Ml-agents: Reward thresholding not working
I was able to get curriculum to work using a test with the WallJump environment. For some reason, however, the training doesn't seem to register when the thresholds have been reached when using a nearly identical .json file in a GridWorld environment.
Has anyone else experienced a similar issue? Could it have something to do with using Visual Observations or On Demand Decisions?
 alexchacon2341
alexchacon2341
All 30 comments
Could you give more detail on how "the training doesn't seem to register" please?
 xiaomaogy
on 20 Jun 2018
xiaomaogy
on 20 Jun 2018
Yes, of course.
When I use curriculum training with the WallJump environment, I enter the
following command in my terminal using this wall.json file:
Everything works perfectly -- I am notified in the terminal once the first
threshold of 3000 steps has been reached and the curriculum proceeds to
Lesson 1. The wall begins to appear in the training, exactly as expected.
When I attempt to do the same with GridWorld, however, the curriculum seems
to be ignored entirely. Here are my commands and json file for that
environment:
Please note that while this particular json file uses rewards as its
measure instead of progress, I have also attempted to train using progress
as my measure with identical thresholds and max steps as I used in the
WallJump environment. Even then, the curriculum did not register in the
GridWorld environment.
It seems that, regardless of how I set up my json file, the training skips
over the thresholds as if no curriculum is being used. In the following
training, you can see that, regardless of whether the json file is using
3000 steps or two appearances of a mean reward greater than 0.5 as a
threshold, the criteria has been met. For some reason, however, the lesson
is not increased:
I am at a loss as to what could be causing this difference. As I mentioned
in my post, I am using Visual Observations and On Demand Decisions in the
GridWorld environment. I can't imagine these would affect the curriculum,
but also can't think of any other factors that would disrupt the training.
Thanks in advance for your help, I greatly appreciate it.
Sincerely,
Alex Chacon
On Wed, Jun 20, 2018 at 5:41 PM, Vincent(Yuan) Gao <[email protected]
wrote:
Could you give more detail on how "the training doesn't seem to register"
please?—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
https://github.com/Unity-Technologies/ml-agents/issues/895#issuecomment-398906835,
or mute the thread
https://github.com/notifications/unsubscribe-auth/Adg71wwG0CV-cF4p1OQ5My6vIVd0gzGNks5t-sGRgaJpZM4Uuvu9
.
alexchacon2341
on 21 Jun 2018
@alexchacon2341 It seems that I cannot see the pictures you attached.
xiaomaogy
on 21 Jun 2018
Sorry, I responded via email. I'll try replying in GitHub itself with the
images.
On Wed, Jun 20, 2018 at 6:39 PM, Vincent(Yuan) Gao <[email protected]
wrote:
@alexchacon2341 https://github.com/alexchacon2341 It seems that I
cannot see the pictures you attached.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/Unity-Technologies/ml-agents/issues/895#issuecomment-398920161,
or mute the thread
https://github.com/notifications/unsubscribe-auth/Adg71z6hR7a7ZwFBrAhhTijNqHVAZTCaks5t-s86gaJpZM4Uuvu9
.
alexchacon2341
on 21 Jun 2018
Yes, of course.
