?
(Also this made it apparent to me that we really should implement #1717 to warn users of potential rank deficiency…)
cc @shirllim @nandmone
 hoechenberger
hoechenberger
All 33 comments
an PR to update the doc is welcome
 agramfort
on 12 Feb 2020
agramfort
on 12 Feb 2020
Yes, the ICA parameters are a constant source of confusion (at least for me) even with the updated docs. By all means, please try to make it clearer by adding this information regarding EEGLAB.
Regarding the rank, I think this is because when you load some data the reference channel is usually not included. Therefore, if you now re-reference to an existing channel, you will reduce the rank because you didn't add the original reference back.
Try this:
data = mne.io.read_raw_brainvision(infile, preload=True)
rank_before_ref = mne.compute_rank(data)['eeg']
data = mne.add_reference_channels(data, "REF")
rank_before_ref_post = mne.compute_rank(data)['eeg']
data.set_eeg_reference(['Oz'])
rank_after_ref = mne.compute_rank(data)['eeg']
print(f'Rank before referencing: {rank_before_ref}')
print(f'Rank before referencing, after adding original reference channel: {rank_before_ref_post}')
print(f'Rank after referencing: {rank_after_ref}')
Which will give you:
Rank before referencing: 64
Rank before referencing, after adding original reference channel: 64
Rank after referencing: 64
Maybe also worth noting somewhere.
 cbrnr
on 12 Feb 2020
cbrnr
on 12 Feb 2020
Regarding the rank, I think this is because when you load some data the reference channel is usually not included. Therefore, if you now re-reference to an existing channel, you will reduce the rank because you didn't add the original reference back.
We don't use a reference in most recordings :) The system is truly reference-free, i.e., during recording, the reference is a "virtual ground" inside the amplifier (which, I believe, is connected to the GND electrode on the participant's scalp); no electrode is selected to be a reference at recording time.
Edit: See https://www.brainproducts.com/files/secure/Manuals/actiCHamp_actiCHamp-Plus_OI.pdf page 64
Edit2: Still not sure whether adding a reference, then, would imply a rank reduction… Took my last linear algebra classes like 7 years ago, whoops.
hoechenberger
on 12 Feb 2020
We don't use a reference in most recordings :) The system is truly reference-free, i.e., during recording, the reference is a "virtual ground" inside the amplifier (which, I believe, is connected to the GND electrode on the participant's scalp); no electrode is selected to be a reference at recording time.
Same for our BioSemi system (it uses a combination of two channels labeled GND and DRL, which are not part of the recorded data) - but since the EEG system records voltage there needs to be some reference. If it's the ground, that's the zero-level, so you need to add it back to the data.
cbrnr
on 12 Feb 2020
If it's the ground, that's the zero-level, so you need to add it back to the data.
No, the data is already "referenced. Just to GND, which of course is unusably noisy; to "properly" reference, we simply select one of the channels as reference during analysis.
There's another option offered by our recording software, which allows us to set one or more reference channels _during recording_; all the system does, then, is an online subtraction of the reference channel signal from all the other channels at the time or recording (in software). When then importing the data into MNE, the reference channel is missing and indeed needs to be added back via mne.add_reference_channels()
hoechenberger
on 12 Feb 2020
But even with GND you need to add this channel back to the data, because it is the reference and this reference is not part of the data.
cbrnr
on 12 Feb 2020
But even with GND you need to add this channel back to the data, because it is the reference and this reference is not part of the data.
Are you sure about this? The rank oft the data would stay 64 (number of electrodes) that way, is that _really_ what I want / would expect?
hoechenberger
on 12 Feb 2020
Are you sure about this? The rank oft the data would stay 64 (number of electrodes) that way, is that really what I want / would expect?
Yes, the rank stays 64. But if you then re-reference to any existing channel, the rank also stays 64.
cbrnr
on 12 Feb 2020
Have you tried my modified example with your data?
cbrnr
on 12 Feb 2020
Have you tried my modified example with your data?
