Ml-agents: Can't train a simple game.
Hello.
I'm trying to train a neural network to play a simple game - the player can move a blue square on a walled off plane. If player collides with any of the walls, he recieves a reward of -1 and the game is reset. There's also a randomly spawned green square that needs to be collected. On collision, it gives a reward of +1 and resets the game.
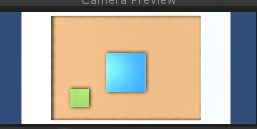
Here's a screenshot of it from a viewer's perspective. Right now I'm trying to run 9 games simultaneously.

My goal is to make a neural network learn how to play this "game" using only image input - a top-down orthographic view of the game. The input is 2 continuous variables - X and Y axis. The maximum speed for each is defined in the environment.
So far, no matter what I do, the neural network seems to converge to some kind of a local minimum. One of the most frequent results is seemingly ignoring all negative rewards and just going in a single direction in hope that eventually a reward will be hit.
I've tried numerous things:
- adding a small negative reward for each step,
- disabling/enabling negative reward for hitting the walls,
- enabling/disabling game reset on hitting the wall,
- adding multiple green squares, etc.
Most of them seemed to make the progress worse than better, so yeah.
The current training process seems to be doing better than the previous ones, however the entropy is increasing.
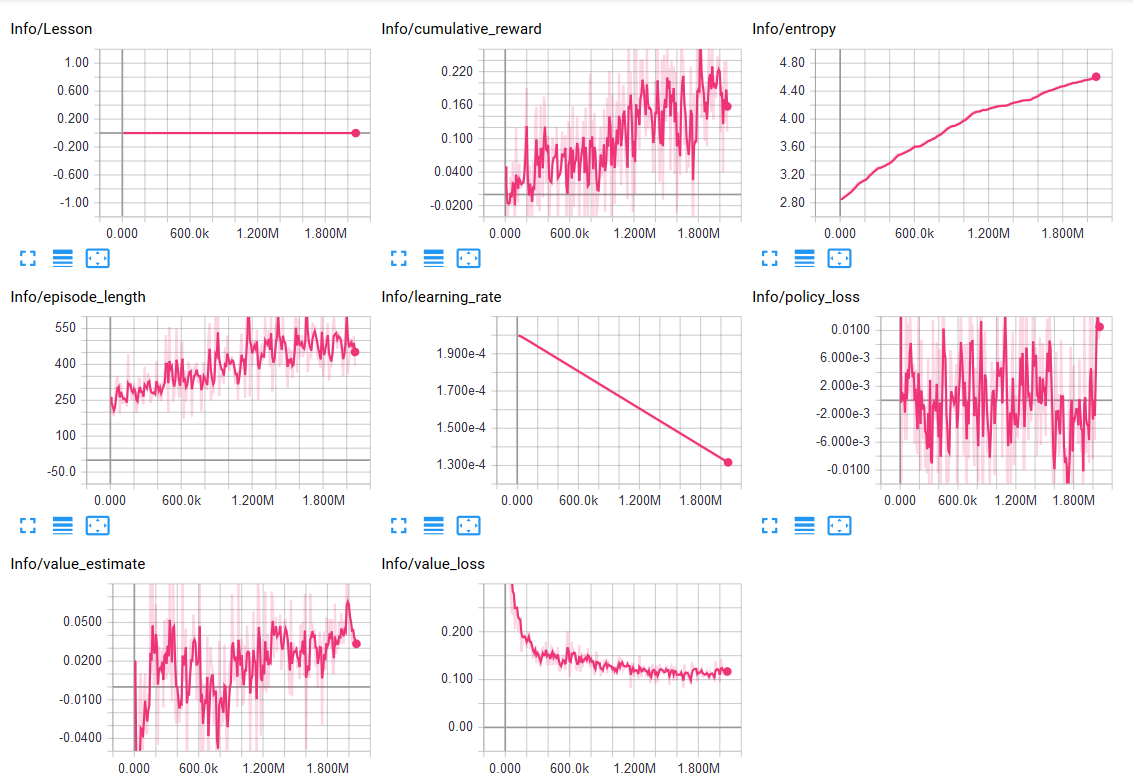
What should I do to improve the results?
How can I check if the neural network actually receives the image?
 drArthur
drArthur
All 20 comments
In my experience training locomotion with continuous control is a bit more challenging. Try switching it to a discrete version to start with.
Also, I would encourage you to make use of the curriculum system to speed up your training.