When I use curriculum training with the WallJump environment, I enter the
following command in my terminal using this wall.json file:

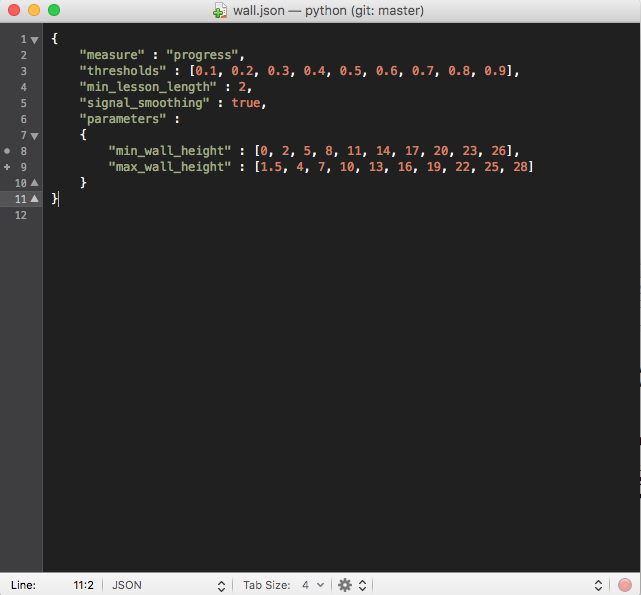
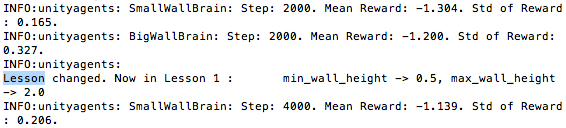
Everything works perfectly -- I am notified in the terminal once the first
threshold of 3000 steps has been reached and the curriculum proceeds to
Lesson 1. The wall begins to appear in the training, exactly as expected.
When I attempt to do the same with GridWorld, however, the curriculum seems
to be ignored entirely. Here are my commands and json file for that
environment:

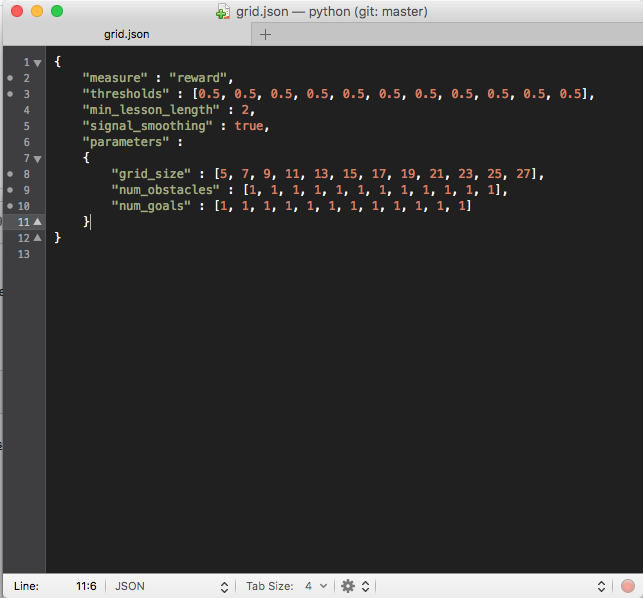
Please note that while this particular json file uses rewards as its
measure instead of progress, I have also attempted to train using progress
as my measure with identical thresholds and max steps as I used in the
WallJump environment. Even then, the curriculum did not register in the
GridWorld environment.
It seems that, regardless of how I set up my json file, the training skips
over the thresholds as if no curriculum is being used. In the following
training, you can see that, regardless of whether the json file is using
3000 steps or two appearances of a mean reward greater than 0.5 as a
threshold, the criteria has been met. For some reason, however, the lesson
is not increased:
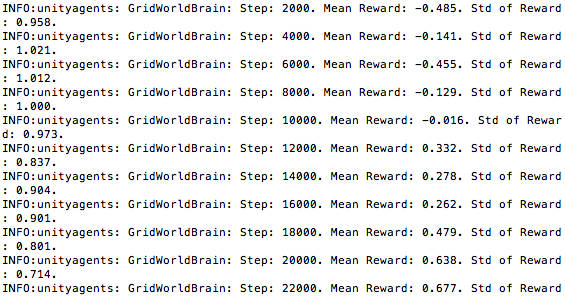
I am at a loss as to what could be causing this difference. As I mentioned
in my post, I am using Visual Observations and On Demand Decisions in the
GridWorld environment. I can't imagine these would affect the curriculum,
but also can't think of any other factors that would disrupt the training.
Thanks in advance for your help, I greatly appreciate it.