Yes, it works and the rank of the data remains 64 (== number of channels) after adding that "virtual" reference.
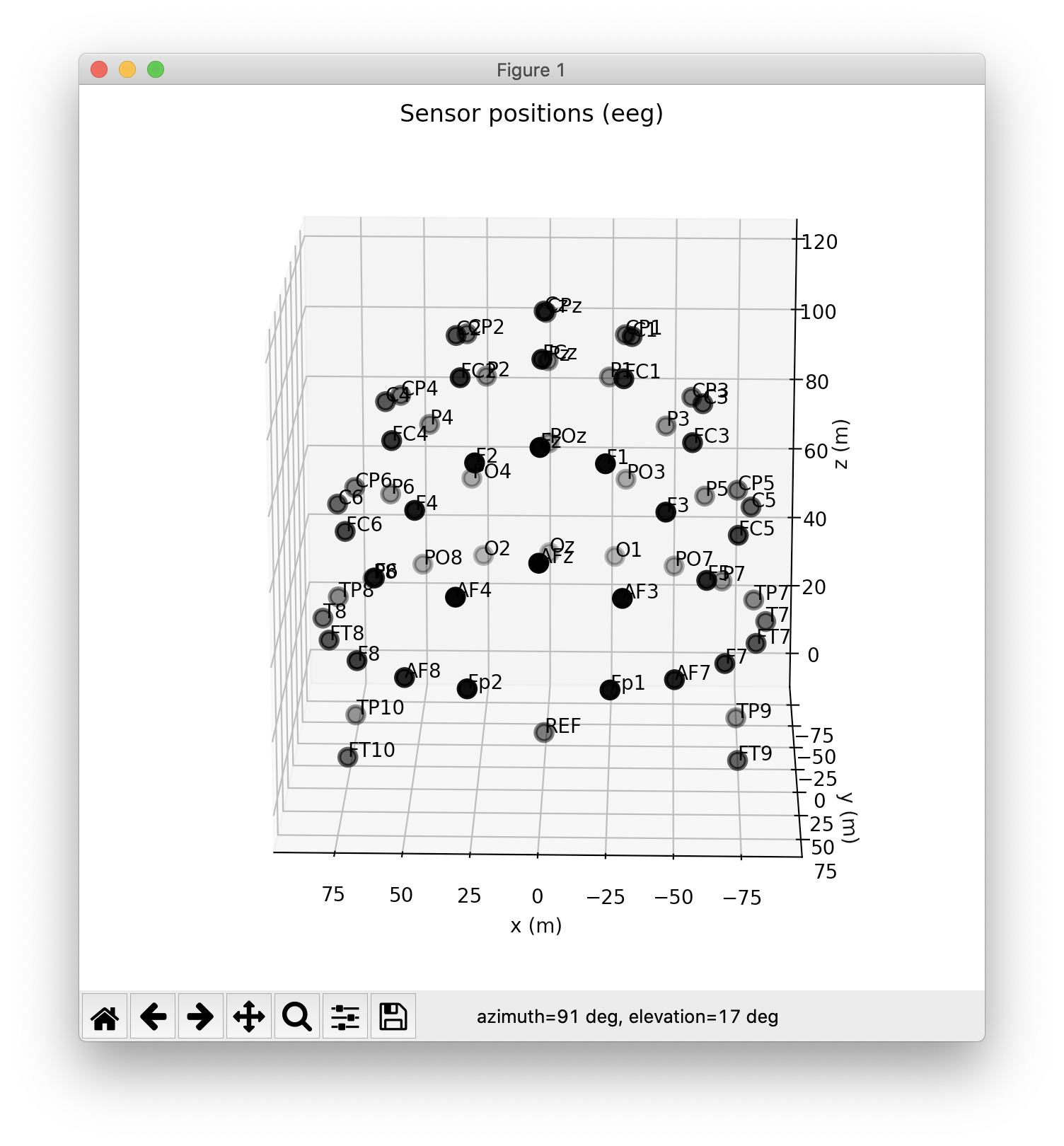
I'm still not sure this is the right thing to do. The channel has no position in my montage (since, well, it's virtual), so it will appear at [0,0,0] by default, this cannot be right?