In this example that I am on currently, I started with the character 3 units away from the target, no obstacles. When it learned that it should go towards the target, I increased the distance gradually. Only after it could hit the target at a longer and random distance I added the obstacles, once again with increasing difficulty.
This type of breaking down of the problem and gradually retraining the trained model with more difficult environments gave me better results. Then again, all experimental so your mileage might vary!
Good luck, enjoy life
 batu
on 12 Dec 2017
batu
on 12 Dec 2017
Hey, thanks for the reply!
I'll definitely try it out with a discrete version.
There are a few questions I'd like to ask:
Are you passing the image from a camera to the NN?
Do you also pass the positions for the player and the goal?
Roughly how long did it take for the neural network to reach the results as shown in the animation?
drArthur
on 12 Dec 2017
No, I am not using camera data, but rather a state that has information about some rigidbody information and closest obstacles.
The full state information is as follows:
Rigidbody velocity info.
Rotational info.
Vectors and distance per axis on the closest 4 object. (walls and obstacles)
The position and the distance to the target.
It took a long time. Probably in total 4 hours of training. Initial training to move to the target from a direct rotation (the player starts looking directly at the target and the target gets farther and farther away using the curriculum). Another hour of training on the same model in which the player starts by having a random initial rotation. (Which in itself gets more and more varied as time goes on using the curriculum system) And finally, I add the obstacles to the mix, once again getting more and more difficult.
batu
on 12 Dec 2017
Just chiming in here that I had similar problems until I increased the amount of agents and variance in the environment - running with multiple agents provides more stable data and faster training results. Can you describe the state information in more detail - code level maybe?
The high noise on the cumulative reward graph changed to a smooth, curvy up-trending line after introducing 8 more agents in my scene.
 mikaisomaa
on 13 Dec 2017
mikaisomaa
on 13 Dec 2017
I build a similar environment.
The only difference seems to be that my agent does not get punished for hitting a wall. Besides that it makes use of continuous actions. It was pretty easy to train that agent using a continuous state space. But as soon as I add camera input (64x36 grayscale) to the input space, the agent keeps moving into one corner regardless of adjusting hyperparameters, rewards and adding continuous inputs.
 MarcoMeter
on 14 Dec 2017
MarcoMeter
on 14 Dec 2017
Thanks for all the input!
@batu Thanks for the information. I've tried to use discrete space, and the results seem to be somewhat better. They're not satisfactory yet, though. Looking into curriculum learning right now.
@mikaisomaa I'm passing to the neural network only camera data(58x32 color image). The goals are spawning randomly. The player, however is spawned in a constant point. What different kind of variance could I introduce in the environment?
@MarcoMeter Interesting. I'll check out your environment. It looks like I had similar results when using continuous space. The pawn was going in a single direction most of the time. Either way, having only camera data is pretty important for me.
So far I've been training the network with 9 simultaneous agents.
Since the last time I tried to train the same thing, but with discrete space.
The problem I've encountered is that it goes up to an okay result and then it plummets into the abyss.
The first session was something like this:
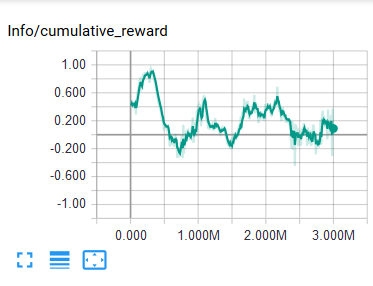
And the most recent one(I introduced a reward of -0.01 each second).
