Ml-agents: Help Understanding Mean Reward Behavior

First of thank you to Unity for coming up with SDK! It has been a treat to play with. On to the question I have. I am not so sure why my mean reward is peaking and then starts to decrease back. I couldn't figure out what makes the direction switch signs.
I am using the default PPO algorithm with the default parameters. I played around with the parameters but it just hampered the progress.
A little bit of info on the domain:
I am basically work on adversarial RL. I initially trained a model to chase a given target (which works really well! The reward structure was +1 when caught and -0.01ish every tick) now, I am generating an avoidance model using the already trained chaser. The reward structure is basically a +small amount every tick and -1 when caught or going out of bounds. Here is the training in progress:

As you can see the avoider isnt that well established.
Long story short I am looking for some way to understand the "up then down" behavior of my learning structure, and maybe some guidance in what to tweak, instead of semi blindly trying stuff out.
Once again, thanks a bunch!
 batu
batu
All 22 comments
@batu That looks awesome !
Question : Does the target know of the bounds? Is the absolute position known ? It seems the target runs into the wall, so just wanted to make sure.
I would try to decrease the learning rate and train it for longer, that is usually what I do when the reward goes up then down. If your action space is continuous, try to increase the batch size and buffer size of PPO. I am hope this will help, let us know of the results, I think your findings could help a lot of people facing similar issues.
 vincentpierre
on 19 Nov 2017
vincentpierre
on 19 Nov 2017
They do not know the bounds (what would be a good way to represent the bounds?), however, they do know their absolute position. If either (but realistically target) goes out of bounds it gets -1 reward and resets.
The action space is discrete (4 directions)
I will test your suggestions and keep you updated regarding the results! After this is done I am hoping to try and extend the ppo.py to train two brains at the same time, in an adversarial way, but let's take it one step at a time!
batu
on 19 Nov 2017
If the bounds are fixed, the target should learn where they are and how to avoid them. According the best practices with PPO if the actions are discrete, the batch size should be small, between 32 and 512. Still, decreasing the learning rate might help...
vincentpierre
on 19 Nov 2017
They should right? And yes, made sure that they are fixed. I will experiment and inform on the findings.
Are you interested in a pull request that has better formatting of the models and summaries? I just added some little bits to ppo notebook to get the following behavior:

I separate my builds to different versions and each gets their own directory. Each time I run a model, a directory is made under the corresponding version, with the model#. The tensorflow board information + the used parameters are saved there.
Let me know if this is something you might be interseted in and thanks for the tips!
batu
on 19 Nov 2017
As mentioned, reducing the time step and increasing the overall learning time seemed to have worked.
Some overall observations:
- Keeping the batch size small was much better overall.
- Tweaking beta such that entropy did lower gradually was another important step. There were certain thresholds where mean reward never increased (entropy didn't decrease), but in other cases entropy plummeted very fast. Walking that thin line seemed important for good consistent learning.
I preserve the highest rated model to be used in the end, as you can see there are several "very good" spikes that are not consistent. Unfortunately for this go TF deleted my checkpoints and I only fixed it after the long learning sessions...
Here is the graph form:
(* Ignore the harsh drop around 20m mark, I was loading the model and was using very different parameters to test stuff. The drop is artificial.)
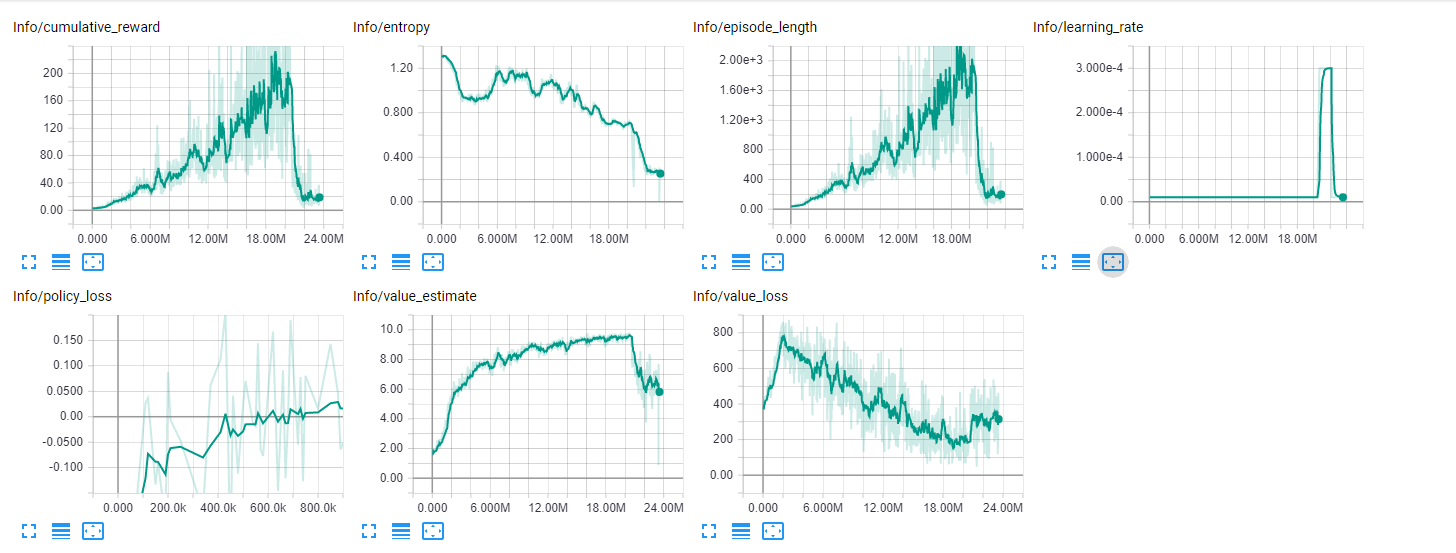
And here is the actual result:

As you can see the avoider successfully psyches out the chaser. Now on to training the chaser to catch the bugger. Let's see how this goes!
batu
on 19 Nov 2017
Concerning potential inputs related to the boundaries, you could add the distance from the agent to the wall.
 MarcoMeter
on 20 Nov 2017
MarcoMeter
on 20 Nov 2017
Very glad that training has gone well @batu,
I will make a point of updating our best practices documents to include your training findings.
Please feel free to submit a PR with the changes to the summaries. They do indeed look helpful. Do you ensure that when a model is reloaded halfway through training that a new version is not created?
 awjuliani
on 20 Nov 2017
awjuliani
on 20 Nov 2017
Yes! If you decide to load a model to keep training the summaries are also updated from that point onwards.
I will do a pull request when I am sure it is robust and clean.
batu
on 22 Nov 2017
@batu May I ask a question? Do you use the same neural network to train both or different ones?
 kwea123
on 23 Nov 2017
kwea123
on 23 Nov 2017
So I was not training them at the same time. I am training one, on a fixed model of the other one and vice versa.
As you can guess this results in gross overfitting to win against the previous technique and only that.
Currently I am working on a multi agent ppo trianing set up but I am sure the official channel will come up with a release before I crack it.
batu
on 24 Nov 2017
Thanks for the answer, I am also experiencing the same problem.
I opened another issue about general questions of multi agent training.
kwea123
on 25 Nov 2017
@batu Nothing official yet, but you can look at the branch dev-multi which is a hack of ppo training with multiple external brains. It does not support freezing the network to train against a fixed version of the opponent but maybe you can get some inspiration from there?
vincentpierre
on 25 Nov 2017
Thank you Vincent, will definitely take a look!
batu
on 26 Nov 2017
@vincentpierre
On the note of looking at the dev branch, is it possible for you to give us the parameters you used when training the new agents you for the new scenes you uploaded? I am struggling a bit with finding the best combinations, especially in the continuous action space.
Thank you!
batu
on 27 Nov 2017
I did not do a lot of work nor parameter tuning. I had a very simple environment so I used the same parameters as the default ppo. As of now, all the brains must take the same hyperparameters, but feel free to change this.
vincentpierre
on 27 Nov 2017
@vincentpierre
Maybe I couldn't find it but can you ensure that ppo_multi is pushed? (assuming it is not proprietary code) I am looking into working with the dual brian set up.
Thank you very much
batu
on 27 Nov 2017
@batu Sorry, I was talking about the dev-multi branch. I did not do a lot of parameter tuning for the environment on that branch. Is that what you are referring to ? The branch dev-multi has been pushed, this I am sure of.
vincentpierre
on 27 Nov 2017
In dev-multı branch, in the PPO.ipynb notebook there is the following import:
from ppo_multi.history import *
from ppo_multi.models import *
from ppo_multi.trainer import Trainer
but there isnt a ppo_multi directory for it to find the history, models and trainer. Are the contents of ppo_multi and (currently existing) ppo the same? If so all should be fine!
batu
on 27 Nov 2017
Hi, I really appreciate that you've already done amazing work using two agents. I also hope to have ppo to train multi-external brains, since the last comment here, I guess there haven't been any updates made yet. I'm still looking forward to seeing updates!
 BeskaMilk
on 4 Mar 2018
BeskaMilk
on 4 Mar 2018
Regarding multi agents : As of today, there is multi external brain training with ppo on development-0.3. Only problem is that there is not much documentation on it yet.
vincentpierre
on 5 Mar 2018
Great, I'll take a look! Thank you, Vincent.
BeskaMilk
on 6 Mar 2018
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![lock[bot] picture](https://avatars1.githubusercontent.com/in/6672?v=4&s=40) lock[bot]
on 3 Jan 2020
lock[bot]
on 3 Jan 2020
Related issues
 devedse
·
34Comments
devedse
·
34Comments
 lukemadera
·
25Comments
lukemadera
·
25Comments
 KilianSillero
·
29Comments
MarcoMeter
·
31Comments
KilianSillero
·
29Comments
MarcoMeter
·
31Comments
 sunrui19941128
·
33Comments
sunrui19941128
·
33Comments
Most helpful comment
Regarding multi agents : As of today, there is multi external brain training with ppo on development-0.3. Only problem is that there is not much documentation on it yet.