hoechenberger
on 12 Feb 2020
Also just noticed the units on the axis labels are off, I specified 'mm' when loading the montage, yet the plot produced by data.plot_sensors() displays m.
hoechenberger
on 12 Feb 2020
IIRC the units should be for whatever units there are on disk, in MNE everything should be converted (during read) to m to be correct.
 larsoner
on 12 Feb 2020
larsoner
on 12 Feb 2020
I'm still not sure this is the right thing to do. The channel has no position in my montage (since, well, it's virtual), so it will appear at [0,0,0] by default, this cannot be right?
Ok scratch that, you probably meant to add the ref at the location of GND?
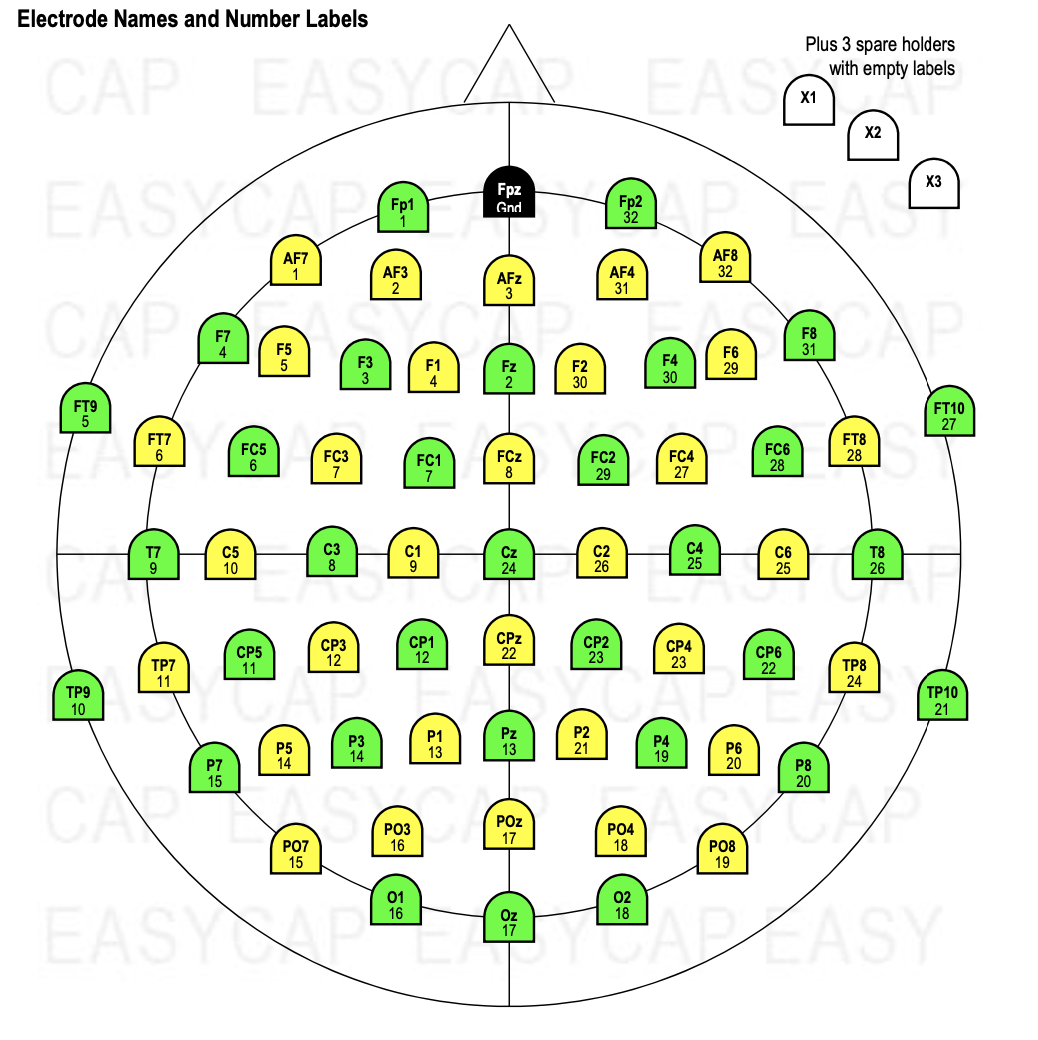
Our cap layout for reference (no pun intended):
hoechenberger
on 12 Feb 2020
The position is irrelevant for calculating the re-referenced signals.