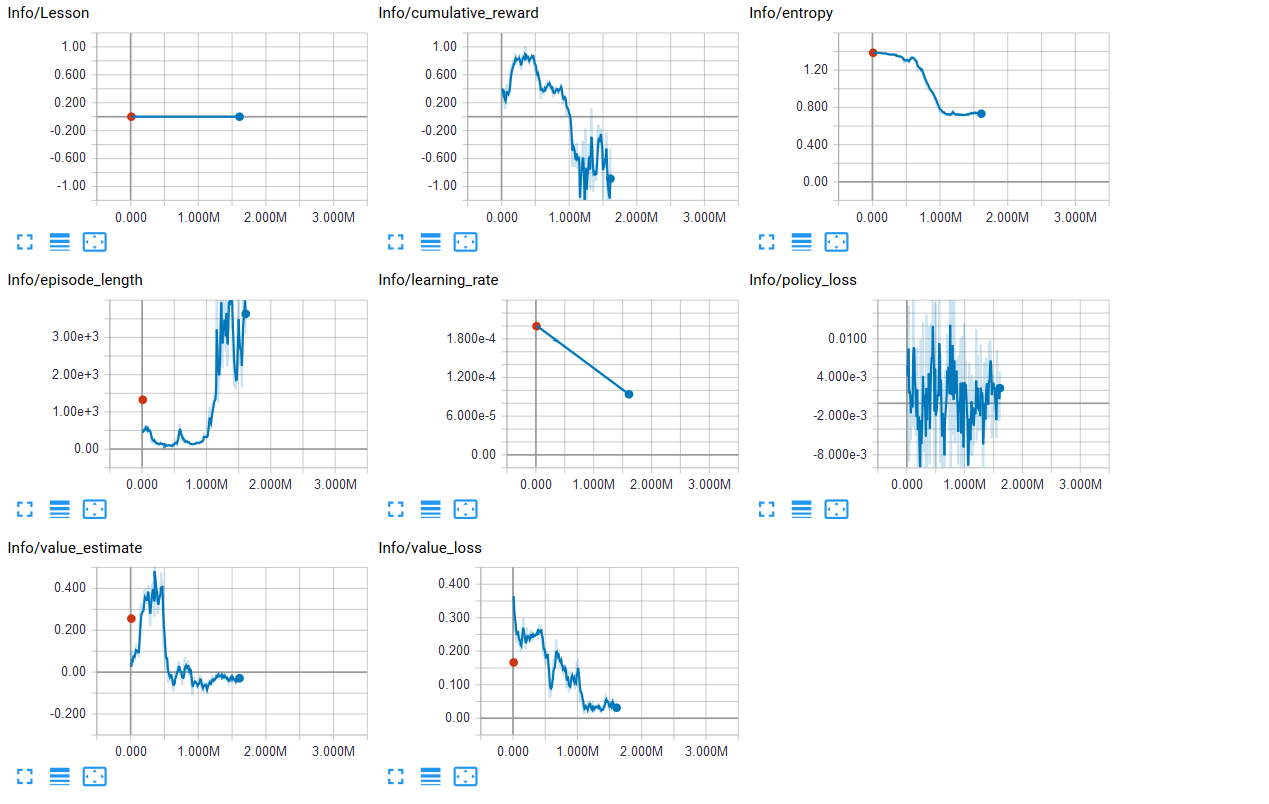
After somewhere around 300k steps it just goes down.
Right now I'm thinking about using curriculum learning, but it will take some time to implement.
drArthur
on 14 Dec 2017
Hi All,
Learning from camera input is inherently a more difficult problem than learning from a compact state representation. If using camera, I would recommend a larger beta to regularize the entropy more. We also currently don't have support for stacking frames/states, so if the camera doesn't contain important information about the velocity of objects, it might not be enough to learn an optimal policy.
Also, a general point on using negative rewards - they should generally be used as sparsely as possible. In the case of training an agent to not hit the wall, a better approach would be to provide a small positive reward every step it doesn't hit the wall, and simply end the episode when the wall is hit.
 awjuliani
on 14 Dec 2017
awjuliani
on 14 Dec 2017
@awjuliani I don't quite understand what containing information about velocity in the camera means... Does that mean that basically without giving any additional information besides camera input, the neural network will give suboptimal results?
Also, found a little problem with goal spawning. It sometimes spawned under the player. Looks like it was messing up the learning process quite a bit. I also made the camera follow the agent.
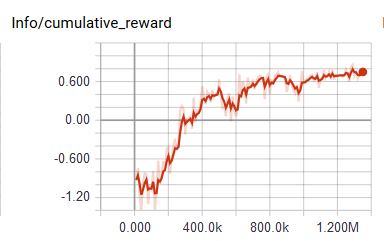
Right now the results are a lot better than before. Though, I've noticed that the neural network is still too "dumb" to start exploring the environment if there is no goal within the limits of camera input. Currently I'm still using the small negative reward each second and the bigger one when hitting the walls.
Guess I'll try to implement the small reward technique now.
drArthur
on 15 Dec 2017
The agent's velocity can be derived from the past and the current frame.
MarcoMeter
on 15 Dec 2017
Hi @drArthur, as @MarcoMeter mentioned, if you have two frames, you can take the difference between them and learn what objects are moving, and how fast they are moving. Both things might be critical for learning depending on the problem. Another possibility is to get the velocity of the Rigidbody you are interested in, and add it to the state representation, so that the network can learn from both the camera and the "true underlying" velocity.
awjuliani
on 18 Dec 2017
I see. I'll look into that then.
Though, now it seems to be working quite well simply using camera as an input. Guess it will be helpful later on as the problems become harder to solve.
By the way, I tried to use curriculum learning, but the lessons don't increase, even though the mean reward goes above the appropriate thresholds.
Here's the current JSON data:
{
"measure" : "reward",
"thresholds" : [0.85, 0.8, 0.75, 0.7, 0.6],
"min_lesson_length" : 2,
"signal_smoothing" : false,
"parameters" :
{
"spawn_radius" : [5.0, 10.0, 15.0, 20.0, 25.0, 25.0],
"random_spawning" : [0.0, 0.0, 0.0, 0.0, 0.0, 1.0],
"wall_size" : [10.0, 15.0, 20.0, 25.0, 30.0, 30.0]
}
}
And here's the training reward data:
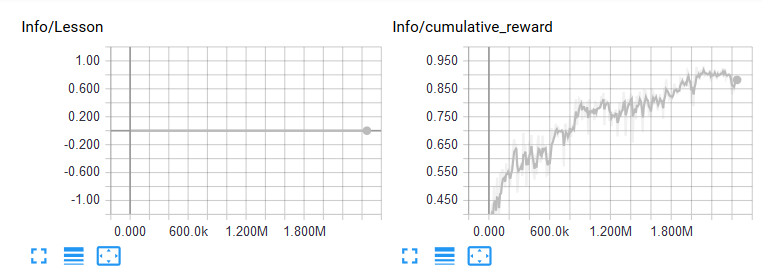
If I understand it correctly, the lesson should've changed when the mean reward is above 0.85 for at least 2 snapshots.
How could I fix this issue?
drArthur
on 18 Dec 2017
Hi @drArthur,
How often does your Academy reset? If max_steps for the academy is set to 0, then it will never reset, and as such it will never check for a new lesson.
awjuliani
on 18 Dec 2017
Oh, I see. That seems to be the case. Thanks!
drArthur
on 18 Dec 2017
Hi @awjuliani,
I've just started looking into ML-Agents and the example Unity scenes don't seem to be behaving as I expected (no learning appears to take place, the agents just generally sit in place like the simulation isn't even running).
I notice that in each one max_steps for the Academy defaults to 0 -- maybe this is why?
 jglazman
on 24 Dec 2017
jglazman
on 24 Dec 2017
Hi @awjuliani,
if you have two frames, you can take the difference between them and learn what objects are moving, and how fast they are moving.
So is this doable right now? I ask bc you mentioned there's currently no support for stacking frames/states, so I'm currently adding the velocity from a Rigidbody (as you suggest) to my state. But is there another way available to me now?
 saporter
on 10 Jan 2018
saporter
on 10 Jan 2018
Hi @jglazman,
max_steps=0 just means that there is no fixed limit to the number of steps in an episode. Have you checked that you are using the external brain when training?
@saporter,
We actually have a working version of the stacking feature in the dev-gather branch. I would recommend checking it out!
awjuliani
on 10 Jan 2018
Oh will do, thanks!
saporter
on 12 Jan 2018
@saporter Feel free to contribute feedback as well, as it is still in development!
awjuliani
on 12 Jan 2018
Hi @drArthur , thanks for reaching out to us. Hopefully you were able to resolve your issue. We are closing this due to inactivity, but if you need additional assistance, feel free to reopen the issue.
 vladimiroster
on 28 Mar 2018
vladimiroster
on 28 Mar 2018
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![lock[bot] picture](https://avatars1.githubusercontent.com/in/6672?v=4&s=40) lock[bot]
on 3 Jan 2020
lock[bot]
on 3 Jan 2020
Related issues
 m-ronchi
·
22Comments
m-ronchi
·
22Comments
 alexchacon2341
·
30Comments
alexchacon2341
·
30Comments
 sunrui19941128
·
33Comments
sunrui19941128
·
33Comments
 devedse
·
34Comments
devedse
·
34Comments
 syigzaw
·
20Comments
syigzaw
·
20Comments
Most helpful comment
In my experience training locomotion with continuous control is a bit more challenging. Try switching it to a discrete version to start with.

Also, I would encourage you to make use of the curriculum system to speed up your training.
In this example that I am on currently, I started with the character 3 units away from the target, no obstacles. When it learned that it should go towards the target, I increased the distance gradually. Only after it could hit the target at a longer and random distance I added the obstacles, once again with increasing difficulty.
This type of breaking down of the problem and gradually retraining the trained model with more difficult environments gave me better results. Then again, all experimental so your mileage might vary!
Good luck, enjoy life