Sincerely,
Alex Chacon
alexchacon2341
on 21 Jun 2018
I think the problem is that the grid world academy does not reset (only the agent does). Try setting an academy max step in the grid world. Please let us know if this helped.
 vincentpierre
on 21 Jun 2018
vincentpierre
on 21 Jun 2018
Are you sure the GridWorld academy doesn't reset? This is the agent reset
function from GridAgent.cs:
public override void AgentReset()
{
academy.AcademyReset();
}
Is this not causing the academy to reset?
Thanks,
Alex
On Thu, Jun 21, 2018 at 4:13 AM, vincentpierre notifications@github.com
wrote:
I think the problem is that the grid world academy does not reset (only
the agent does). Try setting an academy max step in the grid world. Please
let us know if this helped.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/Unity-Technologies/ml-agents/issues/895#issuecomment-399015472,
or mute the thread
https://github.com/notifications/unsubscribe-auth/Adg714HKUjhMsSHqd72fwrwykLXlQ5ZTks5t-1WZgaJpZM4Uuvu9
.
alexchacon2341
on 21 Jun 2018
Can you try with setting a max step. There is a possibility that the academy resets without being set to done. This means that python might not realize that the academy is done and has reset.
vincentpierre
on 21 Jun 2018
Sure. I'm running a training session at the moment, but I'll run another one with a max step after. Just to be sure we're on the same page, this is where I should be setting the max step, correct?
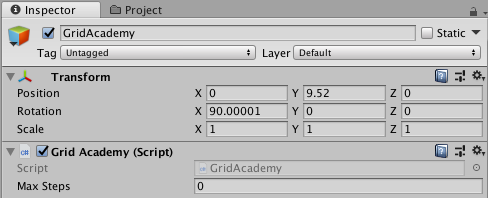
alexchacon2341
on 21 Jun 2018
Yes
vincentpierre
on 21 Jun 2018
OK, great. I'll run the training and get back to you ASAP. Thanks again!
alexchacon2341
on 21 Jun 2018
No luck, I'm afraid. With a max step of 30,000 and the first threshold at 0.1, the lesson should have increased at 3,000. Here is my data:

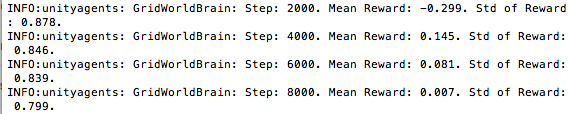
alexchacon2341
on 21 Jun 2018
Same problem here. Curriculum does not jump to next step. It is possible to start every lesson by handy by using --lessong=[0,1,2...], but there is no next lesson by the curriculum.
Reward and progress mesure do not work.
 marcelwessely
on 1 Jul 2018
marcelwessely
on 1 Jul 2018
Yeah, I’ve tried using another self-made environment and still can’t get
curricula to work. I ended up creating a variable that tracks steps and can
recreate the effects of progress-based curricula using it, but still have
no way of using a mean-based curriculum (which would be far more useful).
Is there a way of accessing the mean reward that is printed in the console?
I’ve tried using GetReward(), but that data comes in much more frequent
intervals that are difficult to work with.
On Sun, Jul 1, 2018 at 10:28 AM marcelwessely notifications@github.com
wrote:
Same problem here. Curriculum does not jump to next step. It is possible
to start every lesson by handy by using --lessong=[0,1,2...], but there
is no next lesson by the curriculum.
Reward and progress mesure do not work.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/Unity-Technologies/ml-agents/issues/895#issuecomment-401610402,
or mute the thread
https://github.com/notifications/unsubscribe-auth/Adg712jl9R2fkSlkdqXRHkVJFXOc6XJEks5uCNyPgaJpZM4Uuvu9
.
alexchacon2341
on 1 Jul 2018
Hi @alexchacon2341,
@dericp is working on improving the curriculum feature for the v0.5 release. I'll let him know to take a look at this thread.
 awjuliani
on 14 Aug 2018
awjuliani
on 14 Aug 2018
@awjuliani Great, thanks Arthur!