cbrnr
on 12 Feb 2020
The position is irrelevant for calculating the re-referenced signals.
Yes, but then I'd have to remove the sensor again before plotting topomaps etc? This all seems kinda strange to me
hoechenberger
on 12 Feb 2020
The alternative is not to add the reference and live with the reduced rank data. I think that's what basically everybody does, but I was thinking that especially in the case of average reference it might be sensible to add the reference before (even more so if the original reference is on the scalp e.g. at Cz).
cbrnr
on 12 Feb 2020
@larsoner
IIRC the units should be for whatever units there are _on disk_, in MNE everything should be converted (during read) to
mto be correct.
The issue seems to be that I'm using a "generic Theta-phi in degrees" montage, and read_custom_montage() silently swallows my unit kwarg, as the _read_theta_phi_in_degrees() function it invokes doesn't have one
Will open a new issue for this.
hoechenberger
on 12 Feb 2020
@cbrnr
Will think about what you said and get back to you tomorrow :)
I mean, if you really think it would be a valid approach to add the reference back in, it would actually increase the number of electrodes from 64 to 65, which could be nice (because GND, which is used as reference during "reference-free" measurements, is Fpz and normally lost).
hoechenberger
on 12 Feb 2020
@cbrnr
Yes, the ICA parameters are a constant source of confusion (at least for me) even with the updated docs. By all means, please try to make it clearer by adding this information regarding EEGLAB.
So, we do agree that to get EEGLAB-like behavior as in pop_runica(..., "pca", 123), users would have to use max_pca_components=123 and leave n_components and n_pca_components alone?
hoechenberger
on 12 Feb 2020
So, we do agree that to get EEGLAB-like behavior as in pop_runica(..., "pca", 123), users would have to use max_pca_components=123 and leave n_components and n_pca_components alone?
That I'm not sure, I will check tomorrow.
cbrnr
on 12 Feb 2020
Thanks @cbrnr!
hoechenberger
on 12 Feb 2020
I just read the docstring, and I'd say that you want the n_components argument. It says that this is the "number of principal components (from the pre-whitening PCA step) that are passed to the ICA algorithm during fitting". The other two arguments deal with signal reconstruction when applying the fitted ICA.
cbrnr
on 13 Feb 2020
@cbrnr Hmm. Ok so the EEGLAB wiki says:
When computing average reference on n-channel data, the rank of the data is reduced to n-1.
...
There are ... some cases in which the rank reduction arising from use of average reference is not detected. In this case, the user should reduce manually the number of components decomposed. For example, when using 64 channels enter, in the option edit box, "'pca', 63".
MNE docs say (highlights by me):
n_components int | float | None
Number of principal components (from the pre-whitening PCA step) that are passed to the ICA algorithm during fitting. If int, must not be larger than max_pca_components. [...] If None, max_pca_components will be used. Defaults to None; the actual number used when executing the ICA.fit() method will be stored in the attribute n_components_ (note the trailing underscore).max_pca_components int | None
Number of principal components (from the pre-whitening PCA step) that are retained for later use (i.e., for signal reconstruction in ICA.apply(); see the n_pca_components parameter). If None, no dimensionality reduction occurs and max_pca_components will equal the number of channels in the mne.io.Raw, mne.Epochs, or mne.Evoked object passed to ICA.fit().
