Ml-agents: How to compare two models?
Hi, there are some trained models, but I am not sure which one is the best.
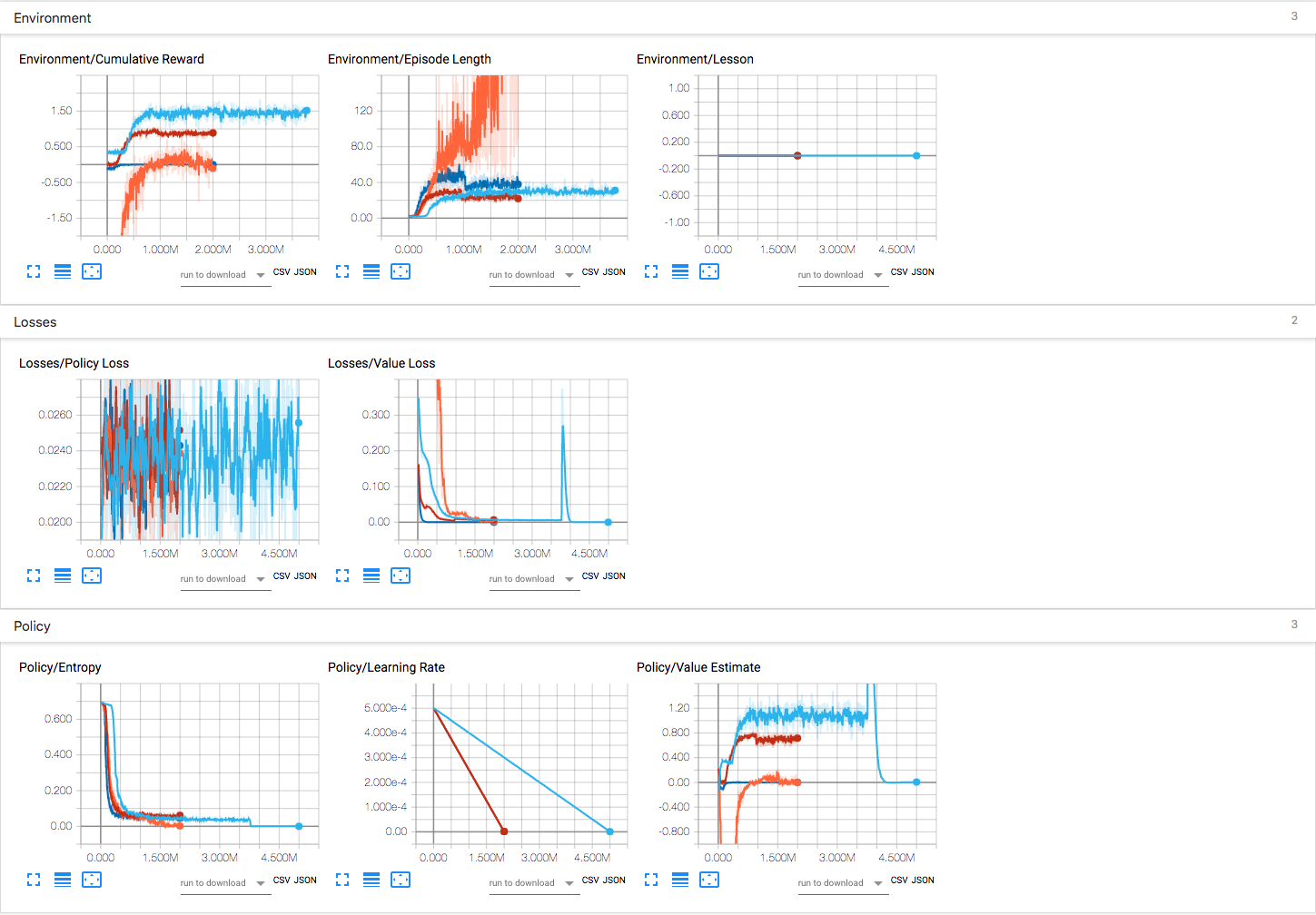
As shown by the tensorbord results, there are 4 models(i.e. blue, red, cyan and orange) in total. Obviously:
- The blue one(only positive reward without penalty) has the highest cumulative reward, but it starts from 0.3 instead of 0.
- the red one(both positive reward and negative penalty) has the similar increment(from 0 to 0.9) than the blue one. But the best value is smaller than the blue one. And it is more 'stable' than the blue one.
- The cyan one is set to only add penalty, if reaching the expect result, add 0 reward, otherwise corresponding penalty.
- The orange one is set to positive and negative reward as well, but only reaching the expect best result will add +1 reward, otherwise add corresponding penalty(more strict than red one).
The problem now is that I can't tell which one is better. Especially for red one and blue one. Even using them in the brain and inferencing in the practical game environment, they perform similarly. Who can tell me how to compare these models deeply from other aspects like Losses etc.? And explain the specific meaning of the stuff shown in the results like Episode Length, Value Loss etc.? It's weird that there is a sharp rise for value loss about 4M steps for blue one, I have no idea about the meaning of this..
 gzrjzcx
gzrjzcx
All 6 comments
Read the documentation.
https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Using-Tensorboard.md
 mansto0
on 25 Jun 2019
mansto0
on 25 Jun 2019
Thanks @mansto0. @gzrjzcx Please refer to our doc on how to interpret the tensorboard result. Also generally if you define your reward correctly, the model with the highest reward should be the best one.
 xiaomaogy
on 25 Jun 2019
xiaomaogy
on 25 Jun 2019
@xiaomaogy Hi, what's the specific meaning of the correct reward? In terms of this case, the blue one has the highest value because it only set positive reward without penalty. I am confused about how to compare these blue and red two models.
In other words, how to compare the reward function? Or how to confirm if this reward function is correct? When inferencing with these two models, they both take similar actions.
gzrjzcx
on 26 Jun 2019
If they take similar action, and you can't differentiate between them, then they are the same. You can add some logging to summarize the agent's behavior to make it more accurate.
xiaomaogy
on 26 Jun 2019
Using different rewards/parameters can make it difficult to directly compare the results.
A simple thing you can do is: make a test scene with a concrete objective (doing the task faster, staying alive longer, collecting more objects, etc) then run each model on that scene and collect their statistics.
 caioc2
on 30 Jun 2019
caioc2
on 30 Jun 2019
Thanks for the discussion - closing this issue due to inactivity. Feel free to open a new issue if you're still running into problems.
 ervteng
on 13 Aug 2019
ervteng
on 13 Aug 2019
Related issues
 dlindmark
·
3Comments
dlindmark
·
3Comments
 MrGitGo
·
4Comments
MrGitGo
·
4Comments
 Hongsungchan
·
3Comments
Hongsungchan
·
3Comments
 mattinjersey
·
3Comments
mattinjersey
·
3Comments
 DVonk
·
3Comments
DVonk
·
3Comments
Most helpful comment
Read the documentation.
https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Using-Tensorboard.md