@dericp Please let me know if there is any way I can be of assistance!
alexchacon2341
on 14 Aug 2018
Hi @alexchacon2341 and @marcelwessely,
Thanks for getting in contact. I believe the issue is related to _Academy_ Max Steps like Vince mentioned. Let me explain a bit more.
There are three max steps parameters---one for _agents_, one for _academies_, and one for the _trainer_. The max steps that you set above was for the academy.
An environment will not reset and increment the lesson number unless the academy is "done" or has reached its max steps.
The max steps which is related to the "progress" that you define in a curriculum is the _trainer_ max step.
Here is what I did to get curriculum learning working in GridWorld.
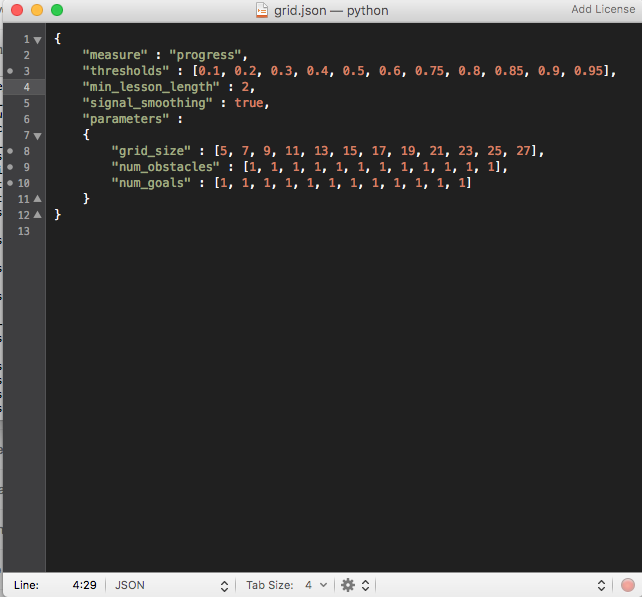
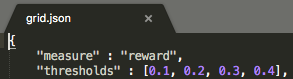
My curriculum is defined as:
{
"measure" : "progress",
"thresholds" : [0.1],
"min_lesson_length" : 2,
"signal_smoothing" : true,
"parameters" :
{
"gridSize" : [5, 7]
}
}
I set the max steps of the academy to 1000:
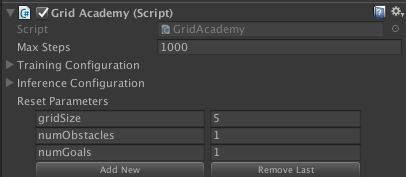
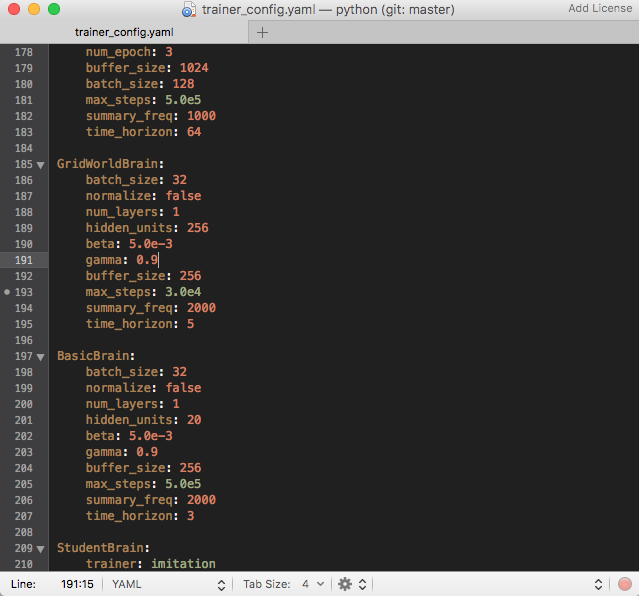
In python/trainer_config.yaml, I have edited max_steps under GridWorldBrain to be 5.0e4. This means that the trainer will run for 50,000 steps total instead of the default 500,000 that is set for GridWorldBrain.
This means we expect the lesson to change at step 5000.
Here is my output:
$ python python/learn.py --train \
--curriculum=python/curricula/grid.json \
--run-id=grid-world
. . .
INFO:unityagents: GridWorldBrain: Step: 2000. Mean Reward: -0.154. Std of Reward: 0.984.
INFO:unityagents: GridWorldBrain: Step: 4000. Mean Reward: -0.342. Std of Reward: 1.002.
INFO:unityagents:
Lesson changed. Now in Lesson 1 : gridSize -> 7
INFO:unityagents: GridWorldBrain: Step: 6000. Mean Reward: 0.031. Std of Reward: 0.960.
Let me know if this works for you! If anything doesn't make sense feel free to reach out.
__Note__: Curriculum learning has been revamped and will be different in v0.5. If you're curious, check out the develop branch.
 pderichai
on 14 Aug 2018
pderichai
on 14 Aug 2018
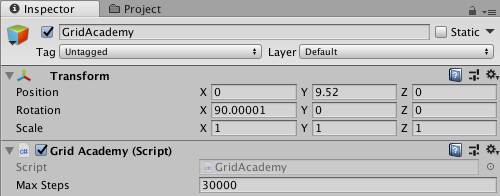
@dericp Ah, I see my error. The Max Steps on the Grid Academy script was so high (30,000) that the AcademyReset() function was never called. Good to know the difference between this value and the max steps value in trainer_config.yaml. I have updated everything and the curriculum now works for both "progress" and "reward" measures.
I did notice something a little strange, which is that the lesson was increased before the mean reward reached each threshold. As you can see below, the curriculum entered Lesson 1 when a mean reward of -0.045 was reported even though the "reward" measure threshold was 0.1:

And later, the curriculum entered Lesson 2 with a mean reward of 0.189 even though the next "reward" measure was 0.2:

I'm guessing this means the "reward" measure looks at individually reported reward values instead of the mean reward -- is that correct?
alexchacon2341
on 16 Aug 2018
@alexchacon2341 That is definitely strange and could be a bug. Let me look into it.
pderichai
on 17 Aug 2018
Sounds good, thanks very much!
On Thu, Aug 16, 2018 at 6:42 PM Deric Pang notifications@github.com wrote:
@alexchacon2341 https://github.com/alexchacon2341 That is definitely
strange and could be a bug. Let me look into it.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/Unity-Technologies/ml-agents/issues/895#issuecomment-413706028,
or mute the thread
https://github.com/notifications/unsubscribe-auth/Adg716beKHRAO_p_8b2ULlSArkYiYC1eks5uRfVKgaJpZM4Uuvu9
.
alexchacon2341
on 17 Aug 2018
Encountering the same issue,
In GridAcademy (for sample reference) resetParameter doesn't have any "Write Access" according to the IDE, the default resetParameter seems only initialize in editor inspector?

 karta1297963
on 24 Aug 2018
karta1297963
on 24 Aug 2018
Hey everyone,
This bug should be fixed by https://github.com/Unity-Technologies/ml-agents/pull/1141. You can try it out on the release branch https://github.com/Unity-Technologies/ml-agents/tree/release-v0.5. Note that ml-agents has evolved quite a bit on this branch and if you're interested in trying out the fix, read the migration doc https://github.com/Unity-Technologies/ml-agents/blob/release-v0.5/docs/Migrating.md.
pderichai
on 5 Sep 2018
Bug fix #1141 looks good, thanks! In the current implementation, will changing "buffer_size" in trainer_config.yaml also change the size of the "reward_buffer" from which trainer_controller.py samples mean reward? Also, will the "Mean Reward" reported in the terminal (or equivalent) now be the same as the mean reward sampled from "buffer_size"?
alexchacon2341
on 7 Sep 2018
buffer_size in the trainer configuration file refers to "the number of experiences to collect before updating the policy model" which is completely separate from the size of the reward_buffer. The size of the reward_buffer will be the min_lesson_length defined in the curriculum. Unfortunately, the mean reward reported in the console will not be the same as the reward sampled from the reward_buffer.
Copying from the CL docs:
min_lesson_length (int) - The minimum number of episodes that should be completed before the lesson can change. If measure is set to reward, the average cumulative reward of the last min_lesson_length episodes will be used to determine if the lesson should change. Must be nonnegative.
__Important__: the average reward that is compared to the thresholds is different than the mean reward that is logged to the console. For example, if min_lesson_length is 100, the lesson will increment after the average cumulative reward of the last 100 episodes exceeds the current threshold. The mean reward logged to the console is dictated by the summary_freq parameter in the trainer configuration file.
pderichai
on 7 Sep 2018
Got it. So, if desired, I could set "min_lesson_length" and "summary_freq" to the same value in order to make the output to the console essentially monitor the mean used by the curriculum, correct? And this would not effect the actual training of the agent?
alexchacon2341
on 8 Sep 2018
Yes and yes, that sounds right.
pderichai
on 8 Sep 2018
Perfect, thanks so much!
alexchacon2341
on 8 Sep 2018
Thanks for reaching out to us. Hopefully you were able to resolve your issue. We are closing this due to inactivity, but if you need additional assistance, feel free to reopen the issue.
 eshvk
on 29 Jan 2019
eshvk
on 29 Jan 2019
I was able to resolve the issue, thanks very much!
Best,
Alex
On Tue, Jan 29, 2019 at 1:23 PM esh notifications@github.com wrote:
Thanks for reaching out to us. Hopefully you were able to resolve your
issue. We are closing this due to inactivity, but if you need additional
assistance, feel free to reopen the issue.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/Unity-Technologies/ml-agents/issues/895#issuecomment-458650668,
or mute the thread
https://github.com/notifications/unsubscribe-auth/Adg717O7a8khnPEAE8IUPtVfFcVpK95Mks5vIJGegaJpZM4Uuvu9
.
alexchacon2341
on 29 Jan 2019
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![lock[bot] picture](https://avatars1.githubusercontent.com/in/6672?v=4&s=40) lock[bot]
on 30 Jan 2020
lock[bot]
on 30 Jan 2020
Related issues
 phoenixSK
·
17Comments
phoenixSK
·
17Comments
 beardordie
·
58Comments
beardordie
·
58Comments
 atapley
·
22Comments
atapley
·
22Comments
 ElliotWood
·
19Comments
ElliotWood
·
19Comments
 devedse
·
34Comments
devedse
·
34Comments
Most helpful comment
Hi @alexchacon2341 and @marcelwessely,
Thanks for getting in contact. I believe the issue is related to _Academy_ Max Steps like Vince mentioned. Let me explain a bit more.
There are three max steps parameters---one for _agents_, one for _academies_, and one for the _trainer_. The max steps that you set above was for the academy.
An environment will not reset and increment the lesson number unless the academy is "done" or has reached its max steps.
The max steps which is related to the "progress" that you define in a curriculum is the _trainer_ max step.
Here is what I did to get curriculum learning working in GridWorld.
My curriculum is defined as:
I set the max steps of the academy to 1000:
In
python/trainer_config.yaml, I have editedmax_stepsunderGridWorldBrainto be5.0e4. This means that the trainer will run for 50,000 steps total instead of the default 500,000 that is set forGridWorldBrain.This means we expect the lesson to change at step
5000.Here is my output:
Let me know if this works for you! If anything doesn't make sense feel free to reach out.
__Note__: Curriculum learning has been revamped and will be different in v0.5. If you're curious, check out the
developbranch.