Therefore I figured one would either have to set n_components = max_pca_components, or simply set max_pca_components and leave n_components at the default of None (which would imply n_components = max_pca_components), since we want a dimensionality reduction via PCA before ICA and want to ensure PCA itself doesn't try to identify more components than the rank of the data in the first place.
My understanding is that this would pretty much resemble what EEGLAB does, at least when using the picard algorithm:
if pca_opt
if g.options{pca_ind+1} < 0
[tmpdata,eigvec] = runpca(tmpdata, size(tmpdata,1)+g.options{pca_ind+1});
else
[tmpdata,eigvec] = runpca(tmpdata, g.options{pca_ind+1});
end
options2(pca_ind:pca_ind+1) = [];
end
Here, pca_opt indicates whether tha pca argument was passed to pop_runica(), and pca_ind is the number of components to estimate (e.g., 123 in case of pop_runica(..., 'pca', 123). Not sure why they're +1'ing this, though, but this must be an implementation detail of the runpca() function.
hoechenberger
on 13 Feb 2020
Hm. According to my comment from 2 years ago, the only difference seems to be the pca_components_ matrix. For n_components this matrix retains its original shape (channel x channel) whereas for max_pca_components the discarded rows are missing. The resulting decomposition should be the same I think.
cbrnr
on 13 Feb 2020
For
n_componentsthis matrix retains its original shape (channel x channel) whereas formax_pca_componentsthe discarded rows are missing. The resulting decomposition should be the same I think.
I would assume the decomposition _can_ differ since only setting n_components, but not max_pca_components, could cause PCA to run into a case of "rank deficiency" (please excuse my non-mathematical language here), as by default it would try to find nchans components, even if the rank of the data might be < nchans e.g. after average referencing… n_components would then select n components acquired through this "rank-deficient" PCA.
@agramfort, could you share any insights here?
hoechenberger
on 13 Feb 2020
max_pca_components is the maximum number of PCA components you may want to
use and therefore need to estimate.
n_components <= max_pca_components is what is fed to the ICA that operates
on square unmixing matrices.
Whatever component between n_components and max_pca_components may still be
kept and put back in the data during apply.
>
agramfort
on 13 Feb 2020
@agramfort Thanks! So I suppose the question is, if I conduct a PCA to find n components and then run the PCA once again on the same data, but now trying to find n+1 components, would the first n components found in both runs be identical?
(all under the assumption that the rank of the data is >=n+1)
hoechenberger
on 13 Feb 2020
For the ICA result (unmixing matrix), it should not matter whether you specify n_components=60 or max_pca_components=60. In both cases, only the first 60 PCA dimensions will be used as input for ICA, which will yield a 60x60 unmixing matrix in both cases.
It's the apply step where these two parameters may yield different results (but only if n_components < max_pca_components; if you supply one the other will be inferred anyway).
cbrnr
on 13 Feb 2020
@cbrnr
Created a quick MWE and I think you're right:
import mne
import pathlib
import numpy as np
sample_data_folder = pathlib.Path(mne.datasets.sample.data_path())
sample_data_raw_file = (sample_data_folder / 'MEG' / 'sample' /
'sample_audvis_raw.fif')
raw = mne.io.read_raw_fif(sample_data_raw_file, preload=True)
raw.crop(tmax=60)
raw.filter(l_freq=1, h_freq=None)
random_state = 123
ica_1 = mne.preprocessing.ICA(max_pca_components=10, random_state=random_state)
ica_1.fit(raw)
ica_2 = mne.preprocessing.ICA(n_components=10, random_state=random_state)
ica_2.fit(raw)
assert np.array_equal(ica_1.mixing_matrix_, ica_2.mixing_matrix_)
assert np.array_equal(ica_1.unmixing_matrix_, ica_2.unmixing_matrix_)
assert np.array_equal(ica_1.pca_components_, ica_2.pca_components_[:10, :])
print(f'Mixing matrix dims: {ica_1.mixing_matrix_.shape}')
print(f'Unmixing matrix dims: {ica_1.unmixing_matrix_.shape}')
print(f'PCA components dims for ica_1: {ica_1.pca_components_.shape}')
print(f'PCA components dims for ica_2: {ica_2.pca_components_.shape}')
Produces:
Fitting ICA to data using 364 channels (please be patient, this may take a while)
Selecting all PCA components: 10 components
Fitting ICA took 3.0s.
Fitting ICA to data using 364 channels (please be patient, this may take a while)
Inferring max_pca_components from picks
Selecting by number: 10 components
Fitting ICA took 2.4s.
Mixing matrix dims: (10, 10)
Unmixing matrix dims: (10, 10)
PCA components dims for ica_1: (10, 364)
PCA components dims for ica_2: (364, 364)
So… What do we suggest in the docs now? For EEGLAB-like behavior, users should set n_components and leave max_pca_components and n_pca_components alone – that simple? :)
hoechenberger
on 13 Feb 2020
So… What do we suggest in the docs now? For EEGLAB-like behavior, users should set
n_componentsand leavemax_pca_componentsandn_pca_componentsalone – that simple? :)
I'd say yes.
BTW you did see https://mne.tools/dev/auto_tutorials/preprocessing/plot_40_artifact_correction_ica.html#ica-in-mne-python, right?
cbrnr
on 13 Feb 2020
BTW you did see https://mne.tools/dev/auto_tutorials/preprocessing/plot_40_artifact_correction_ica.html#ica-in-mne-python, right?
Thanks, I was aware of it but had totally forgotten about the nice flow chart to help me understand the ICA process in MNE.
I once more took the time to step through EEGLAB's runica.m
The docs say:
% 'pca' = [N] decompose a principal component (default -> 0=off)
% subspace of the data. Value is the number of PCs to retain.
% 'ncomps' = [N] number of ICA components to compute (default -> chans or 'pca' arg)
% using rectangular ICA decomposition. This parameter may return
% strange results. This is because the weight matrix is rectangular
% instead of being square. Do not use except to try to fix the problem.
If the user only passes 'pca', val to runica(), as suggested in the wiki, ncomps is set to this value:
ncomps = Value;
Using the PCA results, the data actually gets dimensionality-reduced to ncomps
data = PCEigenVectors(:,1:ncomps)'*data;
Although the PC eigenvectors are retained for later use, only ncomps elements are ever used.
EEGLAB then even states that the ICA is run on the dimensionality-reduced data.
Lastly, the weights matrix is computed – and again, only ncomps eigenvectors are used.
weights= weights*sphere*eigenvectors(:,1:ncomps)';
Based on these observations, and on the remark in the docs that setting ncomps manually leads to the "weight matrix [being] rectangular instead of being square" – meaning it would be square if only pca, but not ncomps were set – I'm now quite convinced that the equivalent to EEGLAB's pca parameter is MNE-Python's max_pca_components.
hoechenberger
on 13 Feb 2020
Like I said, for decomposition it doesn't matter, n_components and max_pca_components yield identical results.
cbrnr
on 13 Feb 2020
Yes, I got that, but it does matter when one invokes ICA.apply() :)
hoechenberger
on 13 Feb 2020
Related issues
 thht
·
38Comments
thht
·
38Comments
 kingjr
·
36Comments
kingjr
·
36Comments
 mmagnuski
·
43Comments
kingjr
·
37Comments
mmagnuski
·
43Comments
kingjr
·
37Comments
 rob-luke
·
51Comments
rob-luke
·
